Введение
Общеизвестно, что в хранилищах данных для связи таблиц фактов со справочниками используются суррогатные ключи. В большинстве случаев это целочисленный счетчик, который взаимно однозначно определяет бизнес ключ (или бизнес ключ плюс зависимость от времени для медленно меняющихся справочников). С увеличением объемов обрабатываемой информации в случае большой кардинальности справочников использование счетчиков в качестве суррогатных ключей становится проблемой с точки зрения производительности, т.к. при загрузке фактов необходимо определить значение суррогатного ключа по довольно большому справочнику. Для решения этой проблемы многие компании переходят на формирование суррогатных значений на основе хеш-значений бизнес-ключей. Очень подробно такой подход описан в докладе Евгения Ермакова и Николая Гребенщикова о модели данных хранилища Яндекс Такси (Евгений Ермаков, Николай Гребенщиков — Highly Normalized Hybrid Model - YouTube)
Однако, при использовании хеш-значений в качестве суррогатного ключа, могут возникать коллизии, когда для разных значений бизнес-ключа хеш-функция дает одно и тоже хеш-значение суррогатного ключа. Количество коллизий зависит от кардинальности справочника и выбранной хеш-функции, но в любом случае остается.
В явном виде с этой проблемой мы столкнулись в одном из тендерных запросов и позже в реальном проекте в результате чего, стало понятно, что было здорово выработать какое-то шаблонное решение, тем более, что быстрый поиск по просторам интернета готового решения не дал.
Постановка задачи
В общем случае на входе имеется массив данных, который необходимо загрузить в целевую таблицу фактов, заменив бизнес-ключи на суррогатные для связки со справочниками.
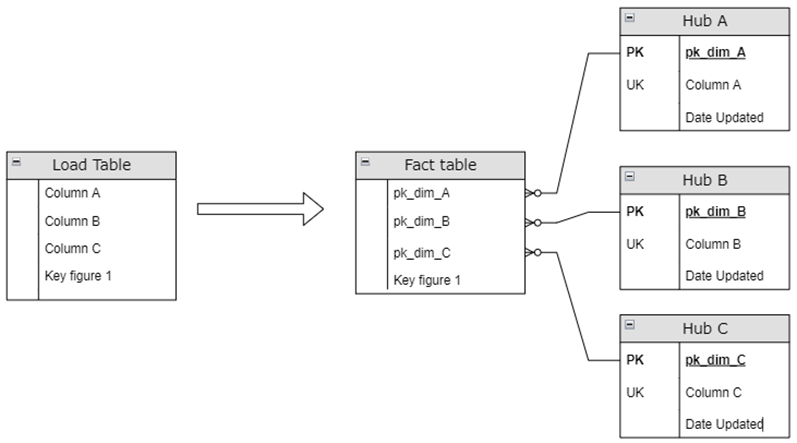
В условиях, когда значительная часть значений справочников формируется на основе данных фактов, формирование справочников с суррогатными ключами на основе хеш-значений можно осуществлять параллельно с загрузкой фактов. Многие компании так и делают, пренебрегая возможными коллизиями, как ничтожно малыми.
Очень часто в качестве хеш-функции используют алгоритм MD5, который дает низкую вероятность дублей значений, но на выходе у него получается строка в 32 символа, что не оптимально с точки зрения хранения данных и использования в качестве ключа связи. Небольшое обсуждение по опыту использования данных алгоритмов хеширования можно найти по ссылке: https://www.sql.ru/forum/1266277/hash-vs-surrogate-keys
СУБД Oracle 11.2g имеет встроенную функцию хеширования ORA_HASH(), которая на выходе дает целое число, однако имеет заметную вероятность получения дублей значений. Если решить проблему с дублями, то ее можно будет использовать для генерации суррогатных ключей.
Предлагаемое решение
Формирование справочника
Общая идея в формировании справочника с суррогатными ключами на основе хеш-функции с обработкой коллизий заключалась в том, что для большинства значений справочника используется значения хеш-функции, принимающие положительные значения, а для дублей – используются счетчик значений в отрицательной области. Таким образом пространства возможных значений не пересекаются, что исключает дубли.
Для демонстрации реализации этой идеи нам потребуются следующие таблицы:
| Таблица SRC – наш входной поток данных, который в самом простейшем случае содержит только бизнес-ключ Bkey, для которого мы хотим рассчитать суррогатный ключ |
| Таблица TMP – таблица со временными данными, в которую попадают только те бизнес-ключи, которых нет в целевом справочнике HUB, в рамках одного цикла загрузки. Т.е. это дельта, для которой необходимо сгенерировать суррогатный ключ. Поля таблицы: Bkey – бизнес ключ Hkey – хеш-значение бизнес-ключа Hkey_qty – порядковый номер хеш-значения для бизнес ключа внутри дельты Skey – суррогатный ключ для дубля, рассчитанный через последовательность/счетчик, имеющий отрицательное значение. |
| Таблица HUB – наш целевой справочник, который в самом простом виде содержит первичный ключ Pk_bkey и бизнес-ключ Bkey. Множество значений первичного ключа является объединением множеств значений Hkey и Skey. |
| Таблица Excl – таблица исключений, содержащая суррогатные ключи для дублей бизнес-ключей. Используется при загрузке фактов. |




На диаграмме ниже представлен алгоритм формирования справочника, реализующий подход, описанный выше.
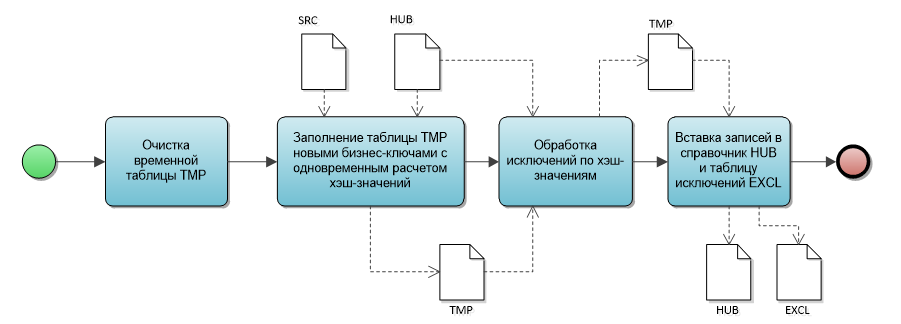
На первом шаге мы очищаем нашу временную таблицу.
На втором шаге осуществляется вставка записей из входного потока SRC во временную таблицу TMP по тем бизнес-ключам, который отсутствуют в целевом справочнике HUB. При заполнении идет расчет хеш-значений бизнес-ключа и для тех бизнес-ключей, которые имеют дубли на данных входного потока, рассчитывается ключ-исключения на основе последовательности.
Пример запроса:
INSERT INTO tmp (bkey, hkey, hkey_qty, skey) SELECT DISTINCT bkey, ORA_HASH(bkey) as hkey, DENSE_RANK() OVER (PARTITION BY ORA_HASH(bkey) ORDER BY bkey) as HKEY_QTY, CASE WHEN DENSE_RANK() OVER (PARTITION BY ORA_HASH(bkey) ORDER BY bkey) > 1 THEN -1* seq_excl.nextval END as skey FROM src WHERE bkey IS NOT NULL AND not in (SELECT bkey FROM hub)
На третьем шаге мы проверяем, есть ли дубли хеш-значений для новых записей по отношению к тем записям, которые уже есть в справочнике HUB. Для таких записей рассчитывается ключ-исключения на основе той же последовательности.
Пример запроса:
UPDATE tmp SET tmp.hkey_qty = hkey_qty + 1, tmp.skey = -1* seq_excl.nextval WHERE tmp.skey is null and tmp.hkey in (select pk_bkey from hub)
В результате выполнения третьего шага в таблице TMP для всех новых бизнес ключей рассчитаны хеш-значения, а для дублей сгенерированы значения ключей-исключений и все готово для финального шага – вставки записей в целевые таблицы.
На четвертом шаге осуществляется вставка записей в целевой справочник HUB и таблицу исключений EXCL.
Пример запроса:
INSERT INTO hub (pk_bkey, bkey) SELECT nvl(skey, hkey) as pk_bkey , bkey FROM tmp; INSERT INTO EXCL (bkey, skey) SELECT bkey, skey FROM tmp WHERE skey is not null;
Загрузка фактов
Теперь, когда сформирована таблица исключений EXCL, загрузка фактов из источника (назовем его LOADF) с привязкой к справочнику HUB может осуществляться без обращения к этому справочнику с помощью запроса:
INSERT INTO fact (pk_bkey, …) SELECT nvl(EXCL.skey, ORA_HASH(LOAD.bkey)) AS pk_bkey , … FROM LOADF LEFT JOIN EXCL ON (EXCL.bkey = LOADF.bkey);
Опыт применения
Описанный выше подход был опробован в одном из проектов по оптимизации имеющейся структуры хранилища данных по данным кликов (визитов) интернет магазина.
До оптимизации в хранилище данных загружались строки визитов, которые парсились и результаты парсинга записывались непосредственно в таблицу фактов в соответствующие колонки вместе с исходной строкой.
Например, из строки вида:
Колонка | Значение |
url | /katalog/bumaga-i-bumazhnye-izdeliya/bumaga-dlya-ofisnoj-tekhniki/formatnaya-bumaga/c/135000/?sort=price-asc&listingMode=GRID&sortingParam=price-asc&email=polydkinamargo%40mail.ru&sc_src=email_5359903&sc_lid=321430171&sc_uid=ipz4a29dvS&sc_llid=16237&sc_eh=53cbe15b802f05341&utm_source=mailing1-mail-ems-v4&utm_campaign=20220419_1709_mailing1-priyatnyye_syurprizy_20220418-b2c-op_z1-nbr-ntr-ntm-v4&utm_term=B2C&utm_medium=%D0%91%D1%83%D0%BC%D0%B0%D0%B3%D0%B0+%D0%904+%D0%BF%D0%BE+%D1%81%D1%83%D0%BF%D0%B5%D1%80%D1%86%D0%B5%D0%BD%D0%B5&utm_content=Akcion_block |
Формировалась строка вида:
Колонка | Значение |
url | /katalog/bumaga-i-bumazhnye-izdeliya/bumaga-dlya-ofisnoj-tekhniki/formatnaya-bumaga/c/135000/?sort=price-asc&listingMode=GRID&sortingParam=price-asc&email=polydkinamargo%40mail.ru&sc_src=email_5359903&sc_lid=321430171&sc_uid=ipz4a29dvS&sc_llid=16237&sc_eh=53cbe15b802f05341&utm_source=mailing1-mail-ems-v4&utm_campaign=20220419_1709_mailing1-priyatnyye_syurprizy_20220418-b2c-op_z1-nbr-ntr-ntm-v4&utm_term=B2C&utm_medium=%D0%91%D1%83%D0%BC%D0%B0%D0%B3%D0%B0+%D0%904+%D0%BF%D0%BE+%D1%81%D1%83%D0%BF%D0%B5%D1%80%D1%86%D0%B5%D0%BD%D0%B5&utm_content=Action_block |
cat_lvl_1 | katalog |
cat_lvl_2 | bumaga-i-bumazhnye-izdeliya |
cat_lvl_3 | bumaga-dlya-ofisnoj-tekhniki |
cat_lvl_4 | formatnaya-bumaga |
utm_source | mailing1-mail-ems-v4 |
utm_campaign | 20220419_1709_mailing1-priyatnyye_syurprizy_20220418-b2c-op_z1-nbr-ntr-ntm-v4 |
utm_term | B2C |
utm_medium | Бумага А4 по суперцене |
utm_content | Action_block |
В результате рефакторинга было предложено:
разделить таблицу фактов, выделив малоиспользуемые широкие исходные поля в отдельную таблицу (в приведенном примере это поле URL);
логически сгруппировать поля, получаемые в результате парсинга в справочники с генерацией суррогатных ключей на основе хэш-значений (в примере выше выделены справочники структур каталога страниц сайта - Cat_lvl_1, Cat_lvl_2, Cat_lvl_3, Cat_lvl_4 и справочник маркетинговых акций - utm*).
В итоге большинство аналитических запросов стало выполняться по значительно более «узкой» таблице фактов и одновременно за счет выделения справочников было сокращено на 30% занимаемое место на дисках.
С учетом того, что в качестве СУБД для хранилища использовалась не колоночная Oracle 11.2g полученный выигрыш был значительным.
Вот несколько цифр:
№ | Тип операции | Описание операции | Время выполнения операции - До | Время выполнения операции - После |
1 | Загрузка данных | Слой Stage | 25 мин | 69 мин |
2 | Загрузка данных | Слой DDS | 71 мин | 10 мин |
3 | Загрузка данных | Полная загрузка данных до целевых объектов | 96 мин | 84 мин |
4 | Выполнение sql-запроса | Количество операций за день | 2731 сек | 6 сек |
5 | Выполнение sql-запроса | Количество операций за календарную неделю | 2864 сек | 10 сек |
6 | Выполнение sql-запроса | Выполнение регламентного отчета с выборкой данных за календарную неделю | 980 сек | 281 сек |
Заключение
Описанное решение:
гарантирует уникальность генерируемых суррогатных ключей для входных бизнес-ключей;
позволяет использовать метод как при полной перезагрузке данных, так и дельта-загрузке;
имеет лучшую производительность при загрузке объемных таблиц фактов за счет отсутствия необходимости связывания непосредственно со справочниками для определения суррогатного ключа.
Вместе с тем, описанный алгоритм в общем виде не позволяет загружать справочники и факты в параллель, так как при загрузке фактов используется таблица исключений для дублей хеш-значений. Однако при параллельной загрузке он более точен по сравнению с загрузкой с использованием хеш-значений без обработки исключений. Более того, если природа данных позволяет перегружать дельту по фактам за два последних такта загрузки, то ошибки, вызванные коллизиями будут исправляться.

