

Меня зовут Александр Горякин, и я работаю в отделе разработки систем для внешних заказчиков Tarantool. Очень часто мы сталкиваемся с весьма нетривиальными задачами, например с хранением графов. Расскажу об этом на примере создания системы по борьбе с мошенническими действиями для одного из заказчиков, очень крупного банка.
Постановка задачи
У банка много клиентов, которые каждый день, неделю, месяц и год выполняют транзакции: переводят средства с одного счёта на другой, будь то оплата услуг или товаров в магазине, переводят деньги родственникам, знакомым и рабочим.
Каждого клиента банка мы можем считать вершиной графа. Любая транзакция, которую выполнил пользователь — это ребро графа. Запись выглядит так:
{счёт1, счёт2, сумма, год, квартал}, где:счёт 1— это исходный счёт, с которого мы переводим средства;счёт 2— целевой счёт;сумма— переведённые деньги;годиквартал— для идентификации записи.
Сначала заказчик предоставил нам список всех транзакций за год, однако по условиям задачи нужно было хранить данные за пять лет. Это колоссальный объём данных, записей в подобном графе примерно 5 млрд. — это 10 млн. вершин, которые занимают 2 ТБ. Удержать столько в оперативной памяти очень сложно, и искать в таком массиве данных тоже довольно тяжело. А ведь наша цель — поиск клиентов, выполняющих мошеннические операции. Поэтому нам нужно было создать систему, которая может хранить рёбра графа и выполнять запросы по индексу и по графовому поиску.
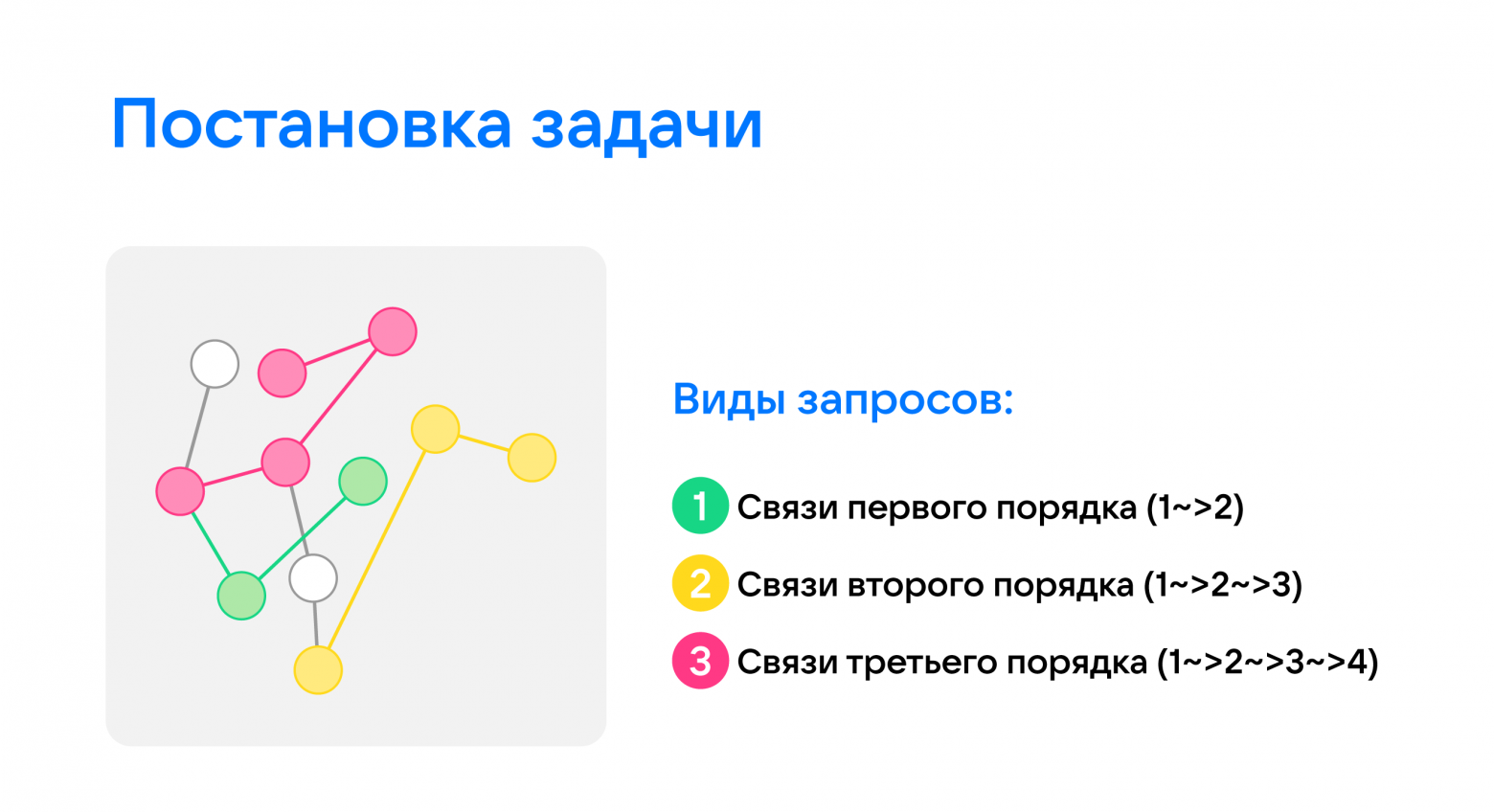
Клиент хотел выполнять запросы трёх видов — связи:
- первого порядка (1->2);
- второго порядка (1->2->3);
- третьего порядка(1->2->3->4).
Виды запросов
Связи первого порядка — это сами транзакции: перевели кому-то деньги. Их мы можем искать по индексу: нам известен исходный и целевой счёт, а также время (год и квартал), когда была проведена операция. Сумма нас не интересует.
Связи второго порядка — это когда в транзакции участвует один посредник. Например, вы хотите перевести деньги работнику, но его контактов у вас нет, и вы переводите деньги кому-то, у кого есть эти контакты — родственнику или знакомому, — а тот пересылает деньги нужному человеку. Для таких связей применяется простейший графовый поиск.
Поиск связей третьего порядка — самый сложный алгоритм, потому что он представляет собой поиск в графе с путём длиной в три перехода. Когда могут проводиться такие операции? Например, мошенники хотят вывести деньги с чьего-то счёта на свой через промежуточные счета. Но при этом им нужно использовать как можно меньше промежуточных счетов, так как за каждый перевод берётся комиссия, особенно если сумма большая.
Выбор инструмента для реализации
Основной сложностью были требования заказчика. Мы должны были уложиться в ограничения:
- Полная холодная загрузка данных — не более 7 часов.
- При поиске связей первого и второго порядка система должна выдерживать нагрузку до 3 тыс. транзакций в секунду. Под транзакциями подразумеваются не внутренние операции, которые выполняются в системе, а бизнес-транзакции по переводу средств.
- В случае графового поиска мы должны были уложиться в SLA 10 тыс. запросов в секунду.
Исходя из поставленной задачи и требований возникает вопрос: а есть ли готовые решения и почему бы ими не воспользоваться? Такие действительно есть — это графовые базы данных Arango DB, Titan и Neo4J. Есть и различные системы обработки графов, например, Pregel, в том числе реализованный на Lua. Кроме специализированных решений можно использовать для хранения графов реляционные файловые базы данных.
Однако у всех этих решений есть свои недостатки. Например, мы не могли использовать в нашем проекте графовые базы данных, так как необходимо было импортозамещение, к тому же у Arango DB, Titan и Neo4J нет русскоязычной поддержки. Некоторые базы данных могут хранить только вершины, а нам нужны были ещё и рёбра. Не все хранят метаинформацию, которая необходима для поиска по индексу. Кроме того, у каждой графовой базы собственный язык запросов: у Arango DB — SQL, у Neo4J — Cypher, у Titan — Gremlin. Каждый язык запросов накладывает свои ограничения на реализацию алгоритмов графового поиска. Скажем, у Titan нет своего хранилища, вместо него он использует Cassandra или Hadoop (является файловой базой данных).
Мы не стали использовать Pregel, потому что он не умеет выполнять запросы по индексам. И если бы мы использовали Lua-реализацию, которая специфична для Tarantool, то она упёрлась бы в ограничение виртуальной машины Lua, то есть работала бы очень медленно. Реляционные файловые базы тоже работали бы очень медленно, потому что в них данных хранятся на диске. К тому же запросы на графовый поиск очень сложные. Вот пример SQL-запроса на поиск связи второго порядка:
SELECT DISTINCT Entity.id
FROM Entity AS X
JOIN R1 AS R1_X ON Entity.id = R1_X.source JOIN Entity AS A ON A.id = R1_X.target JOIN R1 AS R1_A ON A.id = R1_A.source JOIN R2 AS R2_A ON A.id = R2_A.source
JOIN R3 AS R3_A ON A.id = R3_A.source JOIN Entity AS A1 ON R1_A.target = A1.id JOIN Entity AS A2 ON R2_A.target = A2.id JOIN Entity AS A3 ON R3_A.target = A3.id
JOIN R2 AS R2_X ON Entity.id = R2_X.source JOIN Entity AS B ON B.id = R2_X.target JOIN R2 AS R2_B ON B.id = R2_B.source JOIN R3 AS R3_B ON B.id = R3_B.source
JOIN R4 AS R4_B ON B.id = R4_B.source JOIN Entity AS B2 ON R2_B.target = B2.id JOIN Entity AS B3 ON R3_B.target = B3.id JOIN Entity AS B4 ON R4_B.target = B4.id
JOIN R3 AS R3_X ON Entity.id = R3_X.source JOIN Entity AS C ON C.id = R3_X.target JOIN R3 AS R3_C ON C.id = R3_C.source JOIN R4 AS R4_C ON C.id = R4_C.source
JOIN R5 AS R5_C ON C.id = R5_C.source JOIN Entity AS C3 ON R3_C.target = C3.id JOIN Entity AS C4 ON R4_C.target = C4.id JOIN Entity AS C5 ON R5_C.target = C5.id
WHERE
Entity.attr1 = val1 AND Entity.attr2 = val2 AND Entity.attr3 = val3 AND A.attr1 = val4 AND A.attr2 = val5 AND A.attr3 = val6 AND
A1.attr1 = valA AND A2.attr2 = valB AND A3.attr3 = valC AND B.attr1 = val7 AND B.attr2 = val8 AND B.attr3 = val9 AND
B2.attr1 = valA AND B3.attr2 = valB AND B4.attr3 = valC AND C.attr1 = val10 AND C.attr2 = val11 AND C.attr3 = val12 AND
C3.attr1 = valA AND C4.attr2 = valB AND C5.attr3 = valCЗдесь 24 join’а и 21 условие фильтрации. Этот запрос сложно написать и сложно читать, он просто огромный. Изначально у заказчика все данные хранились в Hadoop, запросы на поиск выполнялись через Hive, и на переброску по сети уходило очень много времени и ресурсов. Tarantool этих недостатков лишён.
В результате для хранения графов мы выбрали Tarantool. Одно из его главных преимуществ: мы умеем с ним работать, знаем, как посчитать необходимое количество экземпляров, как правильно их конфигурировать. Кроме того, в Tarantool очень хорошо работает поиск по первичному и вторичному индексу. Если важна производительность, то можно реализовать модули сколь угодно сложных алгоритмов графового поиска на компилируемом языке, например, на С — Tarantool написан на нём с использованием виртуальной машины Lua.
Загрузка и хранение данных
Переданный нам заказчиком один большой граф мы смогли разделить на много мелких, чтобы оптимально шардировать данные и распараллелить обработку. Мы смогли это сделать благодаря тому, что Tarantool позволяет шардировать под конкретные нагрузки. И в результате удалось использовать более эффективную репликацию.
Данные нам передали в формате ORC, а Tarantool из коробки не умеет с ним работать. Поэтому мы написали на Go импортёр на основе существующей библиотеки. Выбирали только необходимые нам поля:
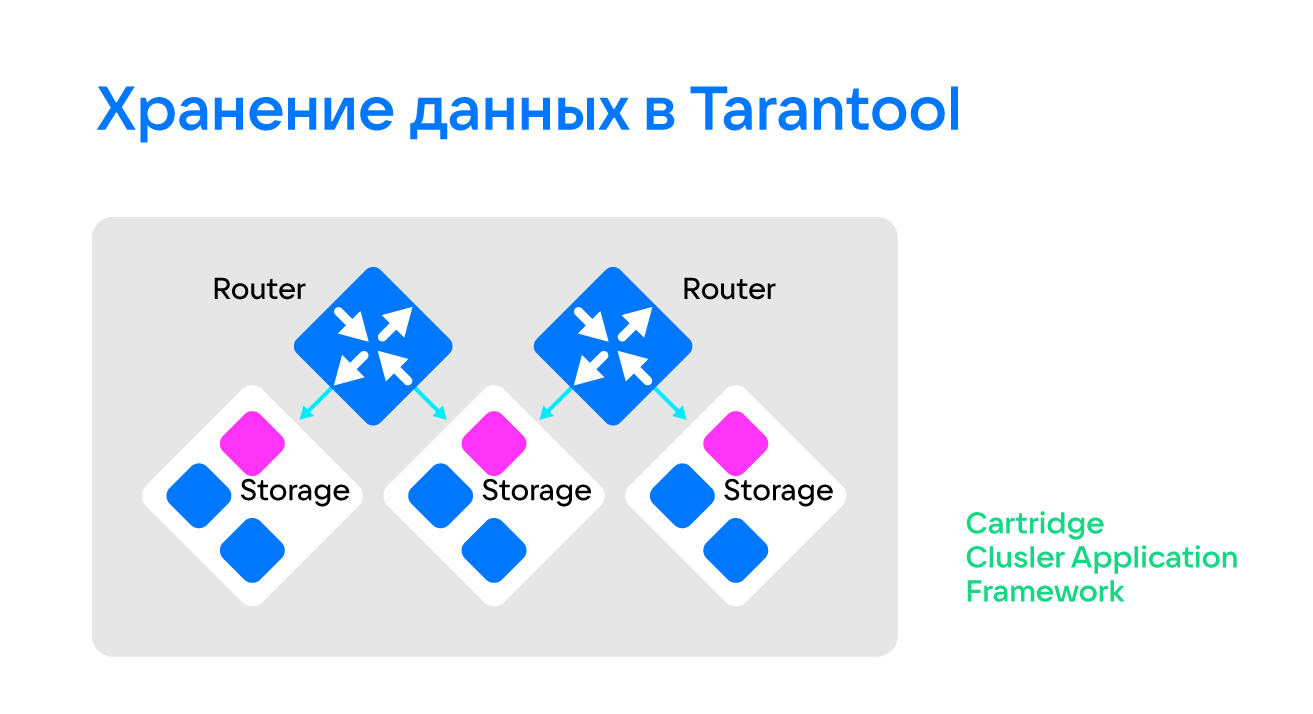
счёт 1, счёт 2, год, квартал и сумму, а затем импортировали. И поскольку нам передали информацию за год, а заказчик хотел за пять лет, пришлось данные размножить. Весь получившийся объём мы загрузили не за 7 часов, как это происходит у заказчика с Hadoop, а за час.Данные мы храним не в одном экземпляре Tarantool, а в кластере, созданном с помощью фреймворка Tarantool Cartridge. У Tarantool есть несколько видов экземпляров: роутеры, маршрутизаторы и хранилища. Роутеры маршрутизируют запросы к хранилищам. Хранилища — это наборы реплик (replica set), в каждом из которых есть один мастер и несколько реплик.
Изучив данные, мы увидели, что у них есть общие поля —
год и квартал. Нам показалось логичным шардировать именно по ним. В нашем случае каждый шард — это квартал определённого года. Для поиска связей первого порядка мы сделали первичный индекс по полям счёт 1, счёт 2, год и квартал, так как этот индекс удовлетворяет всем нашим требованиям к поиску. А для реализации графового поиска мы сделали вторичный индекс по полям счёт 2, год и квартал.Как я уже говорил, мы повысили гибкость репликации: больше запросов и больше реплик. Изучив данные, мы поняли, что больше обращений будет к более свежим данным (за прошедший год), потому что эти транзакции актуальнее и важнее для нас. Поэтому для их хранения мы увеличили количество реплик в наборах. Таким образом мы повысили скорость обработки и отказоустойчивость системы. Даже если упадёт мастер, запросы пойдут на реплику и мы всё равно сможем прочитать данные.
Алгоритмы поиска
В одном кластере Tarantool у нас хранится 10 млн. узлов и 5 млрд. записей. Сначала мы сформировали распределение по степеням вершин по всему набору данных. Степени вершин — это количество транзакций, выполненных с текущего счёта, то есть исходящие связи. Оказалось, что у нас есть вершины, из которых выходит от 100 тыс. до миллиона связей, и если мы будем перебирать наивным поиском в ширину, то это займёт очень много времени. Потому мы отказались от этого алгоритма.

Стали искать другой способ и пришли к такому решению:

У нас есть первичные и вторичные индексы. С помощью первичного индекса мы ищем все вершины — транзакции, — которые выполнялись с исходного счёта на какой-нибудь другой счёт, связанный с какими-то вершинами — назовём это множество Вершины 1. Пусть его мощность будет N. Также у нас есть вторичный индекс, который позволяет найти все вершины, из которых транзакции приходили на целевой счёт — назовем это множество Вершины 2. Пусть его мощность будет К.
Два шага пути нами сделано, осталось найти только связку между этими двумя множествами. Перебираем N*K пар из Вершины 1 и Вершины 2, так мы ищем связи между этими двумя множествами, тем самым сильно уменьшая количество вершин, которые нам нужно перебрать, и увеличивая скорость работы алгоритма.
Поиск связей второго порядка работает примерно так же, но немного проще: с помощью первичного индекса ищем все вершины, которые связаны с исходным счётом, а с помощью вторичного — все вершины, которые связаны с целевым счётом, и потом ищем пересечение этих двух множеств. То есть все вершины, которые есть в множествах Вершины 1 и Вершины 2 являются посредниками в транзакции.
Алгоритмы графового поиска мы реализовали тремя разными способами на Lua, SQL и С. Оставалось только выбрать самый эффективный из них.
Сравнение производительности
Для сравнения мы выбрали самый простой запрос — поиск связей первого порядка.

Хуже всех себя показал Lua, а у SQL в Tarantool есть одна особенность: он работает только в рамках одного экземпляра и не умеет выполнять кластерные запросы. Так что мы выбрали решение на С. Но и у него обнаружился один недостаток: сложность реализации. Наш алгоритм графового поиска получился очень громоздкий и сложный в написании. Тогда мы стали искать, каким компилируемым языком можно заменить С, чтобы сохранить производительность, но написать меньше кода. Выбрали Rust, на нём хранимые процедуры получились меньше где-то в пять раз. Скомпилировали модули и подключили их в Tarantool так же, как и модули на С. Производительность получилась почти такой же.
Результаты
Мы не просто учли требования заказчика, нам удалось их превзойти: данные загружаются в семь раз быстрее, при поиске связей первого и второго порядка обрабатывается уже на 30% больше транзакций в секунду, а в запросах графового поиска — на 80% больше. Даже если случайно заставить Tarantool обработать распределение с 1 миллионом связей, он с этим справится и не упадёт.
Хранить графы в Tarantool возможно, но делать это можно только в том случае, если вы изучили данные и знаете, как их можно шардировать, чтобы распараллелить обработку, Tarantool в этом отношении гибкий инструмент. Если для вас критична производительность или вам нужно реализовать какой-то сложный алгоритм, можете воспользоваться компилируемыми языками, например, С или Rust, для написания более эффективного кода. Причём Rust позволяет сделать это проще и с сохранением производительности.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
