Всем привет! Меня зовут Юра, я iOS-разработчик в core-команде. В этой статье расскажу, как мы работаем с многомодульностью в наших iOS-приложениях. Поговорим про окружение и структуру нашего проекта, затронем тему скорости компиляции и разберем немного кодогенерации.

Команда и проекты
Наша core-team отвечает за то, чтобы ребятам из других iOS-команд было удобно и комфортно работать над приложением. Мы создаем автоматизации, улучшаем код, рефакторинги и так далее.
Сейчас мы работаем над двумя приложениями: для соискателей и работодателей. С приложением для соискателей вы наверняка уже знакомы. Над проектами работает десять iOS-разработчиков, мы распределены между пятью командами в мобильном департаменте. Чтобы всем ребятам одновременно было удобно работать, мы разделяем наше приложение на множество фичей.
Фича в нашей терминологии – это отдельный Xcode-проект со своим изолированным кодом и всем необходимым для работы: ресурсами и тестами, которые подключаются к другим фичам и основному приложению. Благодаря такому разделению на фичи, мы обеспечиваем независимую работу над фрагментами и приложениями в каждой команде.
В 2018 году наше приложение было большим монолитным куском кода, кое-как разделенным на четыре более-менее независимых, но тесно связанных друг с другом, куска. В последние годы мы очень интенсивно грызли и растаскивали этот монолит, поэтому сейчас он стал намного меньше. А все новые фичи мы делаем уже изолированными. Сегодня у нас в приложении существует 75 независимых фич, оно стало своеобразным кораблем-контейнеровозом, на котором нагружено множество контейнеров-фич.
Как говорится, «большому кораблю – большие траблы». С этим разделением фич мы познали и соответственное количество проблем. В статье я подробно опишу следующие:
Во-первых, такое большое количество фич в приложении сложно поддерживать: соблюдать единую структуру и связи между ними.
Во-вторых, у нас действительно большой проект. И поскольку он состоит из огромного количества кода, компиляция происходит довольно медленно.
В-третьих, с большим проектом довольно сложно работать из-за огромного количества договоренностей и связей между фичами. Короче говоря, большой проект сам по себе усложняет разработку.
Проблема первая: поддержка структуры
Естественно, много проектов – это сложно. И вы наверняка сталкивались с конфликтами файлов .xcodeproj при мерджах. Чаще всего решаются они довольно просто. Тем не менее, когда они возникают постоянно, их просто неприятно решать, не хочется тратить на это время. А уходит его много.
Поскольку приложение состоит из большого количества связанных между собой фич, поддержку таких связей бывает довольно сложно организовать. Уследить в ручном режиме за тем, какая фича с какой связана, в интерфейсе Xcode бывает довольно сложно. Запросто можно что-то упустить, пропустить, забыть добавить. Поэтому мы практически сразу стали искать решение этой проблемы.
В начале мы использовали CocoaPods – это известный менеджер внешних зависимостей. Мы поняли, что на нем сможем построить нашу многомодульную архитектуру путем использования development pods для наших внутренних фичей. Внутренние проекты для CocoaPods описываются в специальном файле Podspec. Он намного меньше, чем описание проекта в Xcode и содержит только необходимую информацию.
Его можно разделить на две части. Первая – часть с мета-информацией, например, названием модуля, где находятся его файлы. И вторая – перечисление зависимостей этого модуля. В принципе, мы довольно долго и хорошо развивались, используя development pods для многомодульности. Но со временем начали натыкаться на проблемы и ограничения CocoaPods.
Например, CocoaPods не позволяет одновременно с собой удобно использовать Swift Package Manager или Carthage для внешних зависимостей. В какой-то момент для нас это стало довольно серьезной проблемой. Еще у CocoaPods всё сложно с кэшированием зависимостей. По крайней мере, для нашего проекта нам не удалось настроить плагины для кеширования зависимостей, чтобы они корректно работали.
Мы стали думать, куда бы нам уйти из CocoaPods, какие еще инструменты можно использовать для внешних зависимостей. В результате изнурительных поисков мы наткнулись на Tuist. Это утилита, которая генерирует и поддерживает Xcode-проект. Она полностью написана на Swift и файлы описания проектов тоже можно писать на нём. То что нужно.
Итак, благодаря Tuist описание наших проектов стало еще проще. Вот пример:
let project = Feature( name: "Articles", resources: .accessible( swiftGen: [ .images(), .plural(), .strings() ] ), dependencies: ArticlesSourcesDependencies, tests: FeatureTarget( dependencies: ArticlesTestsDependencies ) ).project()
Мы спрятали всю мета-информацию о проекте, которую можно вычислить из других источников, и оставили только самое важное. По сути, разработчику необходимо указать только название фичи, какие ресурсы для нее должны генерироваться с помощью SwiftGen и какие таргеты в ней есть. Списки зависимостей для каждого таргета генерируются автоматически, с помощью скрипта который ищет все import в файлах таргета. Описание проекта стало проще, а делать его стало удобнее.
Пока мы переезжали с CocoaPods на Tuist, мы заметили, что расположение файлов в нашем проекте довольно странное: по историческим причинам и по кто-еще-знает каким. Чтобы два раза не ходить, мы заодно почистили структуру проекта, и теперь всё лежит в нужных папках. За это разработчики сказали нам отдельное «спасибо».

Проблема вторая: медленная компиляция
В какой-то момент разработчики заметили, что сборка проекта занимает чуть больше пяти минут. И это стало для них довольно большой проблемой, потому что они за это время успевали вывалиться из контекста, переключиться на другие задачи, и из-за этого тратили еще больше времени на то, чтобы просто вернуться в тему своей работы.
Мы стали думать, как это починить и для начала решили собрать честную статистику о том, сколько времени уходит на компиляцию наших проектов. В этом нам помог XCLogParser. Xcode после сборки представляет отчеты в формате xcacrivitylog. Эти отчеты содержат всю информацию о сборке, вплоть до каждого файла. А XCLogParser умеет парсить эти отчеты в более «человекочитаемый» формат. Например, отображать их в каком-то визуальном виде или в формате json.
Вот пример json, который отдает XCLogParser после обработки отчета. Главное поле, которое нам интересно – это время, потраченное на компиляцию проекта.

Тем не менее, этот json, на самом деле, довольно большой и содержит подробнейшую информацию о каждом этапе сборки проекта. И это очень здорово. Всю эту информацию мы отправляем в нашу базу данных, и уже оттуда забираем и строим красивые графики о потраченном времени на сборку проекта в Grafana. Вот как выглядят графики для приложений:
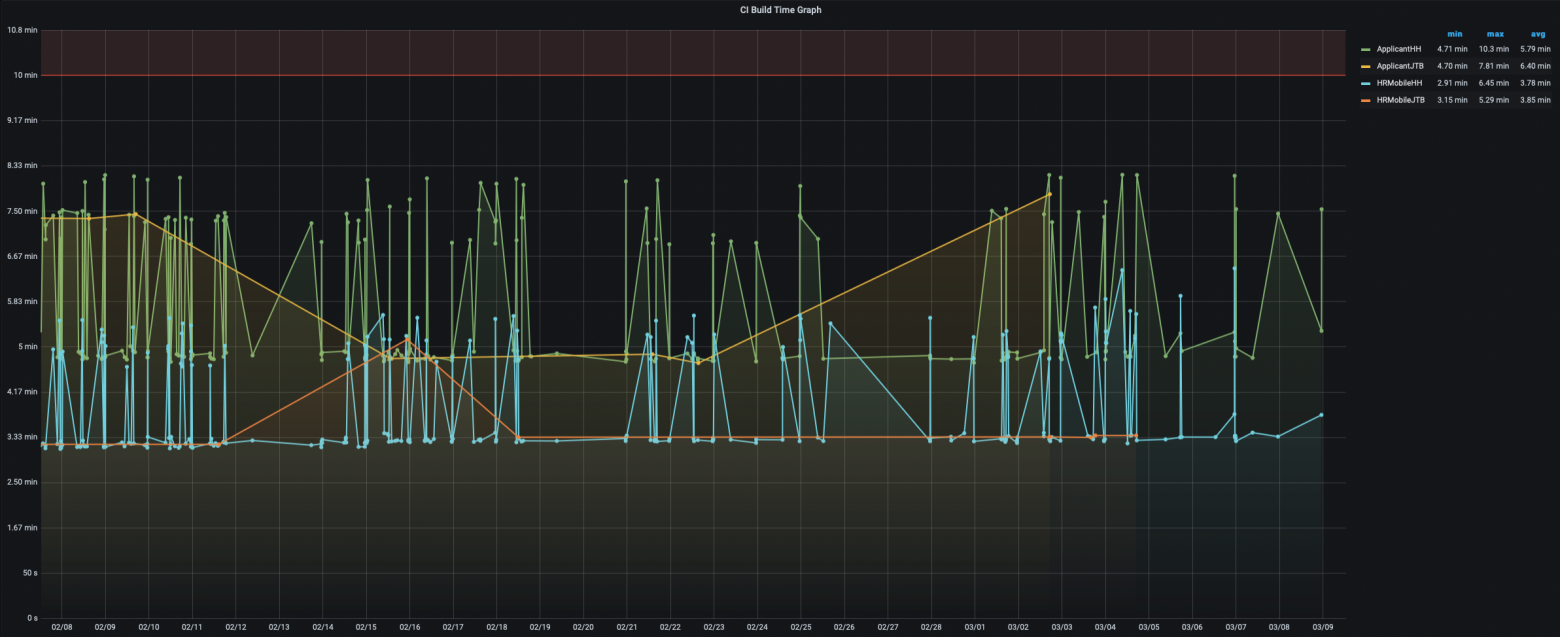
Они немного скачут, но это нормально, потому что у нас сейчас на CI два разных типа машин: на процессорах Intel и M1. Машины на M1, конечно, собирают проект шустрее. Эти графики мы не просто смотрим, они позволяют нам находить проблемы в конфигурации наших проектов. Больше подробностей об измерении скорости сборки можно почитать в этой статье.
Настройка окружения
Очевидный момент. Если в репозиторий попал коммит с каким-то багом, этот баг должен одинаково воспроизвестись: как машинах разработчиков, которые подарили багу жизнь или собираются его фиксить, так и на CI. Соответственно, если баг починили, то и фикс должен одинаково долетать и до всех разработчиков, и до CI.
Это нас подводит к мысли о том, что окружение проекта должно быть воспроизводимым и одинаковым, чтобы не было жизненных историй, когда кто-то пишет в чат, что у него баг, и приложение не собирается, а ему отвечают «WORKSFORME».

Чтобы избежать подобных ситуаций, у нас есть небольшой лайфхак. Например, помимо самого свифтового кода и самого приложения, наш проект состоит из кучи всяких инструментов. Ruby, Fastlane, Danger - для CI, зависимости приложений, которые мы устанавливаем через Carthage, а также свифтовые утилитки, устанавливаемые через Mint.
Если устанавливать, настраивать и запускать все эти штуки вручную, то можно немножечко помереть. Получается, что разработчику нужно помнить о куче каких-то инструментов и знать, как и в какой последовательности они устанавливаются, чтобы ничего не сломалось. А если нужно что-то обновить – это вообще отдельная история.
Мы пришли к тому, что нам нужен единый скрипт для настройки всего окружения. И написали его:
#!/bin/sh set -e readonly script_path="$( cd "$( dirname "$0" )" && pwd )" readonly bootstrap_path="${script_path}/Bootstrap" readonly start_time=$SECONDS "${bootstrap_path}/welcome.sh" "${bootstrap_path}/macos.sh" "${bootstrap_path}/homebrew.sh" --update --verify "${bootstrap_path}/rbenv.sh" --update --verify "${bootstrap_path}/ruby.sh" "${bootstrap_path}/bundler.sh" --update "${bootstrap_path}/libpq.sh" --update "${bootstrap_path}/allure.sh" --update "${bootstrap_path}/gemfile.sh" "${bootstrap_path}/xcode.sh" "${bootstrap_path}/copy_resources.sh" "${bootstrap_path}/mint.sh" --update "${bootstrap_path}/mintfile.sh" "${bootstrap_path}/cartfile.sh" "${bootstrap_path}/check_github_token.sh" "${bootstrap_path}/analyticsgen.sh" "${bootstrap_path}/tuist.sh" --update "${bootstrap_path}/dependencygenerator.sh" "${bootstrap_path}/project.sh" "${bootstrap_path}/congratulations.sh" elapsed_time=$(($SECONDS - start_time)) echo "Total time taken: $((elapsed_time/3600)) h $(((elapsed_time%3600)/60)) min $((elapsed_time%60)) sec"
Он последовательно устанавливает все необходимые зависимости проекта, настраивает окружение проекта и делает всё, чтобы разработчик не думал об этом и не тратил свое время. Теперь можно скачать репозиторий проекта, запустить наш Bootstrap-скрипт, попить чаек, через какое-то время вернуться, а там уже всё будет развернуто и готово для продуктивной работы. Прелесть этого инструмента в том, что все зависимости и инструменты проекта зафиксированы в нашем репозитории. Проще говоря, репозиторий становится единственным источником правды. И это очень удобно – установить и настроить всю эту среду разработки можно выполнением всего лишь одной команды.
Генерация кода
Следующая история будет про генерацию кода. Один из инструментов, которым мы пользуемся – это Xcode-шаблоны. Я думаю, вы все с ними знакомы. По Xcode-шаблонам масса полезных статей в интернете. И они довольно хорошо решают свою задачу. Единственный минус – довольно сложная настройка. И если вы добавляете разные условия при генерации шаблона, то он просто многократно усложняется. А еще у него неприятный синтаксис. Ну вы знаете.
Тем не менее, Xcode-шаблоны довольно хороши для каких-то небольших групп или отдельных файлов. Они удобны и доступны прямо из стандартной менюшки Xcode. Это позволяет не переключаться на какие-то другие программы, не выпадать из контекста и быстренько создавать небольшие файлы, которые нужны. В нашем проекте есть несколько шаблонов для таких целей, например, для MVVM-модулей. Также есть набор маленьких шаблонов для: генерации моделей, аналитики и файлов вьюшек, дизайн-системы и так далее.
Следующий инструмент – снова Tuist, который предоставляет команду для генерации файлов - scaffold. Он довольно удобен для создания больших групп файлов и иерархии папок. Мы используем его для генерации новой фичи. Новая пустая фича, на самом деле, содержит довольно много кода. Она сразу выстраивает необходимую иерархию папок, чтобы разработчик мог сгенерировать всё необходимое и сразу перейти к выполнению своей задачи. Вот так может выглядеть конфигурация шаблона, описанная в Tuist:
let nameAttribute: Template.Attribute = .required("name") let template = Template( description: "Custom template", attributes: [ nameAttribute, .optional("platform", default: "ios"), ], items: [ .string( path: "Project.swift", contents: "My template contents of name \(nameAttribute)" ), .file( path: "generated/Up.swift", templatePath: "generate.stencil" ), .directory( path: "destinationFolder", sourcePath: "sourceFolder" ), ] )
Здесь есть возможность как генерировать отдельные файлы через stencil-шаблоны, так и просто указывать напрямую строку, которая должна быть в контенте этого файла. Словом, для нас здесь есть всё необходимое, чтобы создать новую фичу.
Еще в нашем проекте мы используем SwiftGen для генерации кода и доступа к ресурсам, например, к картинкам или строкам локализации. Кстати, про то, как мы настраивали SwiftGen, у нас есть довольно старая, но, кажется, всё ещё актуальная статья на Хабре. Для всего остального мы используем Sourcery. Sourcery позволяет нам генерировать, например, моки для Unit-тестов и всякие разные мелочи по проекту, о которых сложно рассказать. Но выручает оно неимоверно.
Итоги
Tuist упрощает работу с проектом: как в плане генерации самого проекта, так и в создании новых фич. Мы постоянно замеряем скорость сборки, это позволяет нам видеть проблемы как только они появляются. Мы стараемся не собирать весь проект целиком – собираем только необходимое в данный момент, благодаря тому что проект разбит на фичи. Ну и, конечно, мы автоматизируем разработку и настройку фичей, чтобы разработчики не тратили время на рутину.
На этом всё! Пишите в комментариях о своем опыте работы с большими проектами, и задавайте любые вопросы.

