 Несмотря на свою феноменальную успешность на протяжении всей истории интернета, TCP — плохой транспортный протокол для современного дата-центра. Джон Остерхаут из Стэнфордского университета в научной статье «Пришло время заменить TCP в дата-центре» (опубликована 3 октября 2022 года, doi:
Несмотря на свою феноменальную успешность на протяжении всей истории интернета, TCP — плохой транспортный протокол для современного дата-центра. Джон Остерхаут из Стэнфордского университета в научной статье «Пришло время заменить TCP в дата-центре» (опубликована 3 октября 2022 года, doi: 10.48550/arXiv.2210.00714) аргументированно объясняет, почему все ключевые особенности этого протокола не подходят для ЦОД, начиная с ориентации на «потоки», и заканчивая очередью пакетов. Этот протокол был создан для другой цели. Ничего не поделаешь.
Самое печальное, что проблемы TCP слишком фундаментальны и взаимосвязаны. Все их невозможно исправить. Единственный способ использовать оптоволокно на максимальной скорости — внедрить в дата-центрах новый транспортный протокол.
И такой протокол разработан в 2018 году под названием Homa (на основе докторской диссертации Бенама Монтецери, который раньше работал в Стэнфорде, но потом ушёл в Google). Этот протокол не совместим с TCP по API, но его можно широко использовать на практике, интегрировав в фреймворки RPC.
В предыдущие годы Остерхаут опубликовал несколько научных работ с описанием архитектуры Homa, а также его реализации в ядре Linux. Ниже — основные тезисы из последней статьи автора. Просим прощения за излишнюю техническую сложность, но тема показалась нам очень важной.
История TCP
За 40 лет своей истории протокол TCP продемонстрировал потрясающую гибкость и адаптируемость к новым условиям. Только подумайте, во время разработки TCP в конце 1970-х годов к сети ARPANET было подключено примерно сто хостов, а скорость сетевых соединений составляла десятки килобит/с. За прошедшие с тех пор десятилетия Интернет вырос до миллиардов хостов. Скорости 100 Гбит/с стали обычным делом, но TCP продолжает служить рабочим транспортным протоколом практически для всех приложений.
Создание транспортного протокола, способного пережить столь радикальные изменения в базовой технологии, на которой он работает — выдающееся инженерное достижение.
Однако дата-центры создают беспрецедентные проблемы для TCP. Здесь миллионы ядер CPU и приложения на тысячах машин взаимодействуют на микросекундных интервалах. Разработчики TCP не могли такого представить. Поэтому TCP плохо работает в этой среде. Он добавляет оверхед на нескольких уровнях, что ограничивает производительность на приложений. Например, TCP сильно страдает от длинного «хвоста» распределения задержек (tail latency) для коротких сообщений при смешанных рабочих нагрузках.
TCP вносит основной вклад в так называемый «налог дата-центра» (datacenter tax) — набор низкоуровневых накладных расходов, которые потребляют значительную часть процессорных циклов в дата-центрах.
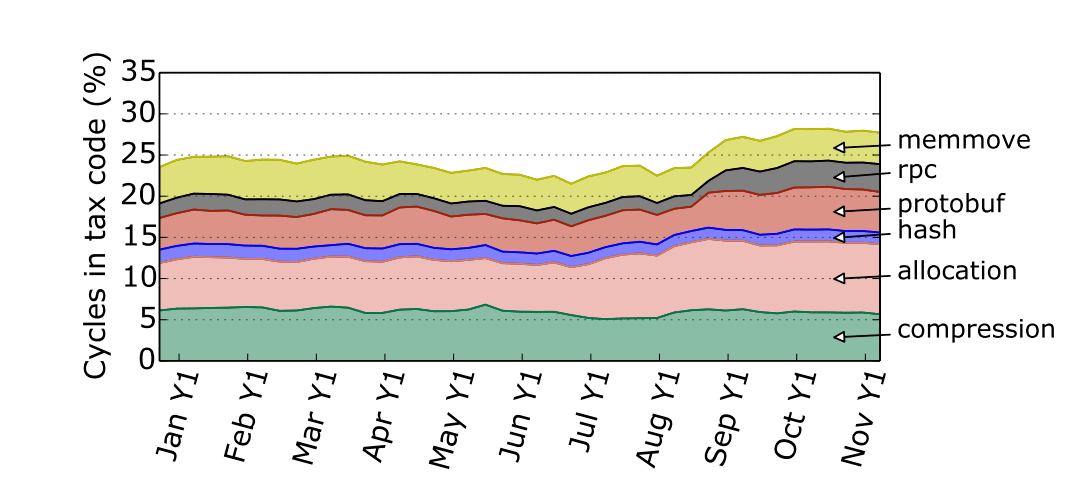
Рис. 1. Налог дата-центра, источник
Самое печальное, что проблемы TCP непреодолимы. Они затрагивают системы на разных уровнях, включая сеть, программное ядро и приложения. Одним из примеров является балансировка нагрузки, которая необходима в дата-центрах для одновременной обработки больших нагрузок. В то время, когда TCP был разработан, балансировка нагрузки ещё не существовала — и TCP мешает балансировщикам нагрузки как в сети, так и в программном обеспечении.
В научной работе доказывается, что TCP нельзя исправить эволюционным путем: здесь слишком много проблем и слишком много взаимосвязанных проектных решений. Вместо этого мы должны найти способ внедрить в центр обработки данных радикально другой транспортный протокол. И в качестве такого протокола предлагается Homa. Он разработан с чистого листа специально для ЦОДов, и практически каждое из его основных проектных решений было принято иначе, чем в TCP.
В результате полностью устранены некоторые проблемы, такие как сетевые заторы в ядре сети. Другие проблемы, такие как управление перегрузками и распределение нагрузки, с Homa решить гораздо проще. Новый протокол демонстрирует, что все проблемы TCP принципиально решаемы.
Но прежде чем перейти к описанию Homa, давайте посмотрим, какие задачи в принципе должен выполнять транспортный протокол.
Требования к протоколу
Любой транспортный протокол для ЦОД решает следующие задачи:
- Надёжная доставка данных между узлами, несмотря на временные сбои в сети.
- Низкая задержка. Современное сетевое оборудование передаёт короткие сообщения за микросекунды. Транспортный протокол не должен значительно увеличивать эту задержку. Транспортный протокол также должен поддерживать низкую задержку в хвосте (речь о максимальной задержке в хвосте распределения всех значений задержки). Для коротких сообщений она не должна более чем в 2–3 раза превышать минимальную задержку.
- Высокая пропускная способность как для объёма данных в целом, так и для маленьких сообщений. В центрах обработки данных крайне важна именно пропускная способность сообщений.
Чтобы соответствовать этим требованиям, протокол должен решать следующие проблемы:
- Управление заторами: борьба с накоплением пакетов в сетевых очередях как на границе (соединения хостов с коммутаторами верхнего уровня), так и в ядре сети.
- Эффективное распределение нагрузки между ядрами серверов. Поскольку производительность отдельных ядер CPU уже практически не растёт, на уровне приложений высокопроизводительные службы больше распределяют работу между ядрами. Балансировка нагрузки приводит к накладным расходам и появлению «горячих точек», когда нагрузка неравномерно распределяется по ядрам. Накладные расходы на балансировку — это одна из основных причин хвостовых задержек. А на них влияет дизайн транспортного протокола.
- Транспорт в сетевых картах. Программные реализации транспортных протоколов больше не способны обеспечить высокую производительность при приемлемых вычислительных затратах. Транспортным протоколам придётся перейти на специализированное сетевое оборудование.
В TCP всё неправильно
Если разобраться, то все пять ключевых особенностей TCP противоречат эффективной работе в дата-центре:
- Концепция «потока»
- Концепция «соединений»
- Распределение полосы («справедливое» планирование)
- Управление перегрузками со стороны отправителя
- Последовательная доставка пакетов
Каждое из этих свойств представляет собой неправильное решение для транспорта ЦОД, и у каждого серьёзные негативные последствия.
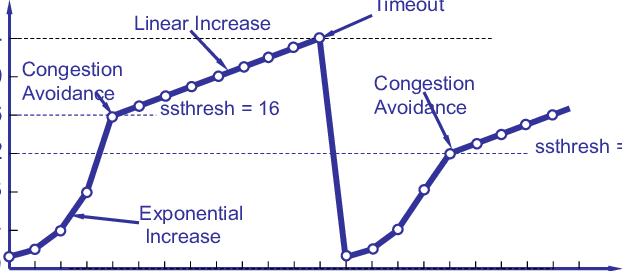
Рис. 2. Управление перегрузками и устранение сетевых заторов в TCP выполняется со стороны отправителя
Модель данных для TCP — это поток байтов. Однако такая модель данных не подходит для большинства приложений ЦОД, которые обмениваются дискретными сообщениями для реализации удалённых вызовов процедур (RPC). Когда сообщения сериализуются в поток TCP, тот не знает о границах сообщений. Это означает, что когда приложение читает из потока, нет гарантии, что оно получит полное сообщение. Оно может получить не полное сообщение или части нескольких сообщений. Приложениям на TCP приходится отмечать границы сообщений при их сериализации (например, путем префиксации каждого сообщения его длиной), и они должны использовать эту информацию для повторной сборки сообщений при получении. Это создаёт дополнительную сложность и оверхед. Потоковая модель катастрофична для программной балансировки нагрузки.
Концепция «соединений» тоже приводит к огромному оверхеду, поскольку приложениям приходится поддерживать долгоживущие состояния с сотнями и тысячами таких соединений. Например, ядро Linux хранит около 2000 байт состояния для каждого сокета TCP, не считая буферов пакетов. Дополнительное состояние требуется на уровне приложения.
В то же время надёжности доставки и контроля перегрузок можно добиться и без концепции «соединений», как будет показано ниже.
Управление перегрузками со стороны отправителя неэффективно, поскольку отправители не имеют представления о перегрузке, которая может возникнуть как в ядре сети, так и на пограничных каналах между коммутаторами и получателями.
Наконец, TCP предполагает, что пакеты будут приходить к получателю в том же порядке, в котором переданы отправителем, и непоследовательное прибытие пакетов означает их потерю. Это сильно ограничивает распределение нагрузки, что приводит к возникновению «горячих точек» как в аппаратном, так и в программном обеспечении, и, как следствие, к высоким хвостовым задержкам.
В ЦОДах наиболее эффективным способом балансировки нагрузки является «распыление» пакетов, когда каждый пакет независимо направляется через коммутационную сеть для балансировки нагрузки на каналы. Однако такой метод нельзя использовать в TCP, поскольку он может изменить порядок прибытия пакетов. Вместо этого в TCP приходится использовать маршрутизацию, согласованную с потоком, при которой все пакеты из данного соединения следуют по одному и тому же пути через сетевую структуру. Поточно-последовательная маршрутизация практически гарантирует, что в ядре сети будут перегружены каналы, даже если общая нагрузка на сеть невелика.
TCP невозможно исправить
Одним из возможных ответов на проблемы с TCP является инкрементный подход, постепенно устраняющий проблемы при сохранении совместимости приложений. Таких попыток уже было много, и они достигли определенного прогресса. Однако такой подход вряд ли будет успешным: проблем просто слишком много, и они слишком глубоко заложены в конструкцию TCP.
В качестве примера автор рассматривает управление перегрузками и контроль заторов. В последние годы было разработано множество новых и умных методов. Один из них — DCTCP, который значительно уменьшает хвостовые задержки (см. рис. 3 ниже). Он получил довольно широкое распространение.
Более поздние предложения типа HPCC обеспечивают дополнительные улучшения, но все эти схемы ограничены фундаментальными аспектами TCP, такими как слабый фидбек о заторах, основанный на заполнении буфера, невозможность использования очередей с приоритетом коммутатора и требование доставки в порядке очереди.
У TCP слишком много проблем, и они слишком взаимосвязаны. Таким образом, придется изменить множество различных частей TCP, прежде чем улучшения станут заметны. Кроме того, проблемы с TCP связаны не только с его реализацией, но и с его API.
Для достижения максимальной производительности в центре обработки данных TCP должен перейти от модели, основанной на потоках и соединениях, к модели, основанной на сообщениях. Это фундаментальное изменение, которое повлияет на приложения. Как только приложения будут затронуты, мы сможем одновременно решить и все остальные проблемы TCP.
Суть в том, что в TCP нет ни одной части, которую стоило бы сохранить. Нам нужен другой протокол, который отличается от TCP во всех существенных аспектах. К счастью, такой протокол уже разработан — это Homa. Она доказывает, что все проблемы TCP принципиально можно решить.
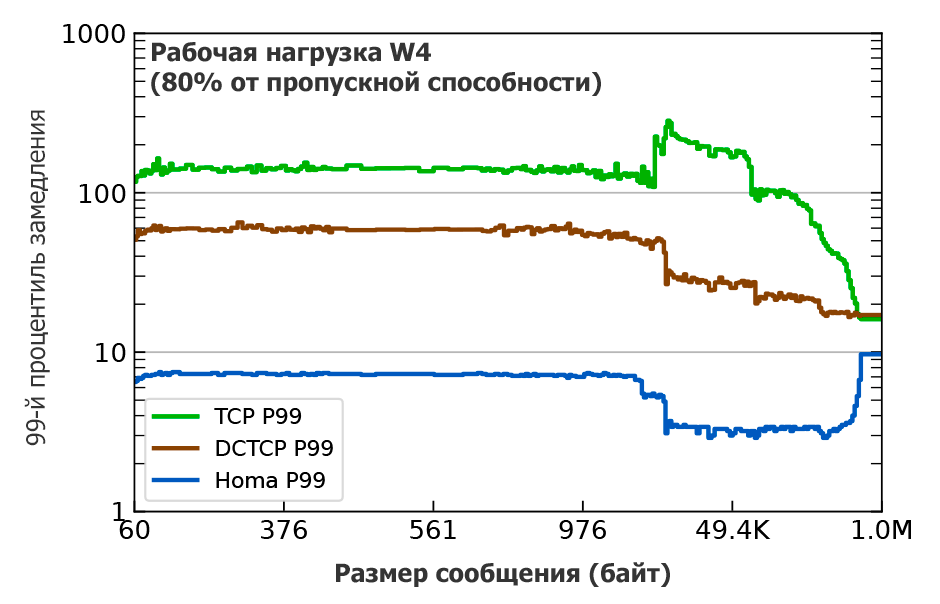
Рис. 3. 99-й процентиль замедления в зависимости от длины сообщения для реализаций TCP, DCTCP и Homa в ядре Linux, работающих на 40-узловом кластере CloudLab с сетевыми каналами 25 Гбит/с при средней загрузке 80% (подробности см. в предыдущей статье Остерхаута). Рабочая нагрузка основана на распределении размера сообщений, измеренном на кластере Hadoop в Facebook. Замедление — это время прохождения сообщения в оба конца на загруженном кластере, делённое на время прохождения сообщений Homa той же длины в незагруженной системе
На рис. 3 показан график для 99-перцентиля на близкой к максимальной нагрузке сети 80%. Но на самом деле Homa превосходит TCP в любой ситуации, при любых нагрузках и размерах сообщений:
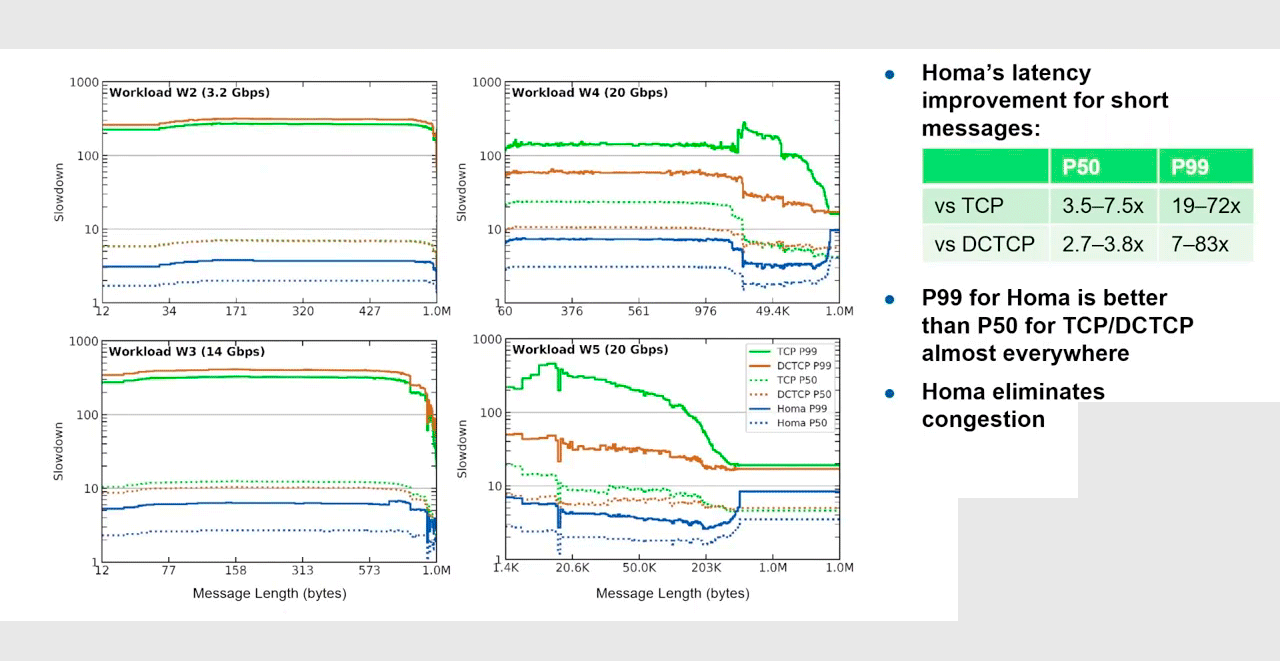
Рис. 4
Протокол Homa спроектирован с нуля, с учётом опыта использования Infiniband и RDMA для реализации крупномасштабных приложений ЦОД. Дизайн отличается от TCP по всем параметрам, рассмотренным выше.
Основные особенности Homa
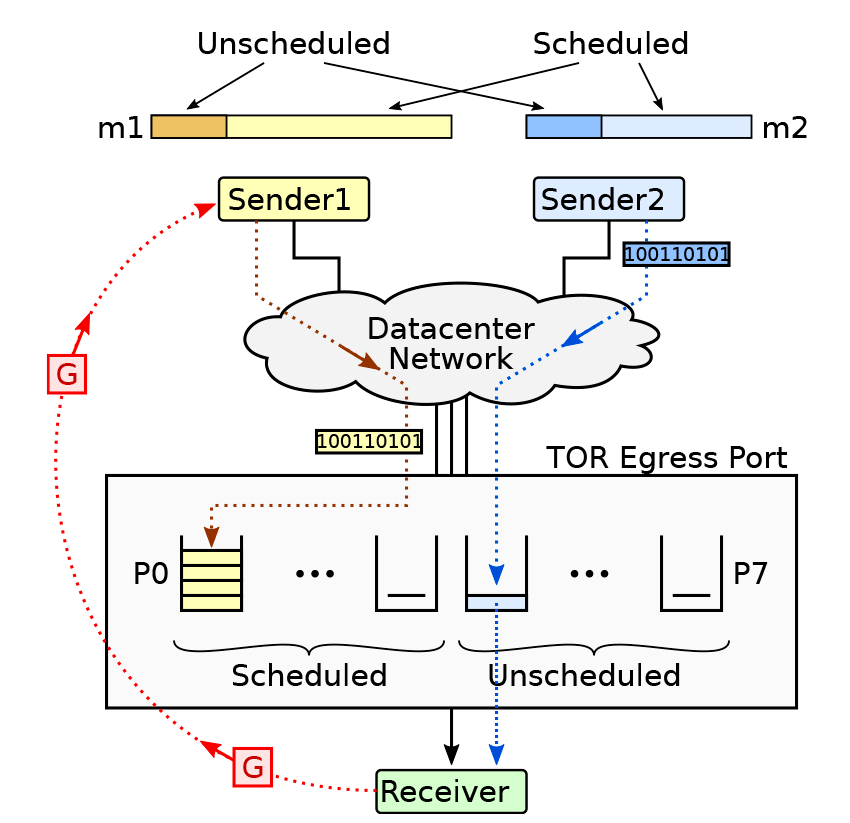
Рис. 5. Протокол Homa. Общая схема
- Протокол Homa разработан с нуля для RPC-коммуникаций в дата-центрах:
- Основан на сообщениях, а не пакетах. Он реализует удаленные вызовы процедур (RPC), где клиент посылает на сервер сообщение-запрос и получает сообщение-ответ. Несколько потоков могут безопасно читать из одного сокета, а реализация протокола на базе сетевой карты может отправлять сообщения непосредственно пулу рабочих потоков. Наличие явных границ сообщений позволяет планировать выполнение до завершения передачи и обеспечивает более мощный сигнал о заторах.
- Connectionless, то есть отсутствие концепции «соединений». Нет никаких накладных расходов на установку соединения, и приложение может использовать один сокет для управления любым количеством параллельных RPC с любым количеством пиров. Состояние в Homa хранится в трёх категориях: сокеты, RPC и пиры. При этом сохраняется надёжность и поддержка контроля потока, как в TCP.
- Политика планирования SRPT позволяет более приоритетным (коротким) сообщениям обходить пакеты, стоящие в очереди для более низкоприоритетных (длинных) сообщений. Как показано на рис. 3, это приводит к значительному улучшению хвостовой задержки по сравнению с TCP или DCTCP. Сообщения любой длины выигрывают от SRPT: даже у самых длинных сообщений значительно меньшая задержка в Homa, чем при TCP или DCTCP.
- Управление заторами на стороне получателя. Получатель знает обо всех входящих сообщениях, поэтому он в лучшем положении для управления заторами. Когда отправитель передаёт сообщение, то может отправить несколько незапланированных пакетов в одностороннем порядке (достаточно, чтобы покрыть RTT), но запланированные пакеты могут быть отправлены только в ответ на гранты от получателя. С помощью этого механизма отправитель может ограничить затор на своём нисходящем канале, а также использовать гранты для приоритизации более коротких сообщений
- Передача пакетов в любом порядке.
- Основан на сообщениях, а не пакетах. Он реализует удаленные вызовы процедур (RPC), где клиент посылает на сервер сообщение-запрос и получает сообщение-ответ. Несколько потоков могут безопасно читать из одного сокета, а реализация протокола на базе сетевой карты может отправлять сообщения непосредственно пулу рабочих потоков. Наличие явных границ сообщений позволяет планировать выполнение до завершения передачи и обеспечивает более мощный сигнал о заторах.
- API без концепции «соединений»:
int homa_send(int sockfd, const void *request, size_t reqlen, const struct sockaddr *dest_addr, socklen_t addrlen, uint64_t *id); int homa_reply(int sockfd, const void *response, size_t resplen, const struct sockaddr *dest_addr, socklen_t addrlen, uint64_t id); int homa_recv(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t addrlen, uint64_t *id);
Модуль Homa/Linux для ядра Linux реализован как динамически загружаемый модуль (примерно 10 000 строк на C) и не требует модификаций ядра.
На видео ниже — презентация с ежегодной технической конференции USENIX ATC 21 с описанием реализации Homa в ядре Linux.
Ниже основные преимущества и особенности Homa из презентации.
Преимущества Homa
- устранение сетевых заторов;
- уменьшение хвоста распределения задержек (tail latency) в 7–83 раза, по сравнению с TCP или DCTCP;
- минимальные задержки, особенно для коротких сообщений и сообщений в хвосте, даже под большой нагрузкой;
- SRPT (Shortest Remaining Processing Time).
После внедрения Homa/Linux основным фактором для повышения для сетевой производительности становятся программные, а не сетевые оптимизации. То есть повышение пропускной способности сети становится вопросом разработки эффективных балансировщиков нагрузки, а также ОС. Например, Homa/RAMCloud демонстрирует в 99-м перцентиле задержку около 14 мкс (это в юзерспейсе, в обход ядра), тогда как Homa/Linux — 100 мкс. То есть после внедрения эффективного транспортного протокола на первый план выходит оптимизация программного обеспечения.
Вывод
В целом, TCP — это неправильный и неподходящий протокол для вычислений в дата-центрах. Каждый аспект дизайна TCP ошибочен: нет ни одной части, которую стоило бы сохранить. Если мы хотим избавиться от «налога на дата-центры», то следует найти способ перевести бóльшую часть трафика ЦОД на радикально новый протокол.
Существующие альтернативы вроде Infiniband/RDMA разделяют большинство «родовых» проблем TCP. В отличие от них, Homa решает эти проблемы.
Полная замена TCP в ближайшее время маловероятна из-за его глубоко укоренившегося статуса. Но к счастью, нет необходимости заменять TCP во всех приложениях. На самом деле сейчас это требуется только в самых высокопроизводительных системах ЦОД, не более того. Во многих приложениях TCP можно вытеснить путём интеграции Homa в небольшое количество существующих RPC-фреймворков, таких как gRPC и Apache Thrift. При таком подходе несовместимый Homa API виден только разработчикам фреймворков, и приложения смогут относительно легко перейти на Homa.
Работа по интеграции с фреймворками уже началась: драйвер gRPC для Homa уже существует для приложений на C++, а поддержка Java находится в процессе разработки. Эта работа основана на реализации Homa для ядра Linux.
P. S. Судя по всему, в дата-центрах Google реализован собственный протокол Snap, который уменьшает задержку ещё в 1,5–2 раза, по сравнению с Homa — прим. пер.

