
Предлагаю немного поразвлечься и научиться придумывать новые слова, которые звучат совсем как настоящие (прям как товары в Икее). Для начала вот вам десяток несуществующих городов:
Лумберг, Сеф, Хирнов, Бинли, Лусский, Ноловорск, Сант-Гумит, Хойден, Голтон и Оголенд
И немного женских и имен:
Инела, Каисья, Ганнора, Целия, Тарисана, Лелена, Феомина, Олиза, Нулина и Рослиба
Для запуска генерации нам не понадобится технических навыков, хотя технология, стоящая за этим, сейчас является очень перспективной и многофункциональной. Это генеративная нейронная сеть, способная решать множество задач по обработке естествнного языка (NLP). Это такие задачи как суммаризация (сделать из большого текста его резюме), понимание текста (NLU), вопросно-ответные системы, генерация (например, стихов, — на Хабре была хорошая статья) и другие. Тема эта очень глубокая, поэтому далее я дам пару ссылок для любителей копнуть поглубже. А те, кто хочет "только спросить", может сразу приступить к созданию слов.
Генерировать будем скриптом makemore от Андрея Карпати (недавно писал про скрипт в канале градиент обреченный), который он выложил пару недель назад. Андрей является известным исследователем в мире ИИ и периодически радует народ такими вот игрушками, можно полазить по его репозиторию, там еще много интересного.
Делаем слова
Для запуска нам поднадобится Python и одна зависимость в виде фреймворка PyTorch. Если python не установлен, то ставим его. Затем ставим pytorch:
pip install torch
Копируем скрипт к себе на компьютер, кладем рядом с ним файл со списком слов, на которых мы хотим обучиться. Если мы хотим создавать новые имена, то это должен быть список имен, по одному имени на строку. Язык тут не важен, нейросеть обучается на уровне символов. Но так как она будет пытаться составлять слова из всех присутствующих символов, то убедитесь, чтобы они были из одного алфавита. Например, русские имена на кириллице.
Я подготовил несколько словарей для примера, попробуйте их, затем можете использовать свои списки для генерации слов на свою тему. Желательно, чтобы из было порядка нескольких тысяч. Города, женские имена.
Запускаем скрипт командой:
$ python makemore.py -i cities_ru.txt -o cities
Начнется процесс обучения, а к нам в консоль начнут сыпаться новые слова, чем дальше, тем лучше.
number of examples in the dataset: 10929 max word length: 27 number of unique characters in the vocabulary: 67 vocabulary: -.`ЁАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюяё number of parameters: 210560 ... step 0 | loss 2.0676 | step time 3280.48ms step 10 | loss 2.1383 | step time 56.45ms step 20 | loss 2.3182 | step time 55.55ms step 30 | loss 2.1130 | step time 57.24ms step 40 | loss 2.2769 | step time 55.46ms step 50 | loss 2.2236 | step time 56.27ms step 60 | loss 2.1755 | step time 59.49ms ...
10 samples that are new: Ермышыевка Тареп Ла-Конково Гольское Крзусто Сыревка Бангруу Балманауннти Голтон Юрчуан
После некоторого обучения можно запустить модель в режиме без тренировки и посмотреть только на новые слова:
$ python makemore.py -i cities_ru.txt -o cities --sample-only
50 samples that are new: Ририка Меимсвилл Дана-Гап Тачьякин Нигина Ассер-Куйн Свитлаум Митсу Баргиси Шивер Венния Бйокенигорд Хирава Халлы Тельск Мудделжон Шюихатай Красноарская Сваркофетольский Хорвион Стомесе-Клинглид Сен Фортингтам Бивле Ряслянд-Сититу Бамборо
Круто. Но как это все работает?
На уровень ниже
Если зайти в папку, переданную в параметре -o (cities), то вы увидете файл model.pt и файлы events.*, — это логи в формате TensorBoard'а. По ним видно как модель обучалась. При обучении данные делятся на тренировочные и валидационные, по последним можно более-менее адекватно оценивать качество модели. Если учить модель достаточно долго, то величина ошибки на тренировочных данных будет продолжать падать, в то время как ошибка на валидации со временем начнет увеличиваться, — это называется переобучением.
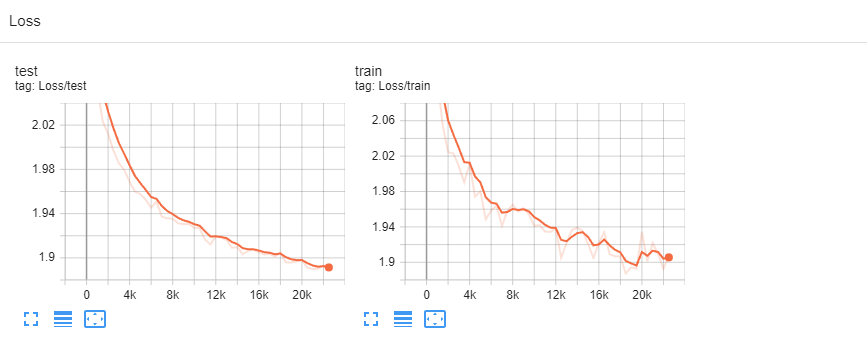
Автор говорит, что скрипт задумывался как "super hackable", поэтому давайте в него посмотрим:
class GPTConfig: # size of the model n_layer: int = 4 n_head: int = 4 n_embd: int = 64 vocab_size: int = None block_size: int = None # regularization embd_pdrop: float = 0.1 resid_pdrop:float = 0.1 attn_pdrop:float = 0.1 class TrainConfig: # optimization parameters learning_rate: float = 5e-4 weight_decay: float = 0.1 # only applied on matmul weights betas: List[float] = (0.9, 0.99) class GPT(nn.Module): """ the full GPT language model, with a context size of block_size """ ...
Действительно, в этом скрипте описывается и архитектура модели (GPT), и ее конфигурация (по-умолчанию в модели ~200k обучаемых параметров, именно поэтому вы можете обучить эту малютку у себя на компьютере без видеокарты), и работа с датасетом, и тренировочный цикл (он же train loop). Именно в train loop'е и происходит вся "магия", — модель считает некоторую функцию ошибки (loss), вычисляются градиенты (чтобы знать, "в какую сторону двигаться" для уменьшения ошибки), делается шаг обучения.
while True: ... batch = [t.to(args.device) for t in batch] X, Y = batch # feed into the model logits, loss = model(X, Y) # calculate the gradient, clip it, update the weights model.zero_grad(set_to_none=True) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step()
Вы можете поэксперементировать со скриптом, задать модель побольше, поменять величину сэмплирования и другие параметры (обратите внимание на аргументы в конце скрипта). Скрипт очень симпатичный и компактный, всего около 500 строк. Рекомендую в нем покопаться, если вам интересны нейросети или чем занимается директор компании Tesla по ИИ в свободное время.
Далее
Для дальнейшего ознакомления с темой вот вам несколько любопытных ссылок. Кроме того, я с недавнего времени веду скромный канал про машинное обучение, в котором рассказываю про новости ИИ и делюсь опытом. Приглашаю вас в него.
⚡ Градиент обреченный — мой канал в телеграм про машинное обучение и заметки о работе в DS.
? DIY. Книги для всех, даром — тут я применил NLP модели для создания параллельных книг, получилось клёво.
? Репозиторий со скриптом — репа Андрея Карпати на GitHub.
? GPT-2 в картинках — тут перевод известной статьи Джея Аламмара.
? GPT для чайников — похожая статья, но в конце есть еще ссылки.
?️ Блог Давида Дале — много хороших статей про русский NLP.
? GPT-3 Playground —тут можно поиграться с оригинальной сетью GPT-3 от OpenAI, которую если и опубликуют, то вы все равно ее не запустите в силу её огромности.
? OPT. GPT от Meta — а тут можно скачать аналог сети GPT на 30 миллиардов параметров (!). И запустить, если у вас есть A100 на 80Gb.
? Сообщество ODS — ну если вдруг кто не знает, то это большое дружелюбное сообщество по DS, ML и смежным аббревиатурам.

