RFM - классический инструмент маркетинга для сегментации вашей клиентской базы. Я использую ее для работы в В2В, В2G сегменте. В основе него - понятные управленцу ценности: LTV и Purchase Frequency.
Как можно применять этот инструмент:
Посчитать отток клиентской базы
Найти клиентов в оттоке - самых крупных заказчиков, которые, почему-то, раньше покупали часто и много, а потом - перестали. В первую очередь, важно выяснить причину оттока и попытаться вернуть именно этих партнёров.
Определить ключевых заказчиков - которые покупают много, часто и давно. Этот сегмент самых лояльных пользователей можно использовать для опросов, создания совместных кейсов использования вашего продукта или услуги, воспитания адвокатов бренда, да и просто для укрепления дружественных связей - например, приглашения на мероприятия.
Определить сегмент пользователей, которые делают заказы часто и давно - работа с таким сегментом будет заключаться в попытках поднять средний чек - возможно, не обо всех продуктах и услугах компании известно этим пользователям.
Методология RFM вполне простая: исследователю нужно присвоить каждому заказчику степень «1», «2», «3» в зависимости от :
общей суммы отгруженных заказов (предоставленных и оплаченных услуг) за весь период работы с контрагентом. За нее отвечает показатель Monetary (M)
частоты заказов – Frequency (F)
насколько недавно была совершена последняя сделка – Recency (R)
Степеней может быть больше – это будет зависеть от того, насколько данные однородные. Какие могут встречаться комбинации в RFM:
R=3, F=1, M=1 = заказчики с самым высоким LTV и высокой частотой заказов, которые делали последний заказ давно, находятся в оттоке. Такие контрагенты требуют экстренных мероприятий по выявлению причин оттока и попыток вернуть клиента
M=1, F=1, R=1 = потенциально опинион-лидеры, адвокаты вашего бренда. Также полезно изучить качественный состав таких контрагентов при большом количестве сегментов целевой аудитории в вашей базе
M=2/3, F=1, R=1= в таком сегменте здорово проводить мероприятия, направленные на увеличение среднего чека
Большинство маркетологов, проводя это исследование, используют выгрузку из своей CRM и проводят сортировку в Excel. Такой подход имеет серьезные недостатки:
Отсутствует простое и быстрое решение исследования однородоности данных. Например, у 5% ваших заказчиков LTV может составлять более нескольких миллионов рублей (маржинальную прибыль вы рассматриваете или общий доход – не так важно), а у остальных 95% заказчиков – составлять менее нескольких сотен тысяч рублей. В такой ситуации «просто поделить базу на 3 сегмента» не получится
Excel работает очень медленно с большим массивом данных (в представленном мною примере мы изучали базу контрагентов производственной компании Первый Профильный Завод, состоящую из 3480 компаний)
Отсутствует простое и быстрое решение визуализации данных (в Python это реализуется в пару строк), визуализация понадобится нам для прогнозирования спроса, выявления тренда и сезонности (может, напишу материал об этой методологии исследования спроса и расскажу о своих попытках применить модели временных рядов, ARIMA и SARIMA на Python).
Я использую в работе Jupiter Notebook, библиотеки Python Numpy, Pandas, Matplotlib. Поехали.
В первую очередь мне понадобилось выполнить предобработку данных непосредственно в Excel и привести выгрузку из 1С к виду:
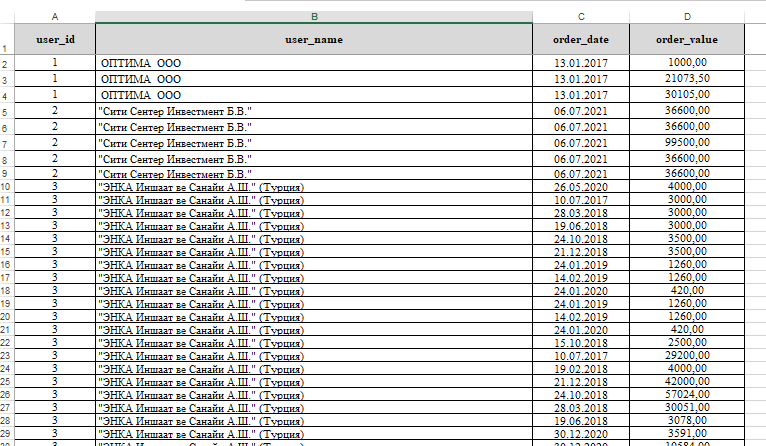
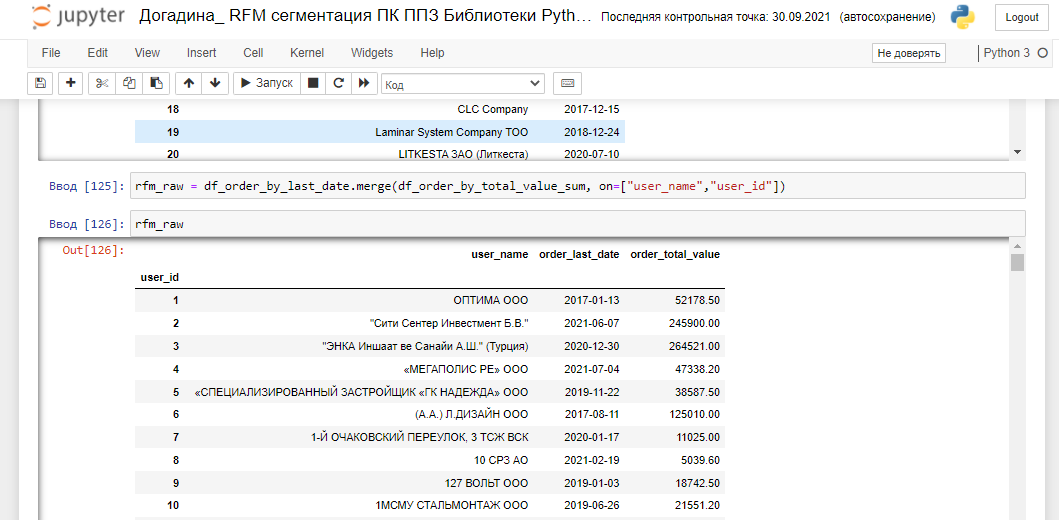
В таблице представлены уникальные наименования контрагентов, даты и суммы всех их заказов за весь период сотрудничества. Уникальный User_id присваивается каждому уникальному наименованию ООО. Если вы – начинающий пользователь Python, обратите внимание на названия колонок таблицы – мы будем использовать их в коде. Мои комментарии к процессам работы вы найдете на скринах после ''#’ символа.
После выполнения предобработки данных, сохраним файл и скопируем путь к нему, откроем новый проект в Jupiter Notebook и импортируем необходимые библиотеки. Откроем файл с данными - наименование компании, id компании, даты заказов компании и суммы заказов. Библиотека Datetime понадобится нам для того, чтобы преобразовать строковый тип данных в дату и посчитать дельту дней между сегодняшним днём и последней датой заказа каждого контрагента.
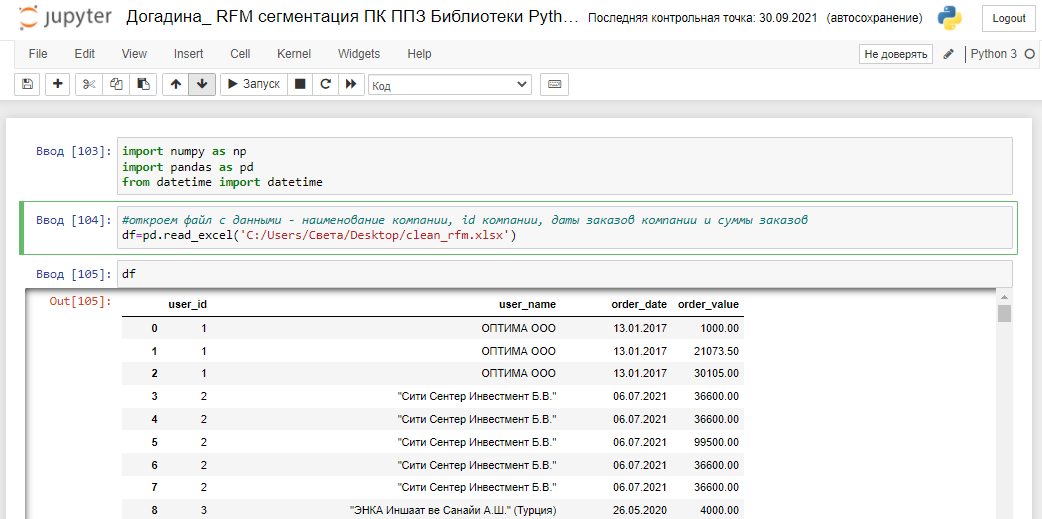
Обращу внимание на принципы работы с датафреймами, которые помогут серьёзно сократить вам время исследования и избежать моих ошибок:
Обязательно пересохраняйте или создавайте новый датафрейм после преобразований.
Проверяйте количество строк в датафрейме после того, как задали индексы или соединили датафреймы методом merge
Переименовывайте колонки после выполнения преобразований над ними, это поможет не запутаться.
Далее мы должны преобразовать строковый тип данных в дату и найти частоту заказов Frequency (частота заказов будет совпадать с количеством упоминаний уникального user_id), это можно выполнить с помощью следующего кода:

Выполняем преобразования датафреймов по индексу:

Вызываем волшебный инструмент, который исследует однородность данных. Функция describe оценивает столбцы с числовым типом данных и возвращает статистические данные, которые дают представление о распределении значений.
Можно отметить значительную разницу между максимальным количеством заказов по контрагенту и 99% процентами других контрагентов, вероятно, контрагентов с количеством заказов 50-1255 стоит выделить в отдельный RFM сегмент или имел место некоторый выброс данных (например, как в нашем случае, компания вешает весомую часть заказов за наличный расчёт на одного контрагента с общим уникальным наименованием и user_id):

Понятно, почему после исследования методом describe таблицы с частотой Frequency, мы обнаружили, что 80% контрагентов делали заказы 5 и менее раз - это связано с ростом количества новых клиентов в последний год.
Найдем общую сумму заказов по каждому контрагенту (LTV по общему доходу):

И переименуем колонку, чтобы избежать путаницы:
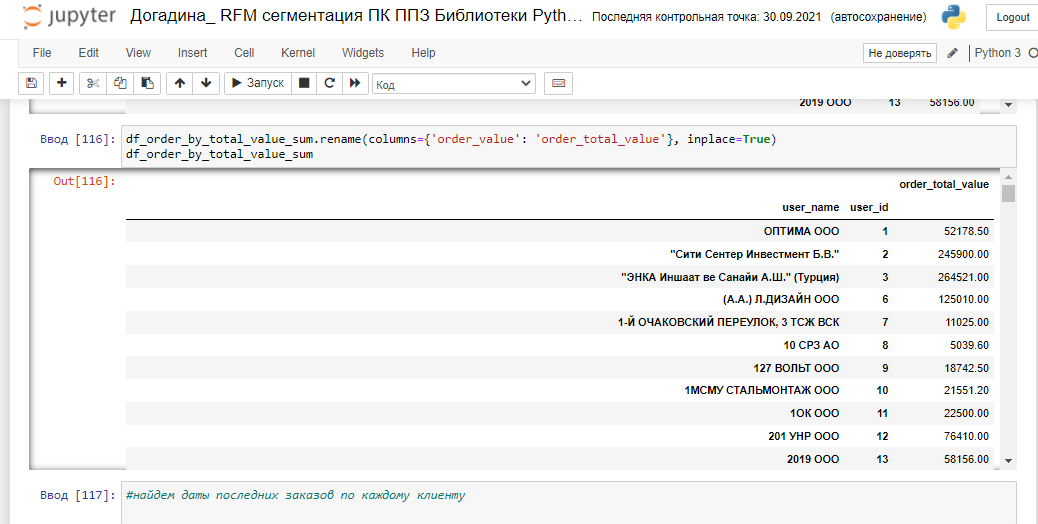
Найдем даты последних заказов по каждому контрагенту, чтобы описать показатель Recency:

Периодически я проверяю количество строк в получившемся датафрейме, чтобы избежать потери данных после неправильного преобразования индексов (своего рода самопроверка). Опять переименуем колонку, чтобы понимать, что мы получили в результате исследований дату именно последней отгрузки:

и удалим из датафрейма более не нужную нам колонку order_value:
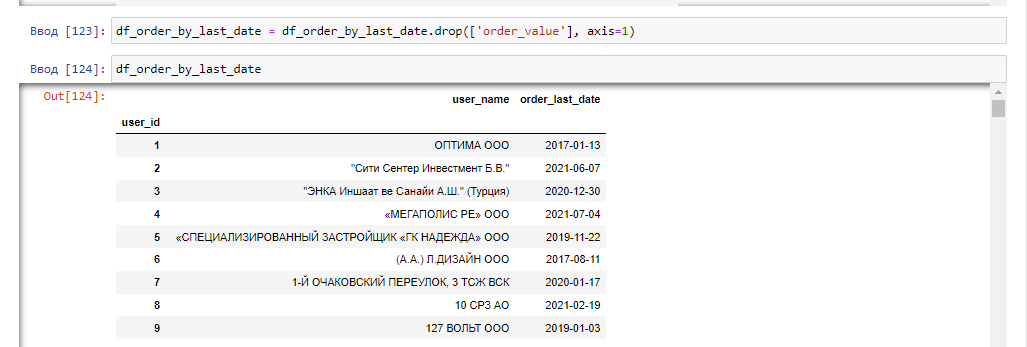
Объединим два датафрейма - с LTV контрагента и датой его последней отгрузки по user_name и user_id:
Используйте форматирование для того, чтобы оставить только два знака после запятой в столбцах с суммами, если того требует вашу чувство прекрасного и размеры монитора. Попробуем описать таблицу, получившуюся после слияния:


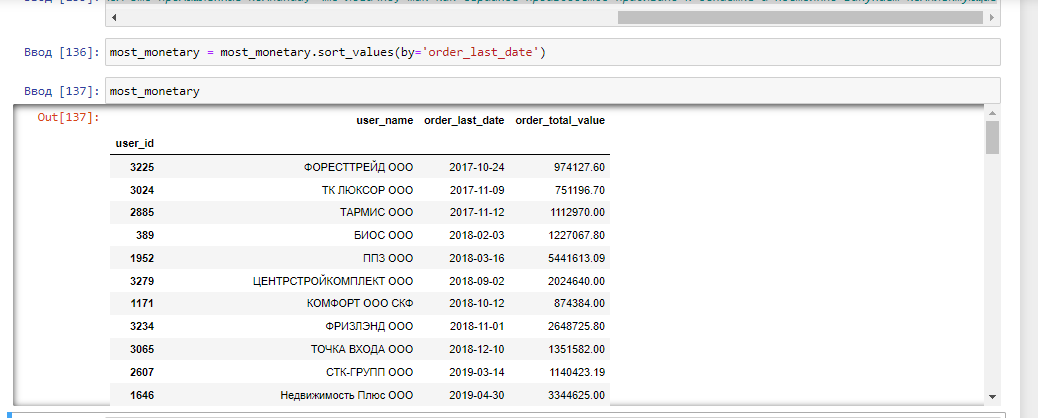
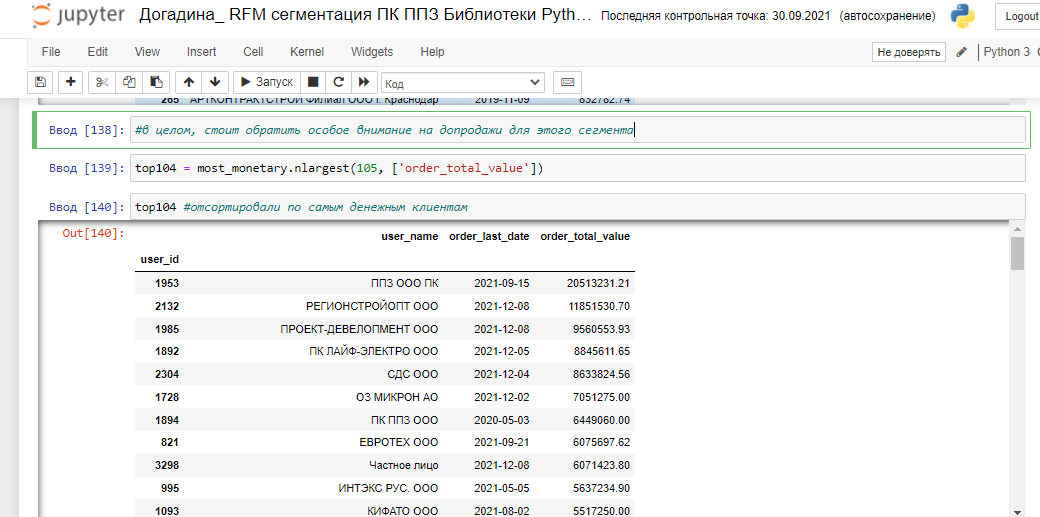
Можно увидеть значительную разницу между максимальной суммой всех заказов одного покупателя и 97% остальных контрагентов, это может потребовать дополнительного изучения, стоит помнить об этом при RFM сегментации, скорректировать персентиль и изучить список контрагентов с самым высоким LTV. Такую картину можно наблюдать еще, если, например, все отгрузки за расчет по кассе вы кидаете на одного контрагента с общим уникальным наименованием - "Частное лицо", например. По - хорошему стоит избавиться от такого выброса данных. Пока я не нашла оптимального способа подбора персентиля для исследования однородности распределения данных и просто подбираю его вручную, в зависимости от амплитуды полученных значений. Клиентов с общей суммой всех отгруженных заказов свыше 716252.17 пока попробуем выделить в отдельный RFM сегмент most_monetary. Вызвав .shape, можно найти сразу, что количество таких контрагентов - 104 шт.

Сегмент most_monetary состоит из 104 клиентов, отсортируем его по последней дате заказа, чтобы выделить клиентов, которые требуют действий для возвратности. Можно отметить, что в основном это заказчики - промышленные компании, а не строительные, что логично, так как серийное производство привязано к OEM-подряду и регулярно закупает комплектующие. Таким образом, теперь мы можем доказать собственнику, что самый важный сегмент (most_monetary) для расширения клиентской базы - именно промышленные компании, несмотря на то, что основную часть оборота составляют строительные материалы, а основную часть базы контрагентов - строительные компании:
Найдем, сколько клиентов делали свой последний заказ более 730 дней назад (6 месяцев, в среднем, по моим подсчетам, составляет цикл сделки в сфере Первого Профильного Завода: В2В, В2G производства комплектующих и строительства, далее вы поймете, почему я выбрала 730 дней для описания пользователей в оттоке - будет страшная история о несостоятельности гипотез. . ). Во время работы я сохранила данные и о пользователях, которые делали последний заказ более полугода назад, и о тех, кто делал последний заказ более года назад, приведу только пример с 730 днями:
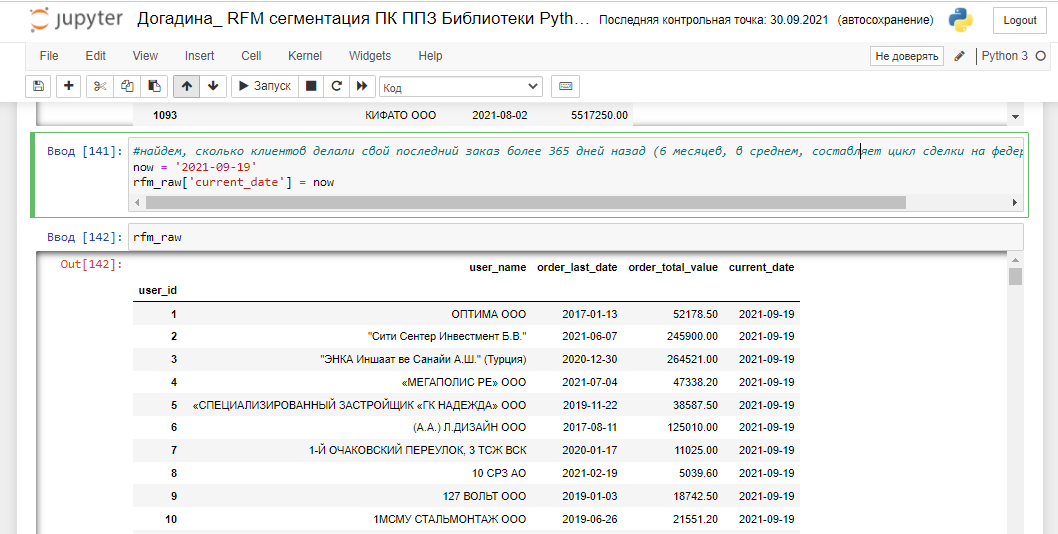
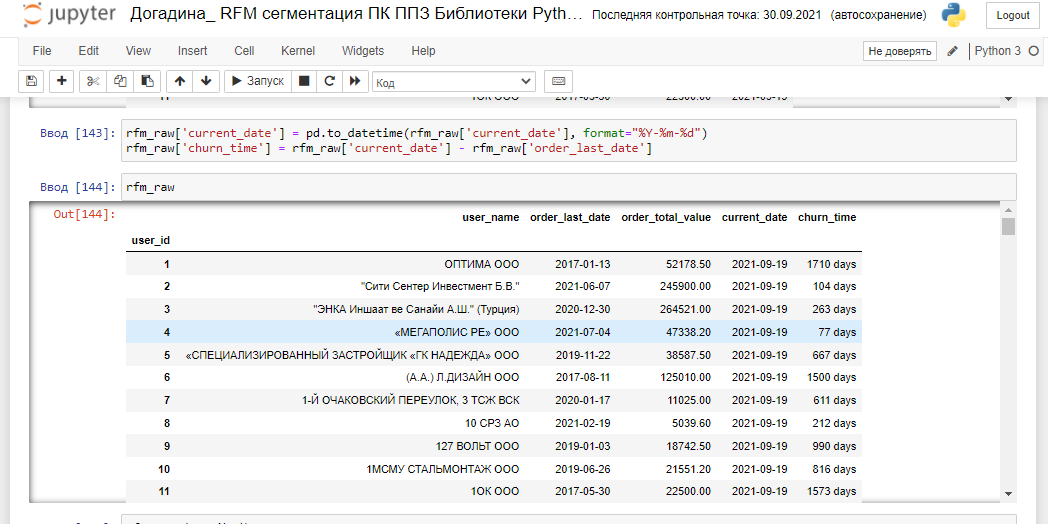
Колонка churn_time покажет, сколько дней назад последний раз был отгружен заказ. Так мы сможем найти контрагентов в оттоке. Исследуем и эти данные на однородность. 50% пользователей делали последний заказ в промежутке между 705 и 1721 днями назад последний раз. Какой-то вопиющий процент оттока, подозрительно:

При первом рассмотрении данных возникла такая гипотеза: что госконтракты - разовые сделки для ООО , некоторые открывают ООО и ИП конкрентно под госпоставки, отсюда и отток.
Я уже собралась проводить опрос среди этих 50% контрагентов, чтобы определить причину отказа от сотрудничества, но меня вовремя остановили собственники - оказалось, что большинство из этих контрагентов были просто перенесены в базу из базы бывшей головной компании, чьими дилерами мы были до запуска своих производственных мощностей. Такой вот Data Science. Опять же, стоит исключить всех таких контрагентов из нашей базы и очистить RFM, но для моделирования пока будем использовать эту базу, присвоив ей статус "сферического коня в вакууме".
Отсортируем пользователей в оттоке по сумме заказов:

Добавили данные по частоте заказов и выбрали оттекших пользователей более 730 дней назад :


Мне нужно было изучить и видеть все строки и колонки данных в этом датафрейме, так что вот волшебная кнопка:

Эти данные - контрагентов с последней датой заказов, частотой заказов и общим LTV и днями пребывания в оттоке уже можно было бы сохранить в виде таблицы, удалив ненужную колонку с информацией по current_date, которую мы использовали для "вычитания" дат.
Таким образом, мы создали базовые коды для быстрой аналитики клиентской базы Первого Профильного Завода для отдела продаж, можем найти клиентов с наибольшим общим доходом в оттоке и сформировать для них персональное предложение, провести опрос по причинам оттока. Приступим непосредственно к RFM-сегментации. Добавим коэффициент значение Monetary, учитывая то, что всего лишь 3% от всех контрагентов сделали заказов всего на сумму более 716252.51 и распределим по сегментам:
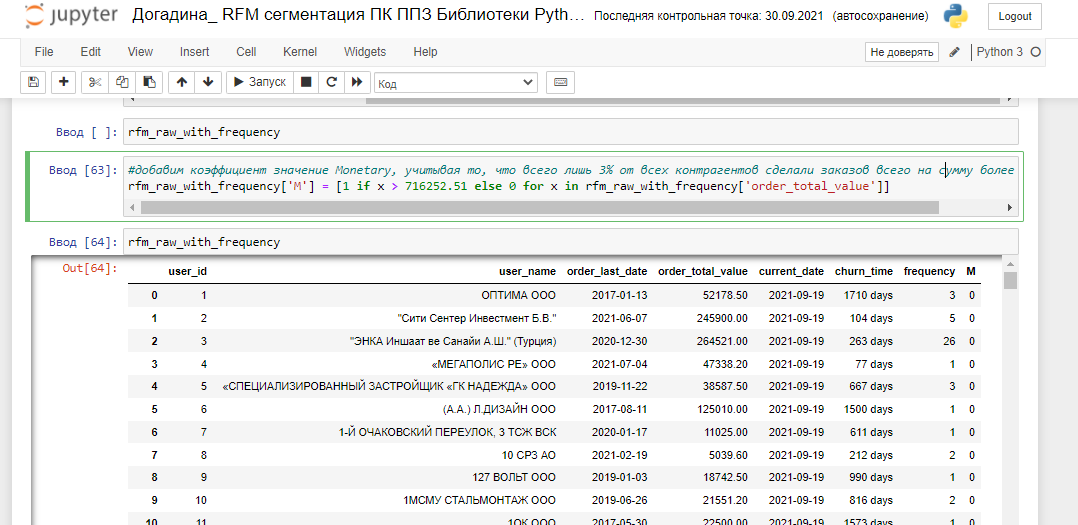
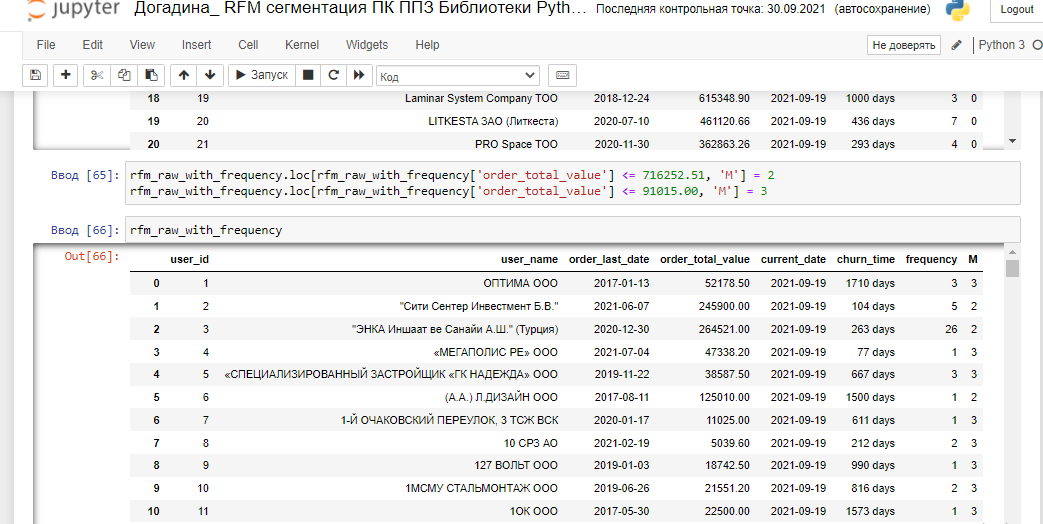
Присвоим индекс количества заказов F (вы помните, что после исследования методом describe таблицы с частотой, мы обнаружили, что 80% контрагентов делали заказы 5 и менее раз):

Добавим коэффициент давности заказа на основе изучения churn time, помня о том, что был значительный рост оборота и прирост клиентской базы в последние 730 дней:
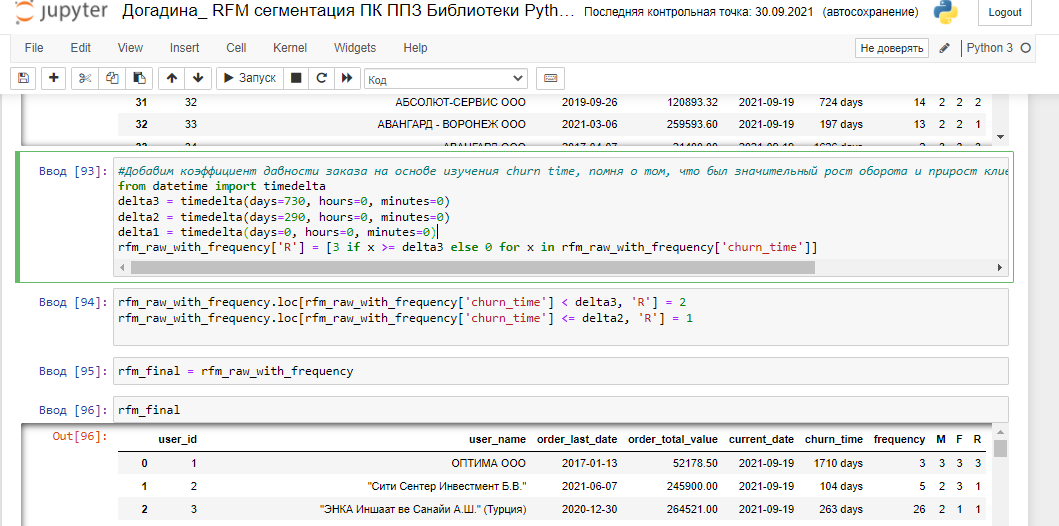
Получили итоговую разбивку по RFM c учетом неоднородности данных клиентской базы:
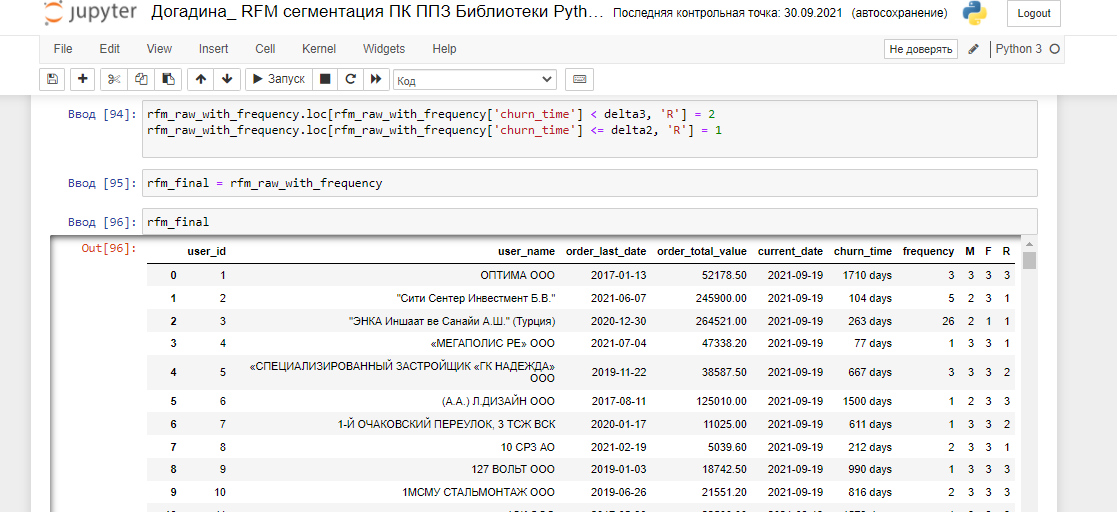
И проведем еще пару полезных манипуляций: Сегмент attention требует изучения причин оттока, одни из самых крупных клиентов с самыми старыми датами последних заказов, которых мы найдем так:
attention_raw = rfm_final.loc[rfm_final ['M'] == 1]
attention = attention_raw.loc[rfm_final ['R'] == 3]
И импортируем их в файл:
attention.to_csv('file1.csv')
Или найдем самых классных, верных и упитанных конрагентов, чтобы премировать их, создавать адвокатов бренда, свозить на море и прочее:
prize_raw = rfm_final.loc[rfm_final ['M'] == 1]
prize = prize_raw.loc[rfm_final ['R'] == 1]
prize_fin = prize.loc[rfm_final ['F'] == 1]
И импортируем их в файл:
prize_fin.to_csv('file2.csv')
Ура, теперь мы знаем, как можно использовать Python для изучения клиентской базы и RFM - сегментации. В будущем я постараюсь показать прогнозирование спроса, выявление его сезонности и тренда с помощью Python. Это мой первый пост на Хабре и первые попытки применить новый для себя инструмент в маркетинговой рутине - я буду очень благодарна за вашу критику и комментарии.
UPD: вы можете написать мне ВКонтакте https://vk.com/korotko_marsianskoe_leto, чтобы получить ссылку на файл .ipynb и датасет.

