Привет, Хабр! Сегодня с вами команда AliExpress Order Management System, и мы поговорим про очередное решение по шардированию PostgreSQL, на этот раз in-app, то есть живущее непосредственно в приложении, которому нужна функциональность шардинга.
Немного контекста
Мы являемся связующим звеном между логистикой, чекаутом, стоками, товарами, продавцами и множеством разных доменов — системой управления заказами. Создаем, храним, раздаем, двигаем по конечному автомату все заказы AliExpress.
Наши данные хранятся в реляционном виде, и их много — несколько миллиардов строк. Мы используем PostgreSQL и размещаем наши базы данных локально, поэтому наше небо безоблачно, а наша команда инфраструктуры занята настолько, насколько это возможно, и возможно, даже немного больше.
Нам нужно хранить около 8 Тб данных в нашей базе данных, и мы планируем увеличить этот объем в два раза за год. Наша рабочая нагрузка на базу состоит из 15% вставок / обновлений и 85% операций чтения. Также имеется одно немаловажное ограничение: для быстрого резервного копирования и восстановления один физический сервер базы данных может содержать не более 500 Гб данных.
Здесь имеет смысл рассказать пару слов о бизнес-задаче, в рамках которой нам понадобились такие объемы данных.
Система содержит в себе информацию по заказам с позициями, информацией о доставке, спорах, комментариях и т.п. Данные хранятся за все время по всем заказам, которые были отправлены в ряд стран (включая Россию). Это мастер-система состояния заказа, которой пользуются как пользователи (покупатели и продавцы) в приложении и на сайте, так и другие домены внутри нашей компании.
До того как мы затеяли создание нашего собственного хранилища, у нас было существующее решение на базе довольно сильно переделанной СУБД MySQL, но у этого решения был ряд недостатков.
Первый — существующее решение было вне нашего контроля, как по масштабированию, так и по обслуживанию, не говоря уж об исходниках — их у нас тоже не было.
Второй — чтение из существующей системы производилось через цепочку API, также неподконтрольных нам. То же можно сказать и о структуре данных — она была неизменна и так же вне нашей юрисдикции.
Все эти недостатки выливались в то, что существующей системой пользоваться было медленно и сложно, а фичи в ней могли реализовываться только не нами и очень долго. Именно поэтому мы и решили построить наше собственное хранилище данных и инфраструктуру доступа, откуда мы могли бы получать всю информ��цию напрямую, минуя неподконтрольные нам прокси-системы.
Итак, необходимо разработать решение для хранения данных, которое было бы хорошо масштабируемым с точки зрения хранения данных, доступности и пропускной способности.
Что ж, есть способ добиться этого — разделение всего набора данных между несколькими физическими серверами или, одним словом, шардинг. Давайте сначала обсудим, какие у нас есть варианты разделения данных в современных СУБД.
Шардированный мир
Шардинг — это процесс разделения одного большого, структурированного, непрерывного набора некоторых объектов (я не называю их строками, поскольку мы можем шардировать любой набор данных, вне зависимости от метода их хранения) на более мелкие части с одинаковой структурой и размещения этих частичных наборов на разных физических серверах.
Идея проста. Во-первых, мы выбираем одно или несколько свойств атомарного объекта в наборе и называем его ключом шардирования shard key, от него зависит физический “адрес” данных.
Когда нам нужно сохранить какие-то данные, мы некоторым образом преобразуем значение ключа шардирования, чтобы определить их физическое местоположение, т.е. задать, на каком сервере должны быть размещены данные.
Чтобы прочитать сохраненные данные с сервера, на который они были перенаправлены, нам нужно снова указать ключ шардирования, чтобы преобразовать его и получить соответствующее физическое местоположение для чтения требуемых данных.
Таким образом, имея набор ключей и правила преобразования, мы можем осуществить распределение данных между серверами.
Распределение
Когда у нас есть несколько доступных серверов с одинаковыми характеристиками, мы не хотим, чтобы данные отправлялись только на один из них — это лишило бы шардинг всякого смысла. Чтобы достичь оптимального использования ресурсов и максимальной пропускной способности в шардированной базе данных, нам нужно, чтобы данные были равномерно распределены между серверами. Есть некоторые случаи, когда мы намеренно не хотим равномерного распределения — например, когда серверы, на которые мы помещаем данные, не равны с точки зрения вычислительной мощности или пространственного распределения, но это довольно экзотический случай, и мы не будем его рассматривать.
Итак, нам нужно равномерное распределение. Как мы его получим? Хитрость заключается в преобразовании ключа шардирования.
Нам нужно преобразование, которое сопоставляет входные значения ключей с выходными значениями адресов данных как можно более равномерно по всему диапазону возможных адресов. К счастью, у нас есть набор математических функций с точно такими свойствами — хэш-функции.
Алгоритм прост. Мы получаем ключ шардирования, передаем его в хэш-функцию и получаем некоторое конечное значение, скажем, 64-битное целое число без знака. Для одних и тех же входных значений выходное значение всегда будет одинаковым, в то время как для разных значений мы можем получать разные или одинаковые значения хэша.
Давайте воплотим эту теорию в жизнь.
Три пути
Допустим, нам нужно разделить один набор данных на 16 частей и поместить каждую часть на отдельный сервер в класт��ре из 16 серверов. Мы получаем значение ключа шардирования каждого объекта в наборе, затем вычисляем его хэш и делим его по модулю на количество доступных нам серверов, таким образом получая смещение в массиве адресов серверов. Далее мы получаем сервер с адресом по смещению, направляем данные на этот сервер и сохраняем их там.
Есть три способа сделать это:
Ручной — мы просто выполняем все вычисления и маршрутизацию самостоятельно. Нам также нужно настроить кластер, добавить хранилище конфигурации, где мы описываем все разделенные наборы данных и ключи шардирования. Затем нужно переписать все процедуры сохранения данных и запросы, чтобы включить информацию о маршруте, и надеяться, что все пройдет хорошо.
Автоматический — есть базы данных, в которых есть одна (ну, почти одна) кнопка “сделать хорошо!”. Хранением конфигурации и изменением запросов будет заниматься сама СУБД.
Гибридный — когда сам сервер базы данных не способен “сделать хорошо” из коробки, мы используем какое-нибудь стороннее решение, которое займется шардированием данных за нас.
Есть несколько СУБД, в которые встроено автоматическое шардирование, но большинство из них — это NoSQL-решения: Elastic, Cassandra, MongoDB. Увы, Postgres не входит в их число.
Что касается гибридных решений для Postgres — большинство из них основаны на технологии PG FDW. FDW (foreign data wrapper) — это функциональность сервера Postgres, которая позволяет ему рассматривать данные на удаленном сервере как часть большего набора и интерпретировать этот разделенный на несколько серверов набор данных как единое целое. У этой технологии есть свои проблемы, но самая большая из них — доступ к данным через FDW чрезвычайно медленный.
Единственный путь
Что ж, выходит, что у нас нет другого выбора, кроме как самостоятельно реализовать механизм шардирования. Вот тут-то и начинается самое интересное.
Первое и самое главное, что нужно выбрать, — это наша хэш-функция. Общие критерии для хэш-функций выглядят так:
Скорость — вычисление значения должно быть быстрым для любых входных данных.
Равномерное распределение — выходные значения функции должны быть распределены максимально равномерно по всему диапазону возможных значений.
Частота коллизий — количество коллизий должно быть как можно меньше.
Лавинный эффект — если входные данные изменяются незначительно (например, меняется один бит), выходные данные должны измениться значительно (например, меняется половина выходных битов).
Последние два критерия принципиально важны для криптографических хэш-функций, но при выборе хэш-функции для целей шардирования нас на самом деле интересуют только первые два критерия.
В сети существует множество сравнений некриптографических хэш-функций. Наиболее каноническим набором тестов является smhasher. Мы рассмотрели следующие хэш-алгоритмы:
DJB2
SDBM
LoseLose
FNV-1 / FNV-1a
CRC16
Murmur2/Murmur3
Среди перечисленных функций Murmur3 является самой быстрой и имеет наилучшую равномерность распределения. Существует новый алгоритм хэширования под названием xxHash, который, как говорят, быстрее, чем Murmur3, без снижения равномерности распределения, но его реализация на C# была недоступна на момент разработки данного решения.
Алгоритм разрешения шардов
Теперь давайте решим, как нам вычислить физический шард, на который направляются данные. Начнем с самого простого решения, а затем, если окажется, что оно не удовлетворяет ни одному из наших требований, посмотрим, как его можно улучшить.
Самое простое решение настолько же просто, как и классическая хэш-таблица. Мы берем постоянное количество физических серверов — назовем их бакетами (buckets), — затем вычисляем числовое хэш-значение для нашего шард-ключа и делим это значение по модулю на количество бакетов, получая таким образом индекс элемента в массиве серверов.
offset = CalculateHash(shard_key) % BucketNumber
server = Servers[offset]Хорошо, но что если после конфигурирования кластера нам нужно добавить или удалить сервер? Операции записи просто получат новый индекс и будут перенаправлены на новый сервер. Но индекс для всех запросов на чтение теперь будет неправильный, и мы можем попасть в шард, где искомые данные будут отсутствовать.
Таким образом, после того как физический шард будет добавлен или удален, нам нужно как-то перераспределить данные между новым количеством серверов — выполнить повторное шардирование (resharding).
Решардинг в случае простой хэш-таблицы — это медленно и больно.
Для каждой строки в каждой шардированной таблице придется пересчитать новый индекс в массиве серверов и переместить строку на результирующий сервер.
Вероятность того, что новое значение индекса будет таким же, как и старое, неприемлемо мала.
Результатом выполнения этих шагов станет перемещение почти всех строк таблицы.
Для 8 Тб данных на такое перемещение потребуется очень много времени простоя и очень страшные ручные data-фиксы, если что-то пойдет не так. Можем ли мы придумать что-нибудь получше?
Что если у нас изначально будет число серверов, кратное степени 2, а при масштабировании мы будем не добавлять один сервер, а удваивать количество серверов? Давайте посмотрим, как изменится процесс решардинга.
Для каждой строки в каждой шардированной таблице мы пересчитываем новый индекс в массиве серверов и перемещаем строку на результирующий сервер.
Изначально у нас было количество серверов, равное 2n, новое число равно 2n+1.
Вероятность того, что новое смещение будет таким же, как и старое, равна 1/2.
В результате мы переместим только половину строк.
Это лучше, но хорошо работает только для степеней двойки. Можем ли мы еще улучшить наше решение?
Ответ — да, но для этого нам понадобится отойти от стандартной хэш таблицы. Алгоритм, которым мы можем воспользоваться, называется согласованное хеширование (consistent hashing).
Давайте присвоим каждому серверу его собственное значение хэша шард-ключа и расположим наши серверы на кольце.
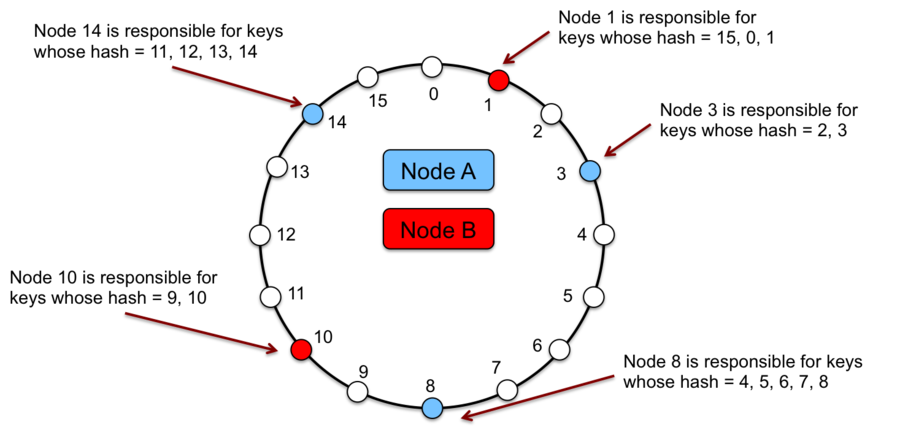
На каждый сервер будут попадать данные с хэшем между значением для данного узла и предыдущего. Таким образом, при добавлении узла в кластер нам нужно будет перемещать данные только для серверов, которые находятся непосредственно перед ним и после него, перемеcтив в худшем случае всего лишь 1 / BucketNumber строк.
Уже гораздо лучше! Но как насчет распределения и балансировки данных? Для случая, когда сервер оказывается на кольце только один раз, возможны условия, при которых большая часть данных в конечном итоге попадает на один сервер, перегружая его.
Эту проблему легко решить, ассоциировав с одним сервером более одного случайного значения хэша, из-за чего он появляется на кольце более одного раза в случайных позициях.
Описанный алгоритм на самом деле очень популярен и используется во многих базах данных, которые имеют возможности шардинга из коробки: DynamoDB, MongoDB, CockroachDB, Cassandra.
Consistent hashing, будучи простым по своей природе, довольно сложен в настройке и обслуживании, поэтому давайте придумаем гибридный подход между ним и предыдущим со степенями 2.
Предположим, что у нас есть постоянное количество бакетов, скажем, 65536, и несколько серверов, каждый из которых будет отвечать за свой собственный диапазон бакетов. Теперь, если мы решим добавить сервер в кластер, можно просто назначить новому серверу некоторый диапазон бакетов и переместить только те строки, шард-ключи которых разрешаются в эти бакеты.
Конфигурация кластера
Теперь определимся с тем, как нам настроить кластер. Чтобы повысить надежность, выделим узел кластера для хранения всей конфигурации — мы называем его master node.
У нас будут шардированные и нешардированные данные. Очевидно, что только шардир��ванные данные должны быть распределены между узлами кластера, все нешардированные (назовем их solid) данные могут быть помещены в собственный выделенный узел (или узлы), который мы называем solid shard.
Таким образом, у нас есть три типа узлов кластера — master node, data shards, solid shards. Master node может быть только один, но допускается любое количество data- и solid-шардов.
Большинство СУБД, которые предоставляют механизмы шардинга "из коробки", позволяют выбирать, какое поле или группа полей в конкретной шардированной таблице будут образовывать ключ шардирования.
Настройка шардирования для каждой таблицы имеет свои преимущества. Это позволяет анализировать, содержит ли фактический SQL-запрос указанные поля шард-ключа, и переписывать запрос на лету, чтобы разделить его между серверами. Это также значительно облегчает понимание того, какие данные шардируются и как. Также это позволяет группировать запросы к одному шарду для оптимизации выборки данных с нескольких шардов.
Обладая всеми этими преимуществами, шардирование каждой таблицы увеличивает накладные расходы на конфигурацию и требует перенастройки для каждой новой таблицы. Более того, если мы не анализируем каждый SQL-запрос, а эта операция является медленной, и сложной, нам нужно указывать имя поля ключа шардирования каждый раз, когда мы хотим выполнить операцию с шардированными данными.
Разберемся, что получится, если просто отбросить информацию о том, какое поле является ключом шардирования.
Без информации о поле шард-ключа в конфигурации необходимо вручную указывать значение эт��го поля для каждой операции над шардом, но для вычисления того, к какому шарду принадлежат наши данные, все запросы и так должны содержать шард-ключ. Без указания связки шард-ключ → data shard у нас появляется возможность добавлять любое количество шардированных таблиц, вообще не меняя конфигурацию. Общий процесс разрешения шардов упрощается, к тому же не нужно переписывать запрос, поскольку у нас сразу есть значение ключа шардирования.
Но есть небольшая проблема. Теперь у нас нет способа проверить, действительно ли запрос, который отправляется в шард, работает с какими-либо шардированными данными на этом шарде. Таким образом, если указано неверное значение шард-ключа, по ошибке можно извлечь или изменить данные, которые мы не собирались трогать. Разрабочик приложения, клиента должен быть особенно осторожен в отношении того, какие запросы он делает, к каким шардам и с какими ключами. В случае нашего in-app шардирования мы считаем это приемлемой ценой простоты.
А что насчет доступа к нешардированным данным? Поскольку мы храним их в выделенном узле, можно просто дать этому узлу имя, и когда необходимо подключение к solid-шарду, просто его указать.
Определившись с алгоритмом шардирования и процессами настройки кластера, можно переходить к структуре таблиц на master node.
Master node
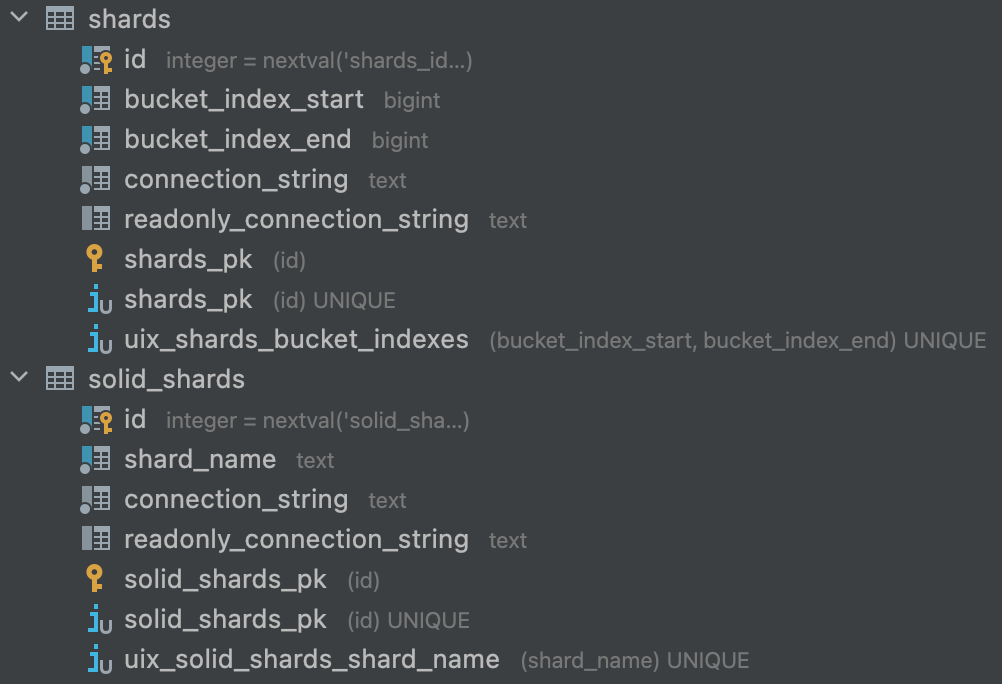
В итоге у нас осталось только две конфигурационных таблицы — одна для хранения настроек data-шардов и одна для solid-шардов. Data-shard ассоциирован с диапазоном бакетов, за которые он отвечает, и строкой соединений физического узла. Solid-shard имеет имя и строку подключения.
Show me the code!
Со стороны API библиотеки для in-app шардирования нам необходимо иметь возможность получить экземпляр соединения для шарда, в который разрешается наш шард-ключ. В случае data-шарда все, что нужно сделать — это указать значение шард ключа.
Сигнатура метода получения соединения выглядит следующим образом:
protected virtual Task<TDbConnection> GetShardConnectionAsync<TShardKeyValue>(
TShardKeyValue shardKeyValue,
CancellationToken token)Очень похожий API имеет метод получения соединения для solid shard.
protected virtual Task<TDbConnection> GetSolidShardConnectionAsync(
string solidShardName,
CancellationToken token)Вместо передачи значения шард-ключа мы просто указываем строковое имя solid-shard.
Что происходит, когда мы вызываем метод разрешения шарда? Сначала мы вычисляем значение хэш-функции для переданного значения шард-ключа и вычисляем индекс бакета, разделив его по модулю на наше фиксированное количество виртуальных бакетов, равное 65536. Получение значения хэша и бакета абстрагировано, чтобы дать возможность использовать другие хэш-алгоритмы или по-другому вычислять бакет.
public interface IShardKeyHasher
{
Task<ShardKeyHashBucket> ComputeShardKeyHashAndBucketAsync(string shardKeyValue, CancellationToken token);
}После того как бакет был вычислен, мы находим диапазон бакетов, в который он попадает. Мы можем возложить эту задачу на SQL-сервер, который содержит конфигурацию.
SELECT
connection_string,
readonly_connection_string
FROM
shards AS s
WHERE
s.bucket_index_start <= @Offset
AND @Offset <= s.bucket_index_endПоскольку таблица конфигурации data-шардов не очень велика и в большинстве случаев целиком помещается в кэш, запрос будет выполняться очень быстро.
Затем останется просто создать экземпляр соединения с соответствующей строкой подключения, открыть его и вернуть.
В принципе, это все, но мы можем добавить пару оптимизаций.
Кэширование конфигурации
Во-первых, поскольку конфигурация нашего кластера меняется очень редко, мы можем кэшировать все таблицы с master node. Это позволяет нам избавиться запроса к базе данных во время разрешения шарда.
var shardDescriptor = cachedDescriptors.Single(
d =>
d.BucketIndexStart <= bucketIndex
&& bucketIndex <= d.BucketIndexEnd);Когда размер кэша невелик, этот код выполняется довольно быстро, но мы можем еще немного ускорить эту операцию.
Для поиска диапазона по значению, попадающему в него, можно воспользоваться вариантом двоичного дерева поиска — интервальным деревом (range tree). Эта структура данных имеет логарифмическую характеристику затрат времени на поиск.
var shardDescriptor = cachedDescriptors.Query(bucketIndex)После применения этой оптимизации количество обращений к master node сокращается до одного на все время жизни кэша, которое может быть очень велико.
Кэширование соединений
Вторая оптимизация, которую можно применить — это уменьшение количества физических подключений, созданных для конкретного запроса. Рассмотрим цепочку запросов к одному шарду (single-shard queries).
var data1 = _repository1.Query(shardKeyValue);
var data2 = _repository2.Query(shardKeyValue);
return (data1, data2);В результате выполнения мы создадим и откроем два отдельных подключения к одному и тому же шарду. Если мы не хотим выполнять операции запроса параллельно, это кажется излишним, и экземпляры соединения к одному и тому же шарду (мы различаем их по connection string) можно закэшировать. Это позволит нам использовать кэшированные экземпляры соединений в single-shard вызовах к одному и тому же шарду.
Отметим, что в случае параллельных запросов к одному и тому же шарду этот кэш принесет больше вреда, чем пользы, так как мы можем попытаться выполнить запрос на соединении, которое уже используется и выполняет другой запрос. Для случаев параллельных запросов к одному шарду предусмотрена возможность получать некэшированные экземпляры соединений.
Что в черном ящике?
Разрешение шарда и получение соединения для пользователя является непрозрачной снаружи операцией, однако в процессе ее выполнения участвует много механизмов. Мы хотели бы знать, какие шарды были разрешены из каких ключей, когда произошло кэширование конфигурации и т.п. Для того чтобы получать эту информацию, мы инструментируем некоторые вызовы в нашей библиотеке. Будем использовать стандартный DiagnosticListener для предоставления возможности получать исчерпывающую диагностическую информацию, когда это необходимо:
public class ShardingDiagnosticSource : DiagnosticListener
{
public const string SourceName = "Diagnostics.Sharding";
public const string DataShardResolutionSuccessDiagnosticName = "DataShardResoultion_Success";
internal static ShardingDiagnosticSource Instance { get; } = new();
internal ShardingDiagnosticSource() : base(SourceName)
{ }
}Добавим класс-listener для диагностических сообщений.
public class LoggingShardResolutionDiagnosticListener
{
[DiagnosticName(ShardingDiagnosticSource.DataShardResolutionSuccessDiagnosticName)]
public void LogDataShardResolutionSuccess(
string resolvedShardDescription,
bool isResolvedFromCache)
{
if (!_settings.IsLoggingEnabled)
{
return;
}
if (isResolvedFromCache)
{
_logger.Log(
_settings.DiagnosticMessagesLoggerEventLevel,
"Resolved {ResolvedShardDescription} from cache",
resolvedShardDescription);
}
else
{
_logger.Log(
_settings.DiagnosticMessagesLoggerEventLevel,
"Resolved {ResolvedShardDescription}",
resolvedShardDescription);
}
}
}Обернем внутренние вызовы.
if (ShardingDiagnosticSource.Instance.IsEnabled(ShardingDiagnosticSource.DataShardResolutionSuccessDiagnosticName))
{
ShardingDiagnosticSource.Instance.Write(
ShardingDiagnosticSource.DataShardResolutionSuccessDiagnosticName, new{
resolvedShardDescription = ret.DescribeSelf(),
isResolvedFromCache = true
});
}И соединим все вместе.
services
.AddSingleton<LoggingNpgsqlShardResolutionDiagnosticListener>()
.AddSingleton(NpgsqlShardingDiagnosticSource.Instance);
...
DiagnosticListener diagnosticListener = app.ApplicationServices.GetRequiredService<NpgsqlShardingDiagnosticSource>();
var listener = app.ApplicationServices.GetRequiredService<LoggingNpgsqlShardResolutionDiagnosticListener>();
diagnosticListener.SubscribeWithAdapter(listener);Ограничения
Каждое решение имеет свои ограничения, и наше — не исключение.
Мы не поддерживаем автоматический решардинг (пока).
Мы не поддерживаем multi-shard операции
JOIN.Мы не поддерживаем распределенные транзакции.
Поддержка распределенных транзакций является наиболее сложной из проблем, с которыми приходится сталкиваться при создании решения для шардинга. Она в том или ином виде имеется лишь в некоторых СУБД и надстройках: MongoDB, CockroachDB, CitusDB, etc.
Стоит отметить, что многие СУБД и надстройки с поддержкой шардирования используют логику, во многом схожую с тем, что получилось у нас и было описано выше.
В заключение приведу немного цифр, полученных в процессе использования получившегося решения:
8Tб распределены на 64 шарда
35k RPS — максимальная нагрузка на сервис, оперирующий кластером (60k QPS на шарды)
50ms response time по 95 перцентилю.
Надеюсь, данная статья помогла вам немного лучше понять принципы внутренней работы шардинга.

