

Lake city by arsenixc
Построение озера данных на основе облачных сервисов предполагает активное использование объектного хранилища S3. Команда VK Cloud Solutions перевела статью, которая раскрывает тонкости Cloud Native Data Lake.
Уровень 0: базовое озеро данных
Простое озеро данных выглядит обычно следующим образом:

У VK Cloud Solutions тоже есть свое объектное хранилище S3 Cloud Storage
Даже такая базовая конфигурация уже хороша, поскольку поддерживает все три основные сценария работы с данными:
- бизнес-аналитику,
- Data-Intensive API,
- машинное обучение.
То, что даже такой простой архитектуре хватает гибкости поддерживать все три сценария, лишний раз подтверждает преимущества объектных хранилищ. Особенно если говорить об интеграции с различными сервисами и инструментами обработки данных. Распределенная in-memory-обработка с помощью Spark? Без проблем. Колоночные хранилища наподобие Snowflake? Проще простого. Движок распределенных запросов для работы с большими данными вроде Trino? Элементарно, Ватсон!
Но можно сделать озеро данных еще более совершенным.
Уровень 1: современные табличные форматы
Озера данных становятся все популярнее, поэтому их базовую архитектуру изменяют, чтобы сделать удобнее. Первое очевидное улучшение — избавиться от ужасных CSV-файлов.
На смену им приходит популярный колоночный формат Parquet, который отлично подходит для аналитики, так как он:
- колоночный,
- обеспечивает высокую степень сжатия,
- поддерживает сложные вложенные типы данных.
Но даже с таким форматом объекты в объектном хранилище остаются разрозненной коллекцией. Если, конечно, не реализовать отдельную службу хранилища метаданных.
Однажды стало понятно, что этой коллекции объектов не хватает абстракции таблицы. В базах данных таблицы встречаются везде, но они имеют ценность и для объектных хранилищ.
И здесь в игру вступают табличные форматы: Apache Iceberg, Apache Hudi и Delta Lake. Подробнее о них читайте в нашем переводе «Hudi, Iceberg и Delta Lake: сравнение табличных форматов для озера данных».
Если сохранять данные в этих форматах, создавать таблицы в объектном хранилище становится намного легче благодаря поддержке определения схем, истории версий и автоматическому обновлению.
Это значительно повышает производительность и удобство использования озера данных. В итоге оно принимает другой вид:
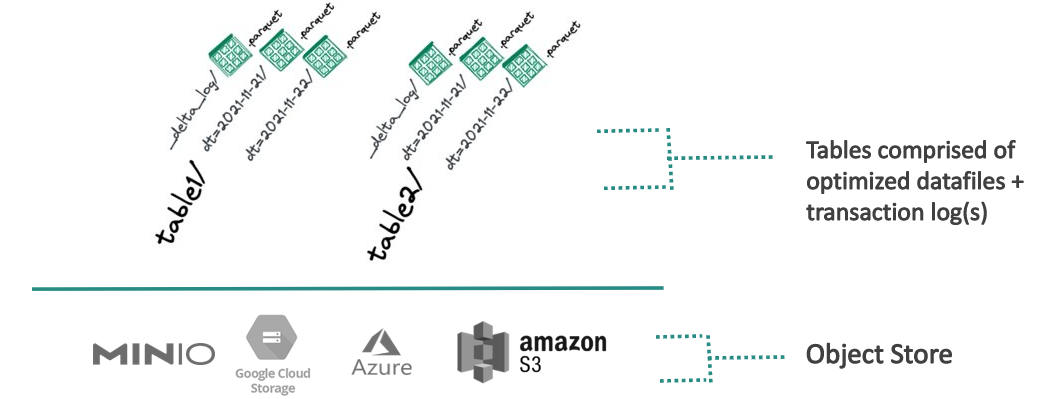
Табличные форматы позволяют вести лог транзакций с добавляемыми и удаляемыми объектами в озере с определенными префиксами. Это обеспечивает атомарность операции записи и позволяет избежать ошибок при одновременном чтении и записи.
Уровень 2: контроль версий данных (Git-Like-подход)
Табличные форматы делают озеро данных более совершенным, но это еще не предел. Преимущества, которые есть у форматов файлов на уровне таблицы, можно экстраполировать на все озеро данных.
В этом помогут инструменты контроля версий данных, например lakeFS. Они превращают бакет объектного хранилища в репозиторий, в котором можно отслеживать несколько наборов данных.
На этом уровне архитектура нашего озера выглядит так:

Здесь мы можем видеть иерархию папок и таблиц, в которую добавлен уровень веток. Именно благодаря lakeFS удалось добавить новый уровень — уровень ветки (branch). lakeFS позволяет создавать, изменять и объединять любое количество веток, поэтому мы можем:
- создавать множество копий всех таблиц без дублирования объектов;
- сохранять снэпшоты таблиц как коммиты и перемещаться между ними во времени.
Например, с помощью операции объединения можно синхронизировать обновления двух таблиц Iceberg (или даже таблиц Hudi и Iceberg) из двух разных веток в одном и том же репозитории lakeFS.
В ходе работы нередко нужно воспроизвести состояние данных для эксперимента по ML или обновить данные, которые лежат в основе критически важных сервисов. И гибкость, которую обеспечивают Git-Like-подход и lakeFS, позволяет эффективно работать в облаке даже с очень большими озерами данных.
Команда VK Cloud Solutions развивает собственные Big-Data-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.
Что почитать по теме:
