
Зачем создавать процесс разметки данных на основе ML?
Быстрое создание высококачественной разметки данных — сложная задача. Парсинг и правильное аннотирование изображений и видео, обычно используемых в сфере беспилотного транспорта или робототехники, могут быть композиционно сложны даже для людей. Наша компания использует машинное обучение, чтобы дополнить реализуемые людьми рабочие процессы, позволяя повысить и качество, и скорость разметки. Так как модели глубокого обучения могут испытывать трудности с устойчивой производительностью в предметных областях с большим разнообразием данных, например, в сценах с участием беспилотных автомобилей, для обеспечения стабильно высокого качества необходимо найти оптимальный баланс между ML-автоматизацией и человеческим контролем.
Autosegment — это инструмент на основе ML, способный точно сегментировать экземпляры объектов в создаваемых людьми ограничивающих прямоугольниках, что позволяет нам делегировать высокоуровневый анализ семантики и классификации сотрудникам (живым разметчикам), а попиксельную обработку — ML-модели. Такое разделение труда позволяет нам разрабатывать универсальный и точный инструмент ML-разметки. Несмотря на использование простой нейросети, Autosegment превосходит по показателям старые инструменты.
Задача разметки семантической сегментации
При семантической сегментации живые люди распознают и размечают каждый пиксель в визуальной сцене, это долгий и монотонный процесс. При такой ручной работе основная часть рабочего времени (около 95%) тратится на кропотливую работу, например, аккуратную обводку контуров объектов в сцене. Например: для обводки контура автомобиля требуется примерно одна минута, а чтобы нажать на этот контур и выбрать метку «Car», достаточно трёх секунд. Что если бы вместо этого мы могли использовать машинное обучение для автоматизации самых трудоёмких аспектов семантической сегментации? Что если ML-модель выполняла бы семантическую сегментацию, а сотруднику было бы достаточно выбрать нужную метку?
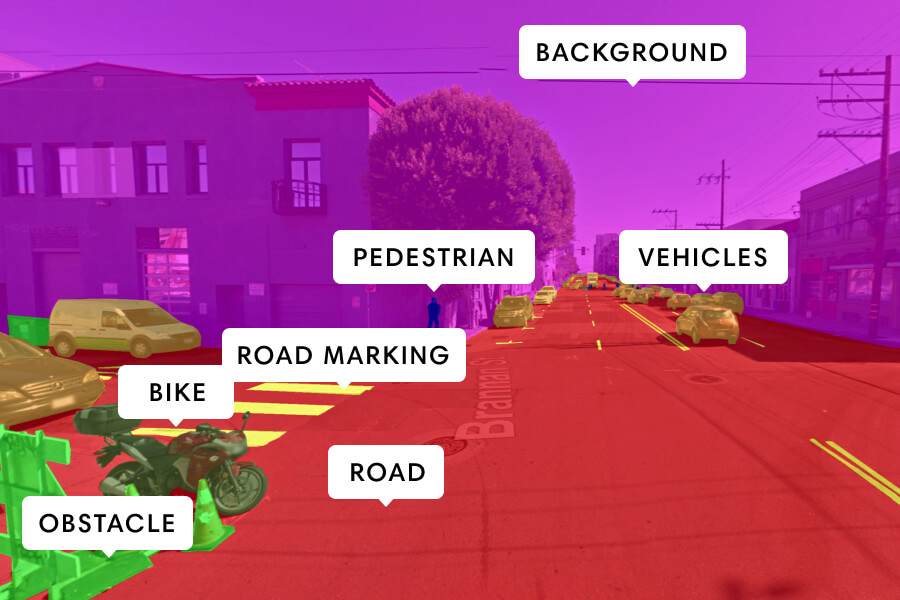
Семантическая сегментация графической сцены. Каждый пиксель закодирован цветом, обозначающим класс его объектов, например, Pedestrian (пешеход), Road (дорога), Bike (мотоцикл) и т. д.
Мы, ML-инженеры, для определения качества наших моделей активно используем метрики на валидации, например, accuracy и intersection-over-union (IoU). Однако при построении моделей, выполняющих оптимизацию под определённый бизнес-результат, например, для уменьшения времени семантического сегментирования изображений живым сотрудником, нам необходимо критически подумать, какую модель использовать и как измерять её точность.
В этом примере наша цель заключается в создании предсказаний для упрощения работы сотрудников. Она необязательно совпадает с «наилучшей производительностью модели». Например, модель сегментации экземпляров может постоянно неточно сегментировать несколько пикселей вокруг объекта. Такая модель может иметь высокое значение метрики IoU, но обладать очень низкой практической полезностью, потому что живым сотрудникам придётся переделывать каждую линию контура.
И наоборот, модель, способная идеально сегментировать объект, даже если она при этом идентифицирует его половину, всё равно будет чрезвычайно полезной. Несмотря на меньшее значение валидации IoU, она станет улучшением для всего процесса. Так как обводка контуров вручную настолько длительна, наличие модели с попиксельно точными частичными контурами значительно сэкономит время.
Парадигма активного инструментария и Autosegment
Autosegment — это инструмент машинного обучения, сегментирующий наиболее заметный объект в созданном человеком прямоугольнике. В процессе аннотирования он гибким и итеративным образом включает в себя обратную связь от сотрудников.
Ещё на ранних этапах разработки Autosegment мы поняли, что единственный способ обеспечения гибкости и высокого качества заключается в представлении сотрудникам доступа к Active Tools.
Active Tools позволяют людям в реальном времени вносить изменения во входную информацию и параметры модели, чтобы генерировать наилучшие результаты для конкретного случая использования. Это схоже с «prompt engineering» — процессом, благодаря которому мы можем заставить нейронную языковую модель наподобие GPT-3 генерировать нужный текст при передаче ей точных указаний. Подробнее о создании указаний для модели GPT-3 можно прочитать в превосходной документации OpenAI.

Люди, работающие совместно с моделями, могут создавать более качественные результаты быстрее, чем модели в одиночку
Благодаря Active Tools мы предоставляем сотрудникам максимальное количество опций. чтобы упростить их задачи. Например, они могут настраивать форму прямоугольника для аннотирования и пороговое значение предсказательной уверенности, чтобы сконфигурировать модель для ускорения выполнения конкретной задачи разметки.
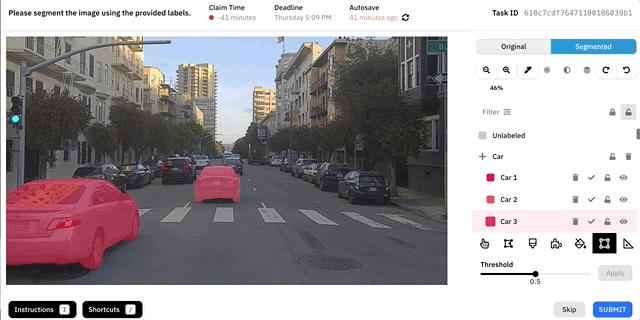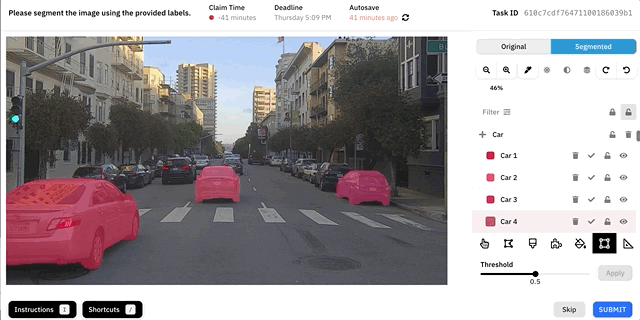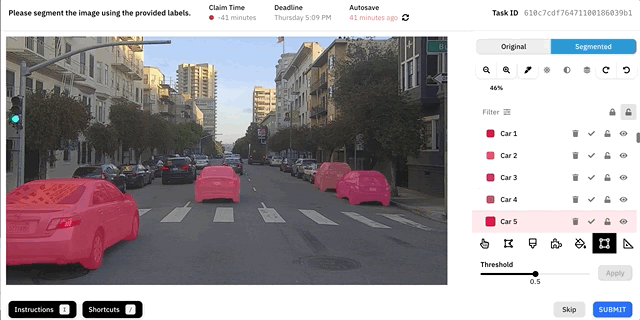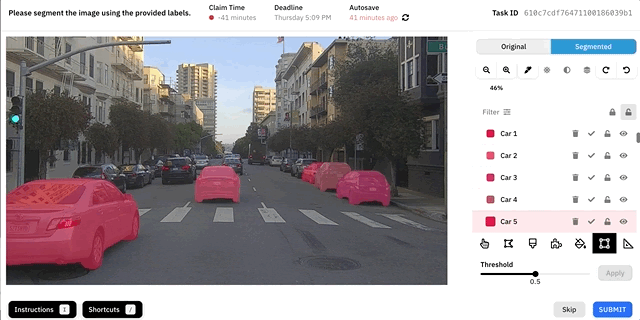
Демо инструмента Autosegment.
Обеспечение возможности свободного исследования людьми пространства вывода модели является важнейшим преимуществом активного инструментария. Мы уже были свидетелями того, насколько это полезно.
В целом мы заметили, что при использовании Autosegment медианное время аннотирования сцены уменьшается на 30%. Также мы опросили сотрудников, чтобы узнать, как они используют инструмент. Хотя наша модель обучена сегментировать легковые автомобили и мотоциклы, один сотрудник использовал инструмент для сегментирования всего. Мы не предусматривали такого рабочего процесса, однако это вдвое сократило его время на сегментацию каждой сцены, с 40 до 20 минут. В разговоре с пятью сотрудниками выяснилось, что они считают Autosegment более точным и эффективным, чем предыдущие ML-решения. Теперь мы можем просто предоставлять надёжные и обобщённые онлайн-модели, позволив живым сотрудникам оптимизировать всё остальное.
Модель Autosegment
Autosegment — это свёрточная нейросеть, обученная сегментировать наиболее заметный экземпляр объекта в пределах указанного человеком ограничивающего прямоугольника. Такая простая структура позволяет нам значительно снизить операционные расходы наших клиентов по внедрению ML, в то же время обеспечивая идеально точную сегментацию экземпляров объектов даже в случае типов экземпляров, никогда не виденных моделью ранее.
Для создания убедительных результатов модели Autosegment необязательно быть особо сложной. Autosegment не имеет понимания различных семантических типов, вместо этого он абстрактно идентифицирует и сегментирует экземпляры на основании композиции сцены.
Модель обучена всегда генерировать сегментацию. Данные обучения содержат несколько ключевых классов, например, пешеходы и транспорт. Задача бинарна; модель просто определяет, принадлежит ли каждый пиксель к самому заметному объекту. Мы не обучаем модели на отрицательных выборках, для генерирования сегментации она делает наилучшую догадку для каждого пикселя.
Самым заметным экземпляром считается объект, которому принадлежит центральный пиксель выделенной области, поэтому даже если сцена переполнена объектами, модель может идентифицировать экземпляр, который нужно сегментировать. Эта бинарная задача сегментации для разных классов и типов экземпляров позволяет модели хорошо обобщать предсказания на новые классы и классификации. На самом деле, мы можем переносить предсказания не только между объектами одного класса, например, между легковыми автомобилями в разных странах, но и между совершенно разными классами, например, от автомобилей к мотоциклам, а затем к дорожным знакам. Такой перенос можно обеспечить частичным переобучением или, в некоторых случаях, вообще без него.

Несмотря на то, что эта модель обучается только на образцах транспорта, обычно она может быть полезна в широком спектре задач сегментации.
Использование распознавания заметных объектов на конкретных участках сцены может генерировать ещё более точную сегментацию. Нам удалось удвоить коэффициент точности распознавания границ (с 0,26 до 0,52) по сравнению со стандартными моделями семантической сегментации целой сцены.
Нейронной сети передаётся не уменьшенная версия целого изображения, а выбранная область в полном разрешении. Так как входные данные меньше, для получения глобального рецептивного поля требуется меньше операций пулинга. В результате получается меньше даунсэмплинга и размытия. Наша модель достигает большей чёткости на границах экземпляров, а это очень критично для обеспечения высококачественных аннотаций данных для наших клиентов. Улучшение до того же уровня разметки всей сцены требовало бы экспоненциально больше усилий и сложности.
Итак, мы разработали активный инструментарий для создания рабочего процесса на основе ML, способного решать простые задачи машинного зрения. Этот процесс помогает нашим сотрудникам достигать более высоких уровней качества быстрее, чем при предыдущих рабочих процессах.
Autosegment и подобные ему инновации критически важны для достижения «закона Мура в разметке данных». Автоматизация разметки раздвигает границы взаимодействия человека и ИИ для компаний.
Понравилась статья? Еще больше информации на тему данных, AI, ML, LLM вы можете найти в моем Telegram канале.
- Как подготовиться к сбору данных, чтобы не провалиться в процессе?
- Как работать с синтетическими данными в 2024 году?
- В чем специфика работы с ML проектами? И какие бенчмарки сравнения LLM есть на российском рынке?

