
В предыдущей части мы научились эффективно передавать данные вспомогательным потокам из основного через разделяемую память, используя Atomics-операции и блокировки.
Но мы рассматривали все-таки идеальную ситуацию, когда основной поток больше ничем не занимался, кроме обмена с "подчиненными" уже заранее готовыми данными. В реальных же приложениях такое встречается достаточно редко - обычно эти самые данные приходится готовить непосредственно перед передачей. И, бывает, в этом участвует существенная доля синхронного кода, что для JavaScript крайне неприятно, но иногда неизбежно - например, при вычислении регулярных выражений.
Давайте оценим, насколько синхронные операции "роняют" производительность нашего тестового приложения. И узнаем, как можно в разы улучшить ее, "скрестив ужа с ежом", используя выделенный поток-координатор из позапрошлой части статьи совместно с разделяемой памятью.
Добавим немного синхронности
Возьмем тот же самый тест из предыдущей части про разделяемую память и вместо массива сохраним все "сообщения" во временный каталог:
const fs = require('node:fs'); const {tmpdir} = require('node:os'); const {sep} = require('node:path'); // создаем временную папку и в ней файлы со всеми "сообщениями" const dir = fs.mkdtempSync(tmpdir() + sep); messages.forEach((data, i) => { const fn = i.toString(16).padStart(3, '0'); fs.writeFileSync(dir + sep + fn, data); });
А уже в ходе теста будем их синхронно вычитывать с помощью readFileSync, намеренно "притормаживая" EventLoop в основном потоке приложения:
// получаем список всех сообщений в папке const fns = fs.readdirSync(dir) .sort() .map(fn => dir + sep + fn); remain = fns.length; tsh = hrtime(); tfs = 0n; // длительность синхронных операций fns.forEach((fn, id) => { const ts = hrtime(); const data = fs.readFileSync(fn); // тяжелый синхронный код tfs += hrtime() - ts; // ... и его продолжительность pool.postMessage({id, data}); });
Миримся с нестабильностью времени чтения с диска
При проведении подобного теста достаточно сильно может влиять аспект кэширования чтения.
То есть если нам "повезло", и данные конкретного файла ОС еще не успела вытеснить и держит в pagecache, то уменьшится время синхронного выполнения для все того же readSync того же файла в следующем прогоне, и поэтому может меньше повлиять на деградацию общего времени теста.
Тут мы замеряем как общее время отработки теста, так и отдельно длительность синхронных операций. Их разность даст нам, конечно, не само время обработки (пока основной поток синхронно читает, остальные-то работают), но некоторую оценку общей потери производительности.
Полный код и результаты тестов
const { Worker , isMainThread , parentPort , workerData } = require('node:worker_threads'); const { randomBytes , createHash } = require('node:crypto'); const hrtime = process.hrtime.bigint; const THREAD_FREE = -1; const EventEmitter = require('events'); class WorkersPool extends EventEmitter { #queue; #workersPool; constructor({queue, workersPool}) { super(); this.#queue = queue; this.#workersPool = [...workersPool]; } #shareMessage(worker, {id, data}) { worker.data.set(data, 0); worker.lock[0] = id; Atomics.notify(worker.lock, 0, 1); const lock = Atomics.waitAsync(worker.lock, 0, id); if (lock.value === 'not-equal') { this.#onMessage(worker); } else { lock.value.then(result => { this.#onMessage(worker); }); } } #onMessage(worker) { const msg = this.#queue.shift(); if (msg) { this.#shareMessage(worker, msg); } else { this.#workersPool.push(worker); } } postMessage(msg) { const worker = this.#workersPool.pop(); if (worker) { this.#shareMessage(worker, msg); } else { this.#queue.push(msg); } } } if (isMainThread) { const taskSize = 1 << 16; const tsg = hrtime(); const messages = Array(1 << 12).fill().map(_ => randomBytes(taskSize)); const fs = require('node:fs'); const {tmpdir} = require('node:os'); const {sep} = require('node:path'); // создаем временную папку и в ней файлы со всеми "сообщениями" const dir = fs.mkdtempSync(tmpdir() + sep); messages.forEach((data, i) => { const fn = i.toString(16).padStart(3, '0'); fs.writeFileSync(dir + sep + fn, data); }); console.log('generated:', Number(hrtime() - tsg)/1e6 | 0, 'ms'); const hashes = messages.map(() => undefined); let remain; const workers = []; let active = 1; let tsh; let tfs; process .on('test:start', () => { hashes.fill(); const Pow2Buffer = require('./Pow2Buffer'); pool = new WorkersPool({ queue : new Pow2Buffer(8, 16) , workersPool : workers.slice(0, active) }); // получаем список всех сообщений в папке const fns = fs.readdirSync(dir) .sort() .map(fn => dir + sep + fn); remain = fns.length; tsh = hrtime(); tfs = 0n; // длительность синхронных операций fns.forEach((fn, id) => { const ts = hrtime(); const data = fs.readFileSync(fn); // тяжелый синхронный код tfs += hrtime() - ts; // ... и его продолжительность pool.postMessage({id, data}); }); }) .on('test:end', () => { const duration = hrtime() - tsh; console.log( 'hashed ' + active.toString().padStart(2) + ':' , (Number(duration - tfs)/1e6 | 0).toString().padStart(4) , 'ms' , '| fs.read' , (Number(tfs)/1e6 | 0).toString().padStart(4) , 'ms' , '| total' , (Number(duration)/1e6 | 0).toString().padStart(4) , 'ms' ); if (active < n) { active++; process.emit('test:start'); } else { process.exit(); } }); const n = 16; Promise.all( Array(n).fill().map(_ => new Promise((resolve, reject) => { // выделяем сегменты разделяемой памяти const sharedBufferData = new SharedArrayBuffer(taskSize); const sharedBufferLock = new SharedArrayBuffer(Int32Array.BYTES_PER_ELEMENT); // инициализируем "пустое" состояние блокировки const lock = new Int32Array(sharedBufferLock); lock.fill(THREAD_FREE); // передаем в поток ссылки на сегменты разделяемой памяти const worker = new Worker(__filename, { workerData : { data : sharedBufferData , lock : sharedBufferLock } } ); worker.data = new Uint8Array(sharedBufferData); worker.lock = lock; worker .on('online', () => resolve(worker)) .on('message', ({id, hash}) => { hashes[id] = hash; if (!--remain) { process.emit('test:end'); } }); })) ) .then(result => { workers.push(...result); process.emit('test:start'); }); } else { const {data, lock} = workerData; const sharedData = new Uint8Array(data); const sharedLock = new Int32Array(lock); do { const lock = Atomics.wait(sharedLock, 0, THREAD_FREE); parentPort.postMessage({id : sharedLock[0], hash : createHash('sha256').update(sharedData).digest('hex')}); sharedLock[0] = THREAD_FREE; Atomics.notify(sharedLock, 0, 1); } while (true); }
generated: 1959 ms hashed 1: 1237 ms | fs.read 4152 ms | total 5390 ms hashed 2: 616 ms | fs.read 555 ms | total 1171 ms hashed 3: 411 ms | fs.read 667 ms | total 1079 ms hashed 4: 344 ms | fs.read 801 ms | total 1145 ms hashed 5: 326 ms | fs.read 560 ms | total 887 ms hashed 6: 307 ms | fs.read 619 ms | total 926 ms hashed 7: 336 ms | fs.read 574 ms | total 911 ms hashed 8: 315 ms | fs.read 572 ms | total 887 ms hashed 9: 315 ms | fs.read 908 ms | total 1224 ms hashed 10: 305 ms | fs.read 904 ms | total 1209 ms hashed 11: 343 ms | fs.read 580 ms | total 924 ms hashed 12: 300 ms | fs.read 598 ms | total 899 ms hashed 13: 326 ms | fs.read 597 ms | total 924 ms hashed 14: 308 ms | fs.read 584 ms | total 893 ms hashed 15: 315 ms | fs.read 580 ms | total 895 ms hashed 16: 310 ms | fs.read 579 ms | total 890 ms

В точке максимальной эффективности "4 потока на 4 ядрах", которую мы вычислили в прошлый раз, условно "чистое" время ухудшилось на 15% - а ведь мы всего лишь на некоторое время заняли основной поток.
К сожалению, отреагировать на освобождение вспомогательного потока и дать ему следующую задачу основной может не раньше, чем завершит текущую синхронную операцию:

Поток-координатор
Но давайте тогда процесс "раздачи заданий" вытащим в отдельный поток, описанный во второй части нашего цикла - пусть в нем будет минимум синхронного кода и его реакции ничем не затормаживаются:
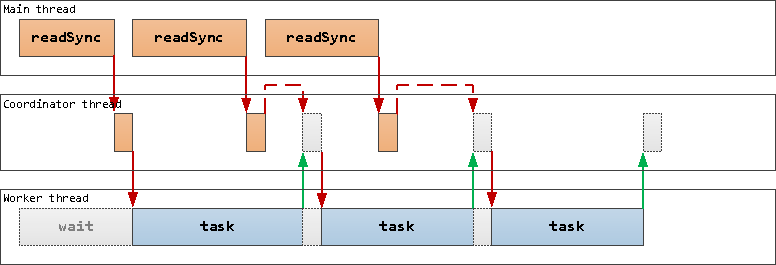
Из основного потока передавать информацию в координатор мы будем "по ссылке", без копирования, с помощью transferList:
fns.forEach((fn, id) => { const ts = hrtime(); const data = fs.readFileSync(fn); // тяжелый синхронный код tfs += hrtime() - ts; // ... и его продолжительность coordinator.postMessage( {id, data} , [data.buffer] // передача по ссылке через transferList ); });
... а уже между координатором и вспомогательными потоками - копировать через разделяемую память, которую передадим при увязке дочерних потоков:
// ... Promise.all( workers.slice(0, active) .flatMap(worker => { const shared = { // сегменты разделяемой памяти вспомогательного процесса data : worker.data , lock : worker.lock }; return [{worker}, {worker : coordinator, shared}]; }) .map(adressee => new Promise((resolve, reject) => { const {worker, shared} = adressee; worker.signalPort.once('message', () => resolve(adressee)); worker.signalPort.postMessage(shared); // shared попадет только в координатор })) ) // ...
Но если мы оставим в потоке бесконечный синхронный цикл ожидания блокировки, у нас пройдет только первый тест, и все встанет - поскольку "слушать" информацию от нового экземпляра координатора будет уже некому.
Поэтому переведем основной рабочий код тоже на Atomics.waitAsync, заодно сможем вернуть и оценку загрузки EventLoop:
// ... case 'worker': const {data, lock} = workerData; const sharedData = new Uint8Array(data); const sharedLock = new Int32Array(lock); const processMessage = () => { // обрабатываем сообщение parentPort.postMessage({id : sharedLock[0], hash : createHash('sha256').update(sharedData).digest('hex')}) // уведомляем координатор о своей доступности sharedLock[0] = THREAD_FREE; Atomics.notify(sharedLock, 0, 1); // ... и возвращаемся к ожиданию блокировки wait(); }; const wait = () => { const lock = Atomics.waitAsync(sharedLock, 0, THREAD_FREE); if (lock.value === 'not-equal') { // если значение изменилось, то поток уже обработал задачу, и реагируем сразу processMessage(); } else { // иначе ждем разрешения Promise блокировки lock.value.then(result => { processMessage(); }); } }; // сигнализируем готовность и начинаем ждать signalPort.on('message', () => { signalPort.postMessage(undefined); wait(); }); break; // ...
Полный код и результаты тестов
const { Worker , isMainThread , parentPort , workerData , MessageChannel } = require('node:worker_threads'); const { randomBytes , createHash } = require('node:crypto'); const hrtime = process.hrtime.bigint; const THREAD_FREE = -1; if (isMainThread) { const taskSize = 1 << 16; const tsg = hrtime(); const messages = Array(1 << 12).fill().map(_ => randomBytes(taskSize)); const fs = require('node:fs'); const {tmpdir} = require('node:os'); const {sep} = require('node:path'); // создаем временную папку и в ней файлы со всеми "сообщениями" const dir = fs.mkdtempSync(tmpdir() + sep); messages.forEach((data, i) => { const fn = i.toString(16).padStart(3, '0'); fs.writeFileSync(dir + sep + fn, data); }); console.log('generated:', Number(hrtime() - tsg)/1e6 | 0, 'ms'); const hashes = messages.map(() => undefined); let remain; const workers = []; let active = 1; let tsh; let tfs; let coordinator; process .on('test:start', () => { hashes.fill(); const channel = new MessageChannel(); coordinator = new Worker(__filename, { workerData : { signalPort : channel.port1 , workerType : 'coordinator' } , transferList : [channel.port1] } ); coordinator.signalPort = channel.port2; coordinator.signalPort.setMaxListeners(0); coordinator.on('online', () => { Promise.all( workers.slice(0, active) .flatMap(worker => { const shared = { // сегменты разделяемой памяти вспомогательного процесса data : worker.data , lock : worker.lock }; return [{worker}, {worker : coordinator, shared}]; }) .map(adressee => new Promise((resolve, reject) => { const {worker, shared} = adressee; worker.signalPort.once('message', () => resolve(adressee)); worker.signalPort.postMessage(shared); // shared попадет только в координатор })) ) .then(result => { // получаем список всех сообщений const fns = fs.readdirSync(dir) .sort() .map(fn => dir + sep + fn); remain = fns.length; [coordinator, ...workers].forEach(worker => worker.eLU = worker.performance.eventLoopUtilization()); tsh = hrtime(); tfs = 0n; fns.forEach((fn, id) => { const ts = hrtime(); const data = fs.readFileSync(fn); // тяжелый синхронный код tfs += hrtime() - ts; // ... и его продолжительность coordinator.postMessage( {id, data} , [data.buffer] // передача по ссылке через transferList ); }); }); }); }) .on('test:end', () => { const duration = hrtime() - tsh; [coordinator, ...workers].forEach(worker => worker.util = worker.performance.eventLoopUtilization(worker.eLU).utilization); const avg = workers.slice(0, active).reduce((sum, worker) => sum + worker.util, 0)/active; console.log( 'hashed ' + active.toString().padStart(2) + ':' , (Number(duration - tfs)/1e6 | 0).toString().padStart(4) , 'ms' , '| fs.read' , (Number(tfs)/1e6 | 0).toString().padStart(4) , 'ms' , '| total' , (Number(duration)/1e6 | 0).toString().padStart(4) , 'ms | ' + (avg * 100 | 0) + ' | ' , (coordinator.util * 100 | 0).toString().padStart(3) + ' c' , workers.map( worker => (worker.util * 100 | 0).toString().padStart(3) ).join(' ') ); if (active < n) { active++; process.emit('test:start'); } else { process.exit(); } }); const n = 16; Promise.all( Array(n).fill().map(_ => new Promise((resolve, reject) => { // выделяем сегменты разделяемой памяти const sharedBufferData = new SharedArrayBuffer(taskSize); const sharedBufferLock = new SharedArrayBuffer(Int32Array.BYTES_PER_ELEMENT); // инициализируем "пустое" состояние блокировки const lock = new Int32Array(sharedBufferLock); lock.fill(THREAD_FREE); const channel = new MessageChannel(); // передаем в поток ссылки на сегменты разделяемой памяти const worker = new Worker(__filename, { workerData : { signalPort : channel.port1 , workerType : 'worker' , data : sharedBufferData , lock : sharedBufferLock } , transferList : [channel.port1] } ); worker.signalPort = channel.port2; worker.data = new Uint8Array(sharedBufferData); worker.lock = lock; worker .on('online', () => resolve(worker)) .on('message', ({id, hash}) => { hashes[id] = hash; if (!--remain) { process.emit('test:end'); } }); })) ) .then(result => { workers.push(...result); process.emit('test:start'); }); } else { const {signalPort, workerType} = workerData; switch (workerType) { case 'worker': const {data, lock} = workerData; const sharedData = new Uint8Array(data); const sharedLock = new Int32Array(lock); const processMessage = () => { // обрабатываем сообщение parentPort.postMessage({id : sharedLock[0], hash : createHash('sha256').update(sharedData).digest('hex')}) // уведомляем координатор о своей доступности sharedLock[0] = THREAD_FREE; Atomics.notify(sharedLock, 0, 1); // ... и возвращаемся к ожиданию блокировки wait(); }; const wait = () => { const lock = Atomics.waitAsync(sharedLock, 0, THREAD_FREE); if (lock.value === 'not-equal') { // если значение изменилось, то поток уже обработал задачу, и реагируем сразу processMessage(); } else { // иначе ждем разрешения Promise блокировки lock.value.then(result => { processMessage(); }); } }; // сигнализируем готовность и начинаем ждать signalPort.on('message', () => { signalPort.postMessage(undefined); wait(); }); break; case 'coordinator': const pool = []; const queue = new (require('./Pow2Buffer'))(8, 16); const shareMessage = (worker, {id, data}) => { worker.data.set(data, 0); worker.lock[0] = id; Atomics.notify(worker.lock, 0, 1); const lock = Atomics.waitAsync(worker.lock, 0, id); if (lock.value === 'not-equal') { // если значение изменилось, то поток уже обработал задачу, и реагируем сразу onMessage(worker); } else { // иначе ждем разрешения Promise блокировки lock.value.then(result => { onMessage(worker); }); } } const onMessage = worker => { const msg = queue.shift(); if (msg) { shareMessage(worker, msg); } else { pool.push(worker); } } // по сигнальному каналу передаем порт worker'а signalPort.on('message', worker => { // добавляем в пул и подписываемся на обработку сигнала готовности от worker'а pool.push(worker); signalPort.postMessage(undefined); }); // обработка входящего сообщения координатору parentPort.on('message', message => { const worker = pool.pop(); if (worker) { shareMessage(worker, message); } else { queue.push(message); } }); break; } }
generated: 2043 ms hashed 1: 373 ms | fs.read 2387 ms | total 2761 ms | 42 | 10 c 42 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 hashed 2: 118 ms | fs.read 602 ms | total 720 ms | 89 | 39 c 98 79 0 0 0 0 0 0 0 0 0 0 0 0 0 0 hashed 3: 119 ms | fs.read 570 ms | total 690 ms | 80 | 33 c 100 99 40 0 0 0 0 0 0 0 0 0 0 0 0 0 hashed 4: 75 ms | fs.read 603 ms | total 679 ms | 77 | 23 c 100 100 96 12 0 0 0 0 0 0 0 0 0 0 0 0 hashed 5: 204 ms | fs.read 931 ms | total 1135 ms | 81 | 27 c 100 100 100 98 11 0 0 0 0 0 0 0 0 0 0 0 hashed 6: 146 ms | fs.read 994 ms | total 1141 ms | 82 | 12 c 100 100 100 100 88 9 0 0 0 0 0 0 0 0 0 0 hashed 7: 260 ms | fs.read 952 ms | total 1212 ms | 81 | 22 c 100 100 100 100 100 67 5 0 1 0 0 0 1 1 0 1 hashed 8: 142 ms | fs.read 1433 ms | total 1576 ms | 89 | 16 c 100 100 100 100 100 100 100 13 0 0 0 0 0 0 0 0 hashed 9: 253 ms | fs.read 1554 ms | total 1807 ms | 86 | 9 c 100 100 100 100 100 100 100 74 0 0 0 0 0 0 0 0 hashed 10: 196 ms | fs.read 1587 ms | total 1784 ms | 80 | 7 c 100 100 100 100 100 100 100 100 6 2 0 0 0 0 0 0 hashed 11: 311 ms | fs.read 1948 ms | total 2259 ms | 87 | 21 c 100 100 100 100 100 100 100 100 81 81 4 0 0 0 0 0 hashed 12: 237 ms | fs.read 1973 ms | total 2210 ms | 83 | 7 c 100 100 100 100 100 100 100 100 100 100 0 0 0 0 0 0 hashed 13: 362 ms | fs.read 2014 ms | total 2377 ms | 78 | 14 c 100 100 100 100 100 100 100 100 100 100 5 5 8 0 0 0 hashed 14: 73 ms | fs.read 2280 ms | total 2354 ms | 77 | 6 c 100 100 100 100 100 100 100 100 100 100 7 38 37 5 0 0 hashed 15: 413 ms | fs.read 2513 ms | total 2927 ms | 83 | 12 c 100 100 100 100 100 100 100 100 100 100 52 100 100 3 1 0 hashed 16: 241 ms | fs.read 2619 ms | total 2861 ms | 86 | 21 c 100 100 100 100 100 100 100 100 100 100 100 100 100 52 11 12

Код нашего приложения уже совсем перестал быть простым, но зато мы все-таки еще почти в 4 раза уменьшили время обработки.
При этом по координатору еще остается запас для другой полезной работы - например, для динамического управления количеством вспомогательных потоков. Но про это - в следующей части.
часть 1: базовые концепты
часть 2: очередь, каналы и координатор
часть 3: разделяемая память, атомарные операции и блокировки
часть 4: координатор против синхронного кода
часть 5: автомасштабирование под нагрузку

