Всем привет! Меня зовут Антон Расковалов и мы с командой отдела перспективных исследований «Криптонит» решили проверить, можно ли использовать Google Coral в решении наших задач. Приобретённым опытом делюсь в статье ниже.
Сейчас нейронные сети пытаются использовать все и практически везде. Их количество растет, а сфера применения постоянно расширяется. В ряде случаев запуск нейронных сетей на серверах (а то и на суперкомпьютерах) заменяется использованием edge computing — вычислениями «на краю» сети. Данный подход подразумевает локальное подключение специализированных ускорителей. Как правило, это компактные устройства с интерфейсом USB или PCIe, оптимизированные для быстрого выполнения расчётов, характерных для ИИ-ориентированных задач.
Такие ускорители позволяют использовать обученные нейросети на устройствах, обладающих скромной вычислительной мощностью, а также не имеющих доступа к облачным платформам ИИ. Для реализации граничных вычислений созданы и серийно выпускаются одноплатные компьютеры со специализированными микросхемами (ASIC), которые называют нейро- или тензорными процессорами (TPU — Tensor Process Unit). Среди компактных ускорителей класса Edge AI один из самых производительных — Google Coral. Устройства серии Google Coral доступны в трёх форм-факторах: отладочных плат для разработчиков (Coral Dev Boards) разных размеров и USB-ускорителя, похожего на флэшку (Coral USB Accelerator). Во всех трёх стоит одинаковый тензорный процессор — Google Edge TPU, который ускоряет работу обученных нейросетей (инференс, логические выводы на основе машинного обучения).
«Из коробки» Google Coral поддерживает нейронные сети, созданные с использованием фреймворка TensorFlow. Однако сейчас набирает популярность другой фреймворк — PyTorch. Разработанные в нём нейросети тоже хочется запускать на Google Coral. Если изложить необходимые для этого действия «в двух словах», то это будет звучать так: «сконвертируйте вашу сеть во фреймворк TensorFlowLite и скомпилируйте результат с помощью EdgeTPU Complier». При кажущейся простоте этой формулировки, в реальности всё оказывается не так уж просто. Эта статья поможет оценить, возможно ли перенести вашу натренированную сеть в Google Coral, и как именно это сделать.
Во второй части статьи приведены результаты преобразования разных модельных нейросетей. Исходя из них, можно оценить, какого размера и вида должна быть нейронная сеть, чтобы её успешно скомпилировать для работы в Google Coral.
Google Coral — полезные ресурсы
Информация о том, как работать с Google Coral, рассеяна по различным ресурсам. Официальная документация хотя и достаточно подробная, содержит мало информации об особенностях и ограничениях как самого устройства, так и моделей.
Что есть на официальном сайте:
квантизованные параметры (uint8 или int8);
постоянные размеры тензоров;
параметры модели (такие как bias) постоянны во время компиляции;
не более 3-х внутренних измерений тензоров могут иметь размеры больше 1;
поддерживаются только операции из таблицы.
Упоминаются даже success stories: Пример использования Coral с приложением для фитнеса.
Конвертация и перенос MIRNet. Для переноса пришлось понизить разрешение входного изображения до 64x64.
Что есть на Хабре:
статья с разбором embedded платформ. В ней нет инструкций по конвертации. Автор уверяет, что почти невозможно запустить свою нейронную сеть на Coral. (В этой статье мы попробуем конкретизировать, в каких случаях это всё-таки возможно сделать и как именно).
статья «Как запихнуть нейронку в кофеварку». В комментарии к ней дана работающая цепочка конвертаций. Автор этого комментария написал конвертер OpenVINO -> TensorFlow, который будет использоваться и в этой статье.
Из PyTorch в TensorFlow
Конвертация и компиляция
Задачу, которую мы собираемся решить в этой статье, можно сформулировать следующим образом: пусть есть обученная нейронная сеть в виде скрипта PyTorch с подгруженными весами, необходимо скомпилировать её под Google Coral. Стандартное решение, предлагаемое в интернете, включает конвертацию через промежуточный файловый формат ONNX (ссылка на Github):
Pytorch → ONNX → TensorFlow lite → квантизация (tflite) → Coral
(NB: В любой цепочке конвертации в обязательном порядке содержится операция квантизации – перевод весов нейронной сети в тип данных uint8 или int8. Квантизация необходима для запуска модели на Google Coral. Насколько эта операция влияет на работу нейронной сети после конвертации – вопрос отдельного исследования).
К сожалению, у этого способа конвертации есть недостаток – добавление лишних операций транспонирования. Дело в том, что тензоры в PyTorch как правило имеют формат NCHW (N - число пакетов, C - число каналов, H — высота, W — ширина), а формат тензора в TensorFlow – NHWC. Каждая свёртка (Conv2D слой) в TensorFlow модели требует, чтобы длина и ширина тензора шли перед числом каналов, поэтому конвертеры добавляют транспонирование (Transpose слой) до и после каждой свёртки. Хотя операция Transpose официально поддерживается EdgeTPU, на практике edgetpu_compiler зачастую спотыкается о неё. Кроме того, квантизация модели с многочисленными transpose способна внести дополнительные искажения в веса в дополнение к тем, которые вносятся самим процессом квантизации.
Чтобы избежать этой проблемы существует решение с использованием цепочки конвертации через OpenVINO.
PyTorch → ONNX → OpenVINO → Tensorflow (saved model) → квантизация (tflite) → Coral
Оригинальный текст решения можно найти здесь.
Вам потребуется установить пакеты согласно Приложению 1.
Последовательность действий по конвертации включает:
1) Сохранение PyTorch модели в формате ONNX с использованием метода torch.onnx.export, код:
onnx_filename = "model.onnx" torch.onnx.export( model, # PyTorch Model dummy_input, # Input tensor onnx_filename, # Output filename opset_version=12, # Operator support version input_names=['input'], # Input tensor name (arbitary) output_names=['output'], # Output tensor name (arbitary) do_constant_folding = True )
Здесь «dummy_input» — входной тензор размерности 1xCxHxW. Он может быть заполнен случайными числами, но должен совпадать по размеру и типу данных с входным слоем. Параметр «opset_version» определяет список поддерживаемых операций. На момент написания статьи доступна версия 13, но эксперименты показали, что лучший результат дают версии 11-12.
Важные замечания:
Google Coral не поддерживает функцию активации LeakyReLu. Практика показывает, что без особых потерь её можно заменить на ReLu. Либо можно воспользоваться обобщением LeakyReLU, функцией PReLu.
ONNX не поддерживает слои InPlaceABNSync, их необходимо заменить на BatchNorm2d + функцию активации, не забыв скопировать веса. На исследованных сетях такая замена InPlaceABNSync даже ускоряла их работу, не затрагивая результата.
2) Упрощение модели с использованием onnx simplifier.
Эта процедура существенно упрощает архитектуру нейронной сети: находит избыточные операции, минимизирует ветвления, заменяет целые структурные блоки на более простые, если это возможно. Если необходимо, заменяет веса в модели на эквивалентные. Иногда без этой операции невозможно выполнение следующих стадий.
Выполняется командой:
python3 -m onnxsim <model filename> <optimized model filename>
3) Конвертация из ONNX в OpenVINO. Эта стадия нужна чтобы перейти от NCHW формата Pytorch в NHWC формат TensorFlow и избежать добавления излишних операций транспонирования.
Выполните в командной строке:
mo --input_model < optimized model filename> --output_dir <directory name>
4) Конвертация из OpenVINO в saved model (формат хранения нейронных сетей для TensorFlow). Для этого используется проект openvino2tensorflow, разработанный автором этого комментария на Хабре.
Выполните в командной строке:
openvino2tensorflow --model_path <vino_path/model.xml> --model_output_path <final_path> --output_saved_model
В параметре --model_path нужно указать не директорию, а путь к файлу *.xml, а в --model_output_path – директорию. Данный конвертер позволяет преобразовывать модели в большое число форматов, в том числе и сразу для edge TPU. Однако, зачастую, попытка конвертировать сразу в edge TPU приводит к ошибке, поэтому мы рекомендуем действовать поэтапно.
5) Преобразование saved model в квантизованную TFlite модель. Эта процедура называется post-training integer quantization. Код дан в Приложении 2.
Здесь необходимо пояснить, что post-training quantization требует указания ссылки на генератор данных. Этот генератор должен возвращать N тензоров размерности 1xHxWxC, соответствующей входу в нейронную сеть. Если вы конвертируете модель только чтобы проверить принципиальную возможность компиляции, то можете использовать случайные числа и небольшое число N. Для полноценной конвертации генератор должен использовать реальные данные из вашего датасета (если «сырые» данные из датасета перед подачей в нейросеть подвергаются препроцессингу, то его необходимо сделать) и чем больше N – тем корректнее преобразование весов. Цель генератора – сделать так, чтобы конвертер «понял» диапазоны чисел, в которых следует работать и выбрал оптимальные коэффициенты для перевода чисел в uint8/int8.
6) Компиляция под edge TPU:
edgetpu_compiler <model.tflite>
Замечание: если компиляция провалилась, попробуйте понизить версию компилятора флагом -m. В ряде случаев, компиляторы более низкой версии (например, 11) рапортуют об успешном завершении компиляции, даже если ни одна операция не была перенесена, но что более важно – будет создан лог, где вы можете посмотреть, какие операции перенеслись, а какие – нет.
Выводы:
Несмотря на то, что для Google Coral «родным» является фрэймворк TensorFlow, во
многих случаях вы можете перенести на эту платформу свою нейронную сеть,
созданную в PyTorch. Этот процесс переноса является трудоемким и
многостадийным, а для некоторых типов слоёв необходимо будет подобрать
совместимые аналоги, но для большинства классификаторов изображений (таких как MobileNet, ResNet) результат будет положительным. Другие типы нейронных сетей также переносятся, если все используемые операции поддерживаются и достаточно памяти для их выполнения. В следующем разделе даны подробные исследования влияния размера модели на её компилируемость.
Оценка компилируемости модели
К сожалению, последняя стадия из предыдущего раздела не всегда успешно выполняется даже при условии, что все слои нейронной сети поддерживаются edgetpu-компилятором.
Слишком большие и сложные модели не пролезут из-за ограничений по памяти. В данном разделе мы попытаемся оценить возможность компиляции, основываясь на закономерностях, полученных на простых моделях. Модели для данных исследований были созданы во фрэймворке Keras.
EdgeTPU-компилятор выдает следующую информацию по окончанию компиляции:
On-chip memory used for caching model parameters (далее used memory).
On-chip memory remaining for caching model parameters (далее remaining memory).
Off-chip memory used for streaming uncached
model parameters
Исходя из названия, первые 2 показателя должны в сумме давать константу, но в большинстве случаев это не выполняется. Третий показатель во всех экспериментах оказался равен нулю, поскольку модельные сетки были небольшими и достаточно простыми. Кроме того, приводим данные по времени компиляции, но нужно помнить, что время компиляции может варьироваться от запуска к запуску, имеет смысл только порядок величины.
Зависимость от размера входного тензора
Простейшая модель: входной тензор 1xSxSx3, затем единственный слой в виде свёрточного фильтра 1x1 с 3-мя выходными каналами, общее число параметров = 4. Изменяем размерность S входного тензора. Во всех случаях used memory = 256 B. На рисунках ниже приведены зависимости показателей компиляции от S.
Код:
SHAPE = (S, S, 3) model = keras.Sequential() model.add(keras.Input(shape=SHAPE, batch_size = 1)) model.add(layers.Conv2D(3, 1, padding="same"))


Из графика видно, что оставшаяся память изменяется скачкообразно при переходе S от 600 к 640 (на 1Мб) и от 7200 к 7230 (на 4Мб). При S = 8129 модель перестаёт компилироваться. Время в целом растет быстрее, чем линейно, с увеличением размерности входного тензора.
Зависимость от числа слоёв
Входной тензор 1x512x512x3. Затем последовательно следуют несколько одинаковых свёрточных фильтров 1x1 с тремя выходными каналами. Следующие графики построены в зависимости от числа слоёв.
Код:
Зависимость от размера входного тензора для многослойной модели
Данные получены для модели из предыдущей серии со 128 слоями. Меняем размерность входного тензора S (тензор вида 1xSxSx3), и строим зависимости от S.
Код:
SHAPE = (S, S, 3) model = keras.Sequential() model.add(keras.Input(shape=SHAPE, batch_size = 1)) for i in range(128): model.add(layers.Conv2D(3, 1, padding="same"))

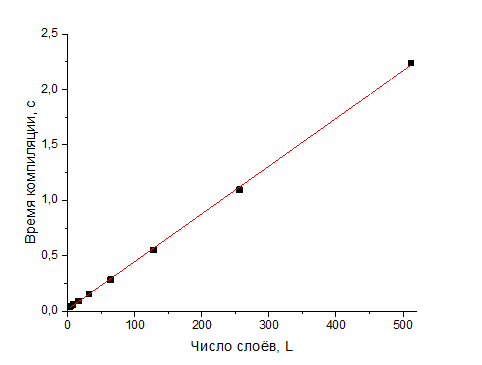
Время компиляции и используемая память растут линейно, оставшаяся память падает почти линейно, но со слабым наклоном. Эксперименты проведены вплоть до 512 слоёв (6144 параметра). Таким образом, если ваша сеть представляет собой последовательность одних и тех же блоков вы всегда можете, скомпилировав несколько вариантов с небольшим числом слоев, оценить, сколько ещё таких слоёв влезет.
Зависимость от размера входного тензора для многослойной модели
Данные получены для модели из предыдущей серии со 128 слоями. Меняем размерность входного тензора S (тензор вида 1xSxSx3), и строим зависимости от S.
Код:
SHAPE = (S, S, 3) model = keras.Sequential() model.add(keras.Input(shape=SHAPE, batch_size = 1)) for i in range(128): model.add(layers.Conv2D(3, 1, padding="same"))
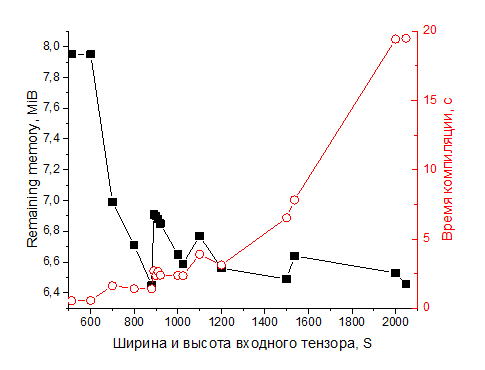
И оставшаяся память, и время компиляции имеют тренд на уменьшение/увеличение, но с осцилляциями. Причем максимум оставшейся памяти как правило совпадает с максимумом на времени компиляции, то есть входные тензоры, оптимальные с точки зрения используемой памяти, неоптимальны по времени компиляции. Эти оптимальные размеры тензоров при этом не являются степенями двойки (первое объяснение, которое приходило в голову). В целом на remaining memory имеются такие же скачкообразные падения, как и на примере с одним слоем.
Зависимость от числа каналов в свёрточных слоях
Фактически, число каналов – это число параллельных фильтров, каждый из которых пишет в свой канал. В данных экспериментах вход в нейронную сеть представляет собой тензор 1x512x512x3. Далее идут 64 последовательных слоя в виде свёрточных фильтров 3*3. Были испытаны несколько серий нейронных сетей: а) у всех фильтров одно и то же число каналов K и б) число каналов в последовательных слоях чередуется: 3/K, 4/K и 6/K. В первой серии, где число каналов во всех фильтрах одинаковое, начиная с К = 63 каналов модели не компилируются.
Код а):
SHAPE = (512, 512, 3) model = keras.Sequential() model.add(keras.Input(shape=SHAPE, batch_size = 1)) for i in range(64): model.add(layers.Conv2D(K, 3, padding="same"))
Код б):
SHAPE = (512, 512, 3) model = keras.Sequential() model.add(keras.Input(shape=SHAPE, batch_size = 1)) for i in range(32): model.add(layers.Conv2D(3, 3, padding="same")) model.add(layers.Conv2D(K, 3, padding="same"))

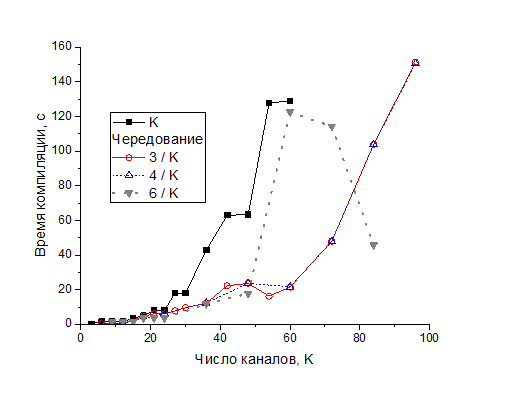
Remaining memory в основном уменьшается, иногда встречаются небольшие плато. При переходе от 42 к 48 каналам в первой серии remaining memory падает скачком. Такое же падение, но позже наблюдается для чередования 6/K каналов. Used memory растет почти линейно, наклон больше для случаев 6/K и когда во всех слоях менялось число каналов. Время компиляции растёт примерно экспоненциально. Для серии 3/K эксперименты проведены до чередования 3 канала / 96 каналов, все модели компилируются. Аналогичные результаты получены для чередования 4/K и 6/K каналов. В последнем случае компиляция провалилась при K = 96.
Влияние количества параллельных слоёв при суммировании Код:
SHAPE = (512, 512, 3) input = keras.Input(shape=SHAPE, batch_size = 1) branches = [] for i in range(5): branches.append(layers.Conv2D(3, 3, padding="same")(input)) output = tf.keras.layers.Add()(branches) model = keras.Model(input, output, name="my_model")
Непосредственное применение операции суммирования возможно только для двух параллельных слоёв, добавление большего числа слагаемых приводит к появлению дополнительных операций суммирования, а нейронная сеть становится похожей на луковицу, (см. рисунок):
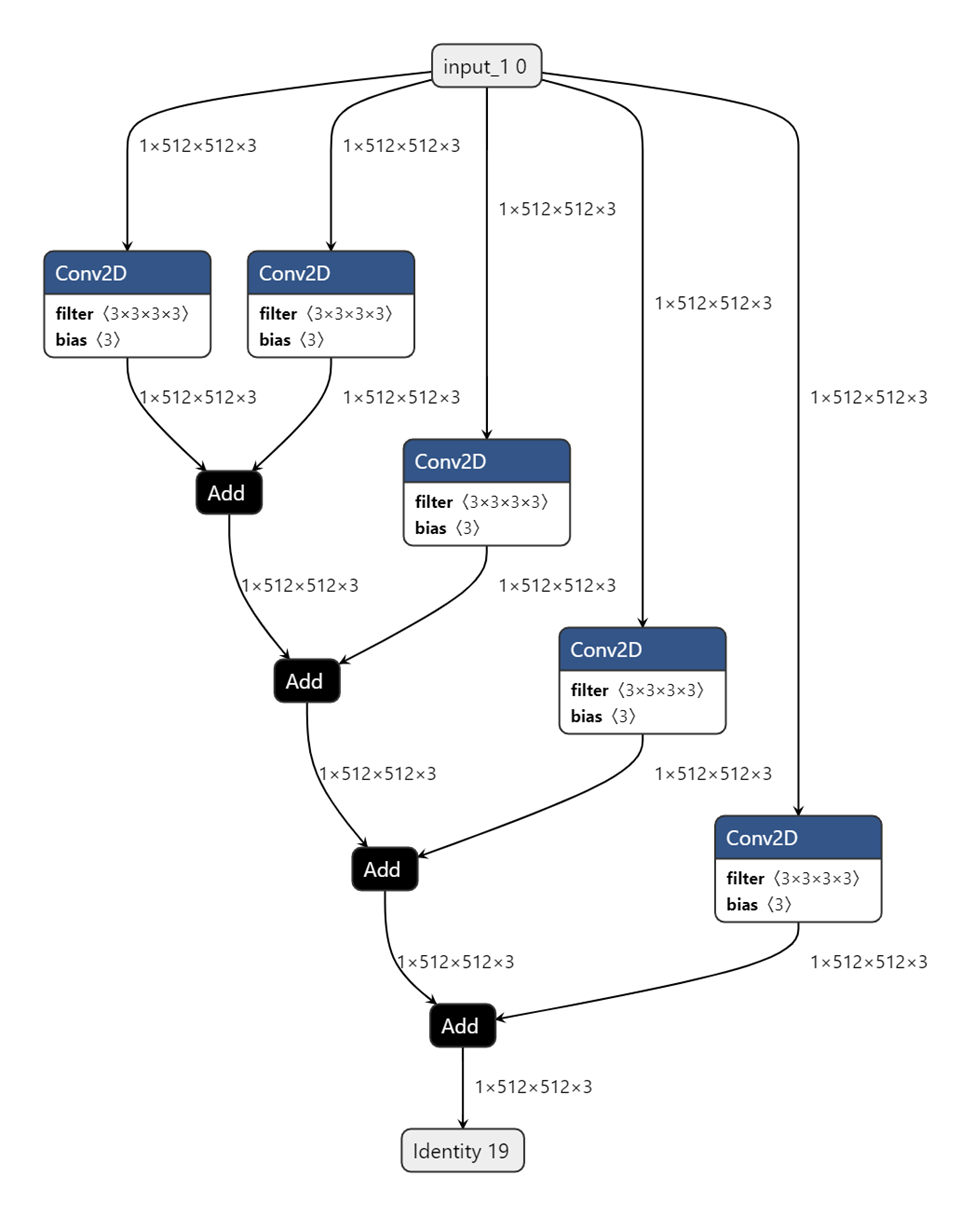
Зависимость всех типов памяти и времени компиляции от числа складываемых слоёв линейна и в этот раз used + remaining memory = const. Добавление свёрточного слоя перед ветвлением не меняет принципиально результат. В экспериментах суммировалось до 80 слоёв, все модели скомпилировались без проблем.
Зависимость от числа конкатенированных слоёв
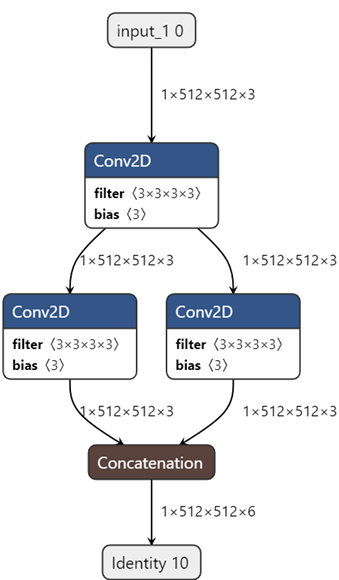
Модель представляет собой входной тензор 1x512x512x3, затем свёрточный слой, а затем несколько свёрточных слоёв расположенных параллельно с последующим объединением конкатенцией:
SHAPE = (512, 512, 3) input = keras.Input(shape=SHAPE, batch_size = 1) next = layers.Conv2D(3, 3, padding="same")(input) branches = [] for i in range(2): branches.append(layers.Conv2D(3, 3, padding="same")(next)) output = tf.keras.layers.Concatenate()(branches) model = keras.Model(input, output, name="my_model")
Схема:
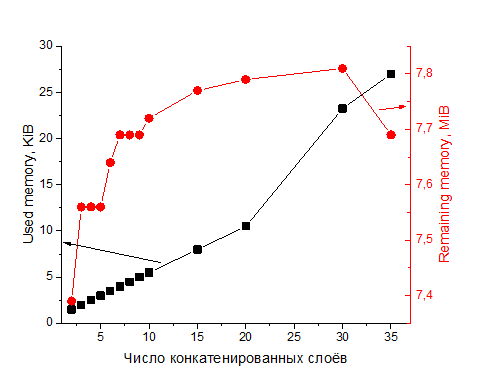

Зависимости построены от числа конкатенированных слоёв. Компиляция для модели с 40 конкатенированными слоями провалилась. Используемая память растёт линейно с несколькими изломами, оставшаяся память проходит через максимум, а затем начинает резко падать. Время компиляции растет экспоненциально, для 35 слоёв время компиляции превысило стандартный таймаут, потребовалось его увеличить.
Слияние функций активации со свёрточными фильтрами
Эксперименты показали, что used и remained memory не зависят от того, используется ли с фильтром слитая (fused) функция активации. Из поддерживаемых функций опробованы ReLu – никак не повлияла, а также tanh и sigmoid – время компиляции увеличилось почти в 2 раза.
Использование ResizeBilinear
В руководстве сказано: «Depending on input/output size, this operation might not be mapped to the Edge TPU to avoid loss in precision». Эксперименты показали, что эта операция почти никогда не переносится на edge TPU. В лучшем случае – модель компилируется, но без этой операции, в худшем – компиляция проваливается. Эта проблема также обсуждается на форуме «EdgeTPU — ResizeBilinear only for small Models?». Ответ официальных лиц дан 9 декабря 2019:
Yes, ResizeBilinear operation is mapped to CPU in specific cases. As we cannot disclose how this happens, i can tell you why. Compiler rejects mapping the ops to EdgeTPU if loss of precision is higher than threshold. Team is working to resolve this and will be updated in our next release.
The reason for runtime error could be due different version of tensorflow. We recommend to use tf 1.15. Please check it, if you are using tf 2.0 or tf 1.15 nightly try to downgrade and run the model.
Забавно, что при попытке воспользоваться этой рекомендацией (понижение версии тензорфлоу до 1.15) возникает ошибка:
AttributeError: module 'tensorflow.python.keras.api._v1.keras.layers' has no attribute 'Resizing'
Заметим, что для второй поддерживаемой операции изменения размера, ResizeNearestNeighbor, на официальном сайте дан тот же комментарий, скорее всего, в случае этой операции будут те же проблемы. Рекомендуем избегать этих операции при разработке нейронной сети для запуска на Google Coral.
Заключение
Чем больше и сложнее модель, тем ниже вероятность её успешной компиляции. Поэтому старайтесь использовать небольшие входные тензоры. В то же время увеличение сети путём последовательного добавления повторяющихся фрагментов исчерпывает ресурс компилятора линейно, то есть увеличивать сеть «в глубину» можно на очень большое число слоёв.
Разделение модели на параллельные потоки данных с последующим слиянием операцией сложения или конкатенации возможно до очень большого числа ветвлений, достаточного для практических целей.
Постарайтесь не использовать различные варианты Resize в своих моделях, с большой долей вероятности он не перенесутся.
Если вы останетесь в рамках перечисленных ограничений, то скорее всего, ваша модель может быть успешно перенесена на Google Coral.
Надеемся, наш опыт упростит вам перенос нейросетей.
Если же компиляция провалится, обратите внимание на «узкие места», перечисленные
в статье. Они помогут выбрать стратегию для оптимизации вашей нейронной сети
для Google Coral.
Приложение 1. Установка необходимых пакетов
# компилятор edgetpu curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add – echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list sudo apt-get update sudo apt-get install edgetpu-compiler # tensorflow sudo pip3 install tensorflow==2.3.1 –upgrade sudo pip3 install tensorflow_datasets # onnx sudo pip3 install onnx onnx_tf onnx-simplifier # openvino sudo pip3 install openvino-dev # openvino2tensorflow sudo pip3 install openvino2tensorflow --upgrade
Приложение 2. Post-training integer quantization
def my_data_gen(): … tensor = … … yield [tensor] filepath = “my_model” out_filename = “qmodel.tflite” converter = tf.lite.TFLiteConverter.from_saved_model(filepath) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = my_data_gen converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.experimental_new_converter = True converter.target_spec.supported_types = [tf.int8] converter.inference_input_type = tf.int8 converter.inference_output_type = tf.int8 quant_model = converter.convert() with open(out_filename, 'wb') as f: f.write(quant_model)

