
В конце 2018 года в nVidia выпустили первую StyleGAN — и сегодня любители технологий с воодушевлением смотрят в будущее безграничных развлекательных медиа, генерируемых ИИ. Это будущее на практике показывает автор, материалом которого делимся к старту флагманского курса по Data Science.
Конечно, генеративные состязательные сети применяются не только в видеоиграх. Их уже активно используют для создания видеофильтров и серьёзных анонимизированных ресурсов медицинского машинного обучения. Однако генеративные алгоритмы переменчивы, их трудно контролировать, а в выходных данных может быть полная неразбериха, если не понимать их ограничений и не уметь обращаться с ними.
Я расскажу об основных принципах латентного пространства StyleGAN3 и о трёх практических методах, в которых они используются для управления выходными данными генеративных состязательных сетей. А в конце покажу, как собрать всё это в одном конвейере, способном одной командой выдавать качественные наборы изображений. Я акцентирую внимание на практике, но для любителей математики приведу ссылки на источники.
Тема этого проекта — мои любимые интерактивные медиа и ролевые игры в японском стиле. Не будем рассматривать обучение исходной модели — на эту тему написали много статей. Возьмём две мои обученных модели StyleGAN: одну для спрайт-артов (графических объектов) персонажей, другую — для портретов в стиле аниме. Код всей этой работы выложен на GitHub, но пока я не могу поделиться ни обучающими данными, ни моделями.
Проект был бы невозможен без этой реализации StyleGAN3 и новой функциональности stylegan3-fun.
Понятие «латентное пространство»
Латентное пространство — это понятие, окутанное завесой тайны, которое часто либо чрезмерно усложняют математическими категориями, либо обходят молчанием. Между тем эту концепцию важно понимать для манипулирования входными данными таким образом, чтобы в модели постоянно выдавались изображения, соответствующие желаемым целям.
Выходные данные обученной генеративной состязательной сети не бесконечны. Создаваемые в ней изображения всегда будут соответствовать обучающим данным. Например, если сеть обучалась только на изображениях собак, то картинка с самолётом в ней никогда не сгенерируется: в модели генератора во время обучения усваивалось лишь то, что делает собаку собакой с точки зрения наблюдателя.
Но непросто бывает точно определить, как выглядит собака. Не очень-то похожи Чихуахуа и корги. Картинки с чихуахуа могут вообще оказаться редкими в наборе данных, но есть общие закономерности и признаки, по которым все породы собак обладают некоей «собачностью». В модели генеративной состязательной сети эти признаки кодируются и сводятся к набору возможных чисел. Каждый диапазон этих чисел в наборе соответствует нормальному распределению, оно также называется распределением Гаусса или кривой в форме колокола, где самые типичные признаки представлены средним значением, равным нулю, а редкие — отклоняющимися значениями. В примере с собакой кодированный признак — глаза чихуахуа, но они могут быть представлены значениями, не очень близкими к средним.
Весь набор возможных выходных данных изображения называется латентным пространством модели, а кодирование с точки зрения числового распределения — пространством z.
Обученная модель генеративной состязательной сети — детерминированная. То есть если всё время вводить в неё одни и те же входные данные, то всегда будет выводиться одно и то же изображение. Поменяв ввод модели на выборку пространства z (или вектор z), получим практически бесконечное количество выходных изображений. Эта выборка — набор случайных чисел, взятых из распределения пространства z. Поэтому изображение собаки на выходе будет, скорее всего, соответствовать тому, что закодировано вблизи средних значений распределения. Если взять все фото собак в Интернете, вероятно, это будет что-то с сильно выраженными признаками корги. Глаза чихуахуа появятся лишь иногда — вероятность их попадания из распределения в выборку меньше.

Конечно, пример собаки с пронзительным взглядом — это сильное упрощение настоящего принципа работы латентного пространства, потому что ни одно число в наборе возможных чисел никогда не будет отображаться так чётко. Не хотелось бы получить результат, который выглядит как хаски с этими глазами чихуахуа. Каждое число в пространстве z, следовательно, случайно выбранный вектор z взаимосвязаны с остальными. Из-за этого глаза чихуахуа обычно будут появляться, только когда у собаки обнаружатся и другие признаки чихуахуа. Анализ того, что именно привносится каждым случайным значением в конечное изображение, — сложная задача.
В модели StyleGAN эта проблема интерпретации решается введением пространства w, то есть промежуточного представления между пространством z и выходными данными изображения. Оно состоит из упорядоченного ряда матриц чисел, которые опять же представляют кодированные в модели специфические признаки. Однако, в отличие от пространства z, пространство w интерпретируется человеком. Каждая матрица в пространстве w соответствует какому-то аспекту или стилю конечного выходного изображения. Нижние матрицы представляют фундаментальные аспекты выходных данных. В примере с собакой эти слои, вероятно, будут сопоставляться с такими аспектами, как положение тела или порода собаки. Средние слои представляют менее фундаментальные аспекты выходных данных, такие как размер носа или мимика собаки. Наконец, верхние слои соответствуют более мелким деталям, таким как цвет шерсти собаки или освещение изображения. Начиная со StyleGAN3 слоёв матриц (с метками от 0 до 15) — всегда 16.
Качество через трюк с усечением
Простейший способ управления выходными данными модели — применение трюка с усечением. Как говорилось ранее, в пространстве z типичные признаки кодируются ближе к средним значениям, а редкие — дальше от них. Модель часто можно обучить признакам, бесполезным для тех, кто смотрит на выходное изображение. К счастью, они редки, а потому кодируются в значениях, не близких к средним. Благодаря трюку с усечением при ограничении диапазона, который может попасть в выборку при случайном выборе из пространства z, странные или редкие признаки не выбираются никогда. Однако, как и всё в машинном обучении, этот метод требует тщательной настройки. Если отсечь слишком много, все выходные данные будут выглядеть одинаково и применение генеративной сети потеряет всякий смысл.
Хотя в большинстве генеративных состязательных сетей трюк с усечением применяется непосредственно к выборке пространства z, в реализации StyleGAN3 он применяется к значениям пространства w после выбора вектора z. Здесь трюк с усечением задаётся через переменную truncation_psi. Использование значения ниже 1,0 приведёт к более стандартным и единообразным результатам, выше 1,0 — к необычным примерам отклоняющихся значений:
for i in range(4): w1 = get_w_from_seed(G,device,seed=i,truncation_psi=1.5) w2 = get_w_from_seed(G,device,seed=i,truncation_psi=0.7) img1 = w_to_img(G,w1,’none’) img2 = w_to_img(G,w2,’none’)

Поиск подходящего смешения стилей
Ранее я объяснял, что слои пространства w соответствуют определённым аспектам выходного изображения, но что это нам даёт? Кодированная информация слишком сложна, чтобы пытаться манипулировать ею вручную. Лучшее решение, которое я знаю, — это смешение стилей.
Оно намного проще, чем может показаться. Нужно только найти изображение с понравившимися аспектами и взять из него связанный с ними слой выборки пространства w. Этот слой потом можно использовать, чтобы либо перезаписать соответствующий слой нового изображения, либо вывести из них средний. Это смешение может выполняться с одним или несколькими слоями одновременно. Можно даже подмешать несколько других слоёв и вовсе из разных изображений, если у выходных данных требования сложнее:
truncation_psi = 0.7 w_avg = G.mapping.w_avg w_list = [] for i in range(4): z = np.random.RandomState(i).randn(1, G.z_dim) w = G.mapping(torch.from_numpy(z).to(device), None) w = w_avg + (w — w_avg) * truncation_psi w_list.append(w) w_base = w_list[0].clone() for i in range(1,4): w_base[:,:7,:] = (w_list[i][:,:7,:]+w_base[:,:7,:])*.5 img1 = w_to_img(G,w_base,’none’) w_base[:,:7,:] = w_list[i][:,:7,:] img2 = w_to_img(G,w_base,’none’)

w_base = w_list[0].clone() for i in range(1,4): w_base[:,8:,:] = (w_list[i][:,8:,:]+w_base[:,8:,:])*.5 img1 = w_to_img(G,w_base,’none’) w_base[:,8:,:] = w_list[i][:,8:,:] img2 = w_to_img(G,w_base,’none’)

Данный метод смешения стилей позволяет включить в конечное изображение нужные характеристики или стили. В этом примере видеоигры можно быть уверенным, что у случайно сгенерированного злодея глаза всегда прищурены, а у юного героя всегда счастливая улыбка. Можно было бы даже определить конкретный стиль оформления, например акварель или поп-арт. Нужно только перенести желаемые стили с изображения.
Проекция латентного пространства
Выше было сказано, что нужно лишь найти слои выборки пространства w понравившегося изображения. Но это просто, только если это изображение — уже результат той же модели. Метод нахождения представления латентного пространства изображения, не связанного с моделью, называется проекцией.
Эта проекция используется для поиска близкого представления данного изображения в латентном пространстве модели генеративной состязательной сети. К сожалению, это не такой простой метод, как описанные выше. Он связан с времязатратным поиском с элементом случайности. Есть много способов решения этой задачи. Применяемый здесь код я заимствовал отсюда.
Этот метод концептуально сложнее двух предыдущих, но ему для хорошей работы в соответствии с нашими целями, к счастью, нужно не так много. Главное — следует учесть, что поиск ведётся в латентном пространстве модели, построенной для конкретного типа изображения. Если искать в модели для собак проекцию самолёта, результаты хорошими не будут. Чем ближе входное изображение данным модели, тем лучше будет найденное в латентном пространстве представление. Кроме того, чтобы получить хорошее соответствие, нужно время, поэтому лучше применять этот метод вне целей реального времени.
Попробуем получить нужные стили при помощи выборки пространства w из примера проекции. Поскольку конечная цель — создать юную героиню для RPG в японском стиле, возьмём в качестве классического примера девочку-волшебницу Мадоку Канамэ:
python projector.py --network=models/face_GAN.pkl \ --target=data/wide_eye.png --num-steps=3000 --outdir=projections \ --stabilize-projection --vgg-normed

Я подготовил нарисованное человеком изображение (слева), очистив обучающие данные модели лица. Изображение справа — это проекция латентного пространства с применением этой обученной модели. Проекция не идеальна, но это не важно, ведь нужны только стили пространства w — для данного примера это разрез глаз и выражение лица.
В коде выводятся все 16 слоёв пространства w. Они в файле .npy, просто загружаем его и извлекаем нужные слои: 6 и 7.
w_input_loc = ‘models/wide_eye_w.npy’ input_w = _parse_cols(w_input_loc, G, device, 0.7) for i in range(4): w = get_w_from_seed(G,device,i,0.7) output_w = w.clone() output_w[:,6,:] = input_w[:,6,:] output_w[:,7,:] = input_w[:,7,:] img_in = w_to_img(G,w,’none’) img_out = w_to_img(G,output_w,’none’) display(PIL.Image.fromarray(img_in.squeeze(0), ‘RGB’)) display(PIL.Image.fromarray(img_out.squeeze(0), ‘RGB’))

Понадобятся и другие персонажи, так что сделаем выражения лица соперницы нашей героини. Оставляем разрез глаз и выбираем другую девочку-волшебницу — личного врага Мадоки, Акеми Хомуру:
python projector.py --network=models/face_GAN.pkl \ --target=data/narrow_eye.png --num-steps=3000 --outdir=projections \ --stabilize-projection --vgg-normed

На этот раз проекция выглядит ещё лучше! Посмотрим, как она сопоставляется со случайно сгенерированными лицами:
w_input_loc = ‘models/narrow_eye_w.npy’ input_w = _parse_cols(w_input_loc, G, device, 0.7) for i in range(4): w = get_w_from_seed(G,device,i,0.7) output_w = w.clone() output_w[:,6,:] = input_w[:,6,:] output_w[:,7,:] = input_w[:,7,:] img_in = w_to_img(G,w,’none’) img_out = w_to_img(G,output_w,’none’) display(PIL.Image.fromarray(img_in.squeeze(0), ‘RGB’)) display(PIL.Image.fromarray(img_out.squeeze(0), ‘RGB’))

Идеально. Глаза по-прежнему большие (для сохранения стиля оформления), а выражение лица явно отличается от предыдущих.
Цвета темнеют из-за того, что выражение лица встроено в слой 7, хотя они в целом соответствуют верхним слоям. Это логично, ведь многие рисунки в обучающем наборе с похожим выражением лица обладают более тёмной палитрой. Несмотря на то, что стили разделены слоями пространства w, ещё могут находиться стили, трудно отделимые друг от друга.
Выбор слоёв 6 и 7 для выражения лица определился путём многочисленных проб и ошибок. Чёткого сопоставления (какой слой пространства w влияет на конкретный аспект конечного результата) нет, кроме общего уровня детализации по порядку слоёв. Чтобы увидеть результаты, для каждой обучаемой модели StyleGAN нужно провести смешение слоя за слоем. В официальном репозитории StyleGAN3 на GitHub есть инструмент visualizer.py для быстрого сравнения смешения двух векторов z слоем пространства w.
Конвейеризация проекта
Теперь у нас есть всё, чтобы автоматически создавать персонажей! В традиционной японской RPG есть два типа игровых ассетов для персонажей: их анимированные спрайты и портреты. До сих пор во всех моих примерах использовалась портретная модель — так легче интерпретировать каждый метод. Дальше подключим её к генератору спрайт-артов.
В этой второй генеративной состязательной сети выдаются изображения одного и того же персонажа в 12 различных ракурсах. Так делается анимация походки. Этот формат хорошо сочетается с RPG Maker MV, простым программным обеспечением создателя видеоигр.
Вот блок-схема финального конвейера проекта персонажей нашей видеоигры:
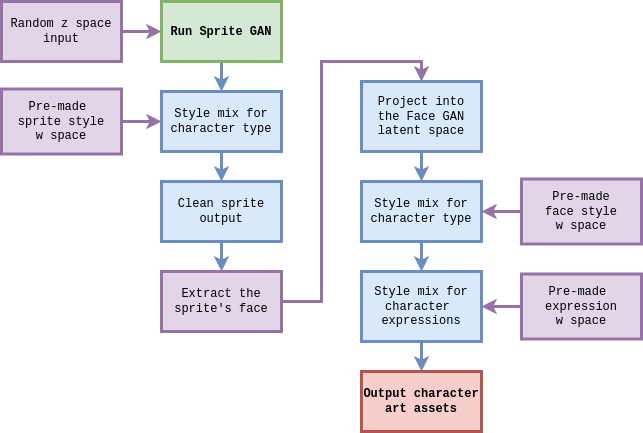
Рассмотрим все результаты с примерами тестового запуска персонажа юной героини. Сначала запускаем модель генерации спрайтов с автоматически созданным случайным вектором z. Затем смешиваем стили этого результата, используя выборку пространства w проекции, заранее сделанную для персонажа с подходящими пропорциями. Наконец, этот результат смешения стилей очищается и готовится к применению в игре:
python generate_character.py heroine 0.6

Первоначальный случайный результат выглядит как мальчик в доспехах, но после смешения стилей превращается в юную героиню, сохраняя при этом цветовые аспекты. Это не прямое преобразование, подобное тому, что было у модели, лица, но на данном этапе достаточно случайного результата, похожего на девочку.
Дальше мы просто обрезаем и увеличиваем верхний центральный спрайт, акцентируя внимание на её голове. Затем, чтобы получить примерное представление о том, как будет выглядеть наш персонаж согласно портретной модели, прогоняем этот результат через проектор латентного пространства генеративной состязательной сети лица:

Результат на этом этапе, конечно, не стоит отправлять в продакшен, но это один из улучшенных примеров результатов после применения проекции. Результат не того же качества, что у других проекций, по двум причинам. Во-первых, он получается от типа изображения, которого в генеративной состязательной сети лица никогда раньше не было. Его блоковая структура не соотносится ни с какими известными признаками. Во-вторых, мы запускаем эту проекцию на гораздо меньшее время: всего 200 этапов по сравнению с 3000 для проекций вне конвейера. Этот процесс будет запускаться много раз (в отличие от других, одноразовых), поэтому важна скорость. К тому же при следующем смешении стилей работы будет намного больше. В примере с выражением лица при смешении использовалось всего два слоя, но на основе проекции посложнее будет перезаписано больше слоёв: 0, 2, 6, 7 и 8. Здесь нужно сохранить только цвета, форму волос и общее положение тела:

Это лицо выглядит намного лучше. Но для настоящей игры этого недостаточно. Лицо персонажа должно выражать различные эмоции в диалогах. Этот результат принимается конвейером, где выполняется ряд целевых смешений с другими заранее подготовленными выборками пространства w, которыми кодируются нужные выражения лица:

Сколько арта сделано одним нажатием кнопки! Конечно, не обошлось без странностей: счастливое лицо получилось жутковатым, а волосы будто бросают вызов гравитации. Для этого запуска я задал всем выходным данным значение truncation_psi, равное 0,6. Так сохраняется согласованность, но до идеала ещё далеко. Возьмём ещё небольшой пример, применив более строгий трюк с усечением. На этот раз выведем другого персонажа:
python generate_character.py villain 0.4


Лица получились хорошо: глаза выглядят симметричнее, рот — естественнее. К сожалению, гораздо меньше они похожи на исходный спрайт. Зелёные волосы в латентном пространстве генеративной состязательной сети лица встречаются редко, поэтому при усечении преобладающим цветом результата стал чёрный. Причёска тоже больше похожа на типичный результат модели, чем на проекцию. В связи с этим возникает самый большой вопрос, на который необходимо дать ответ при использовании генеративных состязательных сетей, предназначенных для выдачи случайного контента. Что важнее: разнообразие или качество? Этот выбор придётся делать всегда, если вам нужны согласованные результаты для чего-то большего, чем демоверсия продукта.
Надеюсь, в этой статье вы зарядились идеями применения генеративных состязательных сетей в реальных ситуациях с использованием конвейеризации корректировок признаков, чтобы получать идеальный случайный результат.
Дайте знать, как вы планируете применять генеративные алгоритмы для решения своих задач!
Дополнительные ресурсы
Keywords to know before you start reading papers on GANs («Ключевые слова, которые нужно знать, прежде чем читать работы о генеративных состязательных сетях»): ещё один ресурс, в котором простыми словами описываются латентное пространство и смешение стилей.
Understanding Latent Space in Machine Learning («Понятие о латентном пространстве в машинном обучении»): чуть более глубокий взгляд на концепцию латентного пространства в целом.
StyleGAN v2: notes on training and latent space exploration («StyleGAN v2: заметки об изучении латентного пространства и обучении модели»).
DeepLearning.AI’s Generative Adversarial Networks (GANs) Specialization («Глубокое обучение. Специализация генеративных состязательных сетей ИИ»): это лучший найденный мной ресурс (платный курс Coursera) для начала работы с генеративными состязательными сетями (и к которому автор не имеет никакого отношения).
А пока автор создаёт свою игру с помощью ИИ, мы поможем вам прокачать скиллы или с самого начала освоить профессию, актуальную в любое время.
Выбрать другую востребованную профессию.


