

Команда VK Cloud уже переводила статью о том, как развернуть локальный стек данных с помощью инструмента Everything Bagel. Теперь переводим вторую часть, в которой на практике разбираем, как выполнять запросы к разветвленным данным lakeFS через механизм распределенных запросов Trino.
Переводим пайплайн на рельсы Docker
Я еще помню времена, когда моя компания переходила на новые технологии: Redis, Kafka, Spark, — и, чтобы разобраться в них, я вчитывался в эти надписи на экране:
Страницы загрузки популярных ИТ-решений
В то время я об этом даже не задумывался. Более того, я гордился тем, что способен разобраться, как самостоятельно установить и запустить современные ИТ-решения.
И хотя это ценный навык, с точки зрения компании такая локальная установка, вручную выполняемая каждым разработчиком по отдельности, — фантастическая трата времени впустую и, как следствие, снижение производительности.
Особенно когда возникает неразбериха с такими мелкими деталями, как версия релиза и зависимости. Как отследить, не свернули ли вы с верной дороги? К примеру, если вы отправляете коллеге файл .jar по Slack, считайте, что вы пробили дно.
Цивилизованный способ организовать локальные установки
Один из подходов к решению этой проблемы — стандартизировать и упростить процесс локальной установки. В предыдущей статье я рассказывал, как это работает с Docker Everything Bagel.
В двух словах: Everything Bagel — это среда Docker Compose, в которой можно с помощью одной команды использовать разные технологии для работы с Big Data: MinIO, lakeFS, Hive, Spark и Trino. Используя реализованные в Bagel концепции Docker, можно выполнить локальную репликацию почти любого пайплайна данных.
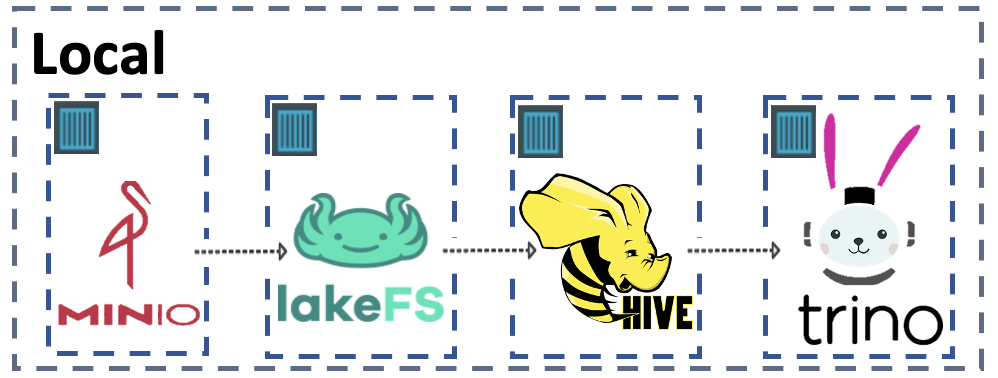
Схема публичной среды lakeS Docker Compose
В этой статье я хотел бы показать все это в действии. Следуя замечательному примеру Брайана Ольсена из Starburst, мы покажем, как с помощью Trino делать запросы к данным в разных ветвлениях lakeFS.
Подключение к Trino Container с помощью Database Manager
В предыдущей статье мы успели перейти к контейнеру Trino и запустить несколько команд запросов, чтобы показать, как он работает. Правда, однако, заключается в том, что никто не хочет выполнять запросы из командной строки.
Первым делом давайте подключим клиент SQL к контейнеру Trino. Как и Брайан, я буду использовать бесплатный инструмент DBeaver. Сначала в раскрывающемся меню Database выбираем New Database Connection. На этом экране Trino находится в разделе Hadoop/BigData:
Выбрав зайчика-космонавта Trino, введите подробную информацию о подключении:
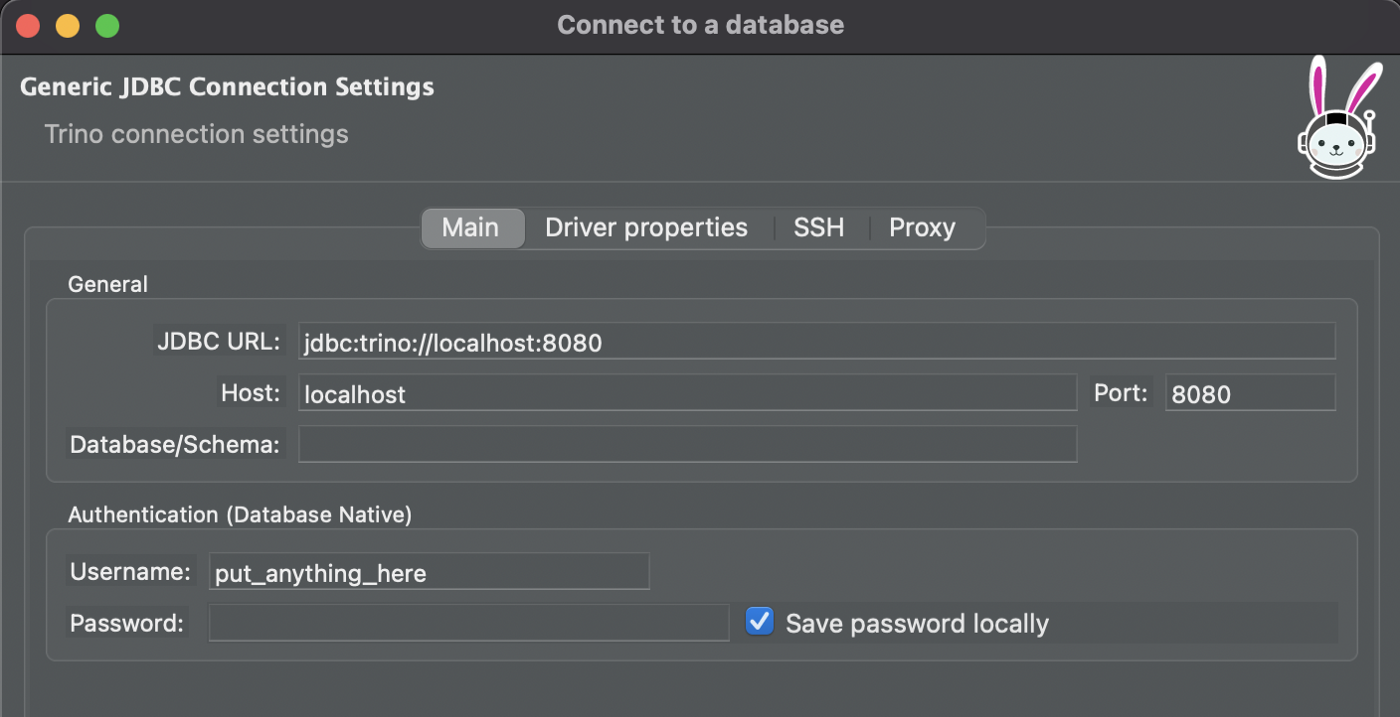
Согласно документации Trino, JDBC URL примет такой вид:
jdbc:trino://{host}:{port}
Чтобы локально запустить Trino в Docker, выполните
host = localhost, а также предоставьте этому контейнеру любой порт (Bagel использует 8080).Положившись на метод проб и ошибок, я вычислил, что для
Username подойдет любая строка, а поле Password нужно оставить пустым. Теперь можно подключиться!Можно также подключиться к UI lakeFS и MinIO. В браузере перейдите в localhost:9001 для UI MinIO (username и password = minioadmin) и в localhost:8000 для UI lakeFS (в Docker Compose учетные данные скрыты в переменных среды lakeFS-setup).Trino + lakeFS
После подключения можно определить таблицы в Hive в главной ветви репозитория lakeFS и выполнить запросы к ним через механизм распределенных запросов Trino. Давайте посмотрим, как это сделать.
Шаг 1. Создать схему. В результате появляется отдельное пространство имен для новых таблиц. Давайте укажем местоположение основной ветви lakeFS.
create schema s3.tiny with (location = 's3a://example/main/tiny');
Шаг 2. Создать таблицы в схеме. Реплицируем таблицы заказчиков и заказов.
create table s3.tiny.customer with ( format = 'ORC', external_location = 's3a://example/main/tiny/customer' ) as select * from tpch.tiny.customer;create table s3.tiny.orders with ( format = 'ORC', external_location = 's3a://example/main/tiny/orders' ) as select * from tpch.tiny.orders;
Шаг 3. Писать запросы! Вот пример соединения обеих таблиц для заказов до марта 1995-го.
select orderkey, orderdate, shippriority from s3.tiny.customer c, s3.tiny.orders o where c.custkey = o.custkey and orderdate < date'1995-03-15' group by orderkey, orderdate, shippriority order by orderdate;
Что происходит, когда я создаю новую ветвь
Конечно, прикольно делать такие запросы к данным, и все же это пустопорожняя трата потенциала Everything Bagel. Вместо просто одной версии данных давайте используем ветвь lakeFS, чтобы создать новую версию.
Сначала создадим новую ветвь в lakeFS. Назовем ее
v2.
Создание новой ветви на вкладке Branches взятого для примера репозитория
Прежде чем выполнить запрос к версии таблиц v2, нужно переопределить схему, указав новое местоположение в S3. Как видно ниже, для этого нужно просто заменить main на v2 в пути расположения.
create schema s3.tiny_v2 with (location = 's3a://example/v2/tiny');
Наконец, нужно переопределить таблицы в новой схеме. Для этого можно запустить
show create table s3.tiny.orders; в созданной ранее таблице, а потом скопировать сгенерированный DDL таблицы, заменив имя ветви.Вот как это выглядит:
CREATE TABLE s3.tiny_v2.orders ( orderkey bigint, custkey bigint, orderstatus varchar(1), totalprice double, orderdate date, orderpriority varchar(15), clerk varchar(15), shippriority integer, comment varchar(79) ) WITH ( external_location = 's3a://example/main/tiny_v2/orders', format = 'ORC' );
Теперь у нас совершенно независимая версия таблицы, в которую мы можем вносить любые изменения, не влияя на версию в главной ветви и не дублируя никакие данные.
Для чего это может понадобиться
Подумайте, какие таблицы с данными представляют собой активы, чаще всего используемые в вашей компании. Во время использования они ведь никак не менялись, да? Или не совсем так? Конечно же, в них все время вносят изменения. Обновляются определения метрик, добавляются столбцы и т. п.
Учитывая зависимости между таблицами, развертывание всех этих изменений, причем так, чтобы потребители данных не пострадали в результате несчастного случая, — это деликатный и продолжительный процесс.
Переход на рабочий процесс на базе ветвления упрощает деплойменты, поскольку обе версии таблицы могут существовать бок о бок без ненужного дублирования данных (важно для больших таблиц). Кроме того, для управления жизненным циклом в вашем распоряжении есть команды git, используемые lakeFS.
В заключение
Когда в следующий раз вы соберетесь вносить изменения, остановитесь на минуточку. Не поддавайтесь соблазну скопировать данные. Вместо этого адаптируйте рабочий процесс, используемый для кода, и создайте новую ветвь данных.
Эффект будет тот же, но при этом вы получите преимущества контроля над источником, которые не добудешь иным способом.
Попробуйте Kubernetes as a Service на платформе VK Cloud. Мы даем новым пользователям 3000 бонусных рублей на тестирование кластера или любых других сервисов.
Что еще почитать:
