
На kotlin для работы с базами я использую библиотечку JOOQ. У неё хороший генератор кода и достаточно вменяемый синтаксис для составления запросов. Вот например:
dsl.selectFrom(Tables.ANIMALS) .where(Tables.ANIMALS.POPULATION.greaterThan(1000)) .orderBy(Tables.ANIMALS.NAME) .map { "${it.name}: ${it.population}" } .toList()
Можно ли лучше? Например, как это сделано в C# LINQ?
Да, можно. Вот рабочий код:
dsl.selectQueryableFrom(Tables.ANIMALS) .filter { it.population > 1000 } .sortedBy { it.name } .map { "${it.name}: ${it.population}" } .toList()
А вот SQL запрос, который отправляется в базу в результате этого вызова:
select (("ANIMALS"."NAME" || ': ') || cast("ANIMALS"."POPULATION" as varchar)) "col0" from "ANIMALS" where "ANIMALS"."POPULATION" > 1000 order by "ANIMALS"."NAME" asc
Дальше я расскажу, как это работает.
Как это выглядит и работает в C#
Вот простой пример кода. Есть 2 функции, одна принимает Func, другая - Expression. В обе можно передать одну и ту же лямбду.
internal class Program { static void ReceiveLambda(Func<int, int> lambda) { Console.WriteLine(lambda(2)); // (1) Console.WriteLine(lambda); // (2) } static void ReceiveExpression(Expression<Func<int, int>> lambda) { Console.WriteLine(lambda.Compile()(2)); // (1) Console.WriteLine(lambda); // (2) } public static void Main(string[] args) { ReceiveLambda(it => it * 2); ReceiveExpression(it => it * 2); } }
Если переданную лямбду просто выполнить (строчки помеченные как (1)), то результат будет одинаковым - выведется 4.
Но если вывести саму лямбду (строчки помеченные как (2)), то результат будет отличаться. Метод, принимающий Func, выведет
System.Func`2[System.Int32,System.Int32]
А метод, принимающий Expression, выведет:
it => (it * 2)
И вот как это выглядит в отладчике:
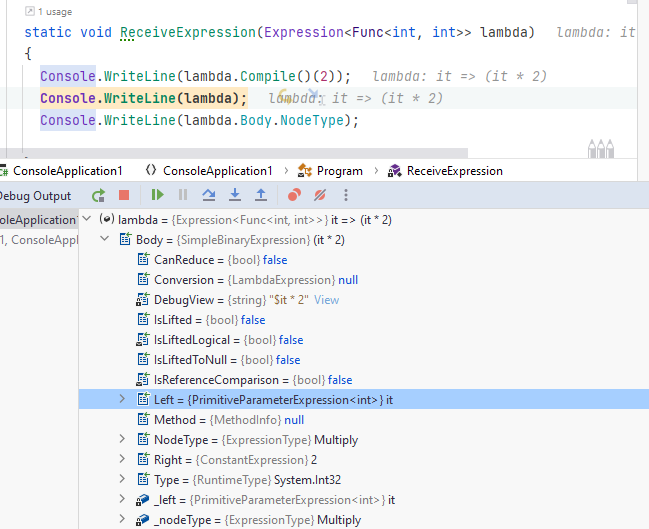
Компилятор C# знает, что если метод принимает Expression, то надо передать в него не просто исполняемую функцию, а AST. Это позволяет во время исполнения анализировать используемую лямбду, брать из неё значения, имена вызываемых методов и т.д. Эта особенность позволяет писать код вроде:
//Querying with LINQ to Entities using (var context = new SchoolDBEntities()) { var query = context.Students .where(s => s.StudentName == "Bill") .FirstOrDefault<Student>(); }
И дальше его можно как выполнить над коллекцией в памяти, так и преобразовать в SQL.
Можно почитать об этом тут на хабре: https://habr.com/ru/post/256821/
В Kotlin/JVM такого нет. Лямбды при компиляции превращаются в анонимные классы или статические методы, в рантайме их изначальное содержимое неизвестно. Да, в теории мы можем посмотреть в байткод, но байткод может сильно отличаться от исходного листинга в силу оптимизаций.
Например, вот такое выражение на kotlin:
val a = maxOf(2, 3)
При компиляции в байткод и де-компиляции обратно в java (для наглядности) превратится вот в такое:
byte var2 = 2; byte var3 = 3; final int a = Math.max(var2, var3);
Исходное название функции “потерялось”, т.к. функция maxOf объявлена как inline.
А такое выражение:
val b = if (arrayOf(3).isEmpty()) 5 else 6
Превращается вот в такое:
Integer[] var2 = new Integer[]{3}; final int b = var2.length == 0 ? 5 : 6;
Да, эти примеры искусственны, но в общем случае мы не можем быть уверены, что из байткода мы 100% восстановим то, что было написано в kotlin коде. А это именно то, что программист видит перед собой, и именно это он ожидает увидеть в AST.
Значит, нужно:
Достать AST из лямбды на этапе компиляции
Подсунуть этот AST в код, однозначно ассоциировав с конкретной лямбдой
Начнём по порядку.
Извлечение AST из исходного кода
Беглый гуглёж нашёл две наиболее часто упоминаемых библиотеки.
Одна из них - kastree - заброшена. Вторая - ast - выглядит живой. При подаче на вход простого kotlin кода получаем что-то такое:
fun main() { KotlinGrammarAntlrKotlinParser.parseKotlinFile(AstSource.String("", """ val d = { it > 5 } """.trimIndent())).print() }
Результат
kotlinFile packageHeader importList topLevelObject declaration propertyDeclaration VAL >>>val<<< (DEFAULT_TOKEN_CHANNEL) WS >>> <<< (HIDDEN) variableDeclaration simpleIdentifier Identifier >>>d<<< (DEFAULT_TOKEN_CHANNEL) WS >>> <<< (HIDDEN) ASSIGNMENT >>>=<<< (DEFAULT_TOKEN_CHANNEL) WS >>> <<< (HIDDEN) expression disjunction conjunction equality comparison genericCallLikeComparison infixOperation elvisExpression infixFunctionCall rangeExpression additiveExpression multiplicativeExpression asExpression prefixUnaryExpression postfixUnaryExpression primaryExpression functionLiteral lambdaLiteral LCURL >>>{<<< (DEFAULT_TOKEN_CHANNEL) WS >>> <<< (HIDDEN) statements statement expression disjunction conjunction equality comparison genericCallLikeComparison infixOperation elvisExpression infixFunctionCall rangeExpression additiveExpression multiplicativeExpression asExpression prefixUnaryExpression postfixUnaryExpression primaryExpression simpleIdentifier Identifier >>>it<<< (DEFAULT_TOKEN_CHANNEL) WS >>> <<< (HIDDEN) comparisonOperator RANGLE >>>><<< (DEFAULT_TOKEN_CHANNEL) WS >>> <<< (HIDDEN) genericCallLikeComparison infixOperation elvisExpression infixFunctionCall rangeExpression additiveExpression multiplicativeExpression asExpression prefixUnaryExpression postfixUnaryExpression primaryExpression literalConstant IntegerLiteral >>>5<<< (DEFAULT_TOKEN_CHANNEL) WS >>> <<< (HIDDEN) RCURL >>>}<<< (DEFAULT_TOKEN_CHANNEL) semis EOF >>><EOF><<< (DEFAULT_TOKEN_CHANNEL) EOF >>><EOF><<< (DEFAULT_TOKEN_CHANNEL)
Многословно, но разобраться можно. Главное, что лямбды хорошо выделяются.
В теории, можно было бы использовать это дерево как есть. Но мне оно показалось слишком многословным и сложным. Особенно если потом его в рантайме пытаться разобрать. Хорошо бы вот такая конструкция превращалась в дерево из 3х узлов, как в C#, а не 300.
Потратив некоторое время на упрощатор, получилось превращать простые лямбды в такие вот деревья.
Greater( LambdaArgument(number=0), Value(value=5) )
Казалось бы, задача решена? Не совсем. Что если нам в лямбдах попадаются:
константы
локальные переменные
приватные поля
конструкторы классов?
Например, вот так:
val one = 1 val d = { it > one }
Greater( LambdaArgument(number=0), Identifier(name=one) )
Когда мы находимся на этапе парсинга кода, то мы, увы, не имеем доступа к рефлексии или вообще какой бы то ни было модели исполняемого кода. У нас есть только имя, а что оно означает - неизвестно. Если бы мы были внутри компилятора, то наверное у нас эта информация была бы. Но мы пока снаружи.
Пока что придётся вставлять это всё как идентификаторы без конкретного смысла. Вернёмся к этой проблеме позже. А пока поймём, как нам эту информацию сохранить на этапе компиляции и использовать в рантайме.
В идеале нам нужно сделать так, чтобы вместо кода
filter { it > 5 }
Стало
filter({it > 5} withExpression Greater(LambdaArgument(0), Value(5)))
Runtime. Попытка 1 (через KSP и ориентирование по именам классов)
Гуглёж по тому, как встроиться в процесс компиляции, приводит нас к kapt, а оттуда, через уведомление об устаревании этого способа, к KSP. Про него есть хорошая статья тут на хабре.
Сначала всё хорошо - можно получить информацию о классах, сгенерировать свои и подсунуть. Поддерживается инкрементальная компиляция, т.е. если kotlin пересобрал 1 файл, то и нам он закинет 1 файл на обработку.
Проблема в том, что таким образом можно создавать новые файлы, но нельзя менять существующие. То есть первоначальная цель недостижима. Что можно было попробовать сделать - это сохранить AST отдельно. А адресовать с помощью имени класса - как мы видим из байткода, все лямбды превращаются в классы с уникальными именами. А имена у них генерируются по некоему правилу, которое можно воссоздать.
Таким образом я написал реализацию SymbolProcessor для KSP, которая:
Для каждого source файла, который надо обработать, генерирует отдельный класс, сопоставляющий класс лямбды и выражение:
@LambdaExpressionInitializer class `io_github_kotlinq_processortest`: Initializer { override fun initialize(e: Expressions) { e.registerFactory("io.github.kotlinq.processor.A\$qso\$1") { Greater(LambdaArgument(0),Identifier("""r1""") ) } e.registerFactory("io.github.kotlinq.processor.A\$qso\$2") { Plus(Plus(LambdaArgument(0),LambdaArgument(1)),Identifier("""r2""") ) } e.registerFactory("io.github.kotlinq.processor.A\$stream\$1") { Greater(LambdaArgument(0),Plus(Identifier("""r2""") ,Value(2))) } } }
Чтобы классы нашлись в рантайме, когда надо, так же генерирую
META-INF/services/<мой интерфейс>, где перечисляю все сгенерированные файлы.В рантайме я использую
ServiceLoader, чтобы получить все реализации моего интерфейса. Про этот механизм в java тоже были статьи на хабре: https://habr.com/ru/post/118488/
object Expressions { fun registerFactory(className: String, expressionFactory: ExpressionFactory) { .. } internal fun getExpression(className: String): Node { return expressions[className]!!.invoke() } init { for (initializer in ServiceLoader.load(Initializer::class.java)) { initializer.initialize(this) } } }
Теперь, после компиляции, можно для переданной лямбды получить соответствующее выражение (ну или ошибку, если что-то пошло не так)
fun filter(predicate: (T) -> Boolean) { val expression: Node = Expressions.getExpression(predicate.className) println(expression) }
И это работает! Пока в лямбдах не появляются ссылки на константы, поля, методы, конструкторы - и иные объекты языка.
Для проверок я собрал вот такой вот “тестовый стенд”:
const val A = "top level const" val B get() = "top level prop" private val C = "top level const/prop" var D = "top level mutable prop" fun E(): String { return "top level fun"} @EmbedLambdaExpressions class ClosureExample { fun getExpression(): Node { val R = "local val" var S = "local var" fun T(): String = "local fun" return lambdaAsIs({ "test" in listOf(A, B, C, D, E(), F, G, H, I, J(), K(), L, L(), M(), N, O, P(), Q(), R, S, T(), ClosureExample2.U, ClosureExample3.V) }).expression() } companion object L { val F = "companion object val" const val G = "companion object const" val H get() = "companion object prop" var I: String get() = "companion object mutable prop" set(_) {TODO()} fun J(): String = "companion object fun" @JvmStatic fun K(): String = "static fun" operator fun invoke() = "companion object invoke" override fun toString(): String { return "companion object instance" } } private fun M() = "private class function" protected val N = "protected class val" internal val O get() = "internal class prop" inline fun P() = "inline class function" inner class Q { override fun toString(): String = "inner class instance" } fun <L> lambdaAsIs(l: L) = l } class ClosureExample2 { companion object { val U = "another class no-named companion object val" } } object ClosureExample3 { val V = "top-level object val" }
Тут все способы сослаться на какое-то значение, которое я смог придумать. Для каждого случая хочется получить или конкретное значение (константы), или полные имена (методы, конструкторы) для дальнейшей обработки.
Первая версия, само собой, проверку не проходила. Надо было думать как быть.
Runtime. Попытка 2 (KSP + javassist)
Вот у нас есть лямбда:
filter { it > someValue }
Нам нужно в рантайме понять, что такое someValue, и сопоставить с нашей лямбдой и с именем someValue. Т.е. сделать что-то вроде:
Expressions.setArgument("ClosureExample$getExpression$1", "someValue", someValue) filter {it > someValue}
Аналогично с именами методов и конструкторов, только там вставлять не само значение, а ссылку
Expressions.setArgument("ClosureExample$getExpression$1", "someFn", ::someFn)
Но для этого надо как-то поменять исходный код или байт код. Исходный код с помощью KSP менять не получится. А после компиляции поменять байт код можно?
Да. Для этого есть разные инструменты. Я воспользовался решением javassist. И для него, что характерно, тоже есть статья на хабре).
Обработчик я добавил в билд отдельной задачей:
task("kotlinqPostProcess", JavaExec::class) { group = "other" dependsOn("kspKotlin") mainClass.set("io.github.kotlinq.processor.PostProcessor") classpath = project.sourceSets.getAt("main").runtimeClasspath } tasks.build.get().dependsOn(“kotlinqPostProcess”)
Сам PostProcessor проходит по нужным class файлам, снова ищет лямбды (которые на этом этапе уже превратились в классы с методом invoke), и дальше пытается в их теле найти ссылки на методы, переменные, константы и прочее. А потом перезаписывает class файл в то же место.
И вот тут пришлось весьма попотеть, чтобы покрыть все случаи моего тестового стенда. Например, что происходит, если лямбда вызывает приватный метод?
class ClosureExample { fun getExpression(): Node { return lambdaAsIs({ M() }).expression() } private fun M() = "private class function" }
При анализе байт-кода выясняется, что вызывается некий метод access$M.
L0 LINENUMBER 20 L0 ALOAD 0 GETFIELD io/github/kotlinq/expression/ClosureExample$getExpression$2.this$0 : Lio/github/kotlinq/expression/ClosureExample; INVOKESTATIC io/github/kotlinq/expression/ClosureExample.access$M (Lio/github/kotlinq/expression/ClosureExample;)Ljava/lang/String;
А что это за метод?
public final static synthetic access$M(Lio/github/kotlinq/expression/ClosureExample;)Ljava/lang/String; L0 LINENUMBER 14 L0 ALOAD 0 INVOKESPECIAL io/github/kotlinq/expression/ClosureExample.M ()Ljava/lang/String; ARETURN L1 LOCALVARIABLE $this Lio/github/kotlinq/expression/ClosureExample; L0 L1 0 MAXSTACK = 1 MAXLOCALS = 1
А это такой секретный публичный метод, который можно вызвать из другого класса (ведь лямбда после компиляции превратилась в другой класс, и просто так приватные методы изначального класса вызывать не может). Приходится учитывать такой вариант наименования.
А вот это что такое? Access понятно, а что за $p в конце?
L0 LINENUMBER 20 L0 INVOKESTATIC io/github/kotlinq/expression/ClosureExampleKt.access$getC$p ()Ljava/lang/String; L1 ARETURN
А это приватное поле объявленное вне класса, на высшем уровне.
private val C = "top level const/prop"
А вот у нас два локальных значения:
val R = "local val" var S = "local var" return lambdaAsIs { listOf(S, R) }
Это превратится в класс, как мы уже знаем, и в него передадутся указанные значения. Сигнатура у этого класса будет примерно таким:
final class io/github/kotlinq/expression/ClosureExample$getExpression$2 extends kotlin/jvm/internal/Lambda implements kotlin/jvm/functions/Function0 { public final invoke()Ljava/util/List; { ... } // access flags 0x1010 final synthetic Lkotlin/jvm/internal/Ref$ObjectRef; $S // access flags 0x1010 final synthetic Ljava/lang/String; $R }
Что ж, в рантайме можно с помощью reflection извлечь значения для R и S прямо из объекта лямбды. Но если R (который val) мы можем использовать как есть, то для S (который var) надо сначала развернуть ObjectRef. Или IntRef. Или ByteRef. И почему они все не реализуют один интерфейс?
private fun Any?.unwrap(): Any? { return when(this) { null -> null is ObjectRef<*> -> element is ByteRef -> element is IntRef -> element is DoubleRef -> element is FloatRef -> element is BooleanRef -> element is CharRef -> element is ShortRef -> element is LongRef -> element else -> this } }
В общем, пост процессинг получился очень сложным и хрупким. Находим метод или поле, и давай отрубать “$” с разных сторон и пытаться угадать - это то, что нам нужно, или что-то левое?
Конечно, было бы куда проще, если бы мы работали с исходным кодом на котлине. В теории можно было бы взять наш AST, сгенерировать код на kotlin, который вызывает всё то же, что вызывается внутри лямбды, и вставить это всё в код. Но тут есть нюанс: javassist может компилировать java код, но не может компилировать kotlin. А то, что в котлине выглядит как просто return X, на java может быть и return getX() или вот даже return access$getX$p()
Я задумался о том, что в каком-нибудь C/C++ проблема модификации исходного кода легко решалась макросами. А вот в Java/Kotlin ничего такого нет.
Конечно, написать простой препроцессор из разряда “взять файл, погрепать и положить обратно” несложно. Но надо же ещё как-то встроить его в процесс билда, чтобы изменённый файл (и только он) был виден только компилятору, а система контроля версий видела бы только исходный файл. Есть ли такой инструмент?
Да, есть. Это плагин к компилятору kotlin.
Runtime. Попытка 3 (плагин к компилятору котлина)
Про это есть тоже статья на хабре, хотя я обходился этой статьёй, а так же исследованием официальных примеров (например All Open plugin)
В пакете org.jetbrains.kotlin.extensions (из подключаемой библиотеки org.jetbrains.kotlin:kotlin-compiler-embeddable:1.6.21 ) можно найти несколько интерфейсов. Эти интерфейсы и есть поддерживаемое api для плагинов к компилятору. Я опасался, что тут будут только “высокоуровневые” точки подключения, однако опасения мои оказались напрасными. Есть прекрасный PreprocessedVirtualFileFactoryExtension , который позволяет подменить тело файла при чтении его с диска.
/** * The interface for the extensions that are used to substitute VirtualFile on the creation of KtFile, allows to preprocess a file before * lexing and parsing */ interface PreprocessedVirtualFileFactoryExtension { companion object : ProjectExtensionDescriptor<PreprocessedVirtualFileFactoryExtension>( "org.jetbrains.kotlin.preprocessedVirtualFileFactoryExtension", PreprocessedVirtualFileFactoryExtension::class.java ) fun isPassThrough(): Boolean fun createPreprocessedFile(file: VirtualFile?): VirtualFile? fun createPreprocessedLightFile(file: LightVirtualFile?): LightVirtualFile? }
Его я и реализовал. При чтении kotlin файла с диска проверялось, что его надо обрабатывать (для этого в конфигурации плагина можно было указать packages), после чего доставал AST, искал внутри лямбды, в лямбдах ссылки наружу - всё как и раньше. И затем подменял исходный файл, заворачивая лямбды в специальный класс с AST внутри.
Например:
@Kotlinq fun main() { val lambda: (Int) -> Int ={ it * 3 } println(lambda.expression) }
превращается в:
@Kotlinq fun main() { val lambda: (Int) -> Int = (withExpression1({ it * 3 }, { Multiply(LambdaArgument(0),Value(3)) })) println(lambda.expression) }
При таком подходе значительно упростилась та часть, которая разруливала ссылки на константы, методы и прочее. В общем-то достаточно было добавить те же вызовы в генерируемый код, если у нас вызов “без скобочек” (val, var, const), и ссылку если вызов “со скобочками” (функции и конструкторы). Но и тут не обошлось без казусов.
Например, вот такая лямбда:
@Kotlinq fun main() { val lambda: (Int) -> Boolean = { it in listOf(2, 3) } }
Превращается в:
@Kotlinq fun main() { val lambda: (Int) -> Boolean = (withExpression1({ it in listOf(2, 3) }, { Call(Identifier("in"),LambdaArgument(0),Call(Ref(::listOf),Value(2),Value(3))) })) }
Ссылка на метод listOf добавилась. Но компиляция падает, потому что:
Callable reference resolution ambiguity: public inline fun <T> listOf(): List<T> defined in kotlin.collections public fun <T> listOf(element: T): List<T> defined in kotlin.collections public fun <T> listOf(vararg elements: T): List<T> defined in kotlin.collections
Я не нашёл способа разрулить такие проблемы, кроме как в конфигурацию плагина добавить список исключений, для которых не надо пытаться вставить ссылку.
Другая проблема - как отличить вызов метода от вызова конструктора? Кажется, разницы нет, но она всё же есть:
@Kotlinq fun main() { val lambda: (Int) -> Pair<Int, Int> = { Pair(it, it*2) } }
превращается в:
val lambda: (Int) -> Pair<Int, Int> = (withExpression1({ Pair(it, it*2) }, { Call(Ref(::Pair),LambdaArgument(0),Multiply(LambdaArgument(0),Value(2))) }))
и валится с ошибкой компиляции:
Not enough information to infer type variable A
Потому что класс Pair - generic класс, и конструктору нужны параметры типов. Но в ссылке на компилятор их никак не передать. Было бы здорово передать ссылку на класс, а не на конструктор, как Pair::class. Но для этого наш плагин должен знать, что Pair(1,2) это конструктор, а listOf(1,2) - это метод.
В итоге решения два:
По-умолчанию плагин считает, что если название с маленькой буквы - это метод, а если с большой - это класс
Исключения можно явно настроить в конфигурации плагина
Дёшево и сердито.
Конечно, было бы совсем круто, если бы мы могли воспользовать результатами анализа кода самого компилятора kotlin. Наверняка ещё на ранних стадиях обработки он уже знает, какой символ обозначает класс, а какой - метод, и точно знает какую именно сигнатуру.
Но на этом этапе я уже очень устал заниматься этим плагином. Может быть, в следующий раз, когда снова захочется странного... Но не сейчас.
Этот вариант я “пустил в дело”, то есть стал на его основе делать свой linq с jooq-ом и лямбдами.
Реализация для JOOQ
Собственно, ради чего всё и затевалось. Чтобы иметь возможность писать код на kotlin и превращать его в sql.
Для начала я завёл интерфейс Queryable аналогичный своему коллеге из C#.
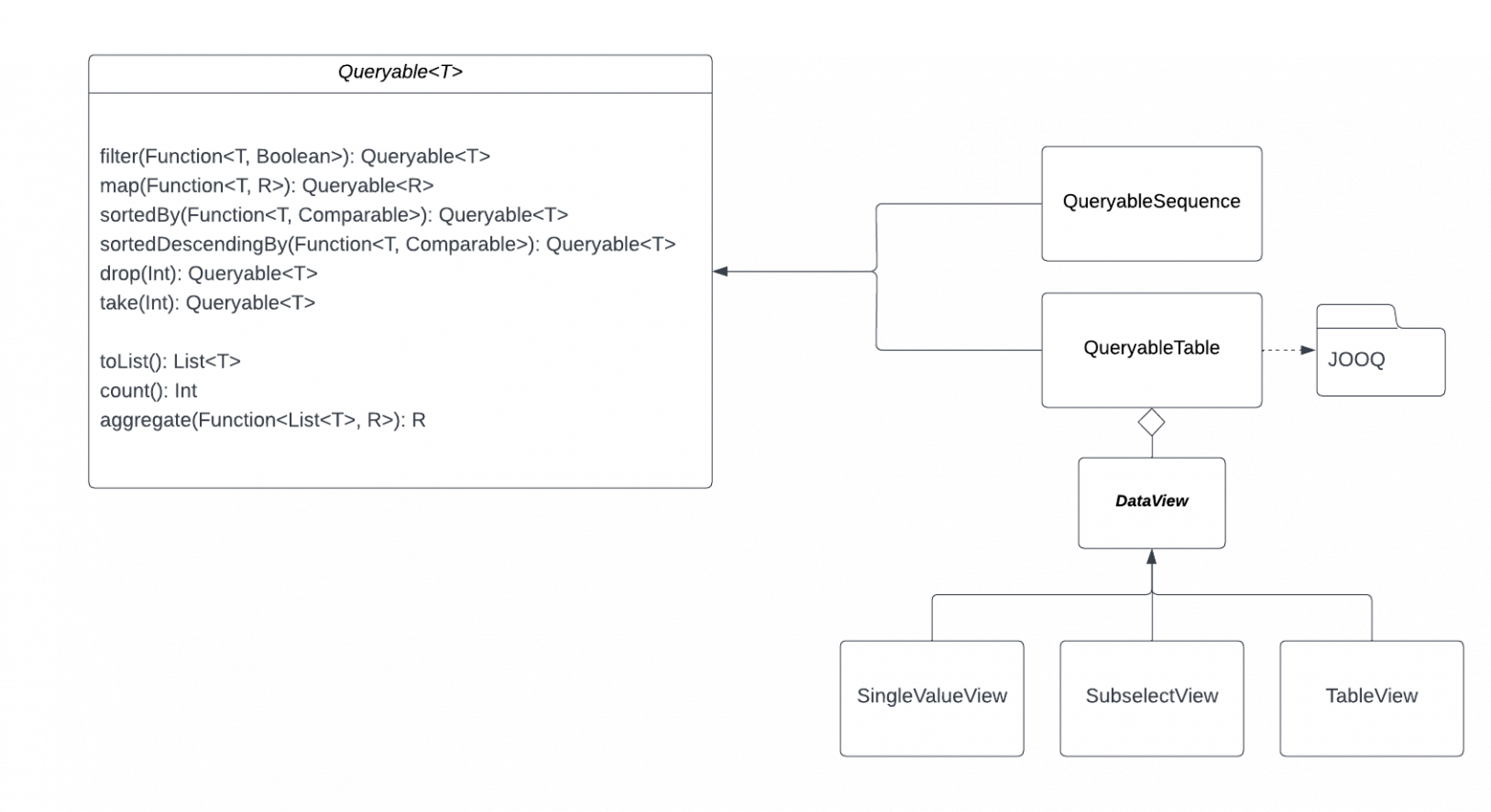
И сделал реализацию/адаптер для обычного sequence. В этом адаптере я просто вызываю передаваемые лямбды и никак не работаю с их AST. Теперь нужно было сделать то же самое для sql выражения.
В JOOQ всё довольно неплохо продумано. Любое SELECT выражение можно “превратить” в таблицу и работать с ним как с таблицей (в SQL это будет вложенный запрос). Что позволяет для разных уровней вложенности использовать один и тот же код, с небольшими отличиями под специфичные ситуации. Ситуаций таких я выделил три - вон там выше три класса DataView. Отличаются они тем, как трактовать AST лямбд, особенно что такое it.
таблица в базе (it == сгенерированный Record);
запрос с несколькими полями (it == произвольный пользовательский класс);
запрос с одним полем (it == скалярное значение).
Вот эти три ситуации:
dsl.selectQueryableFrom(Tables.USERS) // тут it - это UserRecord, сгенерированный jooq-ом из схемы в базе // название проперти соотносится с именем колонки в таблице .filter { it.age > 15 } .map { Pair(it.name, it.age) } // тут it - это уже экземпляр класса Pair, никак не связанный с jooq-овскими структурами // надо где-то “записать”, что second - это исходное поле age .filter { it.second > 15 } .map { it.second } // а тут it - это уже одна колонка в запросе .filter { it > 15}
Немного пробегусь по методам Queryable:
filterТут AST дерево разбирается без особых прикрас. Разве что нужно не забывать про особую обработку null-ов.
fun condition(node: Node): Condition { val secondChildIsNull = (node is TwoChildren && node.right == Value(null)) return when { node is And -> condition(node.left).and(condition(node.right)) node is Or -> condition(node.left).or(condition(node.right)) node is Equal && secondChildIsNull -> field<Any>(node.left).isNull node is Equal -> field<Any>(node.left).eq(field<Any>(node.right) as Field<*>) node is NotEqual && secondChildIsNull -> field<Any>(node.left).notEqual(field<Any>(node.right) as Field<*>) node is Less -> field<Any>(node.left).lessThan(field<Any>(node.right) as Field<*>) node is LessOrEqual -> field<Any>(node.left).lessOrEqual(field<Any>(node.right) as Field<*>) node is Greater -> field<Any>(node.left).greaterThan(field<Any>(node.right) as Field<*>) node is GreaterOrEqual -> field<Any>(node.left).greaterOrEqual(field<Any>(node.right) as Field<*>) node is UnaryBang -> condition(node.child).not() node is GetProperty || node is Value || node is Val || node is Call || node is LambdaArgument -> field<Any>(node).isTrue else -> error("Cannot get conditions from $node") } }Результат разбора (jooq condition) сохраняется во внутреннем поле. SQL выражение составляется и выполняется только при вызове терминальных операций, вроде
toList,countиaggregate.take/dropТоже сохраняем переданные значения для использования позже
sortedByТут надо превратить AST в выражение, по которому можно сортировать. Логика тут тоже не особо замысловатая:
fun <T> field(node: Node): Field<T> { return when(node) { is Unknown -> error("Impossible to use unknown node: ${node}") is UnaryMinus -> DSL.minus(field<Number>(node)) is UnaryPlus -> field(node) is UnaryBang -> DSL.not(field<Boolean>(node)) is Plus -> field<T>(node.left).plus(field<T>(node.right)) is Minus -> field<T>(node.left).minus(field<T>(node.right)) is Multiply -> field<Number>(node.left).mul(field<Number>(node.right)) is Divide -> field<Number>(node.left).div(field<Number>(node.right)) is And, is Or -> error("Cannot use logical operations as fields") is Equal, is NotEqual, is Less, is Greater, is GreaterOrEqual, is LessOrEqual, -> error("Cannot use comparison operations as fields") is GetProperty -> when { node.left is LambdaArgument -> nodeToJooq.field(node.right, node.left as LambdaArgument) else -> error("Cannot parse $node") } is Concat -> DSL.concat(*node.children.map { field<String>(it) }.toTypedArray()) is Identifier -> dataView?.getField(node.name) ?: error("Unknown identifier ${node.name}") is Value -> DSL.value(node.value) is LambdaArgument -> dataView?.getField() ?: nodeToJooq.field(node, node) is Call -> call(node) is Val -> DSL.value(node.value) is Ref -> error("Cannot use references") is Error -> error(node.errorMessage) } as Field<T> }sortedDescendingByАналогично, только надо добавить desc.
mapНаиболее сложная операция. В теории внутри передаваемой функции может быть любое выражение, и если сразу после map идёт toList - надо возвращать именно то, что было попрошено. Т.е.
queryable.map(fn).toList()должно возвращать то же самое, что вернуло быqueryable.toList().map(fn).В общем случае я не знаю как это решить. Решил для двух частных случаев:
fn возвращает скалярное значение;
fn возвращает экземпляр data class, у которого только один конструктор - основной.
В первом случае выполняем тот же парсинг AST, что и для
sortedBy. Получаем в итоге sql выражение представляющее один столбец / значение. Дальше его выполнить, взять единственный столбец и привести тип к ожидаемому типу данных.Во втором случае с помощью reflection можно получить список полей класса и их порядок, для каждого аргумента конструктора выполнить преобразование как для случая с одиночным значением. При выполнении SQL мы получим от JOOQ экземпляр
Recordс тем же числом полей. Дальше мы можем сконструировать экземплярыdata classпередав значения изRecordв конструктор в порядке их определения.queryable // запоминаем запрошенные поля таблицы - name и age // запоминаем порядок аргументов и тип класса .map { Pair(it.name, it.age) } // знаем, что second - второй аргумент // были выбраны два поля - name и age // значит second == age // его и подставляем в итоговое sql выражение .filter { it.second > 18 } // тут мы выполняем SQL и получаем от JOOQ набор экземпляров // org.jooq.Record с двумя полями // для каждого Record создаём экземпляр Pair и передаём // значения полей в качестве аргументов конструктора .toList()toList/countНа этом этапе составляется и исполняется sql запрос. Разница только в том, что остаётся в выражении
select- перечисление полей, илиcount(*)aggregateНе хотелось ограничивать себя или других перечнем конкретных операций. Поэтому был заведён реестр
иностранных агентовфункций и способов их преобразования в агрегирующие выражения.registerAggregator(Iterable<Int>::maxOrNull) { field -> DSL.max(field) } registerAggregator(Iterable<Int>::minOrNull) { field -> DSL.min(field) } registerAggregator(Iterable<Int>::sum) { field -> DSL.sum(field as Field<out Number>?) } registerAggregator(Iterable<Int>::average) { field -> DSL.avg(field as Field<out Number>?) }Это позволяет использовать привычные функции для агрегирования значений и регистрировать свои в случае необходимости
println(queryable.aggregate { it.sum() })
Где всё это искать
Вот репозиторий с самой библиотекой и плагином к kotlin, инструкция по установке в readme.
Вот репозиторий с реализацией для jooq.
И вот репозиторий с полноценным примером.
Можно склонировать, собрать и запустить. Один и тот же “запрос” прогоняется для коллекции в памяти и для БД.
Вот такое выражение:
val report = storage.species() .join( storage.animals(), { s, a -> s.id == a.speciesId }, { s, a -> AnimalDescription(s.name, a.name, a.population / Thousand) } ) .sortedDescendingBy { it.popularityK } .filter { it.popularityK > 0 } .map { "${it.speciesName.uppercase()}: ${it.animalName} [${it.popularityK}K]" } .toList() .joinToString("\n")
И вот такой получается SQL:
select (((((upper("alias_28974773"."speciesName") || ': ') || "alias_28974773"."animalName") || ' [') || cast("alias_28974773"."popularityK" as varchar)) || 'K]') "col0" from (select "left"."NAME" "speciesName", "right"."NAME" "animalName", ("right"."POPULATION" / 1000) "popularityK" from "PUBLIC"."SPECIES" "left" join "PUBLIC"."ANIMALS" "right" on "left"."ID" = "right"."SPECIES_ID" ) "alias_28974773" where "alias_28974773"."popularityK" > 0 order by "alias_28974773"."popularityK" desc
Что дальше
Не знаю. Своё любопытство я удовлетворил. Покажу коллегам, если им понравится - может быть попробуем использовать в наших продуктах. Если нет - значит пополнит список моих никому не нужных творений.
Бесполезное творчество в любом случае лучше, чем полезное разрушение.
Всем мир.

