Эта статья подготовлена на основе доклада «Микросервис головного мозга» Михаила Трифонова, Lead frontend Cloud и основателя frontend-сообщества TeamSnack. Мы разберём когда необходимы микрофронты, каким должен быть технологический стек, как нарезать мироксервисы и какие существуют стандарты при построении микросервисной архитектуры.

Эта статья, по сути, продолжение первой части «Микросервис головного мозга. Пилим всё, что движется». В ней Михаил рассказывает, как ему с командой удалось ускорить разработку с помощью микросервисного подхода. Они поэтапно строили микросервисную архитектуру, распилили монолит, UIKIT и создали архитектуру как на иллюстрации ниже.

На иллюстрации представлена архитектура получившегося проекта.
Вверху — микросервис. Внизу — инфраструктура, необходимая для его поддержания.
Пользователь заходит на сайт и попадает в оркестратор. Далее идут Utility — сервисы, которые ничего не рендерят, а занимаются выстраиванием подкапотной логики. Следующий большой кусок — это рендер микрофронтенда.
Немного статистики (которая пригодится позже). В команде Михаила:
10+ независимых команд, которые даже иногда друг друга не знают;
25 фронтенд-разработчиков;
81 микросервис;
2000+ внутренних зависимостей.
Потребность: когда необходимо применять микрофронты?
Например, у вас есть какое-то legacy-приложение на Angular, и вам необходимо его отрефакторить и перевести, например, на React. Это боль.
При большом рефакторинге
Большинство разработчиков обычно предлагают поднимать второе приложение, все новые фичи делать параллельно, а старые подтянуть когда-нибудь потом. Но энергия иссякает и они предлагают бизнесу сначала закончить рефакторинг, а только потом делать новые фичи. В результате у бизнеса энергия тоже иссякает и остаются просто два приложения.
С микросервисами вы можете пойти по такому пути:

Всё legacy-приложение можно обернуть в один микросервис, параллельно создать второй микросервис, и постепенно фича за фичей переносить из одного приложения в другое. Если у вас нет необходимости в микросервисной архитектуре, вы её потом убиваете и оставляете только новый монолит.
Распределённые команды, работающие над одним приложением
Часто над микросервисом раподают распределенные команды, которые друг с другом никак не взаимодействуют, поэтому у решения есть очевидные сложности:
Недостаток знаний кодовой базы. Из-за того, что понимание кодовой базы лишь частичное, разработчик не знает все приложение целиком и допускает баги.
Merge Conflicts. Устранять конфликты с соседней командой — это тоже баги и дополнительное тестирование.
Релизные циклы. Внедряем релизные циклы, чтобы ничего не сломать.
GitFlow и долгое тестирование. При релизе каждой фичи команды тратят много времени на взаимодействие, чтобы выпустить даже что-то простое.
Как решить эти проблемы
Берём всё наше приложение, делим на микросервисы и каждый загружаем в отдельный репозиторий и назначаем владельца для каждого.

В итоге получается, что разработчик мало взаимодействует с внешним миром. Он живет в своём мирке, без понимания кодовой базы, знает, с чем работает и ни с какими Merge Conflicts не сталкивается. Откуда им взяться, если он чаще всего один работает над микросервисом? Релизные циклы тоже не нужны из-за отсутствия взаимодействия: вместо GitFlow можно пойти GitHub Flow, и тестирования станет намного меньше.
Технологический стек: Webpack MFE vs Single-spa
На чём все-таки стоит сделать микросервисы? Чтобы ответить на этот вопрос, нужно научить браузер делать две вещи:
Загружать bundle в realtime.
Правильно их оркестрировать.
Loading. Для него существует два популярных решения, которые делают одно и то же.
System JS. Загружает bundle в realtime. Он написан на js-модулях и более нативном языке. Из-за этого не привязывает вас к конкретной технологии.
Webpack Module Federation. Загружает bundle в realtime с поддержкой и привязкой к Webpack. Написан на Webpack, под капотом такие же модули, но всё равно занимается всем Webpack. С одной стороны, есть поддержка Webpack, с другой — зависимость от него.
Реализация Shared dependency в System JS

Второе очень важное отличие — это Shared dependency.
С помощью Webpack externals нужно написать, что эти библиотеки (react, react-dom) нельзя класть в bundle, а нужно брать из глобальных переменных и класть туда же. Для этого поднимем микросервис, который кладёт react и react-dom в глобальные переменные, чтобы всё это заработало.
Реализация Shared dependency в Module Federation:

При сборке микросервиса вырезаются bundle react и react-dom, как указано в контейнере. В Bootstrap формируется некий скоуп зависимостей, в который кладётся react и react-dom.
Когда появляется сервис и Bootstrap этого сервиса, MFE обнаруживает, что react уже загружен, и сохраняет у себя ссылку. С react-dom то же самое — зависимости, которых нет, он загружает в скоуп. Когда происходит mount приложения, react и react-dom берутся из оркестратора один раз, а все зависимости — непосредственно из микросервиса.
Дальше начинается магия Module Federation. Сами создатели библиотеки говорят, что настоящее shared dependency у них, а не в System JS.
Что происходит, когда появляется второй микрофронт? React и react-dom не кладутся в скоуп, а dependency 1 кладётся, потому что он имеет другую версию зависимости. Когда происходит mount, все зависимости загружаются только один раз, и собираются в одном микросервисе.

Если сравнить System JS и Module Federation, то shared dependency будет и там, и там. Module Federation сложнее, особенно когда там появляются оптимизации.
Микрофронтенды. Оркестрация
Есть два пути:
Самопис.
Single-spa.
Почему-то люди, которые выбирают Module Federation, начинают с первого варианта.
В Single-spa есть достаточно мощно развернутая документация. Подробнее смотрите в первой части статьи «Микросервис головного мозга. Пилим всё, что движется».
Гранулярность: как резать микрофронтенды
На самом деле, один из самых популярных вопросов, как правильно нарезать микрофронты. Разберём стандартные для микросервисов постулаты.
Coupling должен быть маленьким, а Cohesion — большим
Маленький Coupling — это когда у микросервисов есть между собой связь. Чем она больше, тем меньше микросервис им остаётся.

На микросервис это уже не похоже. Лучше объединить их или переделать архитектуру, вынести один в одну функцию, а другой в другую.
Cohesion — внутренняя связь внутри микрофронта.

Здесь противоположная история — Cohesion должен быть большим. Если он маленький, то лучше эту функциональность вынести в микросервис или хотя бы подумать об этом, потому что иначе она будет просто так пересобираться.
Максимально плоская архитектура
Никаких оркестраторов и подобных вещей! Это сложно и ведёт к багам.
Пример: Распил сервиса
Разделим существующий сервис: есть приложение, которое содержит header, sidebar и контентную часть. Что будет, если мы поместим всё в один микросервис?
Coupling вообще не будет, только Cohesion. Здесь header никак не взаимодействует с контентной частью, так как Cohesion нулевой. Логичней всего большую контентную часть вынести в отдельный микросервис. Header и sidebar — это тоже микросервис. В итоге у нас получатся три микросервиса.

Усложним задачу. У header есть бейдж, когда мы на него нажимаем, открывается pop-up:

Это тоже отдельный микросервис, у него маленький Cohesion и его можно вынести.
Усложним ещё:

У нас есть:
Оркестрация. Её тоже разместим в отдельный микросервис, который находится в core-service.
Хранение данных. Отдельный микросервис перед нами или часть ядра? Если это ядро, то Cohesion это отдельный микросервис, потому что связь с ядром у него маленькая.
Статические конфигурации. С одной стороны, это хранение данных, с другой, от них не зависит оркестрация — это отдельный микросервис, который можно положить в ядро или в store.
Подсказка: это core-service, потому что у него большой Coupling. По функциональной бизнес-логике статические конфигурации идут в store, но мы не можем их туда загрузить, потому что от них зависит оркестрация и появляется большой Coupling. При low Coupling идёт работа со статическими конфигурациями.Вы будете одновременно заходить и в хранение данных, и в оркестрацию, и от этого возникнут проблемы.
В отдельные сервисы стоит вынести: обогащение Ajax-запросов, переключатель языка и Shared dependency. Их положили в один bootstrap-service.
До сих пор ходят споры: Shared dependency — это отдельный сервис или часть ядра. Пока это отдельный сервис, но есть пойнты, почему его стоит поместить в оркестрацию.
Базовые стандарты: как договориться?
Микросервисный подход — это очень гибкий инструмент. Сама библиотека ни в чём не ограничивает. Можно писать на Vue, Angular, React с любым Code Style — с Caps Lock или через чёрточки. Нет вообще никаких ограничений, и в этом беда. Вот шесть базовых стандартов, которых стоит придерживаться:
Code style.
Технологический стек.
Структура проекта.
Git flow.
Development Flow и CI/CD.
Environments и Dependencies.
Команда должна договориться о том, как ей работать. Для этого можно применить модель Коттера.
Модель Коттера. Стадии организационного изменения
Это специальная теория из Change Management о том, как проводить глобальные изменения в компании. Подробнее об этом Михаил расскажет в своём будущем докладе на TeamLeadConf 2023. А пока посмотрим из каких стадий состоит модель:
Создать атмосферу безотлагательности действий. Люди привыкли хвататься за прошлое,это стопорит будущие изменения. Лучше собрать всех, на кого это изменение будет распространяться, и объявить, что теперь вы будете работать по-новому. Так все поймут, что обратного пути нет.
Создать стандарты разработки: сформировать влиятельные команды реформаторов, видение и пропагандировать его.
Пройдёмся по стандартам разработки подробней.

У каждого стандарта есть code-owner. На первом этапе у него RnD, и полная свобода творчества.
Создать альфа-версию вместе с платформенной командой в количестве 3-5 сотрудников. Сode-owner демонстрирует своё видение, а они дают фидбэк и вместе перерабатывают продукт. В результате у 3-5 человек появляется новое видение, так формируется команда реформаторов, которые ассоциируют себя с новым стандартом и пропагандируют его.
Платформенная команда и code-owner демонстрируют стандарт техлидам бизнес-команд. У них также появляется новое видение и фидбэк.
Инкремент демонстрируют всем фронтенд-разработчикам. К этому моменту стандарты уже проработаны настолько, что к ним тяжело придраться, а лидеры всех бизнес-команд уже ассоциируют себя с этим стандартом, а это чаще всего лидеры мнений для команды. Миграция стандартов проходит достаточно плавно и мягко, но важно учесть весь фидбэк.
Для примера обычные наименования папок:
В инкременте на фото выше есть function first подход по каждому стандарту. Все с ним согласны и нужно создать условия для претворения нового видения в жизнь.
Каждый разработчик должен попробовать новый стандарт, а новенькие изучать его при онбординге. Для этого стандарт нужно включить в онбординг-документы.
У разработчика должна быть административная возможность и время соблюдать стандарты. Это тоже может быть проблемой.
Разработчик должен видеть, когда делает что-то не так. Необходимо максимально автоматизировать разработку через linter Линтер и сделать так, чтобы всё, что сделано не так подсвечивалось warning сообщением. Errors и IT-тоталитаризм не нужны, достаточно warning.
Необходимо организовать способ отслеживания чистоты кода. Разработчик может саботировать новые правила, поэтому важно сводно по всей компании следить за соблюдением стандартов, чтобы видеть, что идёт не так. Об этом способе отслеживания нужно заранее всем сообщить.
Систематическое планирование с целью достижения краткосрочных побед. Необходимо разделить на несколько этапов и запланировать рефакторинг.
Закрепить достижения и расширить преобразования. Когда вы всё отрефакторили, это ещё не конец. Нужно всех собрать и объявить о результатах нововведений.
Новые подходы как часть культуры. Не все примут изменения сразу: кому-то не захочется, потому что еще не привыкли. На это потребуется какое-то время.
Monorepo vs раздельные репозитории
Чтобы разобраться, ответим на вопрос: «Что быстрее: 20 приседаний за 1 подход или 20 подходов по 1 приседанию?»
Ответ: 1 подход и 20 приседаний быстрее.

Но ведь 20 приседаний нельзя сделать за один спринт, а ещё всё зависит от того, насколько давно вы приседали в последний раз и ограничений времени.
В жизни получается, что 20 подходов по одному приседанию — быстрее. Микрофронтенды позволяют заниматься рефакторингом в микросервисах по очереди. Но действительно ли можно сделать только одно приседание, зависит от гибкости.
Пример

Есть микросервис с legacy древним UIKIT. Приходит бизнес-задача, где необходима новая кнопка из нового UIKIT. Для этого начинают рефакторить все приложения. Это не одно приседание, оно может занять минимум пару спринтов.
Поэтому мы пошли другим путем: UIKIT тоже распилили.

Получилась Monorepo с пакетами кнопок, Fields, таблиц и т.д., то есть попакетно. Управляем этим с помощью Lerna и хорошо живём.
Boilerplate: общие библиотеки, общие паттерны, Template Configs
В микросервисной архитектуре всё изолировано. Поэтому возникает много boilerplate. Если его не автоматизировать, то придётся заниматься копипастом, и из-за этого возникают большие проблемы.
Например, есть четыре разных сервиса, которые про разный бизнес, как минимум, есть кнопки и вам точно понадобится UIKIT.

А ещё в каждом микросервисе есть общие тулзы, функции, хуки, конфигурации, которые тоже хочется переиспользовать.

Представьте, что будет, если Линтер или настройки Webpack во всех микросервисах будут разные!
Поэтому появляется еще одна Monorepo с названием Frontend Tools:

Дальше такой кейс:

Это четыре разных сервиса, каждый из которых имеет бизнес-специфику и которые не хочется делать постоянно. Возникает иллюзия создать Business UIKIT и Business Frontend Tools. Если так сделать, UIKIT не будет обогащаться, потому что в Business UIKIT меньше ревью, а значит у команды не будет инициативы улучшать общие библиотеки.

Но от Business Frontend Tools не уйти, поэтому важно разделять логику и view: view уходит в UIKIT, а логика существует отдельно.
Общие паттерны
Ещё один boilerplate — это создание нового сервиса.
Например, вот репозиторий одного сервиса:
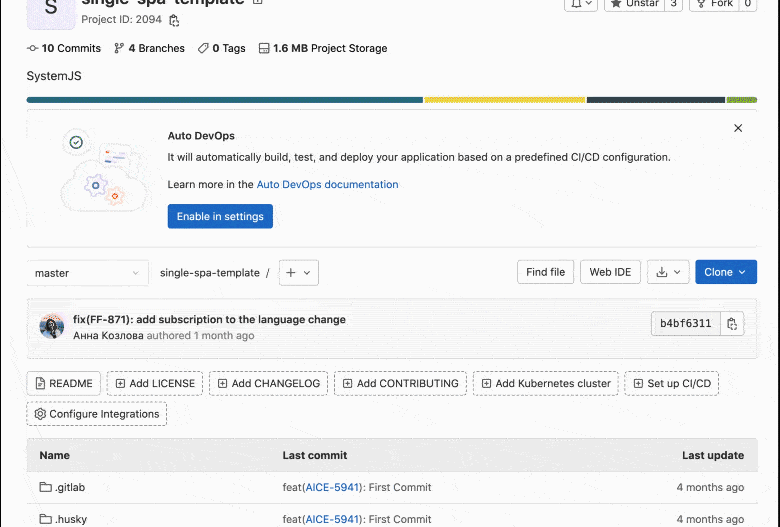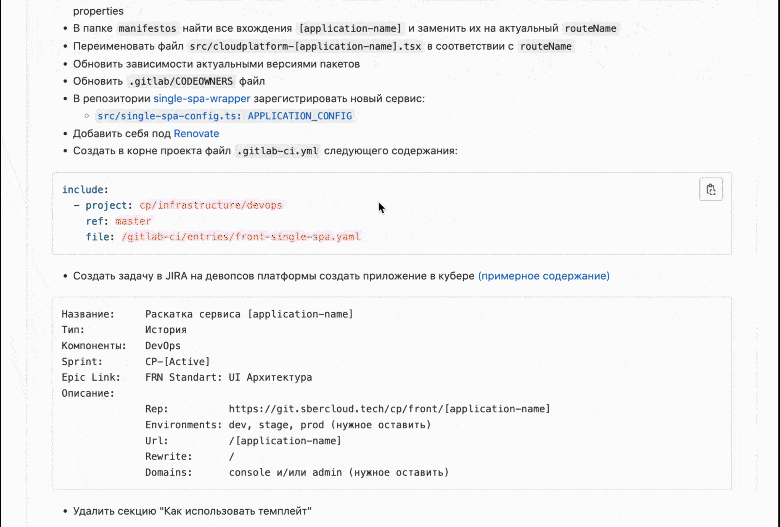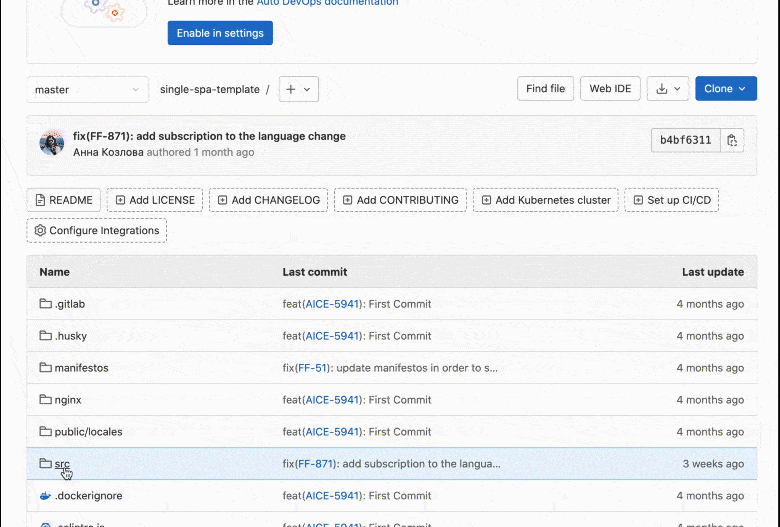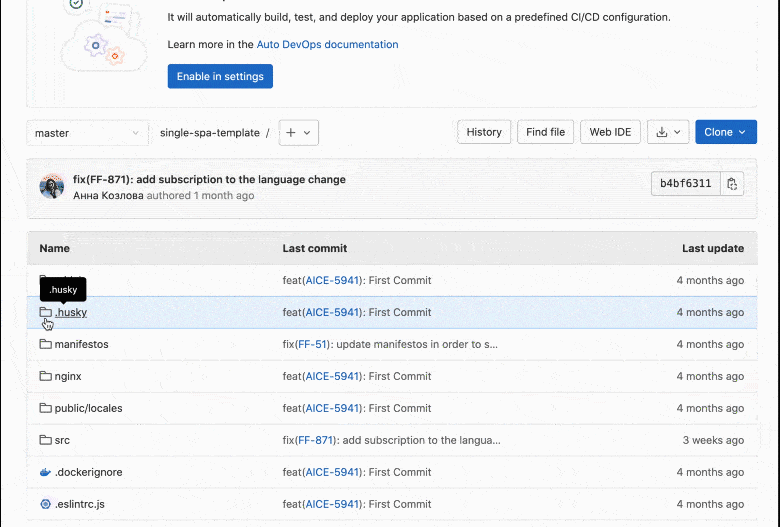
Представьте, если его каждый раз создавать заново, сколько там будет ошибок. Для оптимизации можно использовать GitLab Templates.

Буквально за 15 секунд появится новый микросервис.
Dependency: как обновлять и следить?
Тут есть подводные камни. У нас одно приложение, 81 микросервис и 2000+ внутренних зависимостей.
Для пользователя это одно приложение, ему не важно, что там под капотом. Если в момент перехода между сервисами будет разная кнопка, это не хорошо, поэтому лучше обновлять зависимости один раз в спринт. Но сразу появляются проблемы: разработчики не видят, что им нужно обновлять, поэтому можно использовать бота от Renovate.

Это выглядит так:

Бот создает MR с обновлением, и внизу с change-логом, который показывает, что действительно обновилось. Нужно договориться с продактами, чтобы в Jira появились задачи, а ещё нужен скрипт, чтобы проверять изменения.

Отладка кода: import-map overview и Argo CD
Когда вам приходит баг, можно запустить с прода локально свой микросервис. Это очень удобно — можно запускать всё не только с прода или с dev, а локально. Для этого у single SPI есть import-map overview:

Он добавляет кнопку справа внизу, при нажатии на которую открывается список всех микросервисов.

Вы просто переопределяете, откуда брать bundle микросервиса, и всё работает.
У Argo CD чаще всего один dev-стенд. Разработчики вместе работают на нём, например, надо протестировать фичу и показать её продакту. Argo CD позволяет создать несколько контейнеров в Docker.

Когда вы запрашиваете bundle, то с помощью ModHeader можете добавить header.

Получаете один dev-стенд, а на нём все вариации микрофронтов и их версии с таймингом.
Front Teams: какая необходима команда?
Самые популярные вопросы о команде.
Какая команда нужна?

Чтобы поднять микрофронтенды, нужно время, для этого есть фреймворки. Но чтобы сделать архитектуру, которая минимизирует проблемы изолированности, придётся потратить время. В какой-то момент появилась целая платформенная команда, которая этим занимается. Результат её работы оптимизирует всю разработку других бизнес-команд. 1 Story Points может увеличить эффективность в 10 раз.
Как объяснить, кто ответственный?
Степень ответственности важна. Ведь поддержка может видеть приложение, а кто за какой кусок отвечает, не поймёт. Можно создать табличку в Confluence и расписать там, кому какой кусок принадлежит. Или вывести её в интерфейс, или придумать ещё десяток каких-то вариантов. Но главное, никогда не забывать, что команда, это прежде всего живые люди.
Вот это моя команда:

Абсолютно каждый из них внес вклад в архитектуру. Хочу им сказать спасибо, потому что все они офигенные фронты и мне посчастливилось поработать с ними.

