
Все чаще для сегментации изображений используется глубокое обучение и сверточные нейронные сети. В случае медицинских картинок достаточно сильно проявляются основные проблемы этого метода: не хватает робастности и интерпретируемости. Происходит это в основном из-за того, что CNN обучаются на текстуре изображения, а не на форме, или требуются дополнительные вычисления post hoc, которые, как было показано, ненадежны с точки зрения интерпретируемости.
В статье SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation авторы (Jesse Sun, Fatemeh Darbehani, Mark Zaidi, Bo Wang) предлагают добавить к модели U-Net второй поток данных о форме, а также использовать dual-attention декодер. Такой метод позволил получить очень хорошие результаты на датасетах изображений МРТ сердца SUN09 и AC17, обеспечивая высокую интерпретируемость при различных разрешениях.
Работа опирается на последние достижения в области моделей channel-attention с использованием модулей сжатия и возбуждения, предложенных Hu и др., и spatial attention c оценкой внимания, предложенных Jetley и др..
Суть подхода
ASAUNet состоит из двух потоков: texture stream и gated shape stream.

Texture stream
Текстурный поток имеет структуру U-Net, но энкодер заменен на структуру блоков из DenseNet-121, которые похожи на TiramisuNet. Также авторы предлагают декодер двойного внимания собственной разработки.
Dual attention decoder block
Этот блок объединяет карты, выдаваемые энкодером, с картами декодера с более низким разрешением, которые захватывают больше контекстной и пространственной информации.
Особенно для медицины важно понимать, основываясь на каких особенностях, модель принимает решения.
Авторы предлагают следующую структуру этого блока:
стандартная нормализованная свертка

spatial attention path
channel-wise attention path
Spatial Attention Path
Как раз используется для большей интерпретируемости решений. Состоит из двух сверток  , первая из
, первая из  каналов получает
каналов получает , вторая 1. Далее применяется сигмоида для вложения в отрезок
, вторая 1. Далее применяется сигмоида для вложения в отрезок ![[0, 1]](https://habrastorage.org/getpro/habr/upload_files/fcb/ac5/689/fcbac568973569010465780368dd3e39.svg) . Затем складываем
. Затем складываем  копий в один канал для дальнейшего умножения.
копий в один канал для дальнейшего умножения.
Channel Attention Path
Состоит из модуля сжатия и внимания, выдает коэффициент сжатия для каждого канала, затем масштабирует на него.
Gated shape stream
Второй поток обрабатывает информацию о форме и границах, используя объекты, обработанные энкодером из первого потока текстур.
На каждом шаге данные из U-Net модели передаются в Shape Stream, где вычисляется карта внимания границ  по следующей формуле:
по следующей формуле:

где  - сигмоидная функция,
- сигмоидная функция,  - конкатенация карт по каналам,
- конкатенация карт по каналам,  и
и  - feature maps из потоков,
- feature maps из потоков,  - нормализованная свертка
- нормализованная свертка  .
.
Feature map следующего слоя этого потока получают применением Residual блока, состоящего из двух нормализованных конволюций  с skip-connection, к предыдущему, поэлементно домноженному на
с skip-connection, к предыдущему, поэлементно домноженному на  :
:

Функция потерь
Состоит из обычной функции кросс энтропии и dice loss, вычисляющей перекрытие и сходство между двумя наборами.
Первая определена как

Вторая

где - количество классов, а
- количество классов, а обозначает
обозначает -й пиксель
-й пиксель -го индексированного класса матрицы
-го индексированного класса матрицы .
.
Также определим  - двоичная кросс энтропия предсказанных границ.
- двоичная кросс энтропия предсказанных границ.
Итоговая функция потерь имеет вид

где - гиперпараметры. Авторы используют их равными единице, и все работает хорошо, при этом утверждают, что если занулить один из гиперпараметров, модель плохо и медленно обучается.
- гиперпараметры. Авторы используют их равными единице, и все работает хорошо, при этом утверждают, что если занулить один из гиперпараметров, модель плохо и медленно обучается.
Эксперименты
Эксперименты проводились на двух датасетах:
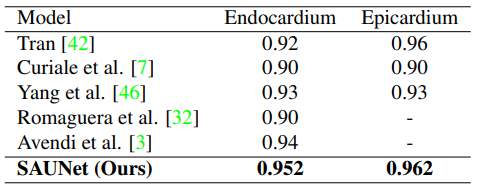
SUN09, два класса (endocardium, epicardium), всего 260 и 135 соответственно двумерных MРT кадров 128 на 128 пикселей. Все модели работали 120 эпох, с размером батча 4.
AC17, 200 наборов МРТ снимков от 100 уникальных пациентов с разрешением 256 на 256, 180 эпох.

Дополнительно авторы провели сравнение на втором датасете, подтверждающее эффективность дополнительного потока.

Итоговые оценки на датасетах получились следующие:

Интерпретируемось
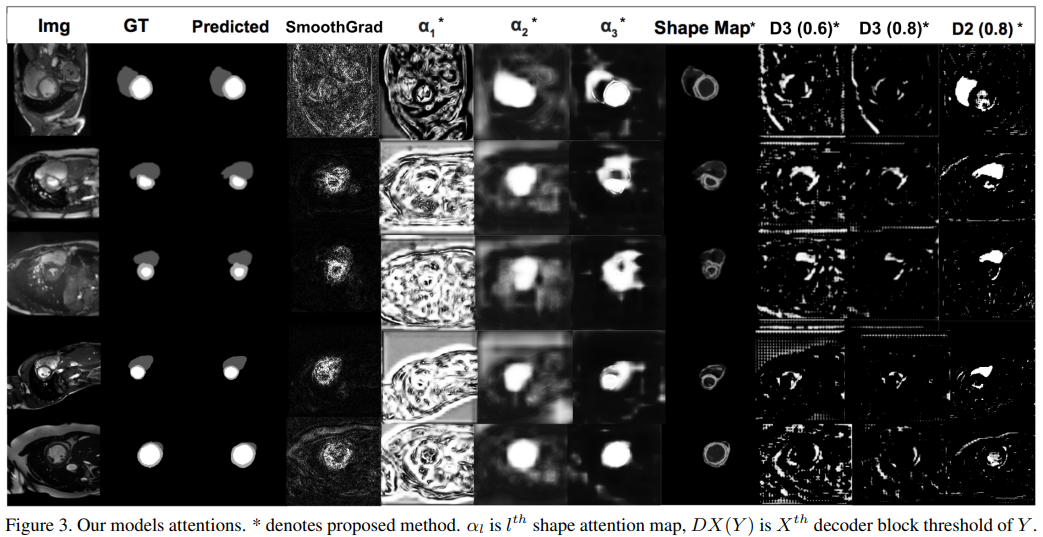
Для получения карты значимости каждого изображения с использованием модели SmoothGrad приходится прогонять модель 25-50 раз вперед-назад, из-за этого на все 384 изображения ушло 24 минуты. А для модели авторов всего 20 секунд! Кроме этого новый метод предлагает и методы определения значимости на разных уровнях и разрешениях, которые другие модели, основанные на градиенте, не предлагают.
Пример приведен ниже:
Заключение
Получилась неплохая модель, особенно учитывая, что она гораздо проще интерпретируемая, чем ее предшественники, поэтому авторы надеются, что приблизили методы глубокого обучения к клиническому применению, обещают проделать дополнительную работу по интерперетируемости.
P.S.
Этот пост написан для https://github.com/spbu-math-cs/ml-course

