
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Тезис, что вы не уперлись в жесткий диск не обоснован.
Его легко проверить: поставьте optane или даже ramdisk и проведите тест еще раз, если есть существенное ускорение, значит в диск вы все-таки уперлись.
Поясню, почему ваши выводы про диск преждевременны.
1. Если система не работает быстро, значит она где-то имеет бутылочное горлышко, оно может быть в процессоре, шине, памяти, диске.
2. То, что показывает вам система как уровень нагрузки не обязано означать то, что вы думаете. На самом деле вы не знаете, что значит загрузка 100% (как и я, кстати).
3. Производительность SSD сильно зависит использует ли по direct-запись. Сброс же кеша (не который SQL flash, а который дисковый flash) оказывает катастрофическое воздействие на скорость SSD, так как SSD без сброса кеша сразу рапартует, что типа он записал, но по факту гарантия записи будет только по flash на SSD.
4. ПО баз данных хочет быть уверено, что все записалось, поэтому часто делает flash на дисковую систему.
5. Так как flash делается часто, а запись последовательная, ни о каких 20-30 тыс. random IOPS не может быть и речи.
6. У вас диски не напрямую в сервер воткнуты, а через хранилку, хранилка может иметь собственную логику обработки flash с собственными кешами и как она работает конкретно в вашем случае - не известно.
7. Скачки в IOPS на графике с записью журнала однозначно говорят, что есть корреляция и видимо какой-то периодически запускающийся процесс. Но нет причин утверждать только лишь из графика, что диск не нагружен. Положим профиль нагрузки такой: запиши 16к, сделать flash, долго ждать flash, запиши 16k... так как это последовательная запись в журнал, она будет долгой, так как латентность из-за flash каждой записи большая, но вот только накопитель у вас на 100% при этом не нагружен! Вы бы могли параллельно еще сделать 10 очередей и производительность выросла бы (так как SSD свою пиковую производительность показывают на большом количестве очередей, а на одной очереди она обычно 50-100МБ/c).
8. Если бы база данных могла писать не последовательно в журнал, а параллельно в несколько потоков, то производительность была бы выше, но база данных так не умеет.
9. Ну и наконец, график загрузки ясно говорит, что основное время занимает запись в журнал, процессор не нагружен а значит вариантов где может быть затык остается не сильно много, ага?
В качестве вывода: да, большое количество запросов на запись отрицательно сказывается на скорости этой записи, здесь можно ускоряться, но на самом деле причина такой работы находится в архитектуре СУБД, которая до сих пор оптимизирована для работы с жесткими дисками и пишет в журнал с частыми flash-ами.
Его легко проверить: поставьте optane или даже ramdisk и проведите тест еще раз, если есть существенное ускорение, значит в диск вы все-таки уперлись.
Прям заинтриговали :) т.е . Сайзингу ssd в спецификациях верить нельзя , счетчикам ос тоже (и это без всякой виртуализации!) .
Вопрос - почему тогда avg waits sec по записи в субд 0.0034 в разы меньше чем в logwriter 0.0131? SSD не всем пишет одинаково, если я в него уперся?
Я конечно могу сделать крамолу и поместить log на ram диск, но хотелось бы знать Ваши аргументы это личный опыт или есть пруфлинк
Не очень понимаю о каком avg waits sec идет речь, но вот пруф лично измеренной зависимости работы СУБД от SSD: https://elibsystem.ru/node/586#pgbench
Спецификация SSD верить можно, просто они снимаются без flush на диск (ну или с неизвестной очередностью flush). И почему вы тогда берете random IOPS? Берите последовательный, чего мелочиться, запись ведь в лог транзакций последовательная (кстати, почему вы решили, что СУБД в журнал пишет по 4k, раз сравниваете IOPS с random 4k?) А потом возьмите fio и проверьте скорость последовательной записи при flush после каждой операции. Удивитесь, что IOPS не походит ни на random ни на sequence.
Потом можно еще раз подумать и понять, что запись на самом деле не случайная и не последовательная, а ее профиль вообще говоря от нагрузки зависит и тогда придет понимание, что и бенчмарк на левой базе не даст вам точные значения по которым вы сможете количественные выводы делать, а в лучшем случае приблизительные, которые можно ожидать, если у вас будет на реальной базе схожая нагрузка, чем и в той ситуации, с которой вы сравниваете.
В итоге: проводите бенчмарки реальных баз, тогда вы и получите конкретные цифры производительности, а синтетика не про точные цифры, а про поведение при различных профилях нагрузки на конкретном оборудовании.
На RAMDISK добрые люди уже проверили: https://habr.com/ru/post/694554/
По wait я ответил тут https://habr.com/ru/post/697504/comments/#comment_24886618, по поводу RAMDISK на который Вы предлагаете поместить Transaction log чтобы была "чистота" эксперимента хочу спросить - Вы сами приведенную ссылку https://habr.com/ru/post/694554/ читали? Видели что там RAM диск проиграл SSD на записи особенно? Если многие хотят убедится что проблема не в диске, RAM это эталон. Ок я могу прогнать это на RAM , давайте ссылку на RAM DISK который
а) Можно скачать для win 2016 бесплатно хотябы на триальный период
б) Диспетчер позволяет обслуживать много потоков.
Последнее поясню, сейчас часто пишут ПО которое не использует многоядерность по факту. Т.е. диспетчер ram садится на одно ядро и как только оно загрузится вся скорость превращается в тыкву.
Сайзингу ssd в спецификациях верить нельзя, счетчикам ос тоже (и это без всякой виртуализации!
а что счётчики ос?
вот смотрите, вы пишете:
В момент возникновения очереди закономерно растет Avg.Disk sec/transfer (желтый).
понятное дело, что вас внешняя полка (что для нагруженных БД не очень интересно на мой взгляд), но даже с учётом этого задержки чрезмерно велики.
у меня, если честно, в голове не укладывается, как вы можете глядя на задержки в/в в 0.1с говорить, что дисковая подсистема справляется. это даже для hdd много, а для ssd это на три порядка (!!!) выше задержек накопителя.
понятное дело, что эта ваша msa по сегодняшним временам выглядит уныло, на чтение она всего лишь немного быстрее одиночного sata-диска, а на запись так вообще медленнее, но всё равно результат слишком плохой. уж не гигабитным ли iscsi у вас подключен сервер к схд?
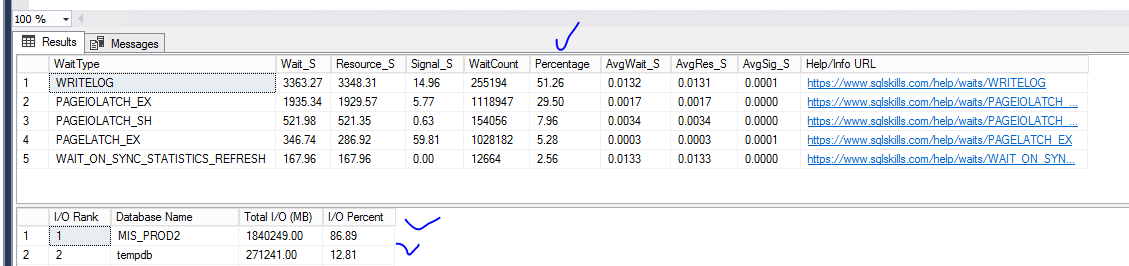
Ответ для @edo1h и @borovinskiy ниже картика waits со стороны SQL для SSD raid на MSA2040 где проводился тест. Raid1 . Для понимания нужно применить синтез анализ и сравнение.
Факт 1 - AvgWait_Second показывает среднее время задержки которое включает в том числе работу подсистем SQL на для выполнения операции. Т.е. не только SSD, контроллер (Fibre channel) , а еще работу процессов самого MS SQL
Факт 2
Write log получился 0.0132 это много
Но PageIoLatch (файлы данных СУБД) - от 0.0017 до 0.0034
Применяем сравнение - странно почему на одном рейде такая разница если эти две подсистемы SQL пишут в одно место? Из за разных размеров блока?
Ну хорошо - повторю тест уменьшив число параллельных потоков в 2 раза
Вау - задержка на writelog уменьшилась в 2.5 раза. Как так ? Он же пишет одинаковыми блоками.
Синтез - Может быть не в дисковой системе проблема? Про ram диск отвечу отдельно

уменьшили нагрузку на дисковую подсистему в 2 раза, после чего задержки упали в два раза.
вы делаете вывод:
Может быть не в дисковой системе проблема?
гхм… какая-то у вас странная логика:
Факт 1 — AvgWait_Second показывает среднее время задержки которое включает в том числе работу подсистем SQL на для выполнения операции. Т.е. не только SSD, контроллер (Fibre channel), а еще работу процессов самого MS SQL
я сужу по скриншоту метрик дисковой подсистемы: у вас слишком высокие задержки:
https://hsto.org/getpro/habr/upload_files/552/3d1/08b/5523d108beb3a69082fa500c8d15239c.PNG
Сайзингу ssd в спецификациях верить нельзя
ну не то что верить нельзя, но нужно внимательно читать. а лучше перепроверять.
если можете, попробуйте поставить fio и запустить такой ps-скрипт:
$fio="C:/Program Files/fio/fio.exe"
$testfilepath="e:/mssql/"
$testfilename="fio-testfile"
$testfilesize=4*1024*1024*1024
function Do-Fio {
echo "`n$args"
& $fio --name=test --filename="$testfilename" --direct=1 --randrepeat=1 --group_reporting --time_based --runtime=15 $args | Select-String -CaseSensitive iops
}
cd $testfilepath
fsutil file createnew $testfilename $testfilesize
echo "`ntest file location: $testfilepath$testfilename"
Do-Fio --numjobs=1 --iodepth=1 --readwrite=randwrite --bs=4m
Do-Fio --numjobs=1 --iodepth=1 --readwrite=randwrite --bs=4k
Do-Fio --numjobs=16 --iodepth=16 --readwrite=randwrite --bs=4k
Do-Fio --numjobs=1 --iodepth=1 --readwrite=randwrite --bs=4k --sync=1
Do-Fio --numjobs=1 --iodepth=1 --readwrite=randread --bs=4k
Do-Fio --numjobs=16 --iodepth=16 --readwrite=randread --bs=4k
Do-Fio --numjobs=1 --iodepth=1 --readwrite=randread --bs=4m
rm $testfilename(пути в первых строчках, разумеется, надо заменить на актуальные для вас)
вот что у меня выдал локальный nvme:
test file location: e:/mssql/fio-testfile
--numjobs=1 --iodepth=1 --readwrite=randwrite --bs=4m
iops : min= 586, max= 598, avg=592.55, stdev= 3.33, samples=29
--numjobs=1 --iodepth=1 --readwrite=randwrite --bs=4k
iops : min=30126, max=36428, avg=34761.83, stdev=1947.73, samples=29
--numjobs=16 --iodepth=16 --readwrite=randwrite --bs=4k
iops : min=245986, max=295098, avg=273224.90, stdev=626.61, samples=464
--numjobs=1 --iodepth=1 --readwrite=randwrite --bs=4k --sync=1
iops : min=33034, max=35732, avg=34938.79, stdev=689.49, samples=29
--numjobs=1 --iodepth=1 --readwrite=randread --bs=4k
iops : min=24644, max=25798, avg=25237.48, stdev=263.65, samples=29
--numjobs=16 --iodepth=16 --readwrite=randread --bs=4k
iops : min=285460, max=354456, avg=321725.03, stdev=1054.36, samples=464
--numjobs=1 --iodepth=1 --readwrite=randread --bs=4m
iops : min= 252, max= 262, avg=257.83, stdev= 2.83, samples=29P. S. знатоки ps тут есть? почему после первой строки --numjobs… идёт пустая строка?
Ответ вероятно очень прост: запись в журнал однопоточная. Когда вы уменьшили в 2 раза число потоков, вы уменьшили нагрузку, вот задержка и уменьшилась. Ну а как многопоточно писать в файл журнала еще с гарантией согласованности, если не одним потоком? Ну по крайней мере в MySQL запись точно однопоточная, а про MS SQL не знаю.
Вообще тезис можно перевернуть: когда увеличение числа потоков записи не изменяет задержку? Тогда, когда дисковая система не нагружена, в нее ты пишешь больше и она прожевывает. А когда с ростом потоков растет задержка - это говорит, что внутри хранилки вы во что-то уперлись и там очередь создается. Отправили в два раза больше нагрузки, она в два раза дольше пишется - это же явный признак бутылочного горлышка.
Это совсем не так, особенно в MS SQL 2019 который я использую
Во первых в MS SQL Flush лога асинхронный
Во вторых есть официальный документ Troubleshoot slow SQL Server performance caused by I/O issues - SQL Server | Microsoft Learn
Prior to SQL Server 2016, a single Log Writer thread performed all log writes. If there were issues with thread scheduling (for example, high CPU), both the Log Writer thread and log flushes could get delayed. In SQL Server 2016, up to four Log Writer threads were added to increase the log-writing throughput. See SQL 2016 - It Just Runs Faster: Multiple Log Writer Workers. In SQL Server 2019, up to eight Log Writer threads were added, which improves throughput even more. Also, in SQL Server 2019, each regular worker thread can do log writes directly instead of posting to the Log writer thread. With these improvements,
WRITELOGwaits would rarely be triggered by scheduling issues.
Я как нибудь соберусь опубликую результаты со всеми оптимизациями Transaction log
RAM диск проверю если ктото подгонит диск с правильным диспетчером ориентированным на многопоточность
В качестве вывода: да, большое количество запросов на запись отрицательно сказывается на скорости этой записи, здесь можно ускоряться, но на самом деле причина такой работы находится в архитектуре СУБД, которая до сих пор оптимизирована для работы с жесткими дисками и пишет в журнал с частыми flash-ами
Основной посыл статьи в том, что в СУБД для производительности рекомендуют использовать один крупный dml опрератор insert update delete вместо 10 мелких. Но реализация современных orm нацелена на создание 10 мелких dml вместо одного крупного. А поскольку СУБД это разделяемый ресурс Orm следует подстраивать идеологию под СУБД а не наоборот
СУБД для производительности рекомендуют использовать один крупный dml
опрератор insert update delete вместо 10 мелких. Но реализация
современных orm нацелена на создание 10 мелких dml вместо одного
крупного
Вы сами выше писали про JDBC batch, но потом как-то невнятно от него отказались. А между тем, он как раз и компонует несколько мелких запросов в один большой. Так что с этой стороны в нормальных ORM всё хорошо.
Batch - это всего лишь выполнение группы DML за одно обращение к СУБД. Радикально он ничего не меняет.
А речь, в качестве очень упрощенного примера, о замене сотни
INSERT ... SELECT ... WHERE Id=<something>
на один
INSERT ... SELECT ... WHERE Id IN (<something>)
То бишь, в первом случае будет сотня записей в журнал транзакций, а во втором - только одна. И это не считая прочих издержек.
Во первых, батч выглядит по другому, примерно так:
Вместо insert into xxx values (1,2,3) будет insert into xxx values (1,2,3), (4,5,6), (7,8,9), ...
То есть БД получит всё необходимое для любых оптимизаций.
Соответственно, во вторых, вместо сотни отдельных актов записи в журнал транзакций будем иметь один акт, включающий все данные. А раз запись на диск одна, то и время сокращается очень существенно, примерно как вы бы и могли ожидать, но почему-то сочли невозможным.
Хотя стоит признать, что умение оптимизировать батчи свойственно не всем СУБД.
Вы привели только еще более простой пример, а потому менее показательный. Если вставляемые в таблицу строки идут с клиента, то они были введены вручную, а значит их немного и оптимизировать нечего. Если бы их было много, то при любых раскладах речь бы шла о INSERT BULK или, в крайнем случае, BULK INSERT.
А к реальным задачам мой пример намного ближе, так как запрашивать данные по сети от сервера клиенту, чтобы их же потом, пусть даже после трансформации, вставлять в таблицу на том же сервере - крайне неэффективно. А на больших объемах данных - вообще не реально.
Ну и я не знаю ни одной СУБД, которая умеет оптимизировать пакеты DML запросов. Хотя бы один пример привели бы.
В статье Торбена не показан сам итоговый оператор dml который сделал batch показан только улучшенный результат выполнения. Хотя итересно посмотреть trace. Но это не так важно. Если документ или набор записей как обьект, который Вы пишите состоит из двух таблиц и вы пишите Doc1 Doc2 последовательно - jdbc batch не сможет их консолидировать. У Торбена более простой тест.
Еще я думаю что jdbc batch будет узким местом при параллельной генерации запросов в рамках даже одного сервера приложений javaee . Это сколько вычислений нужно провести чтобы разгрести то что настрочил ORM
Да методу AddBatch() вообще безразлично, какое именно SQL предложение добавляется в пакет.
Он просто группирует все запросы в один пакет, что сокращает накладные расходы при обращении к БД. А с точки зрения БД, от клиента всегда приходит пакет. Просто, в частном случае, он может содержать только одно SQL предложение. А в общем случае - сколько угодно и каких угодно, за редкими исключениями, когда какое-то SQL предложение допустимо только в начале пакета.
Две таблицы отображаются на два набора объектов, для каждого набора отдельно генерируется dml, затем два dml в режиме batch идут в БД. Всё прекрасно ускоряется.
Параллельная обработка примерно так же - ничего страшного там нет, пройтись по списку объектов очень легко. Возможно, вы имели в виде работу нескольких клиентов, но их запросы ни в коем случае нельзя объединять в один, так что с этой стороны опять всё обстоит так, как должно.
Большинство мифов про страшный ORM базируется на непонимании как внутренней механики сабжа, так и на непонимании цели, ради которой вообще что-то пишут в БД, Если же понимание есть, то всё отлично оптимизируется. В крайнем случае, если реально упёрлись в недостатки ORM, то грамотный разработчик легко напишет оптимизированный SQL. Но до ограничений ORM чаще всего далеко. Главное ограничение - молодые разработчики.
Во-первых, Вы какую-то детскую задачу описываете. На практике же, обычно, есть сложный запрос (c CTE, рекурсиями, оконными функциями и т.п), возвращающий миллионы строк и есть задача, результат этого запроса вставить в таблицу. И на всех ORM, которые я знаю, такая задача решается очень неэффективно.
Во-вторых, объединяя два DML в один пакет, вы экономите только на накладных расходах одного пакета, что очень и очень немного. И ни одна СУБД, которые я знаю, не будут исполнять два DML в одном пакете параллельно. Строго последовательно. Можете убедиться в профайлере.
В-третьих, удел ORM - десятки и сотни записей. Ну максимум тысячи. На миллионах ни одной эффективной ORM я не встречал. Тем более, на миллиардах, с которыми я регулярно сталкиваюсь.
грамотный разработчик легко напишет оптимизированный SQL
Вашими бы устами, да мёд пить. Я уже не один десяток лет занимаюсь оптимизацией SQL запросов и процедур. И "легко" это не было ни разу. На практике, как только у разработчика на C#/1C/X++/ABAP/Python и т.п. возникает задача оптимизации SQL, эффективней отдать эту задачу специалисту по SQL, оформить в виде VIEW, функции или процедуры, и пусть уже этим первый разработчик пользуется.
В плане "обычно" как раз есть много очень простых запросов. Ваш же пример с миллиардами (!!!) записей является редчайшим исключением.
Про объединение в пакете - каждый dml уже содержит требуемые от нас сотни записей, поэтому со стороны бд нет никаких проблем его исполнить с одной записью на диск. В оракле есть insert all, в mysql есть возможность напрямую указывать множественные значения, это всё к тому, что разработчики СУБД уже подумали о таком варианте использования и сделали необходимые синтаксические конструкции, а значит они просто обязаны были подумать и о собственно исполнении этих конструкций. Поэтому два dml по 1000 записей дадут нам две записи на диск (во время транзакции, а во время коммита может ещё много чего писаться, здесь я не спец).
Про "удел ORM" согласен. Но в тексте статьи речь шла о сотнях записей, так что всё опять уместно. Хотя в батчах и тысячи легко пойдут.
По разделению труда между базистами и программистами тоже в принципе согласен, но одно дело, когда на каждого программиста нужно по базисту нанимать, и совсем другое, когда большую часть оптимизаций программисты делают сами, что избавляет нас от раздувания (дорогих) штатов. Так что здесь опять нужно просто внимательно смотреть на проблему - есть экономия или нет. Может ваши миллиарды записей действительно требуют спеца по имеющейся в конторе СУБД ради реально нужных и сложных оптимизаций, но в большинстве случаев привлекать дополнительного базиста нет необходимости просто из-за достаточной грамотности обычных программистов. А вот если там набрали молодёжь и они пишут что-то более или менее сложное без проверки старшими товарищами, то да, быстро возникнет потребность всё это оптимизировать.
Я же явно написал, для меня обычно. Так как уже лет десять не только крупный, но и средний, а порой и мелкий бизнес, заинтересован в прогнозировании, оптимизации и прочих задачах, которые решаются с использованием миллиардов записей. Ну а миллионы - это вообще нормальное явление даже для 1С. Мне тут недавно тут доказывали, что 1С спокойно справляется с 200 тыс. документами в день. Сколько это будет при закрытии месяца?
каждый dml уже содержит требуемые от нас сотни записей
В Вашем то примере с INSERT ... VALUES ... ? Не похоже. По одной вижу.
разработчики СУБД уже подумали о таком варианте использования и сделали необходимые синтаксические конструкции
Вот с этим я полностью согласен. Но я же именно об этом и писал. Что средствами SQL обрабатывать миллионы записей - не проблема. А средствами ORM?
По разделению труда между базистами и программистами тоже в принципе согласен, но одно дело, когда на каждого программиста нужно по базисту нанимать
Не утрируйте. На большинстве проектов у меня хватало одного специалиста по SQL. Естественно, были и исключения. Зависит от проекта. На оптимизационных задачах и прогнозировании бывало и наоборот, что на одного full-stack разработчика приходилось до трех специалистов по SQL. Но там и задачи специфичные. Как раз уже с миллиардами записей, которые надо фильтровать, чистить, трансформировать и только потом скармливать моделям.
Я вот только не пойму, зачем вам в data science нужен ORM? Стоило из-за него вообще что-то начинать, когда он принципиально для другой области?
Плюс миллиард даже вам будет нужен редко, потому что нормальная практика давно уже предполагает агрегирование промежуточных данных, а это уже даже не миллионы, а уже где-то тысячи, ну пусть десятки тысяч. Без агрегирования же вы сначала новую модель придумать должны, и только потом чего-то там ей скормить. То есть опять нечасто.
Не похоже. По одной вижу.
Есть принципиальная возможность, поддерживаемая на уровне языка БД, поэтому я и говорил про оптимизацию на стороне БД. Она тривиальная, вы даже сами о ней знаете, но почему-то предпочитаете возражать. Поступление хоть миллиона инсертов в одну таблицу очень (очень!) легко выявить и обработать.
Вообще, конечно нужен чистый эксперимент. Я чистого не делал, но обычно мои запросы (через ORM) были достаточно производительными для задачи и потому не было нужды дальше оптимизировать. Но если вы принципиально не согласны, то что мешает написать простейший кусок кода в цикле создающий тысячу объектов, а потом скормить эти объекты например hibernate? Для уверенности добавьте внешний цикл шагов на 100, пусть среднее время покажет. Да даже без ORM ведь тривиально - написать инсерт и в цикле его с батчем прогнать, а потом без батча. Тогда будет обоснованное мнение.
средствами SQL обрабатывать миллионы записей - не проблема. А средствами ORM?
Средства ORM служат для ускорения написания кода, а не для ускорения выполнения программы. Но в среднем на стандартных задачах ORM не сильно отстаёт от чистого SQL. На специфических же, разумеется, универсальный инструмент хуже, чем специализированный, тоже давно известная истина.
Я вот только не пойму, зачем вам в data science нужен ORM?
Потому что и для Data Scince необходим пользовательский интерфейс. Там и живет ORM.
Плюс миллиард даже вам будет нужен редко, потому что нормальная практика давно уже предполагает агрегирование промежуточных данных
Естественно, например, из полутора миллиардов исходных данных получается несколько десятков тысяч временных серий, с длиной всего по 300-400 значений. Вот только чем, спрашивается, выполнять эту трансформацию, как не SQL? Надо чистить данные от явно некорректных записей по ряду признаков. Затем надо фильтровать их, например, медианным фильтром и/или скользящим средним (как обычным, так и назад-смотрящим), и только потом агрегировать (медианой, средним по двум квартилям или еще как). При этом еще имеем ворох справочников, в которых пользователь может указать, например, признаки, по которым событие или даже целый ряд событий должны исключаться из обработки. Или наоборот, управляет весом каких-то событий. В комментарии я могу только очень упрощенно написать о том, как выглядит трансформация, для того, чтобы получить данные приемлемые для обучения модели. Это тема уже для целой статьи, а может и не одной.
Поступление хоть миллиона инсертов в одну таблицу очень (очень!) легко выявить и обработать.
Просто это никому не нужно, так как любая СУБД поддерживает массовую загрузку данных. Для MS SQL - это INSERT BULK (предпочтительно) и BULK INSERT (если деваться некуда).
А если нужно вставить сто записей в одну таблицу, то писать сто INSERT ... VALUES (...), вместо одного INSERT ... VALUES (...), (...) ... (...) - граничит с идиотизмом )))
А в одном пакете могут быть вообще-то почти любые DML и DDL предложения. Их то как прикажете СУБД оптимизировать?
Вообще, конечно нужен чистый эксперимент.
А зачем? Он уже 100500 раз проводился. Сравните производительность INSERT BULK (хотя бы загружая данные bcp, которая именно им и пользуется) и любым другим способом. Обнаружите кратную разницу в производительности. Лично я на C#, даже 100 записей вставлять буду INSERT BULK, благо готовый класс SqlBulkInsert доступен их коробки.
И совсем другое дело, если мне действительно нужно в цикле по курсору вставлять в одной транзакции по одной записи и необходимо по ROLLBAK все модификации, в случае чего, откатить. Но это уж точно не последовательность INSERT ... VALUES, а куда более сложный код.
Средства ORM служат для ускорения написания кода
Я вообще-то с этого и начинал:
С одной стороны, ORM позволяет существенно снизить стоимость разработки, которая, обычно, существенно выше стоимости железа. С другой стороны, опыт показывает, что "золотых молотков" не бывает.
писать сто INSERT ... VALUES (...), вместо одного INSERT ... VALUES (...), (...) ... (...) - граничит с идиотизмом )))
Здесь стандартная проблема наибольшего общего деноминатора. ORM должен работать с максимальным количеством БД, поэтому деноминатор в виде относительно древнего стандарта SQL неизбежен. Но с другой стороны batch предназначен именно для ускорения, не смотря на то, что принимает он всё подряд в любой последовательности. То есть ORM базируется на идее эффективного выполнения batch. А уж как конкретно написан этот батч, зависит от реализации библиотек языка, где батч задействован. Но было бы просто глупо сделать в языке батч и не выделять в нём инсерты в одну и ту же таблицу. Зачем тогда вообще он нужен? Вот поэтому выбранный в ORM подход правильный - может кто-то сдуру и сделает дебильный батч, но в среднем по больнице он всё же будет более или менее оптимальный. Так что идиотизма там нет, но есть вполне разумная логика.
А в одном пакете могут быть вообще-то почти любые DML и DDL предложения.
Сортировка по типу (update, insert, delete) и по целевой таблице. Что тут сложного?
А зачем?
В нашем случае - для спортивного интереса. Попадётся мне задача со вставкой большого количества записей - попробую. Потому что так будет ликвидировано сомнение.
Здесь стандартная проблема наибольшего общего деноминатора. ORM должен работать с максимальным количеством БД
Не вижу никакого смысла поддержки БД до стандарта 1992 года, в котором конструкция VALUES (...), (...) ... (...) уже была. Более ранние стандарты не смотрел.
Сортировка по типу (update, insert, delete) и по целевой таблице. Что тут сложного?
Во-первых, в ссылочной целостности, так как поля целевой таблицы могут ссылать на первичные ключи других таблиц, которые к моменту INSERT/UPDATE должны быть. И наоборот, другие таблицы могут ссылаться на первичный ключ целевой таблицы и к моменту DELETE/UPDATE таких ссылок уже быть не должно.
Во-вторых, СУБД без понятия, что и где может модифицировать триггер в одной из нецелевых таблиц в целевой таблице.
В-третьих, есть такие сущности, как IDENTITY, SEQUENCE и т.п., которые не смогут обеспечить строго возрастающие значения, так, как хотел разработчик, если выполнять DML предложения не в том порядке.
В нашем случае - для спортивного интереса.
Так сравнивали уже не раз. INSERT BULK (SqlBulkCopy и Table Valued Parameter) выигрывает с большим отрывом. Например:
https://timdeschryver.dev/blog/faster-sql-bulk-inserts-with-csharp
до стандарта 1992 года, в котором конструкция VALUES (...), (...) ... (...) уже была
Не знаю, насчёт была она там или нет, но знаю, что оракл в 12-й версии её не поддерживал, так что ваши пожелания отправляйте им - они виновники.
Во-первых, Во-вторых, В-третьих...
Всё это актуально и для bulk insert, а потому давно решено. Ссылки ищут одним и тем же алгоритмом, независимо от количества ссылок. Триггеры чаще всего отсутствуют, а если присутствуют - простые. Только в каких-то там тысячных долях случаев триггеры есть и сложные, тогда БД всё делает последовательно и без оптимизации, но в 999 из 1000 случаев этого не бывает. Sequence так же без разницы, какой диапазон отдать, это одна операция и никак более ни на что серьёзное не влияет.
https://timdeschryver.dev/blog/faster-sql-bulk-inserts-with-csharp
Здесь проверка только на стороне сервера. Есть ещё клиент с его батчами. Сервер, как показывает тест, легко справляется с тривиальной оптимизацией. И даже bulk insert не сильно улучшает ситуацию в сравнении с множественным инсертом, там возможно на парсинг время уходит. Остальное осталось за кадром - кто и как реально оптимизирует. Скорее всего, серверу вообще не нужна информация от клиента о наличии батча, поскольку очевидно, что её сервер может собрать сам, тогда вообще весь разговор про "неправильный ORM" окажется полностью некорректным. И это наиболее вероятный вариант, хотя в тесте он не отражён явно, поэтому не 100% уверенности.
И да, перец из статьи по ссылке забыл нам рассказать, какую СУБД он использовал. Или у шарпистов по умолчанию всегда ms sql?
оракл в 12-й версии
Просто у Oracle, как и во ряде иных случаях, синтаксис отклоняется от стандарта. Просто тоже самое в нем делается через INSERT ALL. Какая разница?
Всё это актуально и для bulk insert, а потому давно решено.
Во-первых, пользоваться BULK INSERT не рекомендую, это устаревший костыль с кучей ограничений и более низкой производительностью, чем INSERT BULK.
Во-вторых, если надо вставить несколько записей в одну таблицу, то и не пользуйтесь INSERT ... VALUES. А вот если порядок вставки зависит от той же ссылочной целостности или SEQUENCE, во тогда INSERT ... VALUES может потребоваться. Например, в цикле по курсору.
Ссылки ищут одним и тем же алгоритмом, независимо от количества ссылок.
Вы вообще о чем? Как их искать, если в начале выполнения пакета их может еще не быть? Более того, первичный ключ может быть IDENTITY, а значит, будет известен только после завершения INSERT/MERGE из их OUTPUT.
Триггеры чаще всего отсутствуют
Если на железнодорожной ветке поезда "чаще всего отсутствуют", приляжете ли вы поспать там, положив голову на рельсы?
Sequence так же без разницы
В ряде случаев, может быть очень большая разница. Например, сохранение порядка полученных показаний с датчика, даже если они пришли в одну миллисекунду, может быть необходимо.
Здесь проверка только на стороне сервера.
Прочитайте внимательней. Код на C#, всегда выступает в качестве клиента, даже в CLR по context connection.
И даже bulk insert
В статье BULK INSERT даже не пробовали. Только INSERT BULK.
серверу вообще не нужна информация от клиента о наличии батча, поскольку очевидно, что её сервер может собрать сам
Не может. Именно для явного разделения пакетов и используется не SQL оператор GO в SSMS, SQLCMD и т.п. Во-первых, потому что есть ряд SQL предложений, которые обязаны быть в пакете первыми. Во-вторых, для локализации переменных, так как область видимости DECLARE - пакет.
какую СУБД он использовал
Достаточно ссылок на используемые им классы и методы, ведущие на сайт microsoft.com
Если бы мы затронули не только MS SQL, а еще и PostgreSQL, то я бы упомянул о volatile функциях.
Если честно, я уже перестаю понимать ход Ваших мыслей. То, что для вставки нескольких строк в одну таблицу можно и нужно пользоваться INSERT BULK я уже указал. Если используется INSERT ... VALUES - значит разработчику именно это и требуется. В обоих случаях какое-либо переупорядочивание SQL предложений или не нужно или недопустимо.
В статье я привел пример с 1 миллионом документов в день под каждым 5 движений\проводок (в объектом смысле) , а каждое движение если посчитаете требует 4 последовательных DML операции . Т.е. 20 миллионов DML . Это реально даже в 1С. Обычное такое перепроведение за день
И если для реляционных СУБД в мануалах (точно для Oracle и Microsoft) просят использовать более крупные DML вместо 10 маленьких то и ORM следует реализовывать эти особенности СУБД. А мы видим другое, библиотеки ORM реализуют так как будто они предназначены для дохлых объемов. А ведь всего нужно при проектировании чтобы findById(ID id) позволял искать по списку ID, saveAll(Iterable<S> entities) создавал один DML для каждой таблицы а не кучу маленьких.
1С с таким подходом уже получает результаты - популярность системы возрасла( кстати за счет удобства ORM) , а попытки применения на больших объемах сразу показывают горизонты. И если сразу в библиотеке нет идеологии правильного использования это и любое другое решение ждет
20 миллионов DML
Раз в день этот объём, даже неоптимальным образом исполненный, будет вполне по силам любой СУБД.
ORM следует реализовывать эти особенности СУБД
Выше отвечал - если реализация batch не от группы идиотов, то никаких проблем не будет.
чтобы findById(ID id) позволял искать по списку ID, saveAll(Iterable
entities) создавал один DML для каждой таблицы а не кучу маленьких
findById как раз по списку и ищет. saveAll вы можете руками допилить, на то он и враппер. Но повторюсь - маленькие dml наверняка агрегируются, потому что ms sql всё же довольно старая СУБД и было бы удивительно, если они такую тривиальную оптимизацию до сих пор не сделали.
а попытки применения на больших объемах сразу показывают горизонты
Не знаю про 1С, возможно дело в кривом драйвере, отправляющем на сервер запросы без batch-a.
если сразу в библиотеке нет идеологии правильного использования это и любое другое решение ждет
Идеология ORM везде одна. Вопрос только к конкретной реализации. Со стороны БД наверняка возможность есть, а что там одноэсовцы намутили со своей стороны - ну кто-ж этих умников знает? Хотя вы можете провести предложенное выше простой тестирование и сравнить. Правда не удивлюсь, если в 1С забыли вообще выставить наружу возможность включить batch.
У Вас есть по другой правильный Batching который корректно отработает ситуацию? Язык и ORM не важен, И показать трассировку на любой СУБД
insert tab1
insert tab2
insert tab1
insert tab2
insert tab1
insert tab2
insert tab1
insert tab2
Здесь ответ на те сложности, которые могут показаться неустранимыми, но на самом деле очень просты.
Трассировку не покажу, потому что нужно тратить приличное время. Если нет сложных (для автоматического разбора) триггеров, то трассировка и не нужна - БД сумеет оптимизировать. Примеров в сети много, правда скорее всего не всем вашим критериям они смогут удовлетворить. Но если вам это важно - ничто не мешает провести собственное расследование с важным для вас набором критериев. Принципиально смешанная последовательность, при соблюдении простых условий (присутствующих в 99,9% случаев), ничем не отличается от однородной.
Хорошо, на пальцах. Имеем такие таблицы:
CREATE TABLE t1 (
id int IDENTITY(1,1) NOT NULL,
name nvarchar(255) NULL,
CONSTRAINT PK_t1 PRIMARY KEY CLUSTERED (id))
CREATE TABLE t2 (
id_t1 int NOT NULL,
line_id int NOT NULL,
some_value nvarchar(max) NULL,
CONSTRAINT PK_t2 PRIMARY KEY CLUSTERED (id_t1, line_id),
CONSTRAINT FK_t2_t1 FOREIGN KEY (id_t1) REFERENCES t1(id))И такой пакет:
DECLARE @t1_id TABLE (id int)
INSERT t1(name) OUTPUT INSERTED.id INTO @t1_id VALUES ('blablabla1')
INSERT t2(id_t1, line_id, some_value) VALUES ((SELECT TOP 1 id FROM @t1_id), 1, 'blablabla1-1')
INSERT t2(id_t1, line_id, some_value) VALUES ((SELECT TOP 1 id FROM @t1_id), 2, 'blablabla1-2')
DELETE @t1_id
INSERT t1(name) OUTPUT INSERTED.id INTO @t1_id VALUES ('blablabla2')
INSERT t2(id_t1, line_id, some_value) VALUES ((SELECT TOP 1 id FROM @t1_id), 1, 'blablabla2-1')
INSERT t2(id_t1, line_id, some_value) VALUES ((SELECT TOP 1 id FROM @t1_id), 2, 'blablabla2-2')
DELETE @t1_id
...Как Вы предлагаете его переупорядочить?
Да, такой вариант оптимизатор большинства БД наверняка сочтёт неоптимизируемым и БД выполнит его строго последовательно, по одной записи на каждый инсерт. Но это не значит, что все запросы имеют подобный характер. Я же писал про 99%. Да, вы можете придумать запрос из группы 0.1%, но что это доказывает?
Но, с другой стороны, даже ваш запрос некоторые оптимизаторы могут улучшить. Разработка оптимизаторов такого уровня, разумеется, не для массовых СУБД, а в массовых, возможно, оптимизатор сумеет объединить в один инсерт каждую пару для t2. Принципиально там применим вполне стандартный алгоритм, особенно если оптимизатор знает, что в пределах одной транзакции временную таблицу никто не видит. Ну а дублирующийся селект например даже mysql вообще легко оптимизирует просто запоминая результат, я уж не говорю про оракла или ms sql.
Ну а дублирующийся селект например даже mysql вообще легко оптимизирует просто запоминая результат
The query cache is deprecated as of MySQL 5.7.20, and is removed in MySQL 8.0.
https://dev.mysql.com/doc/refman/5.7/en/query-cache.html
Default Value: OFF
https://mariadb.com/kb/en/server-system-variables/#query_cache_type
что это доказывает?
То, что даже если Вы такой "оптимизатор" напишете, то он никому не будет нужен, так как с ним уже существующий код перестанет работать. Да и в этом случае, более правильно производить такую "оптимизацию" на клиенте, а не в СУБД. Хотя бы с той точки зрения, что СУБД часто является бутылочным горлышком в ИС и не стоит нагружать ее тем, что может быть выполнено на клиенте. И снова возвращаемся к тому, что не надо проблемы ORM сваливать на СУБД. Пусть разработчики ORM сами решают свои проблемы.
ваш запрос некоторые оптимизаторы могут улучшить
Какой ценой? Сравните время компиляции GCC с -O0 и -O3. Разница будет в 6-7 раз. А GCC при этом выполняет куда более простую оптимизацию, чем хотите Вы.
возможно, оптимизатор сумеет объединить в один инсерт каждую пару для t2
А если бы в t2 тоже был IDENTITY и для дальнейшей обработки важно, чтобы он возрастал с возрастанием номера строки и никак иначе?
Разработчик и так может объединить несколько строк в один DML. И если он так не сделал - значит на то были причины. Не надо принимать решения за разработчика.
дублирующийся селект например даже mysql вообще легко оптимизирует просто запоминая результат, я уж не говорю про оракла или ms sql.
Были такие безуспешные попытки. Сейчас, насколько я знаю, от этого повсеместно отказались. План запроса - кешируется. Результат запроса - нет. Слишком много для этого ограничений и слишком большие накладные расходы при очень малой отдаче. Это же, по сути, на все таблицы БД надо CDC включить и отдельным сервисом отслеживать (что совсем не просто), не изменились ли данные в таблицах, используемых кешированным запросом. А профита никакого, кроме поддержки кривых рук, зачем-то посылающих в БД одинаковые запросы. Если действительно надо сохранить результат запроса для дальнейшего использования - пользуйтесь материализированными представлениями, отдавая себе отчет, что в общем случае, данные в них не актуальны.
с ним уже существующий код перестанет работать
Оптимизация всегда производится прозрачно для использующей её стороны. Если же оптимизатор меняет результат алгоритма, ожидаемый разработчиком (а только тогда код перестанет работать), то это означает ошибку в коде оптимизатора. То есть с нормальным оптимизатором всё будет работать.
Какой ценой?
Стоимостной анализ придумали сотни лет назад. Автоматизировали десятки лет назад.
А профита никакого, кроме поддержки кривых рук, зачем-то посылающих в БД одинаковые запросы
То же самое можно сказать про SQL - профита никакого, кроме кривых рук, ленящихся писать специфические для каждой БД запросы сразу в машинных кодах.
Вообще, я не понимаю, зачем вы упорствуете и встаёте на пути прогресса? Оптимизаторы есть. Они развиваются. Если вам в их применении кажется что-то сложным, это совсем не значит, что от оптимизаторов нужно отказаться. Ну а конкретно в случае с ORM ваша собственная ссылка выше показывает, что существенной разница между универсальным множественным инсертом и специализированным для конкретной субд очень мала, соответственно, упрощение работы по созданию ORM вполне приемлемо, поскольку БД умеет оптимизировать неидеальное поведение ORM.
Хотя да, если бы все вещи на свете были бы идеальными, то я был бы только рад. Но мир так устроен, что эффективнее оптимизировать на стороне нескольких известных БД, нежели в сотнях (а то и тысячах) ORM.
Когда-нибудь ORM подтянется, но сейчас это просто неактуально. Возражения же скорее показывают нам этакое старческое брюзжание (независящее от возраста), вечное недовольство тем "какая молодёжь нынче пошла", а затем следует ожидать чего-то вроде "вот в наши-то годы...". Примите мир таким, какой он есть. Или улучшите сами. Не получается? Тогда почему вы вините других, а себе разрешаете быть неидеальным? И не оправдывайтесь другой сферой интересов, потому что в итоге все мы - население одного маленького шарика, и если кто-то на шарике отлынивает, находя очень веские оправдания, то почему то же самое не может сделать другой?
Оптимизация всегда производится прозрачно для использующей её стороны.
Значит в данном случае Вы ее или не сделаете, или затраты на семантический анализ окажутся неприемлемы.
Вообще, я не понимаю, зачем вы упорствуете и встаёте на пути прогресса?
А я не вижу тут прогресса. Я вижу попытку оптимизировать 0.1% операций с БД ценой затрат на семантический анализ остальных 99.9% операций. Причем при этом любая СУБД из коробки предоставляет простой и прямой путь оптимизации этих 0.1% операций.
Если Вас так волнует оптимизация, то лучше займитесь оптимизацией при построении планов запросов. Вот тут широчайший простор для академической деятельности.
эффективнее оптимизировать на стороне нескольких известных БД, нежели в сотнях (а то и тысячах) ORM.
Докажите. Чем лучше увеличивать нагрузку на сервер, обслуживающий тысячи клиентов, а не наоборот, переносить нагрузку на клиентов?
Вообще то, разговорным языком это называется перекладыванием с больной головы на здоровую. Вы же, по сути, открытым текстом заявляете: "Я без объяснения причин отказываюсь пользоваться массовой вставкой данных, и хочу, чтобы сервер сам догадывался, когда мне эта массовая вставка нужна". Так если сами отказываетесь, то и делайте сами то, от чего отказываться не будете. Заводите проект на github, пишите семантический анализатор и пользуйтесь им у себя на клиенте перед отправкой пакета серверу. Лично я не только не вижу смысла в таком семантическом анализаторе, но вижу его вред в увеличении времени обработки запросов и появлению новых сложностей в разработке, отладке и поддержке.
А я не вижу тут прогресса.
Прогресс в оптимизаторах.
вижу попытку оптимизировать 0.1% операций с БД ценой затрат на семантический анализ остальных 99.9%
Анализ (чаще всего не семантический) производится всегда. Вопрос лишь в его полноте. Полноту постепенно подтягивают, добавляя те или иные дополнительные варианты. Если вариант достаточно общий, то внезапно становится простым то, что раньше казалось сложным (затратным по времени). На а, например, граф изменений, который вы задали в своём примере, как раз и укладывается в общий подход по работе с такими графами. Вся сложность там - количественная. Нужно сказать оптимизатору, когда и где меняются переменные. Если для вас непривычно под переменными понимать значения в таблицах, то это не значит, что кто-то другой уже давно не использует именно такой подход. И подход этот достаточно дёшев по сравнению с вашими ожиданиями. Скорее всего дешевле даже одной записи на диск, а потому вполне применим.
Докажите
Тысячу ORM пилят десятки тысяч разработчиков. Пяток-другой оптимизаторов в известных БД пилят хорошо если десятка два разработчиков. Десятки тысяч намного больше пары десятков.
переносить нагрузку на клиентов
Оптимизация распределённых вычислений на порядки сложнее, ибо вносятся вероятностные задержки и неопределённое поведение. Поэтому не надо про "всё делать на клиенте". Он не справится.
Я без объяснения причин отказываюсь пользоваться массовой вставкой данных
Я объяснял - это усложнение практически не нужно, поскольку БД справляется. В том небольшом количестве случаев, когда БД не справится - напишем чистый SQL или вообще хранимку.
Я объяснял - это усложнение практически не нужно, поскольку БД справляется. В том небольшом количестве случаев, когда БД не справится
Любой управленческий , финансовый, бэкофисный учет это работа с проведением (автоматическим формированием проводок) , пересчетом итогов. Это фактически перманентный Delete\Insert Классический OLTP - то самое "небольшое количество случаев" . Эти пересчеты делаются роботами. У меня ежедневно отрабатывают 40 роботов по разным видам учета. А любой робот по нагрузке опередит тысячу пользователей. А делать такие системы проще с ORM поскольку прикладной код требует еще высокой скорости разработки. Такая жизнь
А делать такие системы проще с ORM поскольку прикладной код требует еще высокой скорости разработки.
Почему-то это принято только в 1С. Ведь и в SAP, и в AX, и в OEBS постинг через ORM не делают, хотя и используют механизм, позволяющий на своем языке описать конструкции, напрямую транслирующиеся в [WITH ...] INSERT/MERGE/DELETE/UPDATE ... FROM, избегая лишней пересылки массивов данных между сервером приложений и СУБД (это еще полбеды) и излишних блокировок, включая dead lock, что важнее. Впрочем, в особо важных случаях все равно применяют хранимые процедуры/функции или VIEW на SQL.
К слову, я всегда предпочитал на 1С для обработок использовать хранимые процедуры, о чем Вам уже писал. Не понимаю, что Вам мешает делать так же.
К слову, я всегда предпочитал на 1С для обработок использовать хранимые процедуры, о чем Вам уже писал. Не понимаю, что Вам мешает делать так же
Мне пока средств 1с хватает даже на базе 5 терабайт. Хранимые процедуры хороши если они делают универсальные вещи (типа передачи table valued ) параметров. Писать прикладные запросы и хранить их на SQL сервере - не нравится поскольку это размывает программный код и мне нужно использовать несколько репозиториев для деплоя готового приложения. А так я уверен что все в репозитории 1С . В общем чисто архитектурные причины для упрощения коммуникаций внутри отдела.
Если что нужно сделать не вписывающееся в 1С делаю это на Java как отдельный микросервис и далее интегрирую с 1С
SAP, и в AX, и в OEBS постинг через ORM не делаю
Могу за SAP сказать так как работал с ним и внутреннюю кухню знаю он достаточно старый и сначала там работа была с таблицами и ABAP более неприятные чем 1С язык по стилю.
А потом они тоже сделали ORM, можете таже посмотреть с картинками
ABAP Blog | ABAP Object Services — Persistence Service — часть 1. (abap-blog.ru)
Ну и вообще если брать новые их разработки типа SAP HANA они тянут туда нужные технологии. Чтото напоминает :) https://sappro.sapland.ru/kb/articles/spj/modelirovanie-tranzaktsionnih-prilozhenii-v-cds.html
Причем система у них еще более монолитная чем 1С. Правда до rapid application development они так и не доросли по причине идеологического непринятия "типовых конфигураций" и как следствие code reuse это у них копипаст репозиториев между проектами и докручивание через spro
Просто когда Вы делаете прикладную разработку, Вам ORM показан как RAD tool
Мне пока средств 1с хватает даже на базе 5 терабайт.
Ну а мне не хватало и на меньших БД. Мультимастер репликацию в 1C не сделаешь, а значит, сколько бы ни было SQL серверов в кластере, в один конкретный момент времени мастер только один, и все модификации - только на нем. Для обслуживания БД переключаем роли серверов. Тяжелые обработки - в фоне по очереди. Совсем тяжелые - в период минимальной загрузки с 21:00 по 23:00 МСК, когда Запад почти затих, а Дальний Восток еще не насел.
типа передачи table valued
Это как раз имеет очень узкую область применения. INSERT BULK все же почти всегда эффективней. У процедуры должен быть один параметр - идентификатор элемента очереди (документа в терминах 1С), который она должна обработать. Все остальное, через любимый Вами ORM, сохраняется в этом документе.
там работа была с таблицами и ABAP более неприятные чем 1С язык по стилю
Я не говорил, что ABAP хороший язык, но он издревле поддерживал Open SQL.
новые их разработки типа SAP HANA
Так же поддерживает Open SQL.
Писать прикладные запросы и хранить их на SQL сервере - не нравится поскольку это размывает программный код и мне нужно использовать несколько репозиториев для деплоя готового приложения.
Зачем несколько репозиториев? Репозиторий один в GIT. Конфигурация собирается из него, как и многое другое. Все же сам конфигуратор 1С слишком убог, чтобы в нем производить серьезную разработку с бренчами, мержами, тегами и пулл реквестами.
Что-то вы путаете. Правильная классификация такая - есть OLTP, то есть небольшие количественно изменения, и есть пакетные операции, к которым все ваши проводки раз в день и относятся. OLTP из-за небольшого количества изменений вполне красиво ложится на ORM. Массовое же изменение, естественно, логичнее делать более специализированными средствами. Но поскольку вы сами говорили, что массово проводки сохраняются один раз в день, то простым смещением этого счастливого момента на ночь вы решите все проблемы вашего магазина, и при этом возможная неэффективность используемого вами ORM на больших объёмах никого не заденет.
Но это общие принципы. Конкретика будет когда вы проведёте тесты на своей конфигурации со свойственной именно вам нагрузкой.
Анализ (чаще всего не семантический) производится всегда.
Вы заблуждаетесь. СУБД даже не пытается анализировать все операторы пакета, код триггеров всех используемых таблиц, использование недетерменированных функций, дерево зависимостей FOREIGN KEY и т.п.
Тысячу ORM
А зачем каждой ORM свой оптимизатор уже созданного пакета для отправки СУБД? Напишите один. И если вдруг кто-то из разработчиков ORM пожелает им воспользоваться - он просто возьмет Ваш код. В чем проблемы?
Оптимизация распределённых вычислений на порядки сложнее, ибо вносятся вероятностные задержки и неопределённое поведение. Поэтому не надо про
"всё делать на клиенте".
Сами поняли что сказали? Говоря клиент, я подразумевал клиент СУБД, который, в подавляющем большинстве случаев, является сервером приложений. А распределенные вычисления как раз и реализуются множеством серверов приложений, каждый из которых выступает в качестве клиента СУБД.
А в нашем случае о каких-то распределенных вычислениях вообще речи нет. Есть пакет, просто строка символов. Нужно провести его глубокий семантический анализ и на его основании преобразовать эту строку в другую. Никакими распределенными вычислениями тут и не пахнет.
Я объяснял - это усложнение практически не нужно,
Я тогда вообще не понимаю о чем Вы. Потому что во всех остальных случаях, когда в пакете лишь ряд [WITH ...] INSERT/MERGE/UPDATE/DELETE ... FROM - никаких оптимизаций этого пакета совершенно не требуется.
СУБД даже не пытается анализировать все операторы пакета
А как же она строит план запроса?
А зачем каждой ORM свой оптимизатор уже созданного пакета для отправки СУБД? Напишите один
Я уж извиняюсь, но вы не представляете, что такое независимая разработка под много платформ на многих языках.
в нашем случае о каких-то распределенных вычислениях вообще речи нет
Ваш пример кода, будучи перенесённым на клиента, потребовал бы именно распределённых вычислений с неопределённым поведением БД и случайными задержками.
никаких оптимизаций этого пакета совершенно не требуется
Требуется. Мы уже десяток комментов на эту тему написали.
А как же она строит план запроса?
План запроса строится только для каждого конкретного DML, совершено без связи с остальными предложениями в пакете и, тем более, без связи с кодом функций и триггеров. Для них опять таки план запроса будет строиться для каждого DML. Впрочем, может быть использован кешированный план запроса.
Я уж извиняюсь, но вы не представляете, что такое независимая разработка под много платформ на многих языках.
С чего это Вы взяли? Отлично представляю. Поэтому, если мне нужна функция, которая будет работать и на x86, и на ARM, включая Cortex-M, и на ESP8266/32, под любой ОС или даже при отсутствии таковой, то она пишется на C, что позволяет без проблем пользоваться ей на любой платформе.
Ваш пример кода, будучи перенесённым на клиента
Поясните Вашу мысль. Я вижу только строку символов, которую Вы хотите преобразовать, на основании метаданных, которые можно кешировать на клиенте. Где тут распределенные вычисления?
Требуется. Мы уже десяток комментов на эту тему написали.
Не вижу. Какие оптимизации могут потребоваться пакету, содержащему только ряд [WITH ...] INSERT/MERGE/UPDATE/DELETE ... FROM ... ?
Где тут распределенные вычисления?
Создаём временную таблицу. Читаем из неё. Создаём две записи. Удаляем из временной. Пишем туда же новое значение. Читаем его. Снова создаём две записи.
Посчитайте, сколько обращений к БД вы сделали.
Какие оптимизации могут потребоваться
Такие же, как и при любых других вычислениях. Например, про объединение инсертов в одну запись мы тут уже который день говорим.
Создаём временную таблицу.
Зачем временная таблица для оптимизации текста пакета? Это же всего-лишь строка символов!
Например, про объединение инсертов в одну запись мы тут уже который день говорим.
Для этого есть INSERT BULK. А я спрашиваю совсем другое. Еще раз:
Какие оптимизации могут потребоваться пакету, содержащему только ряд [WITH ...] INSERT/MERGE/UPDATE/DELETE ... FROM ... ?
Зачем временная таблица
Ваш код, вам виднее.
Какие оптимизации могут потребоваться пакету, содержащему только ряд [WITH ...] INSERT/MERGE/UPDATE/DELETE ... FROM ... ?
Группировка для одномоментной записи на диск, например. Но вообще там много места для оптимизаций. Если время выполнения пакета можно улучшить - оптимизация нужна. Если вам кажется, что оптимизация сложная, это не повод от неё отказываться.
Ваш код, вам виднее.
Я никакого кода оптимизации, тем более с временной таблицой не предлагал.
Группировка для одномоментной записи на диск
Я не понимаю что тут можно группировать. Изъясняйтесь, пожалуйста, более развернуто.
Если время выполнения пакета можно улучшить
Можно оптимизацией планов запроса конкретных DML. Но это вообще никакого отношения не имеет к тому, в пакете они были или нет.
Я не понимаю что тут можно группировать
Одна запись на диск стоит дешевле многих записей на диск. Вот и группируем многие записи в одну.
А при чем тут запись на диск? Количество записей на диск зависит только от объема кеша и количества фиксаций транзакций. От порядка или группироки DML оно не зависит вообще.
Опустим даже то, что MS SQL не позволяет в одном запросе использовать более одного INSERT/UPDATE/DELETE/MERGE. Но с чего Вы взяли, что даже в PostgreSQL WITH Del AS (DELETE ... ), Ins AS (INSERT ...) UPDATE ... будет быстрее, чем последовательность DELETE ... INSERT ... UPDATE ... ? Хоть в лоб, по лбу, но это все равно одна транзакция.
Приведите список всех операций чтения/записи с/на диск для следующего набора:
insert into t1 ...
insert into t2 ...
update t1 ...
update t2 ...
Операции включают как период до commit-a, так и сам commit. Ну а затем я покажу вам, что стоит сгруппировать.
При достаточно большом объеме оперативной памяти и уже наличии всех необходимых страниц в буфере данных, будет только одна операция записи на диск в журнал транзакций и ряд операций записи грязных страниц из буфера данных, в зависимости от того, какие страницы были модифицированы в этой транзакции. До фиксации транзакции, при соблюдении вышеописанных условий, обращений к диску не будет.
Oracle адаптирован под длинные транзакции, то есть всё там пишется на диск, хотя может и не сразу.
Если в пакете инсерт и потом на него же апдейт, то достаточно одной записи в лог, а при коммите одна на диск. Если же оптимизатор глупый - будут две в лог и при коммите их обе придётся прочитать, что бы два раза записать в одно и то же место на диске.
Точность схемы не гарантирую, но надеюсь разжёвано достаточно подробно, что бы был очевиден главный принцип.
В Oracle лог пишется циклически, а не раздувается как в MS SQL Sql . Cделайте реально длинную транзакцию на 10 миллионов записей, так чтобы в лог это не поместилось. Что будет? Куда будут писаться незафиксироанные изменения? Ответ откроет много нового в понимании Oracle
оптимизатор глупый
Механизм кеширования данных и журнала транзакций вообще не имеет отношения к оптимизатору. Сам принцип WAL подразумевает, что никакие модификации данных не должны попасть диск до того, как будет выполнена запись в журнал транзакций. Просто для длинных транзакций или при недостатке памяти грязные страницы данных будут сбрасываться на диск, что потребует предварительной записи на диск и буфера журнала транзакций. При этом WAL вообще безразлично, какие именно DML эти страницы сделали грязными.
Количество записей зависит не от количества операций, а от количества commit’ов, то есть от количества транзакций. Хотя, конечно, если везде ставить по умолчанию autocommit (руки б пообрывать тому_кто), то эти цифры равны :)
Это заблуждение. Transaction log как раз существует чтобы иметь возможность откатить транзакцию которая в том числе может быть незавершена да еще длинная . И commit всего лишь одно из условий Flush на диск , который идет асинхронно . Есть такое понятие check point в ms sql oracle точно https://learn.microsoft.com/en-us/sql/relational-databases/logs/database-checkpoints-sql-server?redirectedfrom=MSDN&view=sql-server-ver16
И в общем случае программист может инициировать checkpoint но не может его отложить
У вас в одном комментарии столько ошибок, что я, кажется, понимаю, почему 1С с базой работает вот так. Наверно, там все «специалисты» по БД не имеют представления об её устройстве.
Transaction log как раз существует чтобы иметь возможность откатить транзакцию
log существует для того, чтобы накатить транзакцию после сбоя экземпляра. В нормальных ситуациях никто никогда этот лог не читает (разумеется, кроме репликации). Для отката существует «сегмент отката», только вот называется он в разных БД по-разному. В Oracle – undo space, в PostgreSQL новые значения вообще пишутся рядом со старыми, а старые затираются только вакуумом, а в MS SQL, если мне память не изменяет, «сегмент отката» размещается в базе данных tempdb
И commit всего лишь одно из условий Flush на диск
Нет. При commit обязательно идёт flush на диск, если только это не тестовая база, где можно безнаказанно терять данные. Сбрасывается только журнальный буфер, но не сами блоки с данными.
Есть такое понятие check point
Есть такое понятие, но вы сначала разберитесь, что оно означает. Это сброс на диск изменённых блоков данных, и он действительно идёт асинхронно. Сигналом к нему является не commit, а одно из двух событий – превышение порога количества изменённых блоков в кеше или переключение файла в журнале транзакций.
Количество записей зависит не от количества операций, а от количества commit’ов, то есть от количества транзакций.
Это как понимать? Пример Update миллион записей но не делаем коммит, что сервер будет ждать commit чтобы сделать flush а когда памяти не хватит.?
log существует для того, чтобы накатить транзакцию после сбоя экземпляра
Вы с oracle видно работали а с ms sql нет. Там режим snapshot появился сравнительно недавно. И snapshot too old это фишка oracle. Я его у себя не включал
. При commit обязательно идёт flush на диск, если только это не тестовая база
Я написал что это одно из условий и привел пример checkpoint, который Вы вообще не упомянули. Потому что в Вашем мире
Количество записей зависит не от количества операций, а от количества commit’ов, то есть от количества транзакций
Вы что хотите сказать разработчикам? Типа не волнуйтесь если у вас много мелких dml просто облачите это в одну транзакцию побольше? И все будет ок trans log не будет узким местом
;))) ну расскажете как вы размером транзакции будете решать проблему мелких dml мы слушаем "специалиста"
Если что в статье приведена в пример не мелкая транзакция но с мелкими dml
.
что сервер будет ждать commit чтобы сделать flush
Именно так. Даже журнальный буфер держится в памяти. Конечно, когда он заполняется, сервер сбрасывает его на диск, но это делается асинхронно. То есть когда вы получили управление обратно от «маленькой DML», журнальная информация сохранена в памяти, но совсем не обязательно сохранена на диске.
режим snapshot появился сравнительно недавно
Примерно лет пятнадцать как. Пора бы включить.
Типа не волнуйтесь если у вас много мелких dml просто облачите это в одну транзакцию побольше?
Именно это я и хочу сказать.
Разумеется, одна bulk-операция будет быстрее, чем много маленьких, но ускорение составит десятки если не единицы процентов. Для того, чтобы ускорить обработку транзакций, надо в порядке убывания эффекта
Уменьшить количество транзакций. То есть вся бизнес-транзакция должна помещаться в одну транзакцию БД, никаких промежуточных commit’ов
Использовать подготовленные запросы (prepared queries). Для Oracle это даёт фантастический эффект, для PostgreSQL – просто огромный.
Избавиться от блокировки select’ов (в Oracle и PostgreSQL MVCC включен по умолчанию и не выключается, а вот в MS SQL, оказывается, до сих пор надо включать)
И только на четвёртом месте – замена множества «маленьких DML» на bulk-операции.
Буквально на днях проводил нагрузочный тест на PostgreSQL. 4 ядра, SSD, исключительно мелкие DML, в одной транзакции – два insert и два update. Около 3000 транзакций в секунду, узкое место – процессорная мощность.
исключительно мелкие DML, в одной транзакции – два insert и два update. Около 3000 транзакций в секунду, узкое место – процессорная мощность.
Ну попробуйте не 4 dml в одной транзакции а 40 dml каково будет ускорение? ;) все познается в сравнении
Мне например легко это сделать orm 1с позволяет . И ответ предсказуем
Всё зависит от конфигурации дисковой подсистемы. Конкретно в этой конфигурации ускорения не будет, т. к. проблема исключительно в процессоре. А вот на медленных дисках (когда вместо ssd были обычные hdd) ускорение было примерно в пять раз.
А вы можете снизить нагрузку ну чтобы процессор был не полностью забит ну скажем на 70% и с небольшими очередями. И сделайте замеры 4 dml в транзакции против 40 dml в Вашей теории разница должна быть в разы , а тут еще и диск влиять не будет (SSD) :) совсем чистый эксперимент. Я правда не знаю сколько Postgres пишет потоков (у In SQL Server 2019, up to eight Log Writer threads were added ) . Но у Oracle должно быть 100% c этим в порядке без узких мест
Снижать нагрузку бессмысленно. Редкие коммиты помогают тогда, когда узким местом является именно запись в журнал транзакций. Я ж говорил, на плохих дисках разница была действительно в разы.
In SQL Server 2019, up to eight Log Writer threads were added
Есть нюанс. Все транзакции, выполненные в одной базе, должны быть записаны в журнал строго последовательно, поэтому добавление писателей на пропускную способность базы не влияет вообще никак – работает только один.
Уникальность MS SQL Server в том, что у него в каждой базе данных свой журнал (у Oracle, PostgreSQL и DB2 – один журнал на экземпляр, т. е. на все базы, обслуживаемые экземпляром). То есть добавление потоков может увеличить пропускную способность экземпляра, но не базы.
То есть добавление потоков может увеличить пропускную способность экземпляра, но не базы.
Потому что в Oracle всегда думали о Highload и если делать по одному экземпляру на "базу" (схема в терминах Oracle) то распределение нагрузки будет лучше. Конечно можно несколько схем запихнуть в один instance , но для Highload смысла нет.
Разумеется, одна bulk-операция будет быстрее, чем много маленьких, но ускорение составит десятки если не единицы процентов.
Гугл с Вами не согласен Benchmarking Bulk & Batch Insert with .NET and actionETL (envobi.com) , Как нибудь нагуглю что нибудь более авторитетное, чтобы у всех сомнений не было
Я, как вы заметили, не специалист по конкретно SQL Server, поэтому не могу в полной мере оценить результат по ссылке. За Oracle скажу, что там есть Bulk (т. е. когда у команды аргумент-массив) и direct-path load (когда данные пишутся вообще в обход всех механизмов – клиент формирует готовые блоки данных и записывает их в таблицу выше highwatermark). Я не раз встречал, что инструменты пишут слово «bulk», но при этом используют DPL. И вот у него с традиционной загрузкой действительно примерно такая разница, как в эксперименте, на который вы ссылаетесь. Но это только insert (update так не работает) и только очень массивный (для группировки транзакций этот метод не годится).
Но это только insert (update так не работает) и только очень массивный (для группировки транзакций этот метод не годится).
Ну т.е. Ваш путь борьбы с нашествием мелких DML работает только на Insert (вот этот первый путь)?
1. Уменьшить количество транзакций. То есть вся бизнес-транзакция должна помещаться в одну транзакцию БД, никаких промежуточных commit’ов
А какже такие замечательные bulk конструкции Oracle (для всех DML как FORALL)?
Bulk data processing with BULK COLLECT and FORALL in PL/SQL (oracle.com)
Я не делал DBMS_trace , но как понимаю это не банальный batching в стиле JDBC.
Вообще я фанат Oracle в том смысле, что если хочешь найти хорошее архитектурное решение по реляционной СУБД , лучше сначала в Oracle посмотреть и а делее искать подобное у других вендоров. 1С на Oracle не ставил только по организационным мотивам, а не техническим
«Только на insert» и только на больших объёмах работает не мой пункт, а тот подход, который, скорее всего, применён в эксперименте, на который вы ссылаетесь.
А какже такие замечательные bulk конструкции Oracle (для всех DML как FORALL)?
Что «как же»? Всё с этими инструкциями хорошо, они прекрасно работают. Это именно bulk, а не dpl.
Дело в том, что SQL и PL/SQL изолированы друг от друга и общаются через интерфейс – точно так же, как Java-приложение с SQL. Forall – это один вызов, который принимает в качестве параметра массив. За один вызов выполняется столько операций, сколько элементов в массиве. Насколько я понимаю, «банальный батчинг» в JDBC работает так же.
сли хочешь найти хорошее архитектурное решение по реляционной СУБД , лучше сначала в Oracle посмотреть
Пожалуй, соглашусь.
Несколько лет назад я был на встрече с Томом Кайтом. Его спросили: если бы вы вернулись в далёкие 80-е с теми знаниями, что у вас есть сейчас, что бы вы изменили в архитектуре Oracle? Он ответил: да глобально – наверное, ничего...
Вот что у меня получилось
Тест с увеличенной транзакцией
Концепция ORM как двигатель прогресса – выявит слабое место Вашей СУБД / Хабр (habr.com)
Тест с включенным Delayed durability (в Oracle и Postgres ) аналоги есть. Последний вариант нравится больше
Вы путаете количество фиксаций транзакций с количеством записей в журнал транзакций. Вне зависимости от того, autocommit у Вас или нет каждое SQL предложение, модифицирующее БД, порождает запись в журнал транзакций. Более того, если бы этого не было, то и transaction log shipping не имел бы смысла )
Many types of operations are recorded in the transaction log. These operations include:
The start and end of each transaction.
Every data modification (insert, update, or delete). This includes changes by system stored procedures or data definition language (DDL) statements to any table, including system tables.
Every extent and page allocation or deallocation.
Creating or dropping a table or index.
А вы сейчас путаете количество записей в журнал транзакций и количество записей в файл на диске...
Не путаю. Количество записей в файл журнала транзакций на диске зависит только от размера кеша журнала транзакций и количества фиксаций транзакций.
Вот именно, зависит от количества фиксаций транзакций. А не от количества операций.
Все операции фиксируются в ЖУРНАЛЬНОМ БУФЕРЕ. А на диск содержимое буфера сбрасывается асинхронно. Клиент ждёт сброса буфера только при commit’е.
Операция добавления данных в буфер в памяти едва ли когда-нибудь станет узким местом. А вот операция записи в файл – таки да.
Перепутали flash и flush.
Сброс же кеша (не который SQL flash, а который дисковый flash) оказывает катастрофическое воздействие на скорость SSD
Для datacenter накопителей нет.
Табличка с тестами некоторых dc и десктопных ssd
Спасибо. Отличный пример, как на десктопных SSD 30 000 IOPS превращается в 500. У серверных тоже есть просадка раза в 3, но за счет конденсатора они жульничают с flush.
@1CUnlimited стоит посмотреть табличку.
В таблице не описаны условия тестирования ( размер блока для journal iops , linear write) . Это как минимум принципиально важно, поскольку если вы пишите 32к это может быть в 8 раз медленней чем писать 4К , но это не говорит о том что диск перегружен . Из Ваших постов выше я вижу непонимание приведенных мной цифр, разъясняю выше
С одной стороны, ORM позволяет существенно снизить стоимость разработки, которая, обычно, существенно выше стоимости железа. С другой стороны, опыт показывает, что "золотых молотков" не бывает.
Следует понимать, что императивный язык программирования (1С, Java) по своей сути плохо стыкуется с декларативным (SQL). Отсюда два варианта. Либо добавлять в язык декларативные возможности, позволяющие транслировать конструкции языка напрямую в SQL, обрабатывая одним запросом массивы данных. Либо напрямую использовать SQL, там где это необходимо. Вплоть до вынесения какой-то части бизнес-логики в хранимые процедуры.
С моей точки зрения можно просто библиотеки ORM доработать на пакетную запись/удаление нескольких экземпляров обьектов, а реализация под капотом через крупные dml. Да возможно придется от стандартов sql отойти и использовать table of record в памяти субд но я думаю и сейчас полностью стандарт соблюдать внутри orm не возможно
Так в том то и проблема, что в рамках императивного языка это можно только частично. Ну не подразумевает императивная парадигма параллельной обработки сразу массива данных. Отсюда, кстати, и необходимость в out-of-order execution с предсказанием ветвлений в CPU.
Может я чегото не понимаю, но почему нельзя разделить массив данных на таблицы по 100 записей и передавать их на СУБД как Table valued параметры . jOOQ 3.10 Supports SQL Server’s Table Valued Parameters – Java, SQL and jOOQ. или Table-Valued Parameters in SQL Server (sqlshack.com) или Using Table-Valued Parameters in SQL Server and .NET (sommarskog.se) . Есть масса вариантов в MS SQL и Oracle точно. Эти Table valued переданные на сервер СУБД дальше просто использовать для крупных DML. Но почему то известные мне ORM под капотом так не делают . Врядли это из за следования стандартам sql (кстати последний уже 2016)
Можно, но это все же менее эффективно, чем INSERT BULK (SqlBulkCopy в C#). Так почему бы явно им не пользоваться, если надо вставить больше нескольких десятков записей?
На самом деле задача какая-то надуманная. Ну сколько строк и как быстро пользователь вколотит? Для импорта из того же Excel или еще чего-то - INSERT BULK. А если надо трансформировать данные из БД и результат туда вставить, то это просто выходит за рамки применимости ORM. Не хотите на SQL писать - используйте тот же SSIS, который под такие задачи заточен.
Почему задача надуманная. Классический пример из 1С это перепроведений документов за месяц для фин учета. Иногда по нескольку раз делают в процессе сверки. Это инициирует формирование проводок, а если там их 30 миллионо только документов за месяц, все эти пакеты без распараллеливания не провести ну и утюжит базу очень хорошо. 1С это ORM в чистом виде даже без возможностей прямых запросов к СУБД, я думаю многие другие прикладные системы тоже по данной идеологии делают, чтобы сохранить целостность данных.
И зачем это делать средствами ORM? Подключайте ADODB через COMОбъект - и будет Вам счастье.
Хотя я предпочитал так не делать, ограничиваясь только штатными средствами системы для помещения задания в очередь на выполнение (в терминах 1С - просто создание документа). А уже внешний планировщик сидел на CDC и запускал асинхронно хранимые процедуры-обработчики, в пределах выделенного ему пула соединений. Пользователь же перенаправлялся на отчет, в котором мог наблюдать процесс обработки, обновляя отчет. Уведомление о завершении обработки, опционально, приходило пользователю по e-mail.
А о чём статья? О том, что ещё один слой абстракции над данными замедляет работу? Так это как бы очевидно.
О том, что ORM от 1С работает неоптимально? Да в 1С таких приколов полно. И не исправляют годами. Достаточно поискать на инфостате статью про "Все операции" (ныне "Функции технического специалиста"), где меню собиралось мин 2 вместо нескольких секунд, только потому, что у разработчиков 1С руки оказались откуда-то из плохого места.
А о чём статья? О том, что ещё один слой абстракции над данными замедляет работу? Так это как бы очевидно.
Основной посыл статьи в том, что в СУБД для производительности рекомендуют использовать один крупный dml опрератор insert update delete вместо 10 мелких. Но реализация современных orm нацелена на создание 10 мелких dml вместо одного крупного. А поскольку СУБД это разделяемый ресурс Orm следует подстраивать идеологию под СУБД а не наоборот .
Наличие слоя абстракции над данными не обязательно замедляет работу . Возьмите тот же ORM 1С - я логику вычисления сумм проводок (движений) реализую на сервере приложений. Это можно сделать пакетным образом (по 1000 документов ) как тут описано https://habr.com/ru/post/674282/ , а для СУБД остается только метод .Записать() для каждого документа (с учетом ограничений 1С) . В итоге я архитектурно распределяю нагрузку между сервером приложений и СУБД. При этом даже 1С процессы я могу так раскидать по серверам приложений, что они по производительности будут превосходить ресурсы любой СУБД
Допустим вы загрузили из базы 10 товаров и у них поменяли prop1 = value1. А у четных товаров еще поменяли prop2 = value2, просто для сферического примера.
Когда вы сохраняете товары по-одному, у вас товар сохраняются единой сущностью, т.е. либо весь товар сохранен, либо весь не сохранен. Т.е. генерируется запрос update product set prop1 = value1, prop2 = value2 where id = 1. И так для 10 товаров по очереди.
А если оптимизировать скорость и разбивать данное обновление с помощью крутой ORM автоматически на 2 SQL запроса: update product set prop1 = value1 where id in (1, 2, 3, ..., 10), а потом update product set prop2 = value2 where id in (2, 4, 6, ..., 10), то в случае невыполнения 2-го запроса, т.е. если он завершился с ошибкой у вас в базе и в вашем аппликейшене будет полностью мешанина из обновленных данных и не обновленных - часть полей обновилась, часть не обновилась, непонятно что обновилось а что не обновилось, и у каких товаров. Откатить выполнившиеся update'ы в базе не всегда возможно, по-этому придется проверять и разруливать ситуацию в ручную всегда, писать кастомный код, а разрулить данную ситуацию в плане объектов ORM будет в ну очень сложно.
По-этому для таких ситуаций пишут голый SQL, которые сделает необходимые обновления. И это гораздо проще, чем потом разрулить ситуацию с частично обновленными 10 товарами. Т.е. прям в коде пишешь функцию: update product set prop1 = :prop1_value where id in (:prop1_update_ids). И потом еще один SQL: update product set prop2 = :value2 where id in (:prop2_update_ids), и всё, код очень простой. По сравнению с тем, что надо писать метод прохода по 10 товарам и проверки, что в них обновилось а что - нет и отката всего до какого-то нормального состояния когда автоматический откат невозможен (а непонятно что ORM смогло откатить назад автоматически, а что не смогло, по-этому проверять надо всё).
А почему для одной сессии нельзя это делать в одной транзакции? Даже в 1С есть понятие транзакция которая работает на уровне платформы и влияет сразу на объект. Там вложенных транзакций нет, но я не знаю почему они не смогли. И ORM Достаточно быть эффективным в рамках одной сессии .
Я тут подумал, скорее всего эффективный батчинг - это реально то место, где можно что-то доработать, и действительно является недоработанным местом текущих ORM, и там можно что-то сделать. Но скорее всего там будет другой метод сохранения сущностей, т.к. нельзя при дефолтном вызове save открывать транзакции, рассчитывать что надо как-то доработать клиентский код под откат батчинга и т.д. Пока катимся на голом SQL.
Откатить выполнившиеся update'ы в базе не всегда возможно
Это как? Про то, что транзакция ≠ команда, теперь не рассказывают?
Факт пр ORM известный - за использование упрощенной модели взаимодействия объект<-> реляционная БД (лень разработчика и экономия его времени - эфемерная кстати), придется платить клиенту. Чаще всего не только за железо, но и за разболтанные нервы и впустую потраченноле время на ожидение пользователя. Хотя чаще всего тут ДАЖЕ не нужно массовых вставок, достаточно одного-двух мерджей и индекированной вьюшки. Я лично уже несколько лет пользую Linq2Db - прекрасную возможность писать практически на Sql, но с проверками типов на этапе компиляции. К сожелению, библиотека строго под Csharp, аналогов этой библиотеки я не встречал в других языках и экосистемах.
Часто бывает, что на C# один разработчик, а на SQL - другой. Чтобы упростить их взаимодействие, приходится код на SQL оформлять в виде VIEW, функции или хранимой процедуры.
Я ни в коем случае не утверждаю, что не бывает разработчиков, профессионально владеющих и C#, и SQL. Сам такой. Но нет никакой уверенности в том, что на стороне заказчика есть и будет такой специалист. Поэтому, даже когда пишу сам, то если ORM не применима, оформляю SQL код не в строках C#, а VIEW, функцией или хранимой процедурой. Да и читать потом удобней, особенно если запрос развесистый на несколько экранов.
Del
К сожелению, библиотека строго под Csharp, аналогов этой библиотеки я не встречал в других языках и экосистемах.
Java: jOOQ: query builder с максимально близким к SQL DSL и проверкой типов на этапе компиляции
Rust: Diesel: гибрид ORM и query builder'а, работающий поверх статически генерируемой схемы
Rust: Sqlx: статический валидатор и маппер SQL-запросов
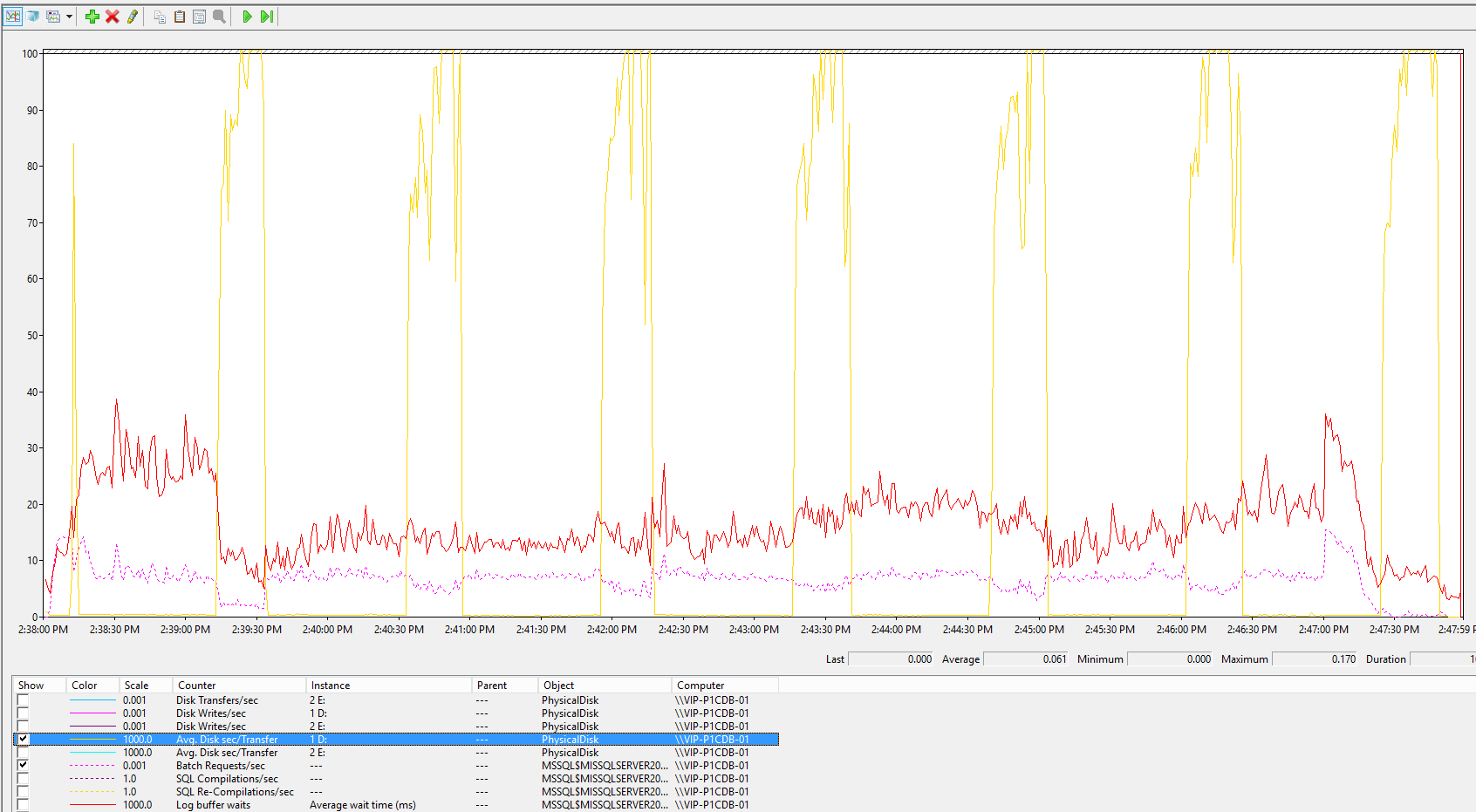{kind=link}
Концепция ORM как двигатель прогресса — выдержит ли ее ваша СУБД?