Привет! На связи Данила Соловьев, руководитель направления PHP в AGIMA. Для проджект-менеджеров и джуниор-разработчиков я подготовил небольшой гайд по тому, как ускорять работу крупных проектов на Битрикс и повышать их отказоустойчивость. Здесь вы не найдете сложных кейсов или сногсшибательных решений. Но зато найдете простые и применимые советы.

Как читать эту статью
Речь пойдет о проектах на Битриксе уровня Enterprise. Некоторые рекомендации будут справедливы и для других PHP-фреймворков и стеков веб-разработки.
Но самое главное: все мы понимаем, что проект в первую очередь нужно реализовать. Уже на этом этапе разработчики продумывают, насколько быстро будет работать система и что ей в этом поможет. Но предусмотреть абсолютно всё невозможно. Эта статья поможет разобраться, как ускорить уже запущенный проект. |
Каждый раздел этого текста — это архитектурный блок. Чтобы приложение летало, поработать можно со всеми сразу или с одним из них. Я выделил 5 блоков:
Сам Битрикс и всё, что написано на PHP/HTML/CSS/JS поверх.
Базы данных: из коробки в Битриксе это MySQL.
Кэш.
Интеграция с другими системами.
Файловая система.
Внутри каждого блока чек-лист с комментариями или просто список советов. Прочитаете — будете лучше понимать своего тимлида. А может, при случае и подскажете ему что-нибудь.
Как ускорить проект на уровне Битрикс и PHP/HTML/CSS/JS
PHP.
a. Использовать готовые библиотеки.
Все библиотеки под решение конкретных задач отлаживаются и версионируются разработчиками не за час и не за неделю. Это большой труд, и все решения прорабатываются годами. У них есть команда поддержки. Поэтому их нужно использовать — это повысит отказоустойчивость проекта.
Для работы с библиотеками и зависимостями используйте composer (https://getcomposer.org/).
b. Профилировать код в серьезных проектах.
Профилировщик собирает данные о том, с какой скоростью и какая функциональность на странице выполняется. Эти данные помогают разработчику и тимлиду на конкретной странице находить узкие места — те, что замедляют общее время загрузки.
c. Пропускать самописный код через статические анализаторы.
Какой бы крутой ни была команда разработчиков, ошибки бывают у всех. Анализаторы страхуют всю команду от опечаток или мелких ошибок, которые бы серьезно сказывались на работе всего проекта.
HTML/CSS/JS.
a. Верстку и фронтовую часть делать на сборщике.
Если верстка изначально оптимизирована и сжата, изъяны искать будет проще. Скорее всего, они будут на стороне Backend-разработчиков.
Полезная ссылка: https://dev.1c-bitrix.ru/learning/course/index.php?COURSE_ID=43&LESSON_ID=12435
Тестирование.
a. Не забывать о тестировании.
Если проект реально большой, то без тестировщиков никуда. Важно, чтобы они внедряли смоки, регрессы и отлаживали процесс тестирования. Благодаря этому в прод уйдет меньше багов. И значит, у разработчиков будет больше времени, чтобы заниматься ускорением проекта и повышением отказоустойчивости.Bitrix.
a. Помнить про ресайз картинок.
Представим сайт с инфоблоком «Новости». В одну из них загрузили картинку на 15 Мб. Без ресайза сеть будет подтягивать ее полностью, страница будет грузиться долго. Это скажется на индексации. Конечный пользователь получит очень долгий рендер.b. Использовать d7 и ORM.
Менеджерам сложно это проконтролировать, но знать полезно. Эти две технологии ускоряют проект примерно в 5 раз — моя личная статистика.c. Переносить как можно больше с инфоблоков на HLB.
Переносить на HighLoad-блоки нужно всё, что возможно. Особенно, если вам не нужен какой-то очень удобный контент-менеджмент из админки. А лучше вообще проектировать свои таблицы и решения. Особенно это касается автоматизированных интеграций.d. Кэшировать одинаковые данные на одном хите.
Объясню на примере. Допустим, на страницу выводятся баллы из системы лояльности. Выводятся они как в начале страницы, так и в конце. Чтобы не делать два запроса в процессе загрузки, можно сделать только первый. Дальше баллы нужно закэшировать на уровне PHP, а потом из кэша в оперативной памяти достать и отобразить в нижней части страницы. Так мы урезаем запрос и уменьшаем время рендера страницы.
e. Архивировать устаревшие данные.
Если у вас хранятся данные 2015 года, а вы живете в 2022, то возможно, эти данные устарели. Желательно унести их куда-то в другое место и доставать только при необходимости.f. Учитывать агенты и их ограничение по времени.
Агенты — фоновые задачи. У них есть ограничение по времени — 10 минут. Поэтому, если тимлид говорит: «Мы будем вот эту выгрузку выполнять на агенте, которая содержит миллионы строк данных», — это плохая идея. Как сделать, чтобы выгрузка постоянно не падала, расскажу дальше.
Как ускорить на уровне баз данных
Разносить базы данных и приложение на разные «машины».
В идеальном мире работа Битрикс и PHP не связана с ресурсами, которые используют базы данных. Так вы распределите нагрузку на эти части системы.
Использовать в базах индексы.
Индексы — это данные из таблиц, отсортированные по конкретным столбцам, по которым построен индекс. Благодаря им в базе работает бинарный поиск. Проще говоря, поиск идет не по каждой строчке. Вместо этого система делит таблицу на две равные части. Смотрит влево, смотрит вправо. Если влево не найдено — то вправо. Правая часть тоже делится пополам и т. д.
Если данные в таблице обновляются/создаются/удаляются намного чаще, чем выполняется их чтение, то использовать индексы не стоит. Этот вариант подходит, если на сайте есть новости с фильтрацией. Фильтрация с помощью индексов будет работать быстрее.
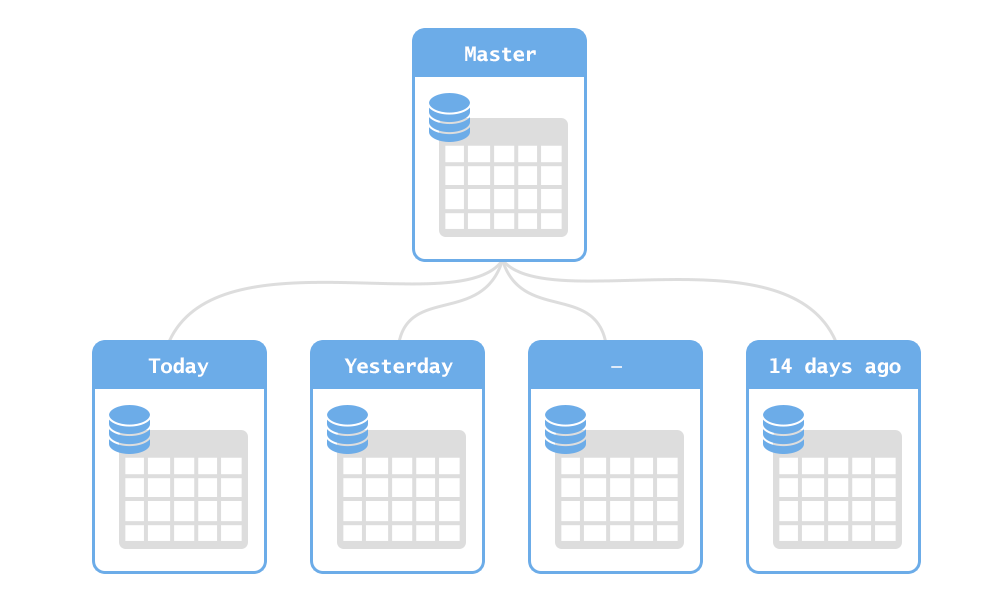
Использовать репликации.
Репликация — это механизм создания копий базы данных, которые синхронизируются с оригиналом. Копии бывают двух типов: Master и Slave. Если копия Master, то мы в ней можем и писать, и читать. А если Slave — только читать. Изменения с Master тиражируются на все копии. Реализуется этот механизм на стороне СУБД, ничего программировать не надо.
Полезно применять, когда у вас на стороне заказчика есть аналитики или системы, которые хотят читать данные в вашей базе. Вы можете сделать отдельную Slave-реплику только для аналитиков. Они будут делать сложные запросы, которые могут уронить всю базу. Но упадет она только для них.
Использовать партиции.
Партиции помогут, если у вас одна большая таблица на проекте. Партиция — это принцип деления таблицы на основании какого-то фильтра. Например, по дате. Когда таблица очень большая, это поможет разделить нагрузку и повысить отказоустойчивость. Этот механизм тоже реализуется на стороне СУБД.
Применять шардирование.
В этом случае нужна работа программиста. Шардирование — это вариант распределения нагрузки. Он похож на партиции: тоже деление таблиц по какой-то логике.
Например, можно шардировать фотографии пользователей. Все фотографии нечетных пользователей уходят в одну шарду, четных — в другую.
Как ускорить проект на уровне кэша
Кэш нужен, чтобы снять нагрузку с баз данных. В Битриксе «из коробки» разные типы кэша. Я перечислю плюсы и минусы самых популярных. Но отдельно подчеркну: все эти решения разгружают базу данных. Это их основная функция.
Файловый кэш.
Плюсы | Минусы |
Объем не ограничен: если ваш жесткий диск на терабайт, он будет наполняться кэшем, пока вы полностью его не забьете. | Самый медленный из всех типов. |
Персистентный: если у вас падает какая-то «машина», закэшированные данные не теряются — как лежали на диске, так и продолжают лежать. | Генерирует нагрузку на ту же файловую систему, потому что лежит на жестком диске. |
Memcached.
Плюсы | Минусы |
Очень быстрый. | Не персистентный: работает в оперативной памяти — если «машина» упала, то кэш потерян. |
Ограничен объемом выделенной под него оперативной памяти. |
Redis.
Это решение тоже работает в оперативной памяти. Его можно применять для быстрых операций. Например, для хранения сессий или для авторизации через сторонние сервисы, храня в нем токены, выданные другой системой.
Плюсы | Минусы |
Быстрый. | Небольшой объем. |
Может быть персистентным: его можно сконфигурировать как персистеным, так и не персистентным. Но если персистентный, то работает медленнее. |
Еще один способ — прогрев кэша.
Он подходит в случаях, когда на проекте могут собираться большие объемы кэша. Допустим, он собирается по городам — на каждый город свой кэш. Это увеличивает его объем. Когда вы задеплоили что-то, для чего потребуется его сброс, можно внедрить ручной или автоматизированный прогрев кэша.
Ручной: после сброса кэша запускаете тестировщика, и он меняет города; можно менять только основные, потому что с них будет больше всего потока и нагрузки.
Автоматизированный: это можно повесить на CI/CD и просто написать какие-то функциональные тесты, которые будут после деплоя ходить и медленно переключать города и собирать кэш.
Как ускорить на уровне интеграций с другими системами
В первую очередь я говорю об интеграциях типа «точка — точка»: REST, SOAP. Они работают просто и понятно: одна система отправила запрос, ждет. Вторая система приняла запрос, обработала, отдала ответ. Отправляющая система ждать перестала, обработала ответ, пошла дальше.
Более важная тема — брокеры сообщений и менеджеры очередей. Их мы можем применить вместо REST и SOAP. Примеры брокеров сообщений — Kafka, RabbitMQ. Вот чего они позволяют добиться:
Асинхронность.
Система отправляет запрос в брокер и дальше занимается своими делами — ответ она заберет в фоновом режиме. Система не забивает память этим запросом: на ее стороне есть обработчик, он же консьюмер, который читает и обрабатывает ответы по одному.
Гарантия доставки.
В случае с REST, когда ваша система отправляет запрос, а вторая система лежит, пользователь получает 500 ошибку. В случае с брокерами вы всегда дождетесь ответа от другой системы. Кроме тех случаев, когда ваш брокер лежит. Но это критическая проблема — сейчас речь не об этом.Уменьшение нагрузки на отправляющей и на принимающей стороне.
Когда у вас «точка — точка», системе тяжелее. Например, 5 млн пользователей одновременно зашли на сайт и вызвали одно и то же интеграционное действие. Ваша система ждет 5 млн ответов. Другая система обрабатывает 5 млн запросов. Брокер же принимает запросы и отдает ответы быстро. Он записывает запрос, отдает в другую систему. Там консьюмер читает и обрабатывает по одному сообщению в фоне. Всё это не занимая ресурсов на 5 млн запросов.Ускорение постоянных и многочисленных однотипных фоновых действий.
Если у вас на проекте много логирования, количество посетителей и файлов записей растет, всё это можно перевести на брокер. Система такая: ваш лог сначала пишется в брокер, а дальше в вашей же системе имеется консьюмер, который читает из брокера и записывает в хранилище с логами, но не генерирует такого количества нагрузки.Решение продолжительных фоновых задач.
Например, если на проекте генерируется больше событий, чем агент успевает обработать за 1 раз, агент падает. В лучшем случае просто не успевает обрабатывать очередь поступающих заявок. С брокерами проще: заявки передаются им, а потом обрабатываются в другом месте без ограничения по времени.
Как ускорить на уровне файловой системы
Файловая система работает как база знаний: в ней есть операции чтения и записи. За этим показателем важно следить и уменьшать его на каждой конкретной «машине». Вот два параметра, на которые стоит обращать внимание:
Статика минимизирована и оптимизирована.
Статический контент — то, что запрашивается при каждом запросе, если он не был закэширован в браузере. К такому контенту относится CSS, JS, дефолтные картинки типа логотипов компаний. В идеале они должны быть минимизированы, оптимизированы и куда-нибудь убраны — например, в CDN.
Динамический контент и медиа в S3-хранилище.
S3-хранилище — это облачное хранилище, которое гарантирует, что ваши данные будут отдаваться, храниться, не пропадать и т. д. С помощью него вы разгрузите файловую систему: файлы при рендере страницы в браузере будут подтягиваться из хранилища, а не с вашего сервера.
Эти рекомендации сделают вашу систему более быстрой и отказоустойчивой. Разработчики применяют их в работе — но знать о них полезно всей команде. В следующий раз, когда покажется, что ваш проект на Битриксе работает медленно, спросите у тимлида, все ли способы ускорения он использовал.
Если есть вопросы, задавайте в комментариях. Я по-прежнему на связи!

