Машинное обучение имеет множество применений, одним из которых является прогнозирование временных рядов.
Состояние сферы искусственного интеллекта сегодня включает в себя множество разных методов, которые позволяют расширить спектр возможностей компьютера. Например, машинное обучение, big data, нейронные сети, когнитивные вычисления и другие.
Машинное обучение – один из передовых методов, который может быть использован для идентификации, интерпретации и анализа чрезвычайно сложных структур и шаблонов данных. Это позволяет проводить последовательное обучение и улучшать прогнозы моделей с помощью систематического ввода более свежих данных.
В данной статье цель состоит в том, чтобы построить современную модель для прогнозирования временного ряда, которая фокусируется на краткосрочном прогнозировании.
Задачи
Поиск источников данных, содержащих информацию о курсе валюты.
Получение, обработка и преобразование данных к необходимому виду, интеллектуальный анализ данных.
Обозначение критериев оценивания для исследования, поиск и выбор наиболее подходящих моделей машинного обучения, разработка программных средств.
Решение задач на основе выбранных моделей машинного обучения, выполнение эмпирического исследования, сбор материала, анализ полученных данных, сравнение результатов.
Что делаем?
С помощью сокетов получаем датасет с binance, анализируем полученные данные и преобразовываем для поставленного исследования,
Строим модель RNN с подходящими гиперпараметрами,
Строим модель полносвязной сети со схожими гиперпараметрами,
Проводим сравнительный анализ.
Данные "ДО"
Датасет для задачи был взят с помощью сокета с ресурса binance в формате txt.

После преобразования данных из txt формата в формат pandas dataframe получаем датасет, где:
"e": "trade" – тип события
"E": 123456789 - время события
"s": "BNBBTC" - тип валюты
"t": 12345 - ID (идентификационный номер трейда)
"p": "0.001" - цена
"q": "100" – количество использованных для трейда единиц валюты
"b": 88 – ID (идентификационный номер покупателя)
"a": 50 – ID (идентификационный номер продовца)
"T": 123456785 – время трейда
"m": true – является ли участник торгов маркет мейкером

При попытке обучить модель и сделать прогноз были получены результаты, совсем не совпадающие с реальным графиком динамики при различных установленных гиперпараметрах и различных взятых для обучения признаках.
Данные "ПОСЛЕ"
Подобные задачи решаются с использованием датасета, в котором указаны такие признаки, как цена при открытии торгов, цена при закрытии торгов, максимальное значение цены за обозначенный отрезок времени, минимальное значение цены за обозначенный отрезок времени, количество использованных для трейда единиц валюты и время трейда.
Данные были преобразованы в подобный формат и представляли из себя:
time – время трейда
min – минимальное значение цены за обозначенный отрезок времени
max – максимальное значение цены на обозначенный отрезок времени
close – цена при закрытии торгов

Задача предсказания строится таким образом, что при обучении модели признаками x требуется предсказать результат y+1.
Признаками x являются признаки time, max и min. Признаком y является признак close.
Модель RNN
Для выполнения задачи прогнозирования были выбраны наиболее популярные для этой задачи рекуррентные нейронные сети. Это сети, содержащие обратные связи и позволяющие сохранять информацию. Рекуррентную сеть можно рассматривать как несколько копий одной и той же сети, каждая из которых передаёт информацию последующей копии.
За последние несколько лет RNN с успехом применили к целому ряду задач, таким как распознавание речи, языковое моделирование, перевод, распознавание изображение и так далее. Немалая роль в этих успехах принадлежит LSTM, необычной модификации рекуррентной нейронной сети, способной к обучению долговременным зависимостям и на многих задачах значительно превосходящей стандартную версию.
При построении RNN модели была использована библиотека Keras.
Модель состояла из:
входного слоя LSTM с количеством нейронов, равным количеству признаков датасета,
скрытого слоя LSTM с количеством нейронов, равным количеству признаков входного датасета,
выходного слоя Dense с количеством нейронов, равным одному.
Модель создана и обучена следующим образом:
model = Sequential() model.add(LSTM(x_train.shape[1], return_sequences=True, input_shape=[x_train.shape[1], 1])) model.add(LSTM(x_train.shape[1], return_sequences=False)) model.add(Dense(1)) model.compile(optimizer='adam', loss = 'mean_squared_error') model.fit(x_train, y_train, batch_size = 1, epochs=30)
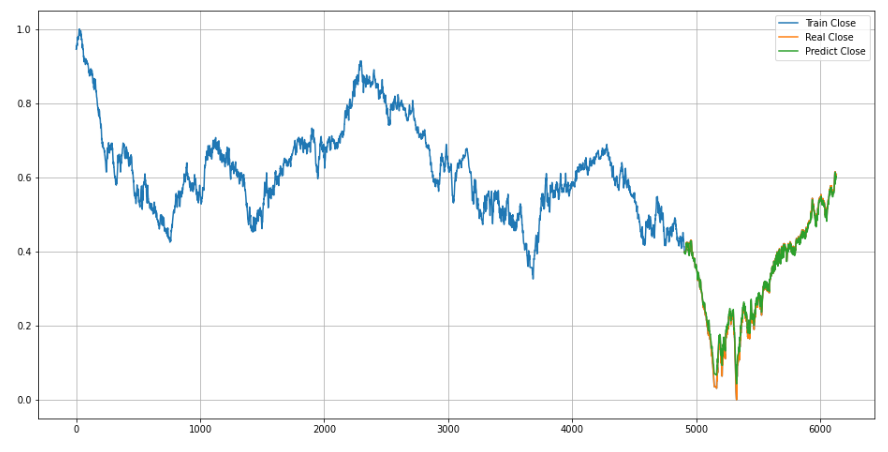
Итоговые результаты обучения:

На диаграмме видно, что график предсказания очень сильно приближен к реальному графику ценового тренда:
Модель полносвязной сети
Для сравнения работы с другой моделью так же была использована библиотека Keras.
Модель состояла из:
входного полносвязного слоя Dense с количеством нейронов, равным количеству признаков x обучающего датасета,
скрытого слоя Dense с количеством нейронов, равным количеству признаков входного датасета,
выходного слоя Dense с количеством нейронов, равным одному.
Данная модель была создана и обучена аналогично предыдущей модели:
model1 = Sequential() model1.add(Dense(x_train.shape[1], input_shape=[x_train.shape[1], 1])) model1.add(Dense(x_train.shape[1])) model1.add(Dense(1)) model1.compile(optimizer='adam', loss = 'mean_squared_error') model1.fit(x_train, y_train, batch_size = 1, epochs=30)
Итоговые результаты обучения:

На графике видно, что график предсказания очень далёк от реального графика динамики:

Сравнение двух моделей и результаты
Как показали результаты предсказаний:
Разница потерь (loss = “mean_squared_error“) у моделей отличается в более чем 500 раз,
График RNN модели наиболее приближен к реальному графику, чем график предсказания модели полносвязной сети.
Исходя из этих результатов, можно сказать, что RNN модель показывает себя в задачах предсказаний лучше, чем модель полносвязной сети, и её можно применять для решения задач предсказания временных рядов и предсказания динамики ценового тренда, в частности.
Так же увеличение количества полезных признаков и набора данных может помочь добиться ещё более точных результатов на наибольший временной период предсказания данных.

