
В процессе написания очередной программы задумался над тем, какой способ создания списков в Python работает быстрее. Большинство моих знакомых используют квадратные скобки. А некоторые совсем забыли о существовании функции list(). Предлагаю Вашему вниманию небольшое исследование. Узнаем правы ли коллеги. А заодно на примере простой задачи посмотрим как можно проводить свои собственные исследования.
Для работы нам понадобятся встроенные в стандартную библиотеку модули dis и timeit, а так же matplotlib. Его необходимо установить отдельно командой pip install matplotlib. Впрочем, мы задействуем сей шедевр графикопостроения на минималках. Для графиков вполне можно обойтись электронной таблицей.
Полный код исследования доступен по ссылке https://gitlab.com/dzhoker1/function-list-or-square-brackets
Наивный подход
Начнём с создания пустых списков.
data_one = [] data_two = list()
Используя модуль dis, который занимается дизассемблированием байтового кода Python в мнемонику, можно заглянуть во внутреннюю механику создания списков. В первом случае получаем:
1 0 BUILD_LIST 0
2 STORE_NAME 0 (data_one)
4 LOAD_CONST 0 (None)
6 RETURN_VALUE
Функция list() отработает чуть дольше:
1 0 LOAD_NAME 0 (list)
2 CALL_FUNCTION 0
4 STORE_NAME 1 (data_two)
6 LOAD_CONST 0 (None)
8 RETURN_VALUE
Итак, есть первая гипотеза. Квадратные скобки не просто так стали привычкой. Они и работают быстрее. Нужен всего лишь создать список BUILD_LIST, вместо загрузки функции LOAD_NAME и её вызова CALL_FUNCTION. Но давайте продолжим исследование.
А что, если список создавать не пустым, а с данными внутри? Проверим.
Для строки кода dis('data_one = [1, 2, 3]') мы получим следующий вывод:
1 0 BUILD_LIST 0
2 LOAD_CONST 0 ((1, 2, 3))
4 LIST_EXTEND 1
6 STORE_NAME 0 (data_one)
8 LOAD_CONST 1 (None)
10 RETURN_VALUE
Что касается list(), строка dis('data_two = list((1, 2, 3))') вернёт нам:
1 0 LOAD_NAME 0 (list)
2 LOAD_CONST 0 ((1, 2, 3))
4 CALL_FUNCTION 1
6 STORE_NAME 1 (data_two)
8 LOAD_CONST 1 (None)
10 RETURN_VALUE
Неужели ничья? А что, если построить немного графиков? Для каждого из 2-х вариантов сделаем замеры через timeit, несколько раз изменяя размер создаваемого списка.
y = (2, 4, 8, 12, 16) x1 = [timeit('data_one = [1, 2]'), timeit('data_one = [1, 2, 3, 4]'), timeit('data_one = [1, 2, 3, 4, 5, 6, 7, 8]'), timeit('data_one = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]'), timeit('data_one = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]')] x2 = [timeit('data_two = list((1, 2))'), timeit('data_two = list((1, 2, 3, 4))'), timeit('data_two = list((1, 2, 3, 4, 5, 6, 7, 8))'), timeit('data_two = list((1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12))'), timeit('data_two = list((1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16))')] plt.plot(y, x1, y, x2) plt.legend(('[]', 'list()')) plt.show()
На выходе любопытный график и мысль о том, что делаю что-то не так.
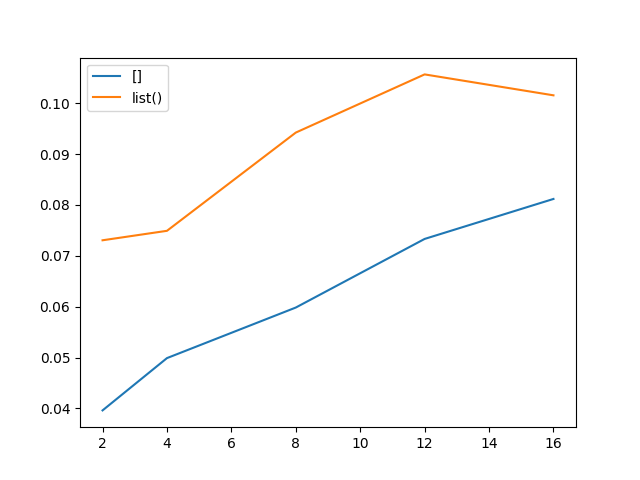
Да, квадратные скобки оказались быстрее функции. Но кто же в здравом уме формирует список вручную? Для этого есть куда более удобные способы. А значит переходим на второй виток исследований.
Функция range() для создания списков
Теперь у нас будет три претендента на самый быстрый способ создания списка.
N = 10 data_one = [i for i in range(N)] data_two = list(range(N)) data_three = [*range(N)] print(data_one == data_two == data_three)
Нижняя строка кода нужна, чтобы убедится в одинаковом результате. Ведь тестировать решения, которые дают различные ответы изначально неверно.
Начнём с дизассемблирования наших претендентов. list comprehension вернул огромную портянку мнемоники
1 0 LOAD_CONST 0 (<code object <listcomp> at 0x000001EF50E4D2F0, file "<dis>", line 1>)
2 LOAD_CONST 1 ('<listcomp>')
4 MAKE_FUNCTION 0
6 LOAD_NAME 0 (range)
8 LOAD_NAME 1 (N)
10 CALL_FUNCTION 1
12 GET_ITER
14 CALL_FUNCTION 1
16 STORE_NAME 2 (data_one)
18 LOAD_CONST 2 (None)
20 RETURN_VALUE
Disassembly of <code object <listcomp> at 0x000001EF50E4D2F0, file "<dis>", line 1>:
1 0 BUILD_LIST 0
2 LOAD_FAST 0 (.0)
>> 4 FOR_ITER 8 (to 14)
6 STORE_FAST 1 (i)
8 LOAD_FAST 1 (i)
10 LIST_APPEND 2
12 JUMP_ABSOLUTE 4
>> 14 RETURN_VALUE
Обратите внимание на цикл (пять последних строчек вывода начиная с >> 4 FOR_ITER). Эти действия будут повторяться многократно, а следовательно повлияют на суммарное быстродействие. Да и в целом мнемоника выглядит серьёзно и страшно.
Посмотрим на проигравшую в первом раунде функцию list().
1 0 LOAD_NAME 0 (list)
2 LOAD_NAME 1 (range)
4 LOAD_NAME 2 (N)
6 CALL_FUNCTION 1
8 CALL_FUNCTION 1
10 STORE_NAME 3 (data_two)
12 LOAD_CONST 0 (None)
14 RETURN_VALUE
Ого! Так просто? Собрали имена функций и переменных, пара звонков (вызовов функций) и список готов.
И остался вариант 3, самый короткий по количеству нажатий на клавиатуру.
1 0 BUILD_LIST 0
2 LOAD_NAME 0 (range)
4 LOAD_NAME 1 (N)
6 CALL_FUNCTION 1
8 LIST_EXTEND 1
10 STORE_NAME 2 (data_three)
12 LOAD_CONST 0 (None)
14 RETURN_VALUE
Как мы видим, квадратные скобки и тут оказались компактными и лаконичными.
Время устроить серию замеров времени (масло масляное рулит). Построим график для списков от 50 до 1000 c шагом 50. А для достоверности каждый эксперимент проведём 10_000 раз.
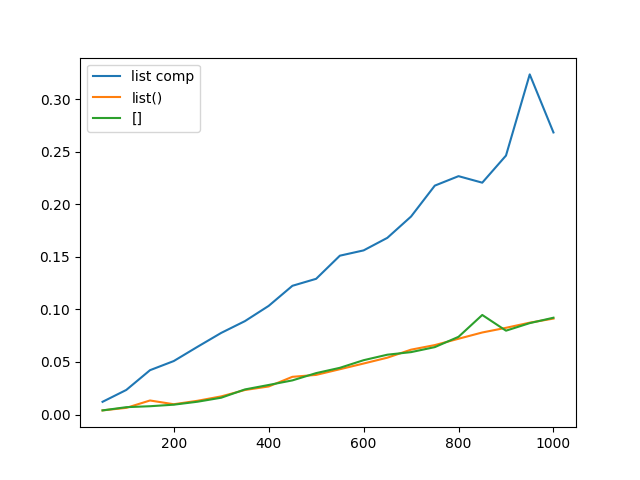
Генераторное выражение выбывает из гонки, заняв третье место. Коллеги "однострочники", вы проиграли. Впрочем, результаты дизассемблирования намекали на слабое звено с самого начала.
Функция range(). Часть 2
Устраиваем повторный забег, чтобы узнать кто же быстрее, list() или []. 50 экспериментов (создаём список от 100 до 5000 с шагом 100), проведённые по 100_000 раз.
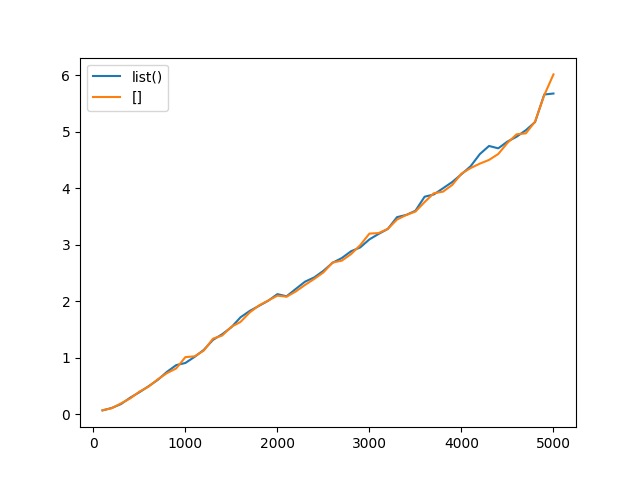
И у нас ничья. Оба подхода оказались одинаковыми по быстродействию. Но, что если всё дело в функции range()?
Финальный раунд со случайными числами
Чтобы исключить влияние функции range(), проведём финальную серию замеров. Создадим генератор, заполненный случайными числами в указанном нами диапазоне. А потом превратим его в список при помощи list() и [].
N = 10 MIN = -100_000 MAX = 10_000_000 test_data_one = (random.randint(MIN, MAX) for _ in range(N)) test_data_two = (random.randint(MIN, MAX) for _ in range(N)) data_one = [*test_data_one] data_two = list(test_data_two)
В последний раз воспользуемся модулем dis. Квадратные скобки вернут:
1 0 BUILD_LIST 0
2 LOAD_NAME 0 (test_data_one)
4 LIST_EXTEND 1
6 STORE_NAME 1 (data_one)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
А функция list() не планирует отставать:
1 0 LOAD_NAME 0 (list)
2 LOAD_NAME 1 (test_data_two)
4 CALL_FUNCTION 1
6 STORE_NAME 2 (data_two)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
В таком случае построим финальный график для вынесения вердикта. 200 экспериментов от 100 до 20_000 с шагом 100. Каждый эксперимент проведён по 1 млн. раз.
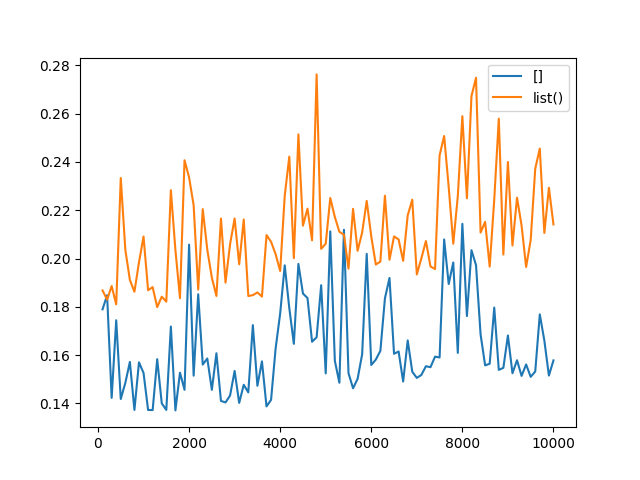
Похоже на пульс программиста в ожидании результата. И результаты говорят о том, что функция list() проигрывает [] при создании списка из генератора.
Вывод: при работе со списками использование квадратных скобок не только экономит нажатие клавиш на клавиатуре, но зачастую показывает лучшие результаты быстродействия. Впрочем, это всего лишь миллионные доли секунды. Для простых задач разницу сложно заметить. Но если привыкли работать со списком через скобки, мысль об экономии тактов процессора будет греть вам душу.
UPD: Исследования проводились на Python 3.9.10

