

О задаче
Одним прекрасным вечером коллега попросил подумать над алгоритмом поворота серийных номеров на металлических брусках — бруски овальные, серийные номера выбиты на их торцах, и ориентация надписи может быть произвольной (пример на картинке ниже).
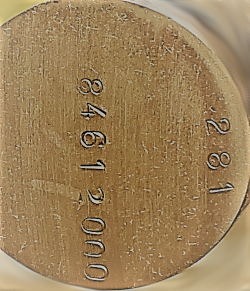
Предполагалось, что если повернуть брусок ��ак, чтобы номер располагался горизонтально, это поможет распознаванию. Один из возможных вариантов поворота придумать несложно, об этом ниже. Но глобально задача предполагала именно распознавание. Ранее задачами OCR глубоко я не занимался, и мне стало интересно, на что способны имеющиеся коробочные решения. Казалось бы, они должны легко решить нашу задачу за час. О том, что было на самом деле, и пойдет речь в этой статье.
Paddle OCR
Одним из самых популярных репозиториев на Github и Papers With Code является PaddleOCR. Обычно OCR-пайплайны сначала детектируют области с текстом, а потом, с помощью так называемого recognizer’a, извлекают текст. PaddleOCR тут не исключение. Единственное усложнение - добавление классификатора ориентации текста после детекции, что позволяет модели отрабатывать на текстах с ориентацией, кратной  (Рисунок 1).
(Рисунок 1).
.")
Сразу перейдем к примерам:
.")
Например, на такой картинке (Рисунок 2) PaddleOCR отлично справился с распознаванием номера 84612000 (confidence 0.98), а 281 не нашел вообще.
.")
А вот на этом изображении (Рисунок 3) нашел:
('612', 0.988)(значение в кавычках - распознанный текст, число рядом - confidence модели, далее результаты распознавания буду предоставлять в таком формате);('C', 0.902);('*8', 0.834).
Получаем лишь куски номеров или вовсе не то, что нужно.
Поворачиваем текст
Окей, PaddleOCR не завелся идеально из коробки, пришлось поворачивать бруски. Идейно подход такой:
сегментируем область с номером, получаем маску. Нестрого говоря, она имеет вид эллипса - то есть вытянута вдоль одной из осей.
Далее через точки маски строится линейная регрессия.
Зная коэффициент наклона прямой, находим угол поворота.

Тест Open Source решений
Для примера в статье возьму часть фотографии, на которой PaddleOCR не отработал, а именно часть фотографии с номером 281 (Рисунок 5)
.")
Подход №1. "В лоб"
PaddleOCR
Тестируем PaddleOCR на повернутом тексте. Ничего не обнаруживается. Кстати, расположение текста мы уже "детектировали" с предыдущего этапа с поворотом номера и возникает вопрос: может быть детектор косячит, и попробовать отдать номер сразу в recognizer?Окей, recognizer что-то распознал, но на номер это не похоже:
('HEi', 0.567).
Tesseract
Возьмем представителя старой школы - Tesseract (python wrapper).
Ожидаемо, он справляется не очень хорошо - ничего не видит.И действительно, Tesseract довольно требователен к входным данным, есть даже отдельный раздел в документации по улучшению данных на входе.
EasyOCR
.")
Рисунок 6. Схема работы EasyOCR (Github).
EasyOCR использует в качестве детектора текста CRAFT, а в качестве recognizer'a - ResNet50 + LSTM + CTC Loss. Реализовано все на PyTorch. Надо сказать, что документации у EasyOCR простая и пон��тная, а recognizer довольно просто дообучить на своих данных.
Но вернёмся к результату на нашем примере. EasyOCR находит что-то более осмысленное:
С детектором видит
('201', 0.728);Без детектора
('3281', 0.237)- нашел даже больше, чем надо.
Замечу, что с настройками по умолчанию, EasyOCR производит вычисления для 4 изображений, повернутых на 0, 90, 180 и 270 градусов. Можно задать свои настройки для углов поворота. Если вы уверены, что текст ориентирован горизонтально,можно указать лишь один угол для экономии времени.
Подход №2. Бинаризация
Как оказалось, для моделей OCR довольно сложно распознавать текст, имеющий сложную форму и структуру (у нас символы состоят из светлых и темных частей за счет преломления света) на произвольном фоне. Попробуем избавиться от фона и минимизировать переливы света на выбитых цифрах за счет бинаризации фотографии. Для примера возьмем всё то же изображение.

PaddleOCR
А вот на бинаризованной фотографии paddle отработал исправно -('281', 0.964)
Recognizer без детектора нашел только('t', 0.541)Tesseract
Still nothing.EasyOCR
EasyOCR с детектором тоже справился -('281', 0.983)
А вот без детектора все еще находит лишнее -('7281', 0.396)(возможно, потому что на нашей фотографии 2 сильно похожа на 7)
Подход №2.1 Инвертированние
В качестве гипотезы, проверили, что будет, если инвертировать бинаризованное изображение так, чтобы текст стал черным, а фон белым - кажется, что модели должны были чаще видеть именно такой формат.

Ниже в таблице приведены результаты моделей на рисунках 6-8.
Таблица 1. Результаты из подходов №1, №2, №2.1.
Модель | Результат подхода №1 | Результат подхода №2 | Результат подхода №2.1 |
|---|---|---|---|
PaddleOCR | _ | ('281', 0.964) | ('8 2', 0.823) |
PaddleOCR (recognizer only) | ('HEi', 0.567) | ('t', 0.541) | ('zal', 0.409) |
Tesseract | - | - | - |
EasyOCR | ('201', 0.728) | ('281', 0.983) | ('8281', 0.354) |
EasyOCR (recognizer only) | ('3281', 0.237) | ('7281', 0.396) | ('7281', 0.199) |
Telegram OCR
Казалось, что современные open source решения должны отрабатывать более стабильно. Поэтому, немного разочаровавшись в результатах, мы решили протестить OCR, встроенный в какое нибудь приложение. Как оказалось, в Telegram для iOS есть встроенный OCR, о котором узнали случайно, просто пересылая фотографию. Загрузили нашу картинку в "телегу" и опа! - он нашел "281" и для оригинальной фотографии, и для бинаризованной версии, а вот для инвертированной версии тоже выдал нечто - "2. 8 Fa" (хотя с "2. 8" можно согласиться).
Выводы и варианты улучшения распознавания
Данная статья не претендует на какую-либо серьезность, скорее показывает на что можно расчитывать, запустив практически втупую современные коробочные решения на вашей задаче.
Как и следовало ожидать, решения из коробки не дают отличных результатов на специфичных задачах. Без "докручивания" кастомными алгоритмами обойтись сложно.
Скорее всего, модели в обучающей выборке видели не очень много выдавленных в металле цифр, и fine tuning моделей должен сильно улучшить результаты - эксперимент с бинаризацией это подтверждает. C другой стороны, Telegram справился, то есть существуют модели, которые "могут".
Возможно, для конкретно такой задачи использованные модели OCR это overkill и следует использовать детекцию каждой отдельной цифры.
