Зачастую, приложение, у которого происходит существенный рост пользователей оказывается не готово к этому. Требования к быстродействию и доступности растут, а инфраструктура и архитектура приложения не позволяют их обеспечить.
Стоявшая передо мной задача: улучшить инфраструктуру и качество работы приложения, успевшего вырасти из MVP и стенда для одного клиента в популярный SaaS. Отсутствие отказоустойчивости и масштабируемости компонентов сервиса начало ощутимо мешать пользователям. Настала пора адаптировать приложение под кластерный режим.
Приложение работало в контейнерах, а оркестрация осуществлялась с помощью Docker Compose. Компоненты приложения не задумывались готовыми к запуску в кластерном режиме, что, разумеется, нормальная ситуация для раннего этапа многих проектов: бизнес требует быстрой доставки новых функций, и на преждевременную оптимизацию не всегда можно и нужно тратить время. Но в какой-то момент именно стабильность и быстродействие становятся самыми важными функциями.
Каково мигрировать приложение с уже сформированным техническим стеком и базой пользователей? Какие есть варианты решения, подводные камни? Как оценить есть ли смысл в таких трудозатратах? В этой статье я поделюсь своим опытом переноса приложения из Docker Compose в Kubernetes.
Что из себя представляет приложение
Для начала расскажу про само приложение. Picvario – это корпоративная платформа, позволяющая систематизировать хранение, поиск и совместное использование цифровых активов: изображений, аудио, видео, тестов, таблиц и файлов других форматов. Изначально Picvario это DAM, но сейчас приложение целится в более широкий рынок CSP-систем.
Технические особенности приложения:
Мультитенантая архитектура с Django в качестве бэкенда. Клиенты приложения используют один и тот же бэкенд и базу данных, но изолированы друг от друга в разных схемах БД.
SSR Frontend на Nuxt.js
Много асинхронных, фоновых задач на Celery, со своими очередями и приоритетами. Это и загрузка и обработка медиа активов, и сканирование внешних хранилищ, экспорт, распознавание лиц и т.д.
Nginx, отвечающий за роутинг трафика до компонентов, раздачу статики и процесс загрузки файлов из S3 с помощью механизма X-Accel
Elasticsearch для полнотекстового поиска
Визуализация статистики в Grafana. Администратор тенанта может просмотреть подробный отчет по своему окружению, а администратор приложения - суммарную информацию по всем тенантам. Эти данные хранятся в отдельном Elasticsearch, и отправляются туда через Logstash.
Большое количество медиаданных. Десятки терабайт с возможностью роста до нескольких сотен в течение пары лет
Плавающая нагрузка по импорту медиаданных
Как инфраструктура выглядела ранее и почему ее нужно было менять
Все компоненты приложения были запущены на одной виртуальной машине с помощью Docker Compose, всего около 24 контейнеров. PostgreSQL и Elasticsearch уже были вынесены в отдельные инстансы, хранение медиа активов было перенесено в S3-бакет.
Такой подход, безусловно, имел кучу недостатков, несмотря на дешевизну и простоту использования.
Например:
Отсутствие отказоустойчивости. Приостановка работы виртуальной машины или незначительные сетевые сбои приводили к падению сервиса.
Производительность. Эффективнее распределить процессы по нескольким инстансам, чем запускать их на одном, пусть и с приличным запасом ресурсов.
Сбой одного компонента, например утечка памяти или высокая загрузка CPU, влияет на другие. Падение одного воркера можно пережить, но целиком лежащий или лагающий фронтенд и бэкенд - проблема более неприятная.
Нет автомасштабируемости. Запуск в Docker Compose не подразумевает ни скейлинга контейнеров, ни скейлинга инстансов. В ситуациях, когда пользователи одновременно создавали большую нагрузку на приложение, происходило сильное падение быстродействия. Подробнее про это расскажу в разделе про масштабируемость.
В первую очередь мне предстояло выбрать решение, которое позволило бы оркестрировать контейнеры между несколькими хостами, с поддержкой автоматического масштабирования.
Выбор платформы. Почему Kubernetes
Для меня главным кандидатом на рассмотрение стал Kubernetes, по сути текущий стандарт для оркестрации контейнеров. Как ни крути, это самая функциональная и развивающаяся платформа, которая точно обеспечила бы все наши текущие и будущие потребности. Из очевидных минусов - более высокая сложность настройки и эксплуатации, по сравнению с другими возможными инструментами. Но так как ранее я уже приобрел опыт и навыки работы с Kubernetes на другом проекте, меня это не пугало. Скорее наоборот, было интересно углубить и развить свои знания по K8s, решая задачу миграции.
В команде звучали сомнения в выборе Kubernetes. Решение может быть избыточным для наших нужд, лучше обойтись более простыми и менее затратными инструментами. Например, Ansible, с помощью которого выполнялась бы оркестрация контейнеров по нескольким хостам, трафик между которыми распределялся бы балансировщиком. Отсутствие механизма автоскейлинга заменили бы тем, чтобы с запасом запускать экземпляры воркеров, на которые приходится больше всего нагрузки. На мой взгляд, такое решение, конечно, закрыло бы некоторые проблемные моменты, но лишь на время: это компромисс, который в будущем снова потребует замены. В таблице ниже мое видение некоторых преимуществ и недостатков разных инструментов.
Инструмент | Плюсы | Минусы |
Kubernetes | - Огромный функционал. Растущая экосистема из open-source решений. - Удобство оркестрации и ее гибкость - Возможность автомасштабирования компонентов. - Почти у каждого облачного провайдера есть Kubernetes как managed сервис. (об их преимуществах я пишу в части про развертывание K8s) - Комьюнити. Большое количество статей, конференций, тредов и готовых решений на любой случай жизни. | - Выше затраты на инфраструктуру. Нужно платить за мастер ноды Kubernetes, и выделять ресурсы для системных компонентов на воркер нодах. - Сложнее в настройке и поддержке. (особенно если администрирование мастера не на плечах облака) - Команду разработки необходимо обучать работе с Kubernetes. |
Ansible (использование стандартного модуля Docker) | - Меньше затрат на инфраструктуру. - Миграция из Docker Compose проще. По-прежнему работаем с Docker, меняется только способ его оркестрации. - Администрирование инфраструктуры не усложняется. Инженеру нужно уметь работать с Docker и Ansible. | - Функционал ограничен возможностями Docker и сильно отстает от тех возможностей, которые предоставляют полноценные инструменты для оркестрации. - Не решается вопрос горизонтального автомасштабирования. |
Docker Swarm | - Проще чем Kubernetes - По сравнению с вариантом №2 имеет больше возможностей и лучше подходит для прода | - Компромиссный вариант по сравнению с Kubernetes, меньше функционал и меньше гибкость настройки - Потребуется время на освоение, хоть и считается простым - Нет горизонтального автомасштабирования - Проект недостаточно популярен, чтобы мы были уверены в том, что его не закроют в обозримом будущем |
Для нас Kubernetes оказался предпочтительным вариантом, подходящим под текущие требования и перспективы развития приложения. То, что в используемом нами облаке есть Kubernetes как managed service, еще один плюс к выбору именно этого оркестратора.
Однако у каждого из этих вариантов есть сфера применения, неправильно считать, что Kubernetes — единственный верный путь. Чаще всего можно обойтись более простыми инструментами, особенно на ранних этапах жизни приложения.
Изменения в архитектуре приложения
Прежде чем углубиться в детали Kubernetes и запуск сервиса в нем, я бы хотел рассказать про изменения, которые были сделаны в коде самого Picvario. Для того, чтобы приложение корректно работало в новых реалиях, вместе с командой разработки была пересмотрена логика работы с файлами, а также внесены некоторые другие изменения.
На схеме изображено, как именно в приложении была устроена работа с загрузкой и обработкой файлов.
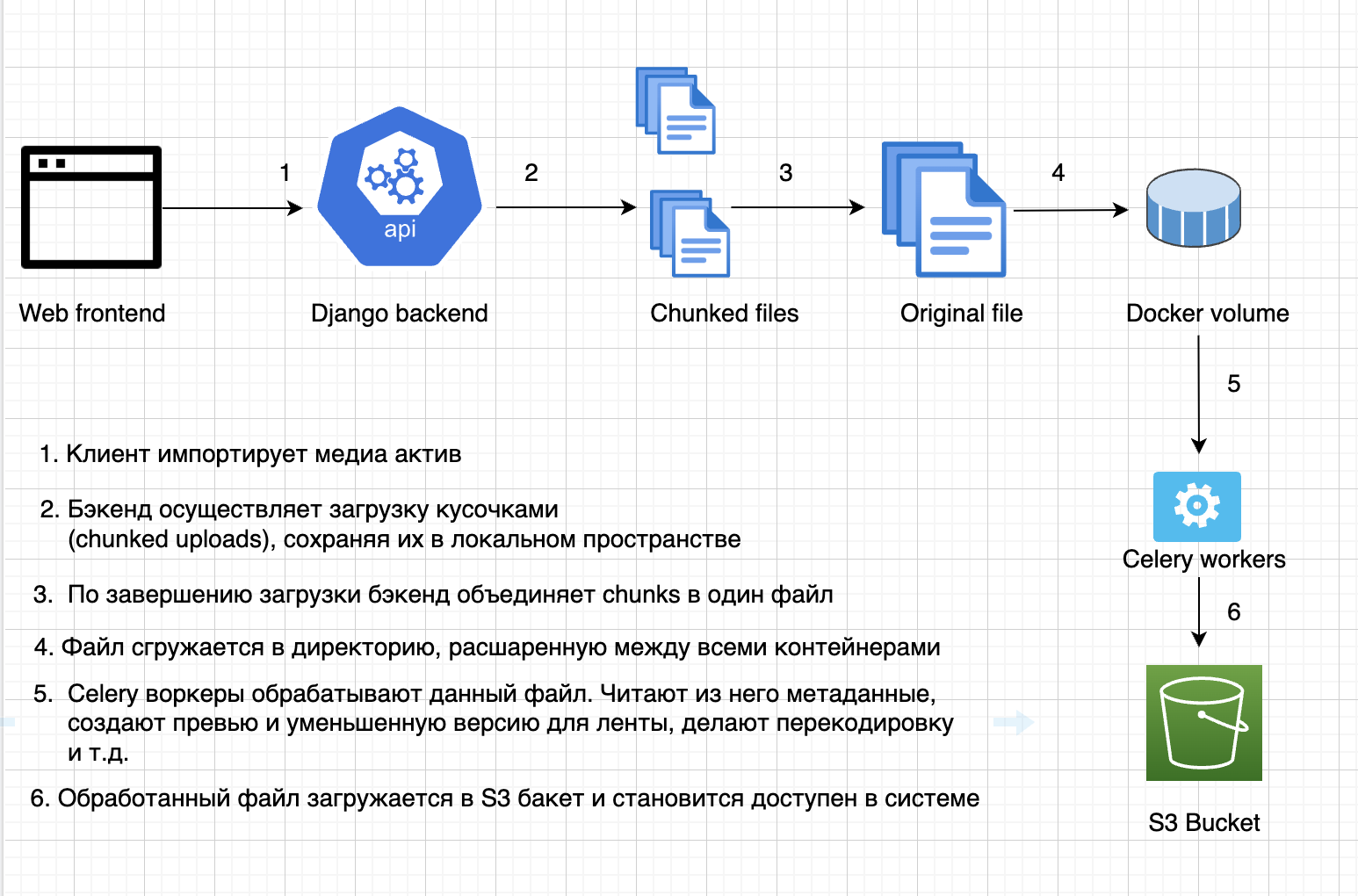
С миграцией в Kubernetes возникли следующие проблемы:
Как обеспечить Celery воркерам доступ к оригиналу файла, если он запущен не на одной ноде с бэкендом?
Как быть с объединением загружаемого файла (шаг №2 и №3 на схеме), если теперь у бэкенда несколько реплик и все части файла находятся в разных подах?
Самым очевидным решением было, как и ранее, обеспечить расшаренное дисковое пространство между контейнерами. Я почитал про Persistent Volumes в Kubernetes и попробовал настроить его и подключить к подам. На практике результат вышел несколько иной, чем я ожидал – вместо одного PV было создано по отдельному на каждый pod. Разбираясь с этим, я узнал про параметр Access Modes, дефолтное значение которого “ReadWriteOnce”, позволяет подключить volume только к одной ноде. Мне же был нужен “ReadWriteMany”-volume, с возможностью подключения к нескольким нодам с опцией чтения и записи. Как оказалось, возможность создать volume с таким access mode не поддерживается в Yandex Cloud. На этом варианты не закончились – можно было развернуть и настроить собственный NFS кластер и смонтировать его к подам.
В итоге обсудив с командой разработки мы решили пойти другим путем и использовать для решения проблемы S3 бакет:
Оригинал файла загружается бэкендом в S3 хранилище, после чего его скачивают оттуда Celery воркеры
Вместо того, чтобы объединять части файла локально, мы используем составную загрузку (multipart upload) в S3. Каждый pod бэкенда сразу загружает свой кусочек в S3 бакет, на стороне которого и происходит объединение в единый файл.
Так был решен вопрос с функционалом загрузки и обработки активов. Но на этом правки не закончились. Вот еще нюансы, которые были решены при миграции тестового окружения в Kubernetes:
У нас много фоновых задач, выполняемых Celery воркерами. Ранее они работали в максимально статичной среде – на хосте доступном 24/7, где работа контейнеров прерывалась только при плановых деплоях. В новых условиях цикл жизни контейнера стал плавающим. Он переезжает с хоста на хост, удаляется при скейлинге, останавливается при превышении лимитов и т.д. Мы столкнулись с тем, что некоторые таски стали теряться – выполняющий задачу воркер прерывал работу в отсутствие механизма, который позволил бы другому экземпляру подхватить задачу. Решением стало изменение параметра Celery acks_late. По умолчанию, задачи удаляются из очереди брокера непосредственно перед запуском. После изменения это происходит после завершения выполнения задачи. Если воркер завершает работу, не выполнив задачу, ее подхватит другой воркер. Так как задачи идемпотенты, их повторное выполнение не приводит к проблемам.
Статические файлы Django хранились в локальном хранилище, а их отдача осуществлялась через Nginx. Перенесли хранение в S3 бакет, изменив параметры STATIC_URL и STATICFILES_STORAGE в settings.py Django. Подробно про перенос статики в S3 можно прочитать в статье Storing Django Static and Media Files on Amazon S3
Отсутствовал механизм самопроверки состояния компонентов. Нужно было сделать так, чтобы трафик не шел на экземпляры контейнеров, которые еще не инициализировались после создания, либо вышли из строя. Для этого разработчик добавил health-чеки для компонентов, а я настроил Readiness- и Liveness-пробы для подов, осуществляющие проверки готовности и работоспособности контейнера по ним.
В результате доработок и изменений компоненты приложения стали полностью готовы к запуску и корректной работе в Kubernetes. Далее я расскажу про нюансы подготовки кластера и запуска в нем приложения.
Запуск Kubernetes кластера
Вся существующая инфраструктура приложения была развернута в Yandex Cloud, тут изменений не планировалось. Настал этап, когда нужно было развернуть Kubernetes кластер. Как я писал ранее, в главе “Выбор платформы”, у каждого крупного облака есть свой managed service для запуска Kubernetes и Yandex Cloud тут не исключение.
Плюсы таких управляемых сервисов заключаются в значительном упрощении работы с инфраструктурой кластера. Ответственность за конфигурацию и работоспособность control plane лежит на облачном провайдере. Я же как инженер могу сфокусироваться непосредственно на деплое и администрировании своего приложения в кластере, настройке системных K8s компонентов (Ingress контроллер, cluster autoscaler и т.п.), настройке воркер узлов, мониторинге и прочем.
Использование таких управляемых сервисов часто оправдывает себя как финансово, так и по качеству работы сервиса. Поэтому однозначным решением было использовать Managed Service for Kubernetes, вместо самостоятельного развертывания и обслуживания собственного кластера.
У меня был опыт работы с Kubernetes в облаке AWS, с сервисом EKS. Несмотря на всю мощь AWS, у сервиса от Yandex есть некоторые преимущества, на которые я обратил внимание:
UI в веб консоли облака обладает неплохим функционалом. Его можно использовать как для визуализации, так и для некоторого управления объектами в кластере. В EKS веб интерфейс менее информативен и полезен, лучше ставить стороннее решение.
При желании можно включить полностью автоматические обновления версии Kubernetes по расписанию. В EKS обновлениями занимается сам пользователь.
В Kubernetes от Yandex предустановлены такие must-have системные компоненты как metric server и cluster autoscaler, их обновления и конфигурация в зоне ответственности облака.

А вот чего мне не хватило в Yandex Cloud:
Сервис для хранения секретов. В AWS EKS для менеджмента секретов можно использовать сервис Secret Manager. Это удобно и избавляет от необходимости развертывать сторонние решения вроде Hashicorp Vault. Позже, когда я уже писал эту статью, у Яндекса появился такой сервис - Yandex Lockbox, но он пока в статусе Preview.
А этот пункт на момент публикации статьи уже неактуален. В Yandex Cloud был только Network LB, и не было Application Load Balancer, поэтому вопрос терминирования TLS трафика нужно было решать на стороне кластера. Для этого я установил распространенную связку – Nginx Ingress и Certmanager. В AWS EKS у меня не было в них необходимости, так как за балансировку HTTP трафика отвечал cloud сервис ALB, а за сертификаты ACM. Но позже в Yandex Cloud появился Application Load Balancer и его можно использовать с Kubernetes через соответствующий Ingress контроллер.
Несмотря на особенности и отличия, managed сервисы для Kubernetes от разных cloud провайдеров одинаково хорошо подходят для решения поставленной задачи. Если выбор надо сделать с нуля, я бы выбирал подходящее облако в целом, а не по критериям одного конкретного сервиса.
Я запустил два отдельных кластера, один под тестовое, другой под продакшен окружение. В первом случае это зональный мастер, а во втором региональный, реплицированный в трех зонах доступности. Почему два отдельных кластера, а не один? Во-первых, чтобы обеспечить полную изоляцию разных окружений друг от друга. Во-вторых, где-то нужно тестировать инфраструктурные изменения. Например обкатывать обновления версии Kubernetes, обновления компонентов или изменения API версий для ресурсов. Многие предпочитают не разделять окружения в отдельные кластеры — оба подхода имеют право на жизнь. Однозначного рецепта нет.
Деплой приложения в Kubernetes. Helm шаблонизация
После развертывания Kubernetes кластера и установки системных компонентов пришло время заняться миграцией нашего приложения в него.
На тот момент в docker compose файле был описан запуск примерно 25 контейнеров. Нужно было решить как реализовать запуск компонентов нашего приложения в условиях Kubernetes. Есть несколько вариантов:
Описать всю конфигурацию компонентов в стандартных YAML манифестах. Нужно подготовить отдельные манифесты под каждое окружение, так как их конфигурация будет отличаться. Проблема такого подхода — в огромном количестве создаваемых конфиг файлов и их объемах, что делает дальнейшую работу с ними неудобной.
Использовать такие инструменты, как Kustomize или Helm. Оба решения облегчают работу с K8s объектами. Kustomize позволяет оптимизировать работу, создавая базовые манифесты с общей конфигурацией, и overlay файлы, содержащие параметры, специфичные для конкретного окружения. Helm вместо большого количества yaml манифестов создает набор универсальных темплейтов, в которые подставляются нужные значения.
Я выбрал Helm, потому что он показался мне более удобным. Единственное, потребуется некоторое время, чтобы освоить написание шаблонов. Тут мне помогло изучение исходников популярных публичных Helm чартов.
Теперь расскажу как происходил перенос компонентов из Docker Compose в Helm, для наглядности на примере двух контейнеров. Под катом их конфиг в docker-compose файле.
docker-compose.yaml
backend: env_file: - backend.env command: ["gunicorn", "--chdir", "picvario", "--bind", "0.0.0.0:8000", "--workers", "8", "picvario.config.wsgi"] image: ${DOCKER_REPO:?err}/picvario-wsgi:${BUILD_ID:?err} restart: always beat_worker: command: celery beat -A config.celery -l INFO --workdir /pcvr/picvario/ env_file: - backend.env image: ${DOCKER_REPO:?err}/picvario-wsgi:${BUILD_ID:?err} restart: always
Прелесть Docker Compose в простоте. В конфиг файле мы описываем всего одну сущность под названием service, создание которой породит контейнер. В Kubernetes количество возможных абстракций в разы больше: Pod, Deployment, StatefulSet, DaemonSet, ReplicaSet, Service, Ingress и тд. В какие именно объекты K8s нужно превратить мои контейнеры из docker compose?
Кратко об основных абстракциях:
Pod - группа из одного или нескольких контейнеров. Kubernetes управляет именно подом, а не контейнером напрямую. Pod в свою очередь задает параметры запуска контейнера.
ReplicaSet - обеспечивает запуск заданного количества подов в кластере.
Deployment - контроллер, управляющий состоянием Pod и ReplicaSet. Предоставляет функционал декларативного обновления этих объектов.
StatefulSet - управляет развертыванием набора подов, при этом обеспечивая сохранение состояние каждого. Используется для stateful приложений.
Service - абстракция, обеспечивающая сетевой доступ к подам, как правило внутри кластера
Ingress - объект для управления внешним доступом к сервисам в кластере (как правило HTTP). Ingress берет на себя балансировку трафика, SSL терминирование, маршрутизацию трафика по виртуальным хостам
С назначением абстракций разобрались. Теперь пару слов о самих компонентах приложения. Контейнер backend запускает rest api Django с Gunicorn в качестве WSGI сервера. А в beat-worker работает процесс Celery Beat, выполняющий периодические задачи по расписанию.
Первым делом для каждого из этих компонентов нужно было создать по объекту Deployment. Те в свою очередь инициируют запуск подов, внутри которых работают контейнеры. При этом какие-то параметры у этих двух Deployment будут общими, а какие-то отличаться — тут приходит на помощь шаблонизация. Вместо того, чтобы описывать конфигурацию каждого объекта, можно создать один универсальный шаблон, в который будут подставляться нужные параметры из файлов с переменными. Получается такая структура:
Шаблон с описанием конфигурации ресурса
Файл с переменными values.yaml. Параметры из него подставляются в шаблон
Файлы с переменными values-dev.yaml и values-prod.yaml. Используются для передачи специфичных для конкретного окружения параметров. Переменные из них подставляются в шаблон и переопределяют переменные из values.yaml
Вот так выглядит сам шаблон для Deployment:
deployment.yaml
{{- range $name, $app := .Values.apps }} {{- if $app.deployment_enabled }} apiVersion: apps/v1 kind: Deployment metadata: name: "{{ $name }}" namespace: "{{ $.Release.Namespace }}" labels: app: {{ $name }} app.kubernetes.io/name: {{ $name }} app.kubernetes.io/component: {{ $name }} {{ include "common_labels" $ | indent 4 }} spec: revisionHistoryLimit: 2 replicas: {{ $app.replicaCount }} selector: matchLabels: app: {{ $name }} template: metadata: annotations: {{- range $fmap := $app.files }} checksum/{{ $fmap.name }}: {{ include (print print $.Template.BasePath "/configs/" $fmap.name ".yaml" ) $ | sha256sum }} {{- end }} labels: app: {{ $name }} spec: {{- if $app.topologySpreadConstraints_enabled }} topologySpreadConstraints: - maxSkew: 1 topologyKey: kubernetes.io/hostname whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: {{ $name }} {{- end }} {{- if $app.nodeSelector }} nodeSelector: env: '{{ $app.nodeSelector }}' {{ else }} nodeSelector: env: '{{ $.Values.nodeSelector }}' {{ end }} {{- if $.Values.affinity }} affinity: {{- toYaml $.Values.affinity | nindent 8 -}} {{- end }} terminationGracePeriodSeconds: 300 {{- if $app.files }} volumes: {{- range $fmap := $app.files }} - name: "{{ $.Release.Name }}-{{ $fmap.name }}" configMap: name: "{{ $.Release.Name }}-{{ $fmap.name }}" {{- end }} {{- end }} {{- if $.Values.image.use_auth_secret }} imagePullSecrets: - name: regcred {{- end }} containers: - name: {{ $name }} {{- if and $app.image_tag $app.image_name }} image: "{{ $.Values.image.registry }}/{{ $app.image_name }}:{{ $app.image_tag }}" {{- else if $app.image_name }} image: "{{ $.Values.image.registry }}/{{ $app.image_name }}:{{ $.Values.image.tag }}" {{- else }} image: "{{ $.Values.image.registry }}/{{ $.Values.image.name }}:{{ $.Values.image.tag }}" {{- end }} imagePullPolicy: {{ $.Values.image.pullPolicy }} {{- if $app.lifecycle }} lifecycle: {{- toYaml $app.lifecycle | nindent 12 -}} {{- end }} env: {{- range $commonkey, $commonval := $.Values.env }} - name: "{{$commonkey}}" value: "{{$commonval}}" {{- end }} {{- if $.Values.secrets_env }} {{- range $sname, $skey := $.Values.secrets_env.keys }} - name: "{{ $sname }}" valueFrom: secretKeyRef: key: "{{ $skey }}" name: "{{ $.Values.secrets_env.name }}" {{- end }} {{- end }} {{- range $key, $val := $app.env }} - name: "{{$key}}" value: "{{$val}}" {{- end }} {{- if $app.command }} command: {{- range $app.command }} - {{ . }} {{- end }} {{- end }} {{- if $app.args }} args: {{- range $app.args }} - {{ . }} {{- end }} {{- end }} {{- if $app.files }} volumeMounts: {{- range $fmap := $app.files }} - mountPath: {{ $fmap.path }} name: "{{ $.Release.Name }}-{{ $fmap.name }}" readOnly: true {{- if $fmap.file }} subPath: {{ $fmap.file }} {{- end }} {{- end }} {{- end }} resources: {{- if and $app.resources.cpu_limit $app.resources.memory_limit }} limits: cpu: "{{ $app.resources.cpu_limit }}" memory: "{{ $app.resources.memory_limit }}" {{- end }} requests: cpu: "{{ $app.resources.cpu }}" memory: "{{ $app.resources.memory }}" {{- if $app.livenessProbe }} livenessProbe: {{- toYaml $app.livenessProbe | nindent 12 -}} {{- end -}} {{- if $app.readinessProbe }} readinessProbe: {{- toYaml $app.readinessProbe | nindent 12 -}} {{- end }} --- {{- end }} {{- end }}
Вот values.yaml. В начале файла указываю образ, из которого будут запускаться контейнеры. Затем перечисляю сами деплойменты и некоторые базовые параметры для них
values.yaml
image: registry: cr.yandex/something name: picvario-wsgi tag: latest pullPolicy: Always apps: backend: deployment_enabled: true command: - /bin/bash - -c - gunicorn --chdir picvario --bind 0.0.0.0:8000 --workers 8 --timeout 1200 --graceful-timeout 300 picvario.config.wsgi beat-worker: deployment_enabled: true command: - /bin/bash - -c - celery beat -A config.celery -l INFO --workdir /pcvr/picvario/
Теперь содержимое values-production.yaml
values-production.yaml
nodeSelector: picvario-production apps: backend: replicaCount: 2 topologySpreadConstraints_enabled: true resources: memory: 4G memory_limit: 4G cpu: 500m cpu_limit: 500m beat-worker: replicaCount: 1 resources: memory: 1G memory_limit: 2G cpu: 200m cpu_limit: 200m env: PRODUCTION_DEBUG_ENABLED: False HAYSTACK_URL: http://something:9200/ DEFAULT_LANG: ru DJANGO_SETTINGS_MODULE: config.settings.prod
Получилось емкое описание развертывания. Я могу добавить сюда еще десяток других компонентов, шаблон при этом останется тот же. В результате создания получилось два объекта Deployment - backend и beat-worker. Они имеют общие базовые настройки, но отличаются командой, параметрами resources и количеством запускаемых реплик. Еще для backend включена опция topologySpreadConstraints_enabled: true, распределяющая реплики по разным зонам доступности. Благодаря использованию в шаблоне механизма if-else условий этот функционал включился только у backend, а деплоймент beat-worker создался без этих параметров.
Итак, контейнеры запущены. Теперь нужно обеспечить сетевую доступность внутри кластера для подов backend, чтобы другие компоненты могли обращаться к ним. Как я писал выше, за это отвечает абстракция Service. При этом для beat-worker в этом не было необходимости, входящие соединения ему не нужны.
Создал шаблон для Service
service.yaml
{{- range $name, $app := .Values.apps }} {{ if and $app.service.enabled -}} apiVersion: v1 kind: Service metadata: name: "{{ $name }}" namespace: "{{ $.Release.Namespace }}" labels: app: {{ $name }} app.kubernetes.io/name: {{ $name }} app.kubernetes.io/component: {{ $name }} {{ include "common_labels" $ | indent 4 }} spec: ports: {{- range $key, $val := $app.service.ports }} - {{- range $pkey, $pval := $val }} {{ $pkey}}: {{ $pval }} {{- end }} {{- end }} selector: app: "{{ $name }}" --- {{- end }} {{- end }}
Добавил опцию service.enabled, а также указал порт по которому доступно приложение
values.yaml
apps: backend: deployment_enabled: true command: - /bin/bash - -c - gunicorn --chdir picvario --bind 0.0.0.0:8000 --workers 8 --timeout 1200 --graceful-timeout 300 picvario.config.wsgi service: enabled: true ports: - name: http targetPort: 8000 port: 8000
Так контейнер backend из Docker Compose в реалиях Kubernetes превратился в объекты Deployment и Service, а контейнер beat worker только в Deployment. По аналогии я развернул остальные контейнеры приложения. Получилось три отдельных Helm чарта для разных компонентов приложения - backend, frontend, nginx-proxy (про него дальше) с одинаковыми темплейтами.
Обеспечение внешнего доступа. Ingress
Дальше нужно было настроить внешний доступ к приложению по HTTPS, к его фронтенд и бэкенд части. Исторически у нас это работало через схему с двумя Nginx. Первый отвечал за SSL терминирование и обработку запросов извне и проксировал их на второй Nginx, запущенный в виде docker контейнера. Тот, в свою очередь, маршрутизировал трафик между компонентами приложения, занимался раздачей статических файлов, проксировал обращения к S3, выполнял манипуляции с заголовками и редиректы. В новой инфраструктуре мы не стали уходить от этой схемы. В рамках отдельного Helm чарта я так же создал для этого контейнера Deployment и Service. Однако, нужно было решить вопрос с тем, чтобы до него доходил внешний трафик от пользователей. Для этого нужен Ingress.
В Kubernetes есть два типа Ingress сущностей. Ресурс Ingress содержит набор правил маршрутизации трафика до сервисов внутри кластера. Контроллер Ingress запускает поды с прокси-сервером, которые обеспечивают выполнение правил, заданных в Ingress ресурсах.
В первую очередь в кластер был установлен Ingress Controller. На выбор есть большое количество решений, я взял самое распространенное из них - Nginx Ingress. Прямо сейчас я рассмотрел бы родной для Yandex Cloud ALB Ingress controller, но на тот момент его еще не существовало.
Пример команд для установки Nginx Ingress
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx helm repo update helm install ingress-nginx ingress-nginx/ingress-nginx
Развертывание контроллера приводит к автоматическому созданию в облаке ресурса Load Balancer, который будет являться входной точкой для доступа к приложениям в кластере.
Далее я подготовил Helm шаблон для Ingress ресурсов, описал нужные правила в values и создал объекты.
ingress.yaml
{{- if .Values.ingresses }} {{- range $name, $ingress := .Values.ingresses }} apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: "{{ $name }}" namespace: "{{ $.Release.Namespace }}" annotations: kubernetes.io/ingress.class: nginx {{- if $ingress.cluster_issuer }} cert-manager.io/cluster-issuer: '{{ $ingress.cluster_issuer }}' {{- end }} {{- if $ingress.annotations }} {{- toYaml $ingress.annotations | nindent 4 -}} {{- end }} {{ include "common_labels" $ | indent 4 }} spec: tls: - hosts: - '{{ $ingress.domain}}' secretName: "{{ $name }}" rules: - host: '{{ $ingress.domain}}' http: paths: {{- if $ingress.rules }} {{- toYaml $ingress.rules | nindent 10 -}} {{- end }} --- {{- end }}
values-production.yaml
ingresses: frontend: domain: "*.picvar.io" cluster_issuer: "letsencrypt-prod" annotations: nginx.ingress.kubernetes.io/configuration-snippet: | proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; rules: - backend: service: name: nginx-proxy port: number: 82 path: / pathType: Prefix backend: domain: "*.api.picvar.io" cluster_issuer: "letsencrypt-prod" annotations: nginx.ingress.kubernetes.io/proxy-body-size: 4096m nginx.ingress.kubernetes.io/proxy-max-temp-file-size: "0" nginx.ingress.kubernetes.io/proxy-connect-timeout: "75" nginx.ingress.kubernetes.io/proxy-read-timeout: "1200" nginx.ingress.kubernetes.io/proxy-send-timeout: "1200" nginx.ingress.kubernetes.io/configuration-snippet: | proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-WEBAUTH-USER $subdomain; send_timeout 20m; rules: - backend: service: name: nginx-proxy port: number: 81 path: / pathType: Prefix
Нам нужна работа по HTTPS, поэтому следующим шагом я установил cert-manager, инструмент для выпуска Let's Encrypt сертификатов в Kubernetes.
Пример команды для установки cert-manager
kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.6.1/cert-manager.yaml
Далее добавил в Helm чарт для nginx-proxy шаблон для cert-manager ClusterIssuer и переменные для него.
certmanager-issuer.yaml
{{- if $.Values.certmanager.enabled }} --- apiVersion: cert-manager.io/v1 kind: ClusterIssuer metadata: name: letsencrypt-prod spec: acme: email: {{ $.Values.certmanager.email }} server: https://acme-v02.api.letsencrypt.org/directory privateKeySecretRef: name: letsencrypt-prod solvers: - dns01: cloudflare: email: {{ $.Values.certmanager.email }} apiTokenSecretRef: name: cloudflare-api-token-secret key: api-token selector: dnsNames: {{- if $.Values.certmanager.dnsNames }} {{- toYaml $.Values.certmanager.dnsNames | nindent 8 -}} {{- end }}
values-production.yaml
certmanager: enabled: true email: some@email dnsNames: - '*.picvar.io' - '*.api.picvar.io'
В результате была обеспечена балансировка и маршрутизация внешнего трафика до компонентов приложения в кластере. Благодаря настройке cert-manager появилось автоматическое управление SSL сертификатами и включением HTTPS соответственно.
Настройка процесса CI/CD
Миграция в Kubernetes потребовала изменений в процессе доставки обновлений в окружения. Для начала покажу как у нас был организован CI/CD до миграции.
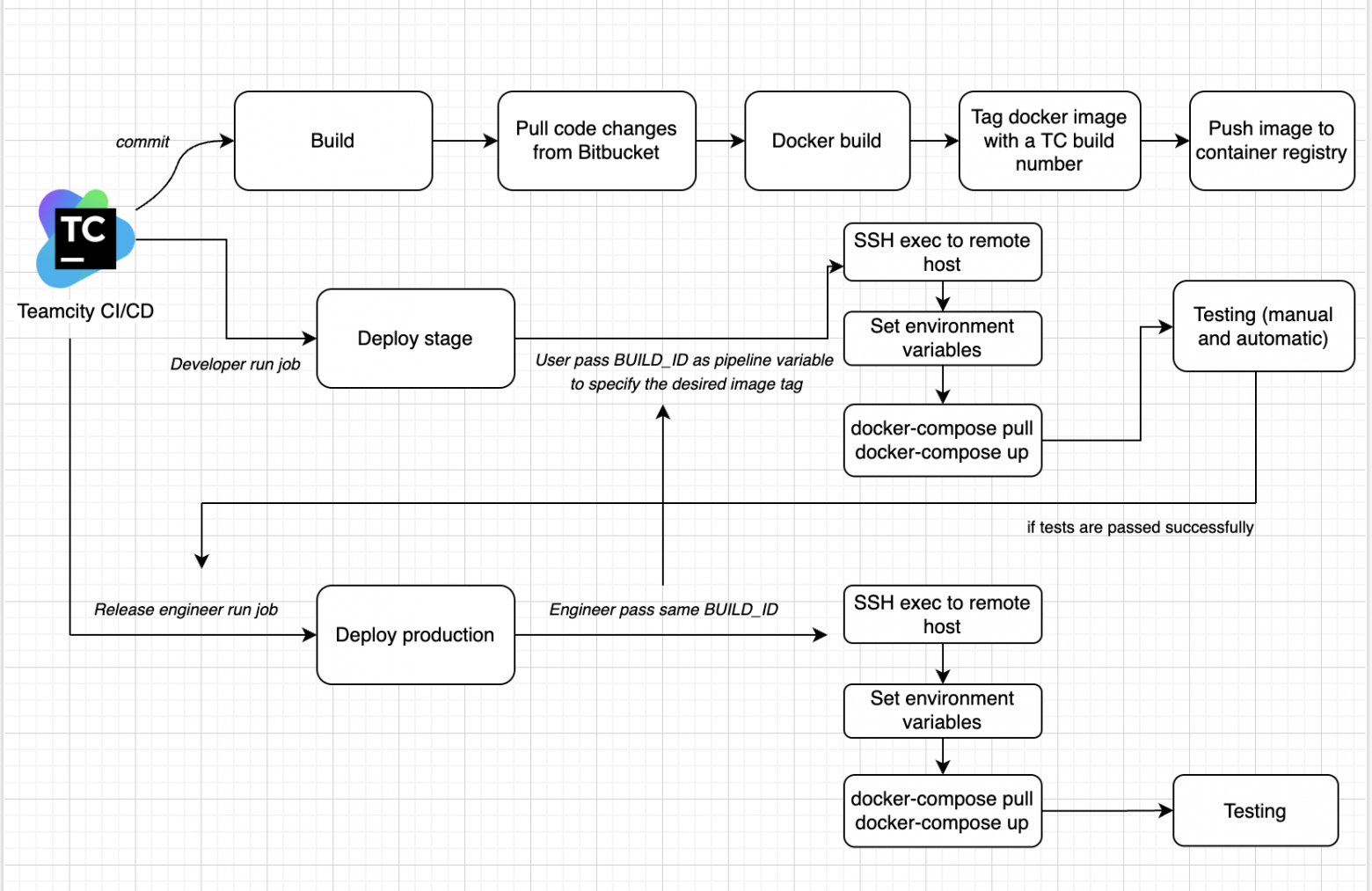
Как понятно из схемы, в качестве инструмента для CI/CD у нас использовался Teamcity. В целом и сам Teamcity, и исторически сложившийся у нас подход к CI/CD всех устраивал. Как минимум, мне нужно было адаптировать деплой под Kubernetes, но заодно я изучил распространенные практики CI/CD в Kubernetes, с возможностью переосмысления процесса целиком при необходимости. В таблице ниже выводы о преимуществах и недостатках, к которым я пришел в результате ресерча.
Подход | Особенности реализации | Плюсы | Минусы |
CIOps (push модель) | - Подход, при котором CI система имеет доступ к кластеру и сама выполняет шаги деплоя и пушит изменения в кластер. - Нужный Docker тег передается во время деплоя в качестве переменной. - Это может быть как обновление чарта путем выполнения команды helm upgrade, так и применение манифестов через kubectl apply | - Простота реализации как в целом, так и в нашем случае. Таким способом у нас уже была построена работа с приложением в Docker Compose, адаптации требовал лишь шаг с деплоем. - Схема с доставкой зафиксированного тега образа во все окружения дает предсказуемость раскатки одинакового состояния кода | - Не защищает от ручных изменений объектов в кластере. Если кто-то внесет изменения, то система не откатит их. - Нет реального аудита происходящего из-за отсутствия некоего единственного источника правды - Нет обратной связи при выкатке. После выполнения команд развертывания (helm upgrade/kubectl apply напр.) мы получаем сообщение об успехе применения, но по факту неизвестно развернулись ли изменения корректно |
GitOps (pull модель) | - Подход при котором Git репозиторий является единственной точкой входа в изменения объектов в кластере. - В Kubernetes устанавливается GitOps оператор, который отслеживает состояние из Git репозитория, сравнивает с текущим в Kubernetes и при наличии изменений обновляет состояние объектов в Kubernetes. - По завершению сборки CI система должна закоммитить в репозиторий с манифестами тег нового образа. После этого GitOps оператор синхронизирует изменения, обновив приложение. | - Наглядность происходящего и подробная обратная связь по результатам развертывания. - GitOps оператор откатывает изменения, сделанные в объектах вручную, если они не совпадают с состоянием в Git. - Безопасность. У CI системы нет доступа к Kubnernetes вообще, а CD оператор установлен внутри самого кластера. - UI с которым поставляются операторы типа ArgoCD, позволяющий по сути заменить использование сторонних дашбордов - Расширение функционала. Тот же ArgoCD из коробки имеет различные полезные фичи вроде уведомлений при определенных триггерах или хуков для более гибкой оркестрации. Плюс функционал расширяется за счет использования сторонних родственных контроллеров вроде Argo Rollouts, Workflow, Events. | - Нужно использовать определенный подход в работе с ветками и CI, соответствующий методологии GitOps. У нас же исторически сложился другой подход в работе с Git и это требовало бы согласований и изменений. - Необходимость дробления на два репозитория: с кодом и инфраструктурной частью. Иначе повышен риск возникновения git конфликтов. - Чисто субъективно мне не нравится история с пушами коммитов в репозиторий от CI системы. Тут я симпатизирую подходу в CIOps с передачей тега образа в качестве переменной. |
Помимо использования чисто CIOps или GitOps подходов распространено и совмещение данных практик. В таком случае:
В CI системе выполняется сборка образа и его пуш в хранилище
В CI системе выполняется deploy-пайплайн, который в качестве переменной сообщает GitOps оператору данные о новом билде компонента. Например в ArgoCD для этого используется механизм Parameter Overrides, который позволяет управлять определенными переменными за пределами Git.
CI система триггерит GitOps оператор на синхронизацию изменений
GitOps оператор определяет, что текущее состояние приложения не совпадает с заданным, и пересоздает приложение с новым образом, тег которого был задан на шаге №2.
Я выбрал именно такой подход. Преимущества, получаемые при использовании GitOps оператора по сравнению с классическим push деплоем через CI систему, весьма существенны. Совместив методы, удалось нивелировать некоторые из недостатков конкретного подхода. Например, оставить привычную нам схему работы с Git и CI, без необходимости изменений процессов.
В качестве GitOps оператора был выбран Argo CD, один из самых распространенных инструментов. Установив его в кластер все дальнейшие настройки я выполнил через web интерфейс инструмента:
- Настроил подключение к кластеру
- Создал Project и настроил доступ к Git репозиторию с чартами
- Создал Applications. Принцип - отдельное приложение под каждый Helm чарт
Argo CD поддерживает работу с Helm из коробки. При создании Application указывается путь к нужному чарту в репозитории. Далее запускается процесс синхронизации и Argo CD создает/обновляет все компоненты, описанные в чарте.

Таким образом был решен вопрос с автоматизацией деплоя приложения в Kubernetes кластер. Центральным инструментом для работы со сборкой и деплоем по-прежнему остается Teamcity, но сам деплой теперь выполняется с помощью ArgoCD. При этом, несмотря на проделанную модернизацию, для наших разработчиков и тестировщиков механизм действий по работе с гитом и CI/CD системой не изменился никак. Удобство для команды разработки — значимый пункт в выборе подхода к CI/CD. Важно, что удалось соблюсти его, не мешая при этом решать задачи DevOps.
Масштабируемость. Быстродействие проблемных компонентов
Одной из ключевых целей перехода в Kubernetes была автоматическая масштабируемость приложения. Чем больше пользователей было у приложения тем чаще небольшое число клиентов создавало большую нагрузку на приложение и это влияло на быстродействие для других пользователей. Прежде чем перейти к решению, расскажу почему возникала такая проблема и в чем конкретно она выражалась.
Напомню, что система мульти-тенантная — каждый клиент работает в изолированном пространстве приложения, эксплуатируя общие системные ресурсы. Поступающими задачами на фоновую загрузку и обработку медиа-активов занимаются воркеры приложения. При этом клиентов много, а очередь на обработку общая, работающая по принципу FIFO. Соответственно возникали ситуации, когда один тенант ставил на загрузку тысячи фото- или видеофайлов, и остальные клиенты были вынуждены ждать пока их обработка завершится. Можно легко представить недовольство пользователя, который не мог загрузить даже пару картинок.
В первую очередь разработчиками был улучшен алгоритм заполнения очереди задачами. Теперь алгоритм учитывал длину очереди по тенантам и выполнял приоритизацию задач. Это позволило справедливо распределять задачи между клиентами, но, тем не менее, не исправляло быстродействия работы приложения в целом.
Нужно было дать системе возможность подстраиваться под плавающую нагрузку так, чтобы весь функционал приложения продолжал работать оперативно, а сервера не выпадали из строя даже при сильной нагрузке.
Для этого отлично подходит механизм автомасштабирования в Kubernetes. Вот кратко принцип его работы:
Масштабирование pod. Количество его реплик увеличивается при нагрузке.
Масштабирование node. Если на текущем железе нет мощностей для запуска новых подов, то происходит заказ новой виртуальной машины.
Масштабирование подов:
Реализуется с использованием стандартного Kubernetes объекта Horizontal Pod Autoscaler. Для работы скейлинга я сделал вот что :
Используя Helm, создал HPA объект для каждого пода, которому необходим скейлинг
В параметрах HPA указал количество реплик (min/max) и отслеживаемую метрику, по которой происходит скейлинг
Настроил для pod параметр Resource Requests, отвечающий за запрашиваемые им ресурсы на ноде.
Скейлинг можно настроить по ряду метрик. Самый базовый вариант — отслеживание нагрузки на CPU и/или memory. Еще HPA позволяет использовать кастомные метрики, например из системы мониторинга Prometheus. В нашем случае я выбрал метрику, отслеживающую нагрузку на CPU. Это подходящий вариант для нашего приложения, но все-таки не универсальный для всех его компонентов, поэтому я планирую в будущем внести изменения. Для Celery воркеров будет правильней организовать скейлинг от количества задач в очереди брокера. Кастомные метрики позволяют это сделать.
hpa.yaml
{{- range $name, $app := .Values.apps }} {{- if and $app.autoscaler_enabled $app.autoscaler_min $app.autoscaler_max }} apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: {{ $.Release.Name }}-{{ $name }} spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: {{ $name }} minReplicas: {{ $app.autoscaler_min }} maxReplicas: {{ $app.autoscaler_max }} targetCPUUtilizationPercentage: {{ $app.target_cpuutilization }} --- {{- end }} {{- end }}
Масштабирование нод:
За автоматическое изменение количества узлов отвечает компонент Cluster Autoscaler. Для его работы в Kubernetes Yandex облака необходимо на этапе создания группы узлов выбрать автоматический тип масштабирования и указать минимальное и максимальное количество машин.
Соответственно, если для пода не хватает ресурсов на существующих ВМ, то заказывается новая виртуалка, на которой и происходит размещение. А как только нагрузка спадает, то уменьшается количество подов и вслед за этим количество нод. Для того чтобы указать — сколько именно ресурсов нужно выделить поду, используется параметр resource requests. Исходя из этой информации kube-scheduler принимает решение о том, на какой ноде разместить данный под.
Расскажу про проблемы в производительности, которые появились на каком-то этапе даже при настроеном скейлинге. Дело в импорт воркере, который отвечал за загрузку и обработку изображений, конвертацию видео (с помощью FFmpeg) и генерацию фото/видео превью. Проблема возникала при большом количестве загружаемых видео. Во-первых, процесс транскодинга приводил к проседанию виртуалок по IOPS, что сильно влияло на быстродействие других компонентов приложения, находившихся на этих же нодах. Во-вторых страдало быстродействие самого процесса транскодинга. Конвертация одного видео шла довольно медленно, пусть скейлинг и приводил к множеству параллельно выполняемых конвертаций.
Вот как это было решено:
Задачи по транскодингу видео вынесены в отдельный Celery воркер. Так появляется больше гибкости в оркестрации и транскодинг не влияет на другие процессы на воркере
Создана изолированная node группа. Воркер деплоится строго на нодах из этой группы. Реализовано с помощью механизма nodeselector, так pod разворачивается только на узлах, где присутствует нужный лейбл.
Изменены параметры FFmpeg, одному процессу выделено 6 ядер процессора. Теперь конвертация одного видео происходит значительно быстрее.
Resource Requests настроены таким образом, что на одной ноде будет присутствовать только один экземляр воркера с FFmpeg. Скейлинг приводит к заказу новой ноды в рамках изолированной группы и размещению реплики на ней.
Таким образом, автоскейлинг обеспечил быстродействие и масштабируемость приложения. Была решена критичная проблема в скорости работы сервиса при высокой нагрузке.
Вывод. Итоги и польза миграции
Сейчас в продакшен кластере запущено чуть больше 120 подов, учитывая системные компоненты. При нагрузке их количество автоматически увеличивается.
Процесс миграции в Kubernetes потребовал немалых трудозатрат. Помимо инфраструктурных работ пришлось изменять и само приложение.
Есть ли в итоге толк от этой миграции? Однозначно да. В результате решены критичные проблемы качества работы сервиса, ради которых затевалась миграция. Повышена скорость работы приложения при нагрузке, появилась отказоустойчивость, обеспечено отсутствие даунтаймов при релизах. А также обеспечена возможность решения будущих задач при дальнейшем росте и развитии приложения.

