
Реактивное программирование в Java — полезный инструмент со множеством применений. Его суть в асинхронной обработке поступающих сообщений, и есть несколько вариантов реализации этого механизма.
И Java в целом, и Spring Framework в частности подразумевают несколько аспектов реактивного программирования. Это касается Spring WebFlux в качестве замены Spring MVC. Также можно использовать Project Reactor в Java непосредственно, без Spring Framework. Однако Spring предоставляет средства декларативного определения функции Spring Cloud Function и средства интеграции приложений с использованием внешних очередей в рамках проекта Spring Cloud Stream. В комплексе эти средства позволяют широко использовать реактивное программирование, упрощая создание, размещение, масштабирование и обслуживание приложений.
Помимо создания новых приложений, Spring Cloud Function/Stream позволяют модифицировать и существующие приложения, облегчая жизнь разработчикам в реализации горизонально масштабируемых сервисов.
Статья является кратким обзором компонентов Spring Framework, позволяющих реализовывать программы в терминах функций асинхронной обработки сообщений. И ориентирована на разработчиков, уже знакомых со Spring Framework, но ещё не имеющих опыта построения реактивных приложений с декларативным управлением функциями-компонентами.
Состав компонентов
Project Reactor
Библиотека реактивного программирования с неблокирующим обменом данными и контролем противодавления. Развивается как самостоятельный проект. Если в первых версиях это был просто каркас для создания реактивных цепочек, то сейчас проект оброс средствами межпроцессного и межмашинного взаимодействия: Reactor Netty, Reactor Adapter, Reactor Kafka, Reactor RabbitMQ и пр.
Противодавление — это дисбаланс нагрузки операторов в конвейере обработки данных. Дисбаланс грозит ростом потребления оперативной памяти (как из-за накопления сообщений в очереди, так и из-за медленных операторов-агрегаторов) и неравномерной загрузкой ядер процессоров и целых серверов. Контроль противодавления позволяет выровнять нагрузку за счёт замедления обработки отдельных операторов, но без снижения общей пропускной способности.
Spring WebFlux
Реализация неблокирующего механизма обработки HTTP-запросов. Благодаря Project Reactor можно описывать цепочки обработки в функциональном стиле. Есть контроль противодавления.
Spring Cloud Function
Проект, цель которого — предоставить инструмент создания компонентов, пригодных для высокоуровневого управления уровнем бизнес-логики. Подразумевает возможность создания таких компонентов, декларативного программирования для связывания отдельных компонентов в более сложные конструкции, а также возможность автономного размещения созданных компонентов как сервисов или облачных функций в бессерверном варианте.
Spring Cloud Stream
Фреймворк для создания событийно-управляемых горизонтально масштабируемых микросервисов. Фактически это дополнение к Spring Cloud Function, дающее интерфейсы для взаимодействия с RabbitMQ, Apache Kafka, Amazon Kinesis, Google Pub/Sub, AWS SQS и другими.
Spring Cloud Data Flow
Инструмент создания микросервисов потоковой (Spring Cloud Stream) и пакетной (Spring Cloud Task) обработки данных и их размещения в Cloud Foundry и Kubernetes. Позволяет создавать сложные топологии конвейеров обработки данных из отдельных приложений Spring Boot. Предполагает несколько сценариев использования обработки данных: ETL, импорт/экспорт, потоковая обработка событий и аналитика. Дополнительно имеет графический интерфейс для композиции сервисов (Spring Flo).
Spring Flo
JavaScript-библиотека для создания встраиваемого браузерного HTML5-интерфейса, позволяющего строить конвейеры обработки данных. Используется совместно с Spring Cloud Data Flow, однако может быть подключён независимо.
Области применения
Реактивное программирование позволяет описывать процесс обработки сообщений как конвейер операторов, которые принимают какие-то сообщения на вход, обрабатывают и формируют сообщения (пользовательские классы, контейнеры, строки) на выходе. Как правило, поток операторов описывается в функциональном стиле. Синтаксически цепочка операторов представляет собой весьма компактный код.
Из дополнительных и неочевидных преимуществ цепочки операторов, записанной в функциональном стиле, — возможность распараллеливания без участия программиста, участвующего в её написании. Реальный конвейер может быть собран с учётом особенностей оборудования. Впрочем, этот пункт зависит уже от реализации конкретного фреймворка потоковой обработки.
Project Reactor для Java — современная основа реактивного программирования и далеко не первая реализация этой концепции в Java. При этом Reactor Core сам по себе не реализует межмашинное взаимодействие. Хотя специальные адаптеры уже существуют. Однако при помощи Spring Cloud Stream появляется возможность использовать с различными сетевыми протоколами входы и выходы описанных цепочек операторов, включая стыковку с брокерами очередей сообщений. А это позволяет получить масштабируемые микросервисные решения.
Асинхронная обработка данных, если она возможна, позволяет избавиться от лишних ожиданий завершения операций и разгрузить вычислительные системы. Механизм очередей не только обеспечивает доставку сообщений до места их обработки, но и позволяет организовать точки раздачи сообщений параллельным потребителям в кластере, количество которых легко регулировать по необходимой производительности с использованием Kubernetes и прочих подобных средств.
Кроме того, сейчас популярна концепция serverless applications, когда размещение приложений в облако происходит не в виде виртуальной машины или постоянно запущенного процесса, а в виде функций и лямбд (тут может быть и иная функциональная терминология — зависит от фантазии облачного провайдера). Ключевой особенностью тут является то, что Spring Cloud Stream позволяет подключить входы и выходы предоставляемого облачным провайдером механизма обмена сообщениями, а контроль исполнения кода и балансирование нагрузки ложится на этого облачного провайдера. Google Dataflow, Google Pub/Sub, AWS…
Надо сказать, что подход, предлагаемый Spring Cloud Stream, напоминает подход ESB (Enterprise Service Bus) с той разницей, что ESB предполагали реализацию сервисной архитектуры в рамках инфраструктуры предприятия, обеспечивая программистов ESB-приложений необходимым набором интерфейсов, очередей сообщений, средств контроля транзакций, безопасности и пр., но платой за это была необходимость использовать конкретный продукт ESB типа MuleESB, JBoss ESB и пр. В то время как Spring Cloud Stream — это минимально необходимый набор интерфейсов, позволяющий встраиваться в чужие инфраструктурные проекты.
Из неочевидных моментов: Spring Cloud Stream позволяет «нарезать» даже монолитную реализацию давно поддерживаемого приложения на множество взаимодействующих компонентов, сохранив код в одном проекте, но добавив внешнее взаимодействие. Конечно, можно сказать, что приложение следует просто запустить в кластере, но не во всех унаследованных приложениях обеспечена независимость обслуживания запросов по данным. И не все монолитные приложения обслуживают запросы разных типов с одинаковой производительностью. Обе этих проблемы могут быть решены нарезкой монолита на небольшие функционально завершенные модули даже в пределах одной кодовой базы, при условии, что появляются точки внешнего балансирования нагрузки (очереди с гарантированной доставкой). Например, RabbitMQ или Kafka.
Особенности построения конвейеров обработки
Reactor Core является базовым компонентом для создания асинхронных конвейеров обработки сообщений. Поскольку для потоковой обработки квантом данных является одиночное сообщение на входе, то будем использовать именно термин «сообщение». Под сообщением будем понимать класс с пользовательскими данными. Это может быть и стандартный класс String, и специально созданный класс-контейнер. Существует два концепта: Flux<T> и Mono<T>. И Flux, и Mono являются шаблонными классами Java и инстанцируются с конкретным типом.
Забегая вперёд, отметим, что Spring Cloud Function добавляет ещё один уровень абстракции — класс Message<T> в качестве универсального контейнера внешней передачи данных, однако на уровне внутреннего построения Flux-конвейера обработки сообщений упаковка/распаковка организована автоматически.
Приведём пару примеров со страницы проекта Reactor Core
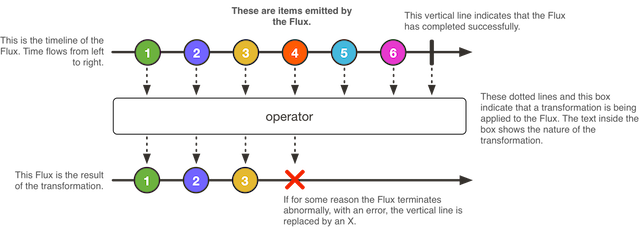
Flux описывает последовательность обработки сообщений операторами. Подразумевается наличие одного или более издателей и подписчиков данных в цепочке операторов.
Flux.fromIterable(getSomeLongList()) .mergeWith(Flux.interval(100)) .doOnNext(serviceA::someObserver) .map(d -> d * 2) .take(3) .onErrorResume(errorHandler::fallback) .doAfterTerminate(serviceM::incrementTerminate) .subscribe(System.out::println);
В этом фрагменте кода:
Flux.fromIterable() — источник данных;
.mergeWith — склейка с сообщениями, генерируемыми интервальным таймером;
.doOnNext — включение в цепочку некоторого метода-наблюдателя, который не поглощает сообщения, а просто получает управление при их появлении;
map и take — функции преобразования и отсечения первых трёх элементов потока сообщений;
.subscribe — включение потребителя сообщений в цепочку. В данном случае потребителем будет метод вывода в системную консоль (stdout).

Mono описывает последовательность обработки данных операторами при жёстком ограничении, когда каждый оператор может обрабатывать ноль или один элемент данных.
Mono.fromCallable(System::currentTimeMillis) .flatMap(time -> Mono.first(serviceA.findRecent(time), serviceB.findRecent(time))) .timeout(Duration.ofSeconds(3), errorHandler::fallback) .doOnSuccess(r -> serviceM.incrementSuccess()) .subscribe(System.out::println);
Единственное видимое отличие от Flux в этом примере — использование метода Mono.fromCallable для порождения (в будущем) ровно одного сообщения, которое будет обработано в конвейере.
Принципиальное отличие Flux от Mono — Flux позволяет группировать сообщения (например, по времени) и вычислять агрегатные функции (например, среднее значение по окну данных за последние 10 секунд). Возможность накопить сообщения в буфер позволяет повысить производительность синхронных операций, таких как сброс пакета данных за последние 30 секунд на диск или выполнение одной пакетной транзакции добавления данных в БД.
В части Mono, документация по классу которой доступна по ссылке, можно отметить, что основными методами для встраивания операторов обработки сообщений являются map/flatMap и filter. Остальные методы служат для управления потоком сообщений (назначение потребителя, триггеры на завершение/прерывание, управление временем ожидания), склейки (методы zip, and, or), методы для синхронизации сообщений в императивном коде (block, blockOptional). Они позволяют дождаться окончания обработки и получить конкретное значение.
Применительно к классу Flux, документация по которому доступна по ссылке, появляются операторы для агрегации сообщений. Среди них groupBy, groupJoin, buffer, interval, collect, collectMap, combine..., count, concat... и др. Все упомянутые методы предполагают получение (включая накопление по времени) некоторого потока сообщений, над которым одномоментно может быть выполнена какая-то операция. А методы типа window позволяют создать окно (например, скользящее), порождая новые потоки сообщений Flux ограниченного размера — public final Flux<Flux<T>> window(Duration windowingTimespan, Scheduler timer).
Ряд методов Flux и Mono служит для стыковки с императивным кодом (например, дождаться результата из какого-то потока или отправить данные в поток). Понять назначение операторов просто. Если возвращаемый оператором результат Flux<> или Mono<>, то имеем дело с реактивным потоком сообщений. В остальных случаях имеем дело с императивным кодом.
Методы преобразования данных типа map, как в случае Mono, так и Flux, могут преобразовывать одиночные сообщения простого или сложного пользовательского типа, а сама функция преобразования определяется функциональным интерфейсом Java Function<?,?>: <V> Flux<V> map(Function<? super T,? extends V> mapper).
Итак, функция обработки данных — это либо лямбда-функция с кодом по месту, либо имя метода существующего класса, либо функциональный класс, реализующий метод Function::apply.
Источниками и потребителями данных могут быть реализации стандартных функциональных интерфейсов Java: Supplier и Consumer. Они заданы либо в виде лямбда-функции, либо в форме классов.
Функции-компоненты
Spring Cloud Function создан как инструмент следующего уровня абстракции над функциональным фреймворком Reactor. И основной задачей Spring Cloud Function является выведение конвейеров Flux/Mono на декларативный уровень с возможностью подключения внешних сетевых протоколов только за счёт конфигураций без программирования на Java. Spring Cloud Function предполагает использование стандартных функциональных сущностей: источник данных (Supplier), функция (Function) и потребитель данных (Consumer) в форме порождающих их методов (то есть вызов метода создаёт нужный объект). Причём каждый такой метод упаковывается в компонент с помощью аннотации Bean и имеет уникальное имя.
Чисто технически вызов функции можно осуществить и непосредственно с помощью метода apply, однако компоненты, созданные по именам декларируемым ими функциями, могут быть декларативно (через файл конфигурации) подключены к внешним сетевым протоколам: очередям и брокерам сообщений, к средствам GCP, AWS и пр.
Поясним на простом примере, в котором numberGenerator порождает 5 чисел. Функция преобразования dataProcess преобразует число в строку. Потребитель данных dataConsumer склеивает сообщения, собранные за последнюю секунду, в одну строку и выводит в консоль.
@Bean public Supplier<Flux<Integer>> numberGenerator() { return () -> Flux.just(1,2,3,4,5); } @Bean public Function<Flux<Integer>, Flux<String>> dataProcess() { return num -> String.valueOf(num); } @Bean public Consumer<Flux<String>> dataConsumer() { return flux -> flux .buffer(Duration.ofSeconds(1)) .subscribe(list -> { String result = String.join(", ", list); System.out.println(result); }); }
Обратить внимание здесь следует на то, что все 3 метода возвращают именно функциональные объекты. Их активация через метод apply в случае numberGenerator и dataProcess породит объекты типа Flux. Потребитель данных же просто напечатает строку. При этом для каждого из трёх методов будет создан компонент с именем, соответствующим имени метода. А это имя позволяет найти и активировать компонент из любой части программы при помощи FunctionCatalog, который также является частью Spring Cloud Function. Следующий код, который обычно встречается в модульных тестах, иллюстрирует это:
@Autowired private FunctionCatalog catalog; @Test void testProcessorWithCatalog() { SimpleFunctionRegistry.FunctionInvocationWrapper func = catalog.lookup("dataProcess"); assertNotNull(func); Object result = func.apply(Flux.just(1, 2, 3, 4, 5)); //... }
Композиция функций
Декларативная композиция функций позволяет создать конвейер обработки с новым уникальным именем, образованным из имён составляющих её функций-компонентов. Этот конвейер также может быть использован как функция (при помощи вызова apply) или быть подключён к внешним сетевым протоколам. Для формирования новых конвейеров на уровне конфигурации приложения существует свойство spring.cloud.function.definition. Конвейер определяется последовательностью имён функций, разделённых знаками | или ,. Например, uppercase|reverse. Возможно формирование нескольких конвейеров сразу, где разделителем между ними будет знак ;.
Конвейер образуется из последовательности функциональных объектов на основе интерфейсов Supplier, Function, Consumer. Любая последовательность из Function в итоге будет иметь тип Function. Если последовательность начинается с типа Supplier или заканчивается Consumer, то и вся цепочка будет типом Supplier или Consumer соответственно. При этом, очевидно, последовательность не может начинаться с Supplier и заканчиваться Consumer (нет смысла замкнутых цепочек, к которым ничего нельзя пристыковать извне). Также типы Supplier и Consumer не могут встречаться где-то между Function.
Генерация сообщений
В простейшем случае программирование потоков обработки сообщений происходит в форме, где просто указывается некоторый источник данных. При этом не важно, откуда источник данных их получает — он их получит в будущем. В тех случаях, когда источником является что-то очевидно асинхронное, никакой необходимости писать дополнительный код не возникает. Например, для WebFlux контроллер будет именно таким источником. Для Spring Cloud Stream таким входом будет подключённый извне канал получения данных, назначенный на конкретную функцию-компонент или на компонент-потребитель. Однако в тех случаях, когда решается задача переписывания существующего кода в реактивный, почти наверняка возникнет необходимость генерации сообщений, которые пойдут в цепочку Flux. Сделать это можно например следующим образом:
public class DataGenerator { private final Sinks.Many<Integer> sink = Sinks.many().multicast().onBackpressureBuffer(); @Bean public Supplier<Flux<Integer>> numbersGenerator() { return sink::asFlux; } public void emitData(Integer data) { while (sink.tryEmitNext(data).isFailure()) { LockSupport.parkNanos(100); } } }
В примере выше декларируется сток для сообщений Sinks.Many<Integer> sink. Декларируется компонент-источник данных numbersGenerator, который просто возвращает Flux-цепочку, полученную из sink. И метод-инъектор данных emitData, который будет пытаться отправить данные во Flux до тех пор, пока они не будут отправлены. LockSupport.parkNanos(100) внутри цикла гарантирует, что процессор не будет перегружен попытками отправки. Причина, почему может возникнуть ошибка — например, к этому конвейеру Flux будет подключён внешний потребитель типа очереди сообщений, но брокер сообщений почему-то недоступен. По-хорошему, в коде необходимо добавить ограничение на попытки времени отправки и выдать сообщение о системной ошибке, если предел достигнут, но это зависит от конкретной логики приложения.
Подключение внешних источников/приёмников
Spring Cloud Stream реализует различные сетевые протоколы для внешнего взаимодействия подготовленных компонентов Spring Cloud Function. Соответствие входов и выходов реализованных компонентов задаётся в файле application.yml. Пример для ранее созданных компонентов:
spring: config: activate: on-profile: dev,production cloud: stream: function: definition: "\ numbersGenerator;\ dataProcess;\ dataConsumer;\ " bindingServiceProperties: defaultBinder: local_rabbit bindings: numbersGenerator-out-0: destination: fl.numbers dataProcess-in-0: destination: fl.numbers group: combiner dataProcess-out-0: destination: fl.result dataConsumer-in-0: destination: fl.result group: presenter rabbitmq: host: localhost port: 5672 username: guest password: guest virtual-host: /
Обратить внимание здесь следует на свойство spring.cloud.stream.function.definition в данном YAML-представлении, разложенном иерархически. В этом свойстве явно заданы имена функций, которые должны быть созданы. То есть "numbersGenerator;dataProcess;dataConsumer;". Обратные слэши в примере выше просто позволяют сделать запись читаемой. А точки с запятой означают создание нескольких функций.
Следующее свойство, на которое следует обратить внимание — spring.cloud.stream.function.bindingServiceProperties.defaultBinder. В данном случае это local_rabbit. Конфигурация для локально запущенного брокера очередей сообщений RabbitMQ содержится в свойстве spring.rabbitmq. Полный перечень возможных вариантов см. по ссылке
И заключительный этап — прописать имена очередей, соответствующих входам и выходам функций-компонентов. Для этого есть группа свойств spring.cloud.stream.bindings. Обратить внимание в первую очередь здесь следует на имена входов и выходов. Они образованы строго именам компонентов. То есть numbersGenerator, dataProcess, dataConsumer. А их суффиксами являются -out-0 или -in-0. Цифра обозначает номер входа/выхода. Компонент может иметь несколько входов и несколько выходов, каждый из которых — отдельный Flux/Mono-конвейер. А in/out является указанием того, вход это или выход. Эта схема именования является жёсткой. Любое изменение имени компонента (имя метода с аннотацией @Bean) должно быть отражено здесь в свойстве definition и bindings.
Ну и несколько слов относительно bindings.destination и bindings.group. bindings.destination указывает имя очереди (здесь мы подключаемся к RabbitMQ). Соответственно, …-out-… будет отправлять сообщения в очередь с указанным именем. А …-in-… будет принимать сообщения. Конфигурацию и имена мы пишем со стороны своего приложения, что следует помнить, просматривая схему имён очередей со стороны брокера. Несмотря на то, что все компоненты у нас описаны внутри одного приложения, между собой они обмениваются через внешнюю очередь.
Свойство bindings.group специфично для очередей сообщений. В случае RabbitMQ оно приводит к тому, что очередь, к которой подключаются потребители с одним и тем же именем группы, будут получать сообщения строго без дубликатов. То есть сколько бы ни было подключено экземпляров приложения, каждый из которых имеет свой экземпляр dataProcess и связь dataProcess-in-0, лишь один из них получит конкретное сообщение на обработку. Это позволяет избежать дубликатов.
В примере конфигурации выше у нас есть вход для dataProcess и вход для dataConsumer, каждый из которых ассоциирован со своей группой. Значит, что мы можем запустить, например, 10 экземпляров приложения, которые будут обслуживать dataProcess и 5 экземпляров dataConsumer для параллельного вычисления и печати соответственно. Впрочем, для этого придётся собрать приложения с разными файлами конфигурации, где активируется только часть компонентов. Для этого достаточно ограничить function.definition.
Тестирование
Особенностью приложений Spring Cloud Stream является то, что подключение конфигурации из application.yml происходит при реальном запуске приложения, но не при запуске тестов. Поскольку для выполнения модульного тестирования необходимо обеспечить независимость от внешних сервисов, то каналы, подключённые в application.yml, будут проигнорированы. Однако конфигурация spring.cloud.function.definition может быть определена в тесте, а соответственно запуск Spring Boot/Spring Cloud Function-приложения активирует указанные функции-компоненты. Причём если нам необходимо проверить связку источник-функция, то имена соответствующих компонентов должны быть указаны через знак |. Фактически это означает создание композитной функции, которую можно будет протестировать в соответствии с её типом — источник/функция/потребитель.
Пример: аннотация для класса тестирования:
@SpringBootTest( classes = SimpleStreamApp.class // класс нашего приложения ) @Import(TestChannelBinderConfiguration.class) @ActiveProfiles("test") @TestPropertySource( properties = { "spring.cloud.function.definition = " + "numbersGenerator|dataProcess;" } ) class SimpleStreamAppTest extends AbstractTest { ... }
Тестирование компонентов Spring Cloud Function можно выполнять традиционными способами, вызывая созданные компоненты функциональных Java-интерфейсов с помощью метода apply. Причём сделать это можно или непосредственно указанием конкретного метода конкретного класса Java, или найти функцию по имени в каталоге FunctionCatalog при помощи SimpleFunctionRegistry.FunctionInvocationWrapper func = catalog.lookup("dataProcess");
Специфичный для Spring Cloud Stream способ заключается в использовании каналов, через которые по номеру или по известному имени канала (от имени композитной функции) можно передать данные внутрь функции или забрать результат. Если выходной канал только один (как в случае выше, definition определяет композицию из двух функций, но только в рамках одного конвейера), то достаточно воспользоваться тестовым объектом класса org.springframework.cloud.stream.binder.test.OutputDestination, подключённым через аннотацию @Autowired, и методом receive с единственным параметром времени ожидания. Впрочем, лучше указать имя канала, которое в случае композитных функций состоит из их склеенных имён без дополнительных знаков и суффикса -out-0 по правилам, упомянутым ранее.
Код, соответственно, выглядит примерно следующим образом. При этом ответ ожидаем внутри контейнера Message, поэтому делаем десериализацию с помощью com.fasterxml.jackson.databind.ObjectMapper. Фрагмент здесь приведён из нижеследующего полного примера приложения, поэтому вместо упомянутого ранее результата преобразования со стандартным типом String указан сложный пользовательский тип UserStatistics.
IntStream.range(0, 1000).forEach(numbersGenerator::emitData); final Message<?> message = outputDestination.receive(WAITING_TIMEOUT_MILLIS, "numbersGeneratordataProcess-out-0"); assertNotNull(message, "processing timeout"); final Object payload = message.getPayload(); assertTrue(payload instanceof byte[]); UserStatistics event = null; try { event = objectMapper.readValue((byte[]) payload, UserStatistics.class); } catch (IOException e) { log.error(e.getMessage()); fail(); }
Размещение приложений
Приложение Spring Cloud Stream может быть запущено множеством способов. И если потоковые компоненты представляют собой часть web-приложения, то для работы потокового приложения будет достаточно наличия в зависимостях spring-boot-starter-web. Собственно, любой другой вариант запуска в составе постоянно запущенных сервисов также пригоден. Отдельный разговор касается способов размещения потокового приложения в облачной инфраструктуре. И здесь это зависит от конкретной реализации конкретного облачного провайдера.
Подробнее см. по ссылке.
Следует напомнить и про упомянутый ранее Spring Cloud Data Flow, который является одним из специализированных средств для управления приложениями для потоковой и пакетной обработки данных.
Ввиду многообразия вариантов на этом остановимся лишь вскользь.
После того, как рассмотрели отдельные элементы Spring Cloud, приведём полный исходный код работающего приложения. Приложение занимается тем, что читает структуры UserInfo с полями «имя» и «страна» из очереди сообщений и определяет, сколько уникальных стран встретилось за последние 10 секунд. Информация выдаётся в виде структуры UserStatistics в выходную очередь.
Структура Spring-приложения выглядит следующим образом:
. ├── build.gradle ├── settings.gradle └── src ├── main │ ├── java │ │ └── ru │ │ └── bmstu │ │ └── iu6 │ │ └── streams │ │ └── reactor │ │ ├── DataConsumer.java │ │ ├── DataGenerator.java │ │ ├── DataProcessor.java │ │ ├── SimpleStreamApp.java │ │ └── models │ │ ├── UserInfo.java │ │ └── UserStatistics.java │ └── resources │ ├── application.yml │ └── logback.xml └── test ├── generated_tests ├── java │ └── ru │ └── bmstu │ └── iu6 │ └── streams │ └── reactor │ ├── AbstractTest.java │ └── SimpleStreamAppTest.java └── resources
plugins { id 'org.springframework.boot' version '2.7.2' id 'io.spring.dependency-management' version '1.0.12.RELEASE' id 'java' id "io.freefair.lombok" version "6.5.0.3" } repositories { mavenCentral() } group = 'ru.bmstu.iu6.streams.reactor' version = '0.0.2-SNAPSHOT' //sourceCompatibility = '17' ext { set('springCloudVersion', "2021.0.3") } dependencies { implementation 'org.springframework.boot:spring-boot-starter-web' implementation 'org.springframework.boot:spring-boot-starter-amqp' implementation 'org.springframework.cloud:spring-cloud-stream' implementation 'org.springframework.cloud:spring-cloud-stream-binder-rabbit' implementation 'ch.qos.logback:logback-classic:1.2.11' implementation 'ch.qos.logback:logback-core:1.2.11' testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } testImplementation 'org.springframework.cloud:spring-cloud-stream:3.2.4:test-binder' implementation("com.github.javafaker:javafaker:1.0.2") { exclude group: 'org.yaml', module: 'snakeyaml' } } test { useJUnitPlatform() } dependencyManagement { imports { mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}" } }
rootProject.name = 'reactor'
package ru.bmstu.iu6.streams.reactor; import org.springframework.boot.Banner; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class SimpleStreamApp { public static void main(String[] args) { SpringApplication app = new SpringApplication(SimpleStreamApp.class); app.setBannerMode(Banner.Mode.OFF); app.run(args); } }
package ru.bmstu.iu6.streams.reactor.models; import lombok.AllArgsConstructor; import lombok.Builder; import lombok.Data; import java.time.Instant; import java.util.Date; @Data @AllArgsConstructor @Builder public class UserInfo { @Builder.Default private Date time = Date.from(Instant.now()); private String name; private String country; }
package ru.bmstu.iu6.streams.reactor.models; import lombok.AllArgsConstructor; import lombok.Builder; import lombok.Data; import lombok.NoArgsConstructor; import java.time.Instant; import java.util.Date; @Data @NoArgsConstructor @AllArgsConstructor @Builder public class UserStatistics { @Builder.Default private Date time = Date.from(Instant.now()); private Long nameCounter; private Long countryCounter; }
package ru.bmstu.iu6.streams.reactor; import org.springframework.context.annotation.Bean; import org.springframework.stereotype.Component; import reactor.core.publisher.Flux; import reactor.core.publisher.Sinks; import ru.bmstu.iu6.streams.reactor.models.UserInfo; import java.util.concurrent.locks.LockSupport; import java.util.function.Supplier; @Component @SuppressWarnings("unused") public class DataGenerator { private final Sinks.Many<UserInfo> sink = Sinks.many().multicast().onBackpressureBuffer(); @Bean public Supplier<Flux<UserInfo>> userInfoGenerator() { return sink::asFlux; } /** * This method emits exact one event by a user data * As we are using Flux, we don't need to additionally wrap the user data by * a Message object. * * @param data the data to be emit */ public void emitData(UserInfo data) { while (sink.tryEmitNext(data).isFailure()) { LockSupport.parkNanos(100); } } }
package ru.bmstu.iu6.streams.reactor; import org.springframework.context.annotation.Bean; import org.springframework.stereotype.Component; import reactor.core.publisher.Flux; import ru.bmstu.iu6.streams.reactor.models.UserInfo; import ru.bmstu.iu6.streams.reactor.models.UserStatistics; import java.time.Duration; import java.util.function.Function; @Component @SuppressWarnings("unused") public class DataProcessor { private static final int COLLECTION_TIME_SECONDS = 10; @Bean public Function<Flux<UserInfo>, Flux<UserStatistics>> flDataProcess() { return this::process; } public Flux<UserStatistics> process(Flux<UserInfo> userInfos) { final Flux<Flux<UserInfo>> window = userInfos .map(event -> { event.setName(event.getName().toLowerCase()); event.setCountry(event.getCountry().toLowerCase()); return event; }) .window(Duration.ofSeconds(COLLECTION_TIME_SECONDS)); return window.flatMap(win -> win .groupBy(UserInfo::getName) .count() .map(count -> UserStatistics.builder() .nameCounter(count) .build()) .flux() ); } }
package ru.bmstu.iu6.streams.reactor; import lombok.extern.slf4j.Slf4j; import org.springframework.context.annotation.Bean; import org.springframework.stereotype.Component; import reactor.core.publisher.Flux; import ru.bmstu.iu6.streams.reactor.models.UserStatistics; import java.time.Duration; import java.util.List; import java.util.function.Consumer; @Component @Slf4j @SuppressWarnings("unused") public class DataConsumer { private static final int COLLECTION_TIME_SECONDS = 10; @Bean public Consumer<Flux<UserStatistics>> flDataConsumer() { return flux -> flux .buffer(Duration.ofSeconds(COLLECTION_TIME_SECONDS)) .subscribe(this::handle); } private void handle(List<UserStatistics> userInfos) { log.info(userInfos.toString()); } }
spring: application: name: "Streaming app based on Flux sample" logging: level: root: INFO ru.bmstu.iu6: DEBUG --- spring: config: activate: on-profile: dev,production cloud: stream: function: definition: "\ userInfoGenerator;\ flDataProcess;\ flDataConsumer;\ " bindingServiceProperties: defaultBinder: local_rabbit bindings: userInfoGenerator-out-0: destination: fl.user_info flDataProcess-in-0: destination: fl.user_info group: combiner flDataProcess-out-0: destination: fl.user_statistics flDataConsumer-in-0: destination: fl.user_statistics group: presenter # binders: # local_rabbit: # type: rabbit # environment: rabbitmq: host: localhost port: 5672 username: guest password: guest virtual-host: /
package ru.bmstu.iu6.streams.reactor; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.cloud.stream.binder.test.TestChannelBinderConfiguration; import org.springframework.context.annotation.Import; import org.springframework.test.context.ActiveProfiles; @SpringBootTest( classes = SimpleStreamApp.class ) @Import(TestChannelBinderConfiguration.class) @ActiveProfiles("test") public class AbstractTest { }
package ru.bmstu.iu6.streams.reactor; import com.fasterxml.jackson.databind.ObjectMapper; import com.github.javafaker.Faker; import lombok.extern.slf4j.Slf4j; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.function.context.FunctionCatalog; import org.springframework.cloud.function.context.catalog.SimpleFunctionRegistry; import org.springframework.cloud.stream.binder.test.OutputDestination; import org.springframework.messaging.Message; import org.springframework.test.context.TestPropertySource; import reactor.core.publisher.Flux; import ru.bmstu.iu6.streams.reactor.models.UserInfo; import ru.bmstu.iu6.streams.reactor.models.UserStatistics; import java.io.IOException; import java.util.ArrayList; import java.util.List; import static org.junit.jupiter.api.Assertions.*; @Slf4j @TestPropertySource( properties = { "spring.cloud.function.definition = " + "userInfoGenerator|flDataProcess;" } ) @SuppressWarnings("unused") class SimpleStreamAppTest extends AbstractTest { final private static Long WAITING_TIMEOUT_MILLIS = 10000L; private final Faker faker = new Faker(); private final ObjectMapper objectMapper = new ObjectMapper(); @Autowired private OutputDestination outputDestination; @Autowired private FunctionCatalog catalog; @Autowired private DataGenerator dataGenerator; @Autowired private DataProcessor dataProcessor; /** * Test with channels based on spring.cloud.function.definition */ @Test void testGeneratorAndProcessor() { List<UserInfo> sampleData = new ArrayList<>(); UserInfo userInfo = generateFakeUser(); sampleData.add(userInfo); sampleData.add(userInfo); sampleData.forEach(dataGenerator::emitData); final Message<?> message = outputDestination.receive(WAITING_TIMEOUT_MILLIS, "userInfoGeneratorflDataProcess-out-0"); assertNotNull(message, "processing timeout"); final Object payload = message.getPayload(); assertTrue(payload instanceof byte[]); UserStatistics event = null; try { event = objectMapper.readValue((byte[]) payload, UserStatistics.class); } catch (IOException e) { log.error(e.getMessage()); fail(); } assertSame(1L, event.getNameCounter()); } /** * Test with the catalog lookup */ @Test void testProcessorWithCatalog() { SimpleFunctionRegistry.FunctionInvocationWrapper func = catalog.lookup("flDataProcess"); assertNotNull(func); UserInfo userInfo = generateFakeUser(); Object result = func.apply(Flux.just( userInfo, userInfo, userInfo )); assertTrue(result instanceof Flux<?>); Object message = ((Flux<?>) result).blockFirst(); assertTrue(message instanceof Message<?>); Object payload = ((Message<?>) message).getPayload(); assertTrue(payload instanceof byte[]); UserStatistics userStatistics = null; try { userStatistics = objectMapper.readValue((byte[]) payload, UserStatistics.class); } catch (IOException e) { log.error(e.getMessage()); fail(); } assertEquals(1, userStatistics.getNameCounter()); } private UserInfo generateFakeUser() { return UserInfo.builder() .name(faker.name().firstName()) .country(faker.country().name()) .build(); } }
Заключение
Мы рассмотрели основные компоненты Spring для создания потоковых приложений. В ряде случаев этого достаточно, чтобы не использовать специализированные потоковые фреймворки типа Apache Beam или Apache Flink и иметь легковесные приложения для обработки потоков сообщений.
Отметим, что компоненты Spring Cloud Function/Stream/Data Flow активно развиваются, поэтому упомянутые в статье области применения, методы использования и тестирования разработанных программ являются лишь частными примерами. Учитывая вводный характер статьи, подробности применения могут быть найдены в документации и многочисленных статьях, касающихся Spring Cloud. Не следует забывать и о доступных официальных примерах, которые также обновляются по мере развития технологий.
Полезные ссылки
- https://github.com/reactor/reactor-core
- https://spring.io/projects/spring-cloud-function
- https://github.com/spring-cloud/spring-cloud-stream-samples
- https://spring.io/projects/spring-cloud-function
- https://cloud.spring.io/spring-cloud-function/reference/html/spring-cloud-function.html#_deploying_a_packaged_function
- https://spring.io/blog/2020/07/20/introducing-java-functions-for-spring-cloud-stream-applications-part-1
- https://spring.io/blog/2020/12/10/cloud-events-and-spring-part-1
- https://spring.io/blog/2020/12/23/cloud-events-and-spring-part-2
Об авторе:
Самарев Роман Станиславович
доцент каф. Компьютерные системы и сети
МГТУ им. Н. Э. Баумана


