Привет, друзья! Это Жека Никитин. Сегодня хочу с вами поделиться нашими практиками MLOPS – что по сути является модным словцом, а на самом деле есть ни что иное как жизненный цикл создания и функционирования ML-систем.
Естественно, каждая модель и задача уникальна. Но в этой статье я постарался максимально разбить процесс развития ML-систем на основные этапы. Поговорим о том, какие требования мы предъявляем к этим этапам и какие инструменты при этом используем. Материал представляет собой текстовую версию доклада на LeanDS.

Какие этапы проходит ML-система за свою «жизнь»?
Сначала хотелось бы сделать небольшую ремарку. Несмотря на то, что мы рассматриваем общий ML-процесс, прошу учесть, что мы работаем с медицинскими изображениями: как 2D (рентген), так и 3D (КТ и МРТ исследования). Поэтому многие примеры реализации будут приводиться именно из этой области. Прошу отнестись с пониманием).
Прежде чем приступить к обсуждению конкретных практик, давайте рассмотрим, как вообще выглядит жизненный цикл типовой ML системы. Конечно, в зависимости от вводных данных и задачи какие-то пункты могут быть исключены – но все же, в общем и целом, этапы выглядят следующим образом:
Оценка осуществимости и значимости гипотезы.
Сбор и очистка данных.
Разметка данных.
Обучение модели.
Оценка качества и устойчивости модели.
Развертывание в продакшн.
Мониторинг.
При этом слово «цикл» я употребил не просто так: ведь данная последовательность этапов в абсолютном большинстве случаев не будет следовать один за другим линейно. Так, например, на этапе оценки качества и устойчивости модели мы можем сделать выводы о необходимости разметки определенного типа данных или же выдвинуть новую гипотезу по обучению нейронной сети с измененной архитектурой. А иногда на этом этапе вообще может быть принято решение о сворачивании гипотезы и переходе к концептуально другой.
Оценка осуществимости и значимости гипотезы
Прежде чем приступить к проекту, его необходимо оценить с разных сторон. Идеи могут рождаться как до начала работы, так и внутри процесса. При этом способность «убивать» идеи на начальном этапе очень важна – так как позволяет сэкономить много времени.
Если рассмотреть «нетехническую» составляющую, то сначала следует ответить на три основных вопроса:
Решает ли продукт важную и распространенную проблему?
Готова ли целевая аудитория продукта платить за решение этой проблемы?
Можем ли мы создать такой продукт в разумные сроки с адекватным уровнем затрат?
Если у нас на этом этапе мы получили положительные заключения по реализуемости проекта, то в ход вступает оценка с технической стороны:
Доступность данных. Есть ли публичные данные? Возможно ли получать и размечать требуемые данные? Решались ли похожие задачи в похожих доменных областях?
Освоение новых технологий и знаний. Потребуется ли работать с новыми форматами данных? Потребуется ли решать задачу нового типа? Есть ли у нас доступ к профессиональным знаниям? Например, при работе с медицинскими данными нам необходимо верифицировать гипотезы и задавать вопросы врачам-экспертам, чтобы итоговый продукт не имел предубеждений, был близким и понятным целевой аудитории.
Требуемое и достижимое качество. Чего можно достичь с помощью готовых бейзлайнов и простых демо и насколько это близко к тому, что нам нужно? Какие метрики у признанных экспертов в решении такой задачи? С какого уровня качества можно начинать внедрять наше решение?
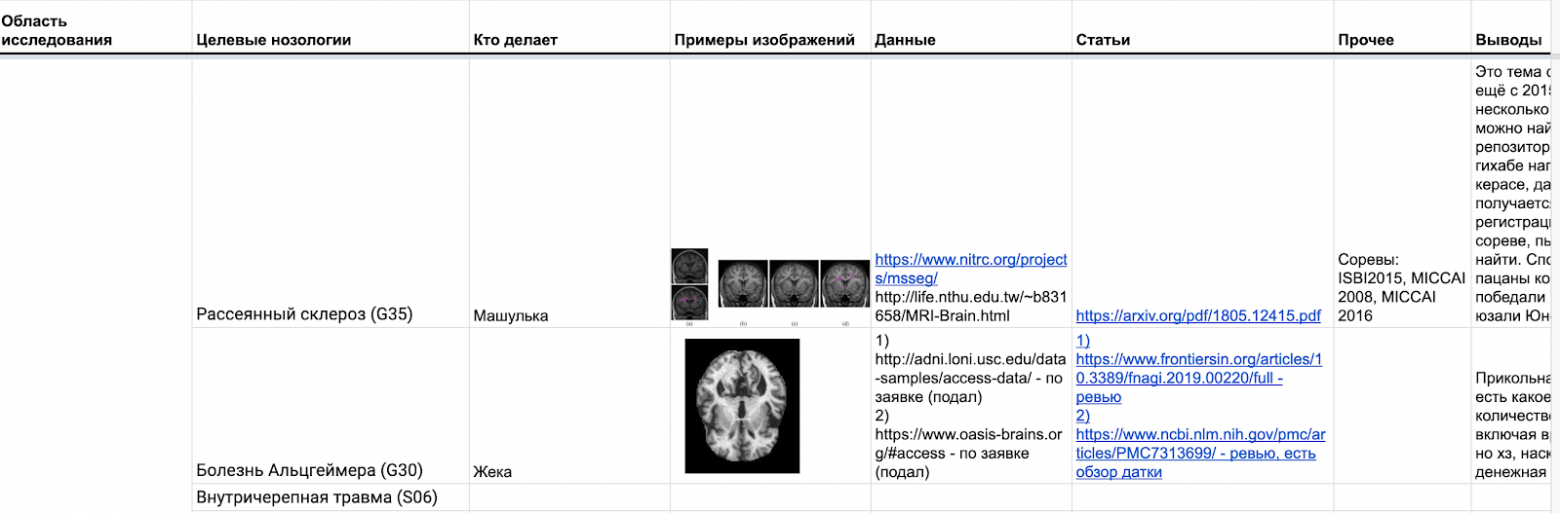
Так может выглядеть реализация проверки гипотез внутри проекта.
Также стоит выделить подходы к сравнению идей внутри проекта - ICE/RICE, голосование, HiPPo.
Сбор и очистка данных
Допустим, мы отобрали гипотезы. Следующим (и одним из ключевых) этапом будет сбор и очистка данных. Почему он так важен и что мы хотим на нем получить?
Во-первых, мы хотим чтобы они надежно хранились без возможности несанкционированного доступа и искажения. Для нас выгрузка данных из медицинской организации – это не только сложный организационный, но и юридический вопрос. Поэтому утрата таких трудозатрат – просто непозволительная роскошь.
Во-вторых, мы хотим удобно и быстро их передавать (с централизованного хранилища на локальный компьютер ML-специалиста). В медицине трехмерные датасеты (например, компьютерные томографии) очень тяжеловесные, речь идет о терабайтах информации в одном датасете. Наверное, не очень прикольно, если данная процедура будет занимать по полдня, в течение которых инженер не сможет работать над задачей?)
В-третьих, необходимо иметь возможность версионировать данные: допустим, сначала мы размечали одни патологии на флюорограммах и сделали эту разметку в бибоксах, а на следующем этапе размечали масками и другие классы. Если не реализовать такую процедуру, то очень быстро начинается бардак. Рано или поздно захочется репродуцировать эксперимент – а окажется, что это физически невозможно ввиду отсутствия версионирования.
Ну и, наконец, в-четвертых, процедура должна быть в той или иной мере прозрачной, и мы в любой момент должны иметь возможность БЫСТРО ответить на простые вопросы из разряда: какие у нас есть данные, сколько их, из каких источников.
Если говорить об инструментах, то для хранения мы используем Yandex Object Storage, Azure Storagе. Среди плюсов: надежность, данные неограничены. Из минусов: трансфер данных и их хранение может влететь в копеечку. Есть также и локальные решения: Minio, SSH Fileserver. Они быстрые, бесплатные, но у них нет версионирования «из коробки», они не так надежны и ограничены локальным железом.
В нашем случае мы используем комбинацию решений, поскольку медицинские данные терять или оставлять незащищенными никак нельзя. При этом «тренируемся» мы на локальном сервере с GPU, базирующимся у нас в офисе.
Также медицинские данные подразумевают хранение их разметки. Тут также возможны вариации.
Разметку можно хранить в CSV/XML/JSON. В этом случае сама разметка будет очень легковесной. Однако сам такой формат будет не унифицирован, и сложно будет организовать автоматическую документацию этих данных.
Можно использовать базы данных. Тогда мы будем иметь унифицированный формат и возможность полной автоматической документации, но при этом будем сталкиваться с нюансами версионирования, и нужно будет постоянно поддерживать такую архитектуру.
Мы – безусловно, как и многие ML- проекты – сначала все хранили в первом формате. Потом начали активнее интегрировать БД для хранения датасетов. Сейчас же мы целиком переехали на базы данных.
Как же быть с версионированием?
Казалось бы, самый простой ответ на этот вопрос – попросту на него забить и вообще не версионировать данные. С одной стороны, это просто: не нужно тратить дополнительное место. Но есть и очевидный минус: если вы не будете версионировать данные, то ваше сумасшествие – всего лишь вопрос времени.
Приведем пример. Число данных и экспериментов разрастается. Кто-то из сотрудников докинул данных в валидационный сет. Метрики по эксперименту не бьются. Вы не понимаете, почему так происходит, перепроверяете – и, разумеется, не можете найти причину. Вуаля! Привет, 13 палата – приехали.
Второй подход – версионирование сплитов в репозиториях. Основное назначение подхода – обеспечение воспроизводимости экспериментов при неизменности самих данных.
Но есть и полноценный хардкор-подход для истинных ценителей порядка: использовать DVC. В данном случае вы обеспечите полную воспроизводимость, но и поплатитесь необходимостью обучения сотрудников новому инструменту. А также тем, что с его помощью сложно работать с большими датасетами.
Немного инструментов для работы с данными
EDA
Когда мы говорим про датасеты, так или иначе на память приходит EDA. При этом концептуальных инструментов для реализации exploration data analysis может быть два. Первый – простой и привычный Jupiter Notebook. Кто-то его ненавидит, кто-то очень любит. Я, например, очень люблю и считаю, что лучшего инструмента для того, чтобы поиграть с данными, попрототипировать, просто не существует.
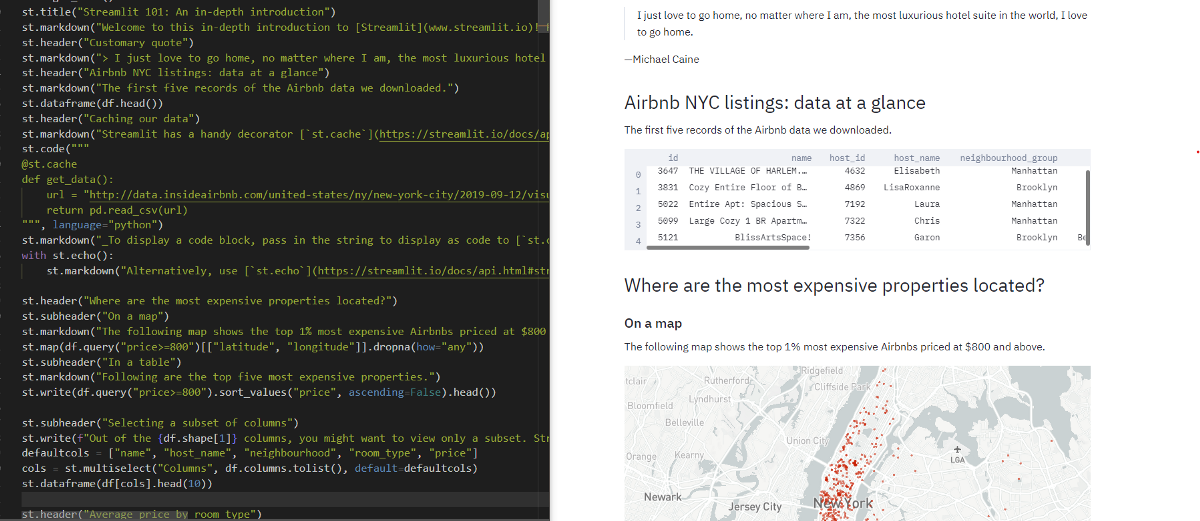
Есть более продвинутый инструмент – Streamlit. Грубо говоря, он дает возможность создания быстрых веб-приложений и интерактивных отчетов. Безусловно, он уже более наглядный, там можно подвигать ползунки и понять как меняются наши данные.
Второй атрибут, который поможет вам не сойти с ума (или уже помогает) – это Dataset Card. Основное его назначение – документирование данных. Карточка датасета содержит важнейшую информацию о нем: что это за данные, как нами получены, какой объем и специфика, какая у него лицензия и т.п.
Помимо решения задачи прямого документирования, карточки датасетов помогают быстрее проходить процесс онбординга новичкам в отделе, помогает ML-отделу и прочим связанным отделам принимать решения относительно данных и вектора их развития.
Реализация dataset Card также может быть различной: это может быть Google-документ, Markdown или даже Streamlit приложение, которое в онлайн-режиме выгружает из той же базы данных информацию.
Разметка данных
Разметка данных – один из важнейших этапов. Но стоит оговориться: не во всех задачах он нужен и не во всех целесообразен. Учитывая нашу специфику и необходимость показывать врачам-рентгенологам контуры патологических объектов на исследованиях, качественная разметка очень важна.
Качественная разметка – это какая?

В нашем понимании – это та, которая максимально приближена к наибольшей точности выделения истинных объектов, которая производится с максимально возможной скоростью и за минимальные деньги.
Для организации процедуры максимизации качества мы реализуем процесс кросс-разметки и процедуру отбора врачей-разметчиков, их дальнейшего обучения и итогового тестирования.
Для максимизации скорости мы стараемся влиять на процесс изнутри, определяя наиболее эффективные и интуитивные инструменты разметки (в нашем случае supervisely). В задачах, где достаточно размечать «коробками», может быть вполне достаточно и бесплатных инструментов – таких как labellmg
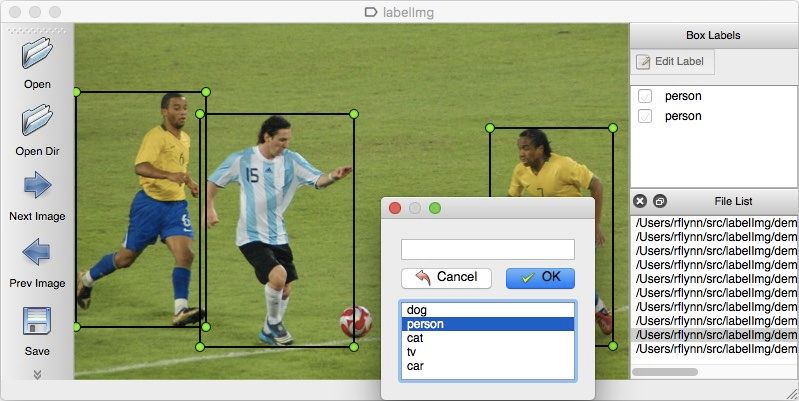
Также на эффективность разметки влияет и само оборудование (монитор, рабочая станция врача, на которой эта разметка проводится). Свою лепту вносит и инструментарий псевдоразметки и авторазметки (auto annotation tools). Эта группа методов позволяет отдавать разметчикам в работу не рандомные исследования, а те, разметка которых предположительно принесет нам максимальную ценность с точки зрения роста целевых метрик.
На снижение стоимости процесса также влияют процедуры активного обучения, интегрированные в модель.
Обучение модели
Вот мы и подобрались к тому этапу когда мы закончили подготовительные процедуры и садимся кодить. Безусловно, про это можно написать много. Но что нам действительно важно на данном этапе?
Воспроизводимость экспериментов.
Удобство сравнения экспериментов.
Скорость тестирования гипотез.
При этом на последний пункт можно вынести основной фокус – так как это процесс, который не имеет смыслового конца. Чем быстрее итерируемость и проверка гипотез в команде – тем выше эффективность.
Инструменты
Если говорить про DL-фреймворки, то их можно разделить на условные три класса:
Голые фреймворки – PyTorch, TensorFlow. Которые, с одной стороны, будут весьма гибкими, а с другой – обеспечивать дублирование кода и лишней работы.
High-level фреймворки – Lightning, Catalyst. Тут ситуация обратная: меньше дублирования кода и меньше гибкости.
Самописные. Гибкие, но их очень тяжело и дорого поддерживать.
Тут мы прошли весь путь, однако пришли к первому пункту, решая вопрос дублирования кода вынесением его элементов в библиотеки – и не очень паримся по поводу того, что CTRL+С и CTRL+V происходит время от времени.
Если говорить про трекинг экспериментов, то реализовать данный процесс, безусловно, можно в Excel таблице.

Неплохо для начала, но хочется же чего-то большего. Тогда на помощь могут прийти специализированные платформы – такие как ClearML, Neptune, MLFlow. Для себя мы остановили выбор на ClearML. В нем хорошо реализован функционал трекинга экспериментов, есть весьма быстрая поддержка пользователей. Ну и самый главный плюс: система OpenSource полностью бесплатна.
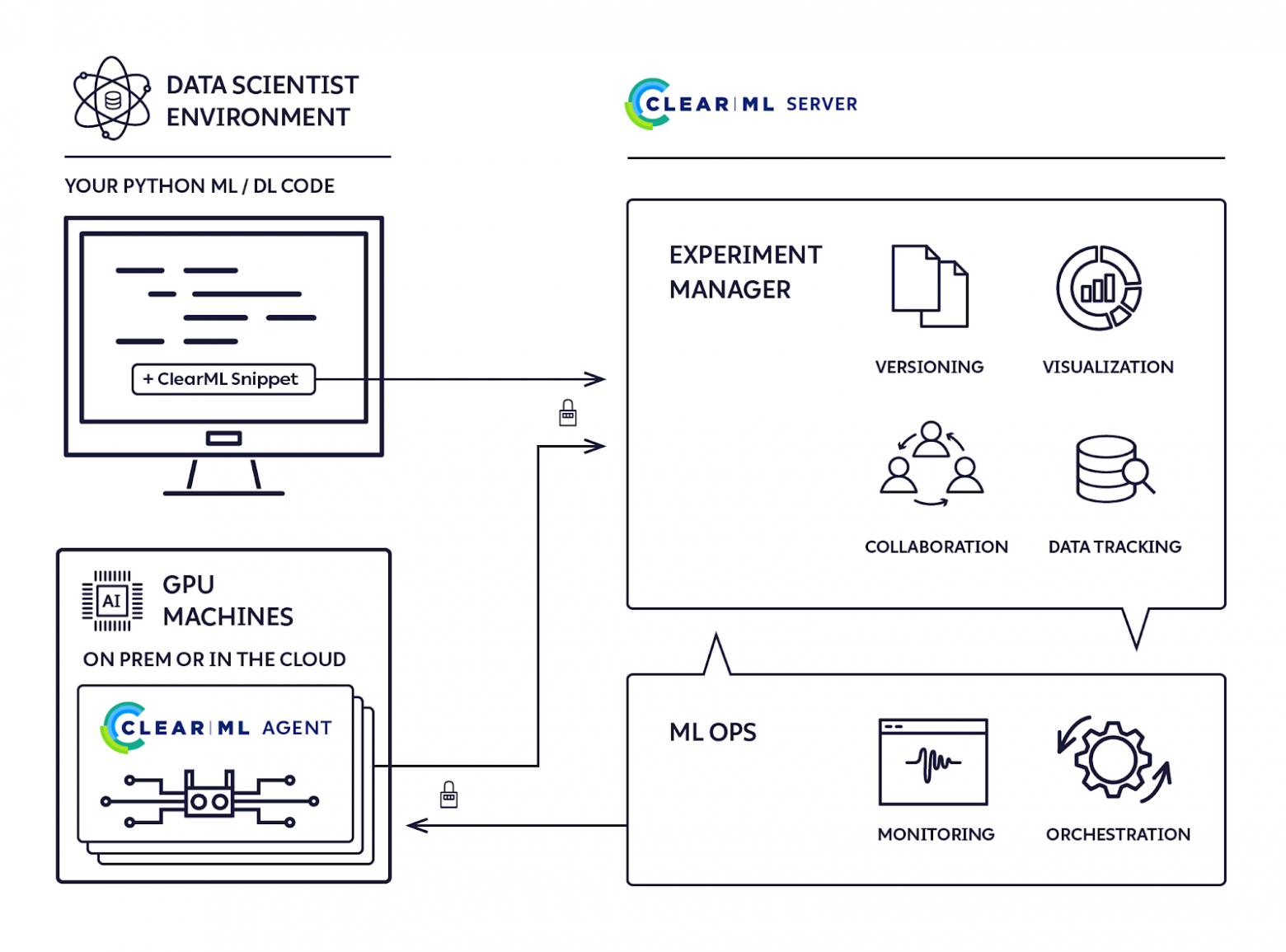
(компоненты ClearM – Код DS-специалиста, Серверная часть, Агент (GPU))
Что нам дает такая автоматизация?
Трекинг – код (commit id + git diff), гиперпараметры, входные модели, данные;
Логирование – все артефакты (модели, картинки и т.д.), метрики, потребление ресурсов, аутпут питона;
Web UI –можно ставить и трекать эксперименты откуда угодно;
Оркестрирование – автоматический старт экспериментов внутри докер-контейнеров;
Пайплайны – объединение экспериментов в связанные цепочки;
Интерактивные сессии –Jupyter-ноутбуки на нашем железе с любого компьютера с доступом в интернет.
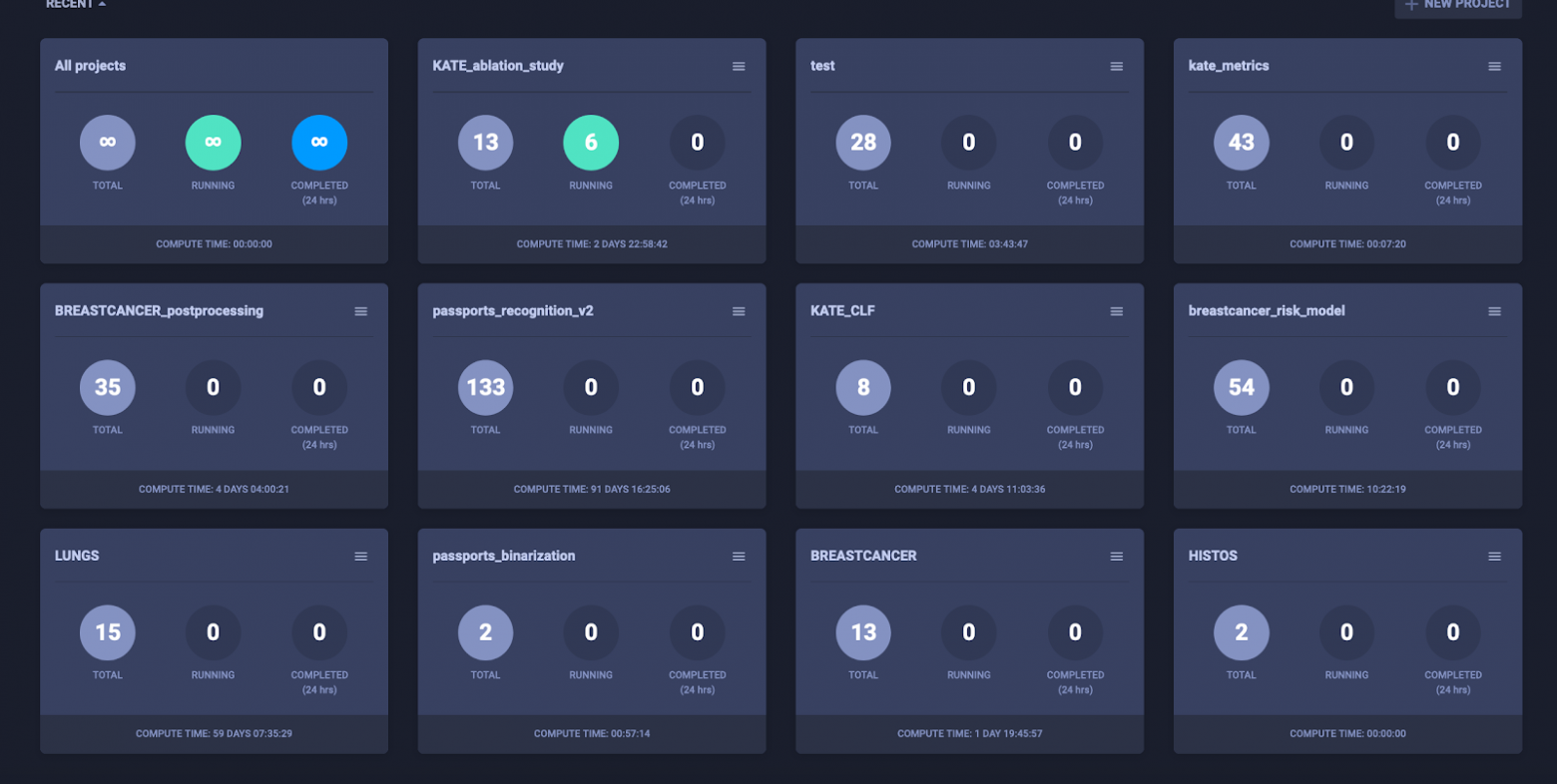
Дашборд
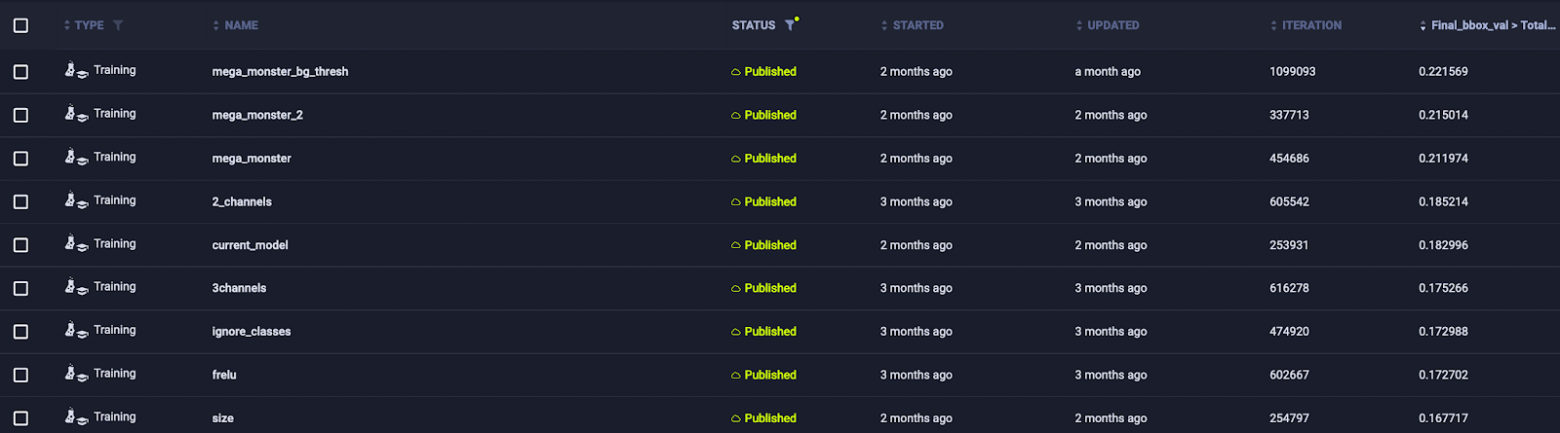


Графики сравнения экспериментов в ClearML
Ну и, конечно, по готовности экспериментов нам необходимо их оценивать – что также является частью оптимизационного процесса.
Инструменты для оценки экспериментов
В отличие от предыдущих технических инструментов, для оценки внедряются, как правило, процессные инструменты. Среди них стоит выделить процедуры:
Code Review (на этапе мерджа в мастер или релизную ветку проекта).
Experiment Review.
Карточка эксперимента со ссылкой на ClearML, включающая основные метрики и выводы. Также может быть реализовано в формате поста в вашей рабочей группе в Telegram или Slack.
Findings
Оценка качества и устойчивости модели.
Итак, на данном этапе мы обучили модель, выбрали лучший эксперимент. Но перед тем, как выводить новую версию клиентам, мы хотим убедиться, что у нас все хорошо, корректно и устойчиво работает.
Что на этом этапе для нас важно?
Качественная работа системы – отсутствие багов и адекватные предсказания.
Скорость и надежность работы под нагрузкой.
Отсутствие критических ошибок с точки зрения пользователя.
Гарантия рабочего и качественного тренировочного кода.
Какие инструменты способны нам обеспечить реализацию таких целей?Как несложно догадаться, это тесты. Но тесты бывают разные. Самые лучшие – автоматические тесты. По направлениям их можно разбить следующим образом:
Интеграционные тесты – проверяют работоспособность приложения в целом.
Метрик-тесты – ML-метрики.
Стиль-тесты – соответствие кода стандартам.
Тесты на воспроизводимость обучения.
Стресс-тесты – надежность работы под нагрузкой.
Юнит-тесты – тесты отдельных частей приложения.
Среди инструментов реализации тестов можно выделить: Docker Compose, PyTest и Black.
Но не стоит забывать что тесты могут быть и ручными – особенно когда мы говорим про такую сферу деятельности как медицина.
В первую очередь нам важно визуальное тестирование предсказаний (причем как сотрудниками, так и фокус-группой врачей). Также нам важна корректная работа UI приложения и корректная работа на проблемных случаях (на которых сталкивалась с проблемами более ранняя версия системы). Ну и, безусловно, корректность с работой out-of distribution случаев.
Если ваша система детектирует рак на канистре, сканированной в рентген-аппарате, едва ли врач – пользователь системы – будет этому рад. А ведь такие рентгенограммы не редкость на этапе настройки нового оборудования в клиническом учреждении.

Ну и, конечно, по итогом всех тестов соответствующие изменения должны быть отражены в новой версии Model Card
Развертывание в продакшн
Далеко не все ML-системы доживают до этого этапа, но если вам повезло и все предыдущие этапы пройдены, то здесь тоже нужно уделить внимание деталям.
На этапе развертывания нам важно:
Удобно запускать процесс. Желательно одной кнопкой
Иметь возможность быстро «откатиться» до предыдущей версии
Быстро и легко масштабировать разные части приложения, чтобы подстраиваться под нагрузку
Менять конфигурацию

Если рассмотреть схематично, то процесс можно проиллюстрировать следующими этапами. Клиент посылает запрос на API, реализованное с помощью Fast API или Flask, далее задача попадает в очередь на обработку – с помощью, например, Salary. Далее запускается ее обработка. Очередь реализована в Redis, где нейронка уже бачами забирает на обработку предобработанные картинки, после чего выдается результат.
Инструменты для деплоя
При выборе инструментов на этом этапе также существует высокая вариативность – в зависимости от ваших целей и задач.
В нашем случае это:
Docker, который служит для контейнеризации всех сервисов;
Kubernetes & Helm – легкость скейлинга, конфигурации и взаимодействия сервисов.

Для самого же процесса релизов мы используем Azure Pipelines, чтобы по одной кнопке создавать гибкие пайплайны сборки.
Мониторинг
Когда мы осуществили сборку и релиз, нам нужно быть уверенными, что в один прекрасный момент это все не обвалится. И что если обвалится – мы сможем точно понять, когда это произошло и из-за чего.
Среди основных требований к мониторингу:
Удобство;
Скорость реакции;
Низкое число требований к человеческому ресурсу.
Инструменты:
Sentry
Slack
Zabbix
Кастомные дашборды и отчеты
Kubernetes Dashboard
В нашем случае отправка сообщений об ошибках реализована в Sentry, который отправляет отчет в профильный канал корпоративного мессенджера Slack – где к задаче уже подключается конкретный исполнитель и разбирается с причинами ошибки.
Также мы используем кастомные отчеты, дашборды и уведомления:
Отчеты об обработке исследований – 3 раза в день: утром, днем и вечером. В них мы видим число успешно обработанных исследований и обработанных с ошибками. Также в них отражается количество запросов, гистограмма предсказаний и другие статистики.
В дашбордах отражаются сами запросы и визуализация предсказаний. В нашем случае – маски на исследованиях с контурами тех или иных объектов (например, рак).
Кастомные уведомления, включающие, например, резкое изменение входных данных, переменных или же предсказаний нейронной сети.
Заключение и рекомендации.
Несмотря на то, что процесс MLOPS весьма многогранен и вариативен, не стоит внедрять сразу кучу новых инструментов и практик. Лучше делать это по мере необходимости. Целесообразно постоянно изучать чужие решения и практики, экспериментировать – но не заниматься слепым копированием (особенно если у вас специфический продукт).
Вам часто придется сталкиваться с тем, что готовых решений «из коробки» для вас не будет. Придется использовать несколько инструментов – готовые и самописные. Это нормально.
Старайтесь максимально автоматизировать все, что съедает время, но не перебарщивайте с алертами. Иначе можно сойти с ума.
Если вы хотите узнать ещё больше об организации процессов ML-разработки, подписывайтесь на наш Телеграм-канал Варим ML
Желаю крутых сеточек и драйвовых проектов!
Жека Никитин.

