

Triton – это языковой компилятор для создания сильно оптимизированных ядер CUDA. Здесь будут изложены основы программирования для GPU и рассказано, как для этой цели используется Triton.
Учитывая нынешний успех глубокого обучения и вал исследовательских статей на эту тему, часто возникает такая ситуация: рождается какая-нибудь новая идея, и выясняется, что для нее не поддерживается аппаратное ускорение. Точнее, стоит вам изобрести новую функцию активации или механизм самовнимания – нам сразу приходится прибегать к возможностям PyTorch/Tensorflow для обработки прямого и обратного прохода через модуль.
В таких случаях применим, например, PyTorch JIT. Но PyTorch JIT – это высокоуровневый компилятор, способный оптимизировать лишь некоторые части кода, но непригодный для написания специализированных ядер CUDA.
С написанием ядер CUDA есть и еще одна проблема – создать такое ядро невероятно сложно. Оптимизация вычислений с расчетом на использование локальности и параллелизма требует много времени и чревата ошибками, и экспертам в этих областях часто требуется хорошо потрудиться, чтобы научиться писать код CUDA. Кроме того, архитектуры GPU стремительно развиваются; например, уже появились новейшие тензорные ядра. Поэтому оказывается еще сложнее писать такой код, который выжимал бы из имеющегося оборудования максимум производительности.Именно здесь на сцену выходит Triton от OpenAI. В состав Triton входит три основных компонента.
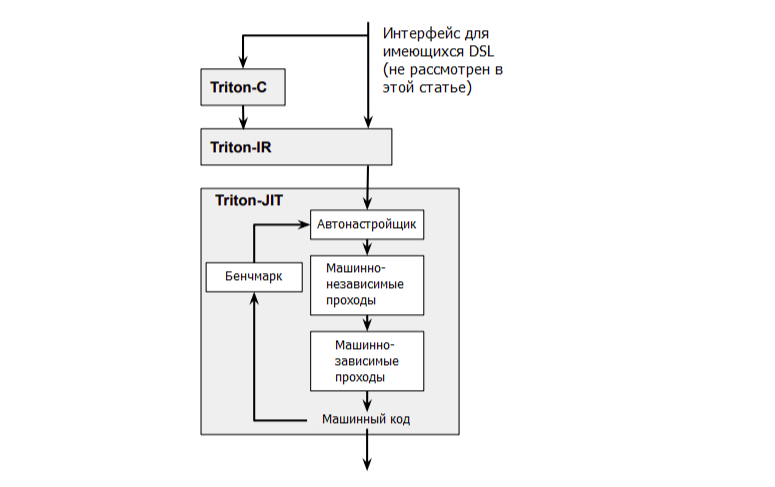
Рисунок 1: Обзор основных компонентов Triton.
- Triton-C: это C-подобный язык, ориентированный в основном на программистов, уже знакомых с CUDA.
- Triton-IR: это промежуточное представление на основе LLVM. Программы на Triton-IR собираются непосредственно из Triton-C. Если коротко, в LLVM предоставляется много специфичных аппаратных оптимизаций, что позволяет нам напрямую использовать компилятор CUDA от Nvidia (NVCC), чтобы приспособить наш код под конкретное аппаратное обеспечение.
- Triton-JIT: это бекенд с динамическим (JIT) компилятором и инструментом генерации кода. Предназначен для компиляции программ, написанных на Triton-IR, в эффективный биткод для LLVM. Также он содержит множество машинно-независимых оптимизаций, что, опять же, сокращает для вас объем работы.
Самая интересная часть проекта Triton – это именно Triton-JIT. Благодаря этому компилятору, программисты почти без опыта работы с CUDA могут писать на Python сильно оптимизированные ядра CUDA. Прежде чем обсуждать Triton, давайте разберемся, как именно программы CUDA работают на GPU.
Полезные ссылки:
- Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations
- Introducing Triton: Open-Source GPU Programming for Neural Networks
- triton github
- Документация по triton
❯ Основы программирования для GPU
Начнем с ЦП (хоста). ЦП обладает доступом к оперативной памяти (RAM), дискам для хранения данных и к любой подключенной периферии. В свою очередь, GPU (устройство) не имеет доступа ни к RAM, ни к чему из вышеперечисленного. У GPU есть своя собственная память, которая называется VRAM. Чтобы GPU мог работать, данные нужно скопировать с ЦП на GPU, а затем обработанные данные должны быть скопированы обратно с GPU на ЦП, чтобы ЦП мог их где-нибудь сохранить или поделиться ими с подключенной периферией.
Примечание: именно поэтому следует минимизировать курсирование данных между ЦП и GPU, насколько это возможно. Продумайте, как можно загружать данные небольшими фрагментами для параллельной обработки или импортировать данные так, чтобы приспособить их для многократного использования, прежде, чем импортировать следующую порцию данных.
В CUDA запускается множество потоков, сгруппированных в блоки, которые образуют грид. Все потоки в одном блоке могут обмениваться информацией друг с другом. В каждом блоке можно запустить до 1024 потоков, а за один запуск может быть сделано до 2^32—1 блоков. Такой пример приведен на рис. 2.

Рисунок 2: Архитектура программ CUDA.
Идея, на которой основано использование блоков такова, что вам не потребуется переписывать ваш код, если в будущем доведется иметь дело с новым GPU. Так что новый GPU просто сможет конкурентно выполнять большее количество блоков, без каких-либо изменений в коде.
❯ Сравниваем программу для ЦП и программу для CUDA
Не вдаваясь в технические тонкости, давайте рассмотрим простой пример: как сложить два массива, имеющих длину 3.
arr1 = [1, 2, 3] arr2 = [10, 11, 12]
Если бы мы хотели сложить эти массивы в C++, то создали бы цикл for, который совершил бы три итерации (предполагается, что у нас однопоточная программа).
Но в CUDA мы запустим 3 потока, и каждый из них выполнит сложение в своем индексе, а цикл for сработает за один шаг. Фактически, здесь произойдут следующие операции
- Копирование
arr1,arr2с ЦП на GPU. - Создание нового массива размером 3 (или сохранение результирующей суммы в
arr1). - Запуск 3 потоков для выполнения сложения и сохранения результата в новом массиве.
- Копирование результата с GPU на ЦП.
Поскольку у GPU тысячи ядер, на них гораздо быстрее, чем на обычных ЦП, выполняются простые вещи, в частности, сложение, перемножение матриц (при условии, что выигрыш в скорости компенсирует время, затрачиваемое на перенос данных между ЦП и GPU).
❯ Сравнение CUDA и Triton
Выше была показана модель выполнения CUDA. Теперь давайте посмотрим, чем от нее отличается модель выполнения в Triton.
В CUDA каждое ядро ассоциировано с блоком потоков (т. e. с коллекцией потоков). В Triton каждое ядро ассоциировано с единственным потоком. При такой парадигме выполнения решается проблема с межпоточной синхронизацией памяти, внутрипоточной коммуникацией, и в то же время разрешается автоматическое распараллеливание.
Теперь мы уже не храним потоки в специальном блоке, а сам блок представляет собой диапазон (range) можно сказать, замощенный указателями на потоки. В данном случае наиболее интересно, что у вас может быть столько диапазонов, сколько захотите. Так, если ввод у вас в 2D, можно указать Range(10) для оси x и Range(5) для оси y всего для 50 потоков. Аналогично, диапазоны можно определять в таком количестве измерений, в каком хотите.
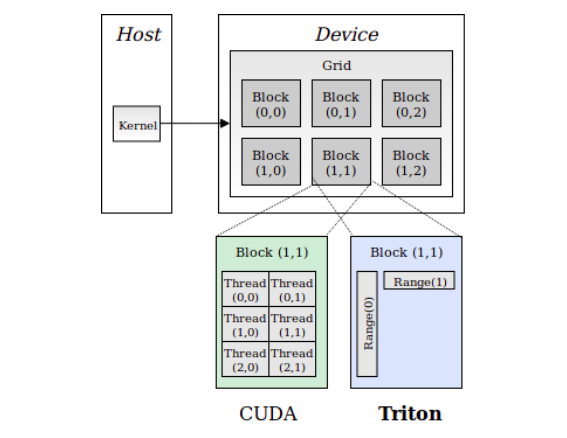
Рисунок 3: Сравнение модели выполнения CUDA и модели выполнения Triton.
❯ Сложение двух массивов при помощи Triton
Итак, мы составили впечатление о том, как работают CUDA и Triton, и можем писать программы на Triton. Triton устанавливается следующей командой
pip install triton.Вкратце этапы работы таковы:
1. Определить блок. Как известно, блоки определяются путем указания диапазона. Поэтому при сложении мы должны просто определить диапазон в одном измерении. Пусть он будет равен 512, и мы определим его как глобальный
BLOCK_SIZE = 512.2. Фактически, диапазон 512 означает, что для выполнения вычислений мы запускаем 512 потоков.
3. Далее получаем индекс входных данных. Допустим, размер входного массива равен 1000. Поскольку мы определили блок размером 512, входной массив мы будем обрабатывать фрагментами по 512 каждый. Таким образом, первый фрагмент начнется с
0:512, а второй с 512:1024. Это делается при помощи кода, показанного ниже.4.
# Сложение одномерно, поэтому нам нужно только получить индекс по axis=0 pid = triton.language.program_id(axis=0)
# Показанные ниже смещения относятся к спискам указателей block_start = pid * BLOCK_SIZE offsets = block_start + triton.language.arange(0, BLOCK_SIZE)
5. Маскировка для защиты операций в памяти. В вышеприведенном примере размер входного массива
N=1000, но, благодаря смещению, он начинается с 512:1024. Поэтому мы должны указать маску, которая защитит нас от выхода за границы массива при запросах. Такую маску нужно указывать для каждой оси.mask = offsets < N
6. Загружаем данные. Теперь, когда у нас определены смещения и маска, можно загрузить данные из RAM и закрыть масками все лишние элементы.
def add_kernel(arr1_ptr, arr2_ptr, output_ptr, ...): ... arr1 = triton.language.load(arr1_ptr + offsets, mask=mask) arr2 = triton.language.load(arr2_ptr + offsets, mask=mask)
7. Выполняем нужную операцию. В данном случае требуется сделать только сложение.
output = arr1 + arr2
8. Произведя вычисления, сохраняем результат в RAM. GPU не имеет доступа к хранилищу данных, поэтому сначала нужно перенести данные в RAM, а затем мы сможем сохранить их на диске, если захотим.
triton.language.store(output_ptr + offsets, output, mask=mask)
Ниже приведен весь код ядра.
import triton import triton.language as tl BLOCK_SIZE = 512 @triton.jit def add_kernel(arr1_ptr, arr2_ptr, output_ptr, N): # Шаг 1: получаем весь диапазон оси pid = tl.program_id(axis=0) # Шаг 2: определяем смещения и маску block_start = pid * BLOCK_SIZE offsets = block_start + tl.arange(0, BLOCK_SIZE) mask = offsets < N # Шаг 3: загружаем данные из RAM arr1 = tl.load(arr1_ptr + offsets, mask=mask) arr2 = tl.load(arr2_ptr + offsets, mask=mask) # Шаг 4: выполняем вычисления output = arr1 + arr2 # Шаг 5: Сохраняем результат в RAM tl.store(output_ptr + offsets, output, mask=mask)
Чтобы использовать ядро, определяем вспомогательную функцию, как показано ниже
def add(arr1: torch.Tensor, arr2: torch.Tensor): output = torch.empty_like(arr1) N = output.numel() grid = lambda meta: (triton.cdiv(N, BLOCK_SIZE),) add_kernel[grid](arr1, arr2, output, N) return output
В принципе,
grid указывает то пространство, над которым мы будем работать. В нашем случае грид одномерный, и мы указываем, как данные будут распределены в гриде. Поэтому, если входные массивы имеют нужный размер, то определим грид следующим образом: [0:512], [512:1024]. На данном шаге мы указываем, как разделить входные данные и передать их ядру.По умолчанию grid принимает один аргумент, обозначающий позицию – назовем его
meta. Аргумент meta нужен для предоставления такой информации как BLOCK_SIZE, но мы определили размер блока в глобальной переменной.Теперь мы вызываем функцию
add как обычную Python-функцию, см. ниже. Перед этим нужно убедиться, что данные, передаваемые функции на вход, уже находятся на GPU.arr_size = 100_000 arr1 = torch.rand(arr_size, device='cuda') arr2 = torch.rand(arr_size, device='cuda') pytorch_out = arr1 + arr2 triton_out = add(arr1, arr2) print(torch.sum(torch.abs(pytorch_out - triton_out)))
Вывод
❯ python main.py
tensor(0., device='cuda:0')❯ Сложение для тензоров более высоких измерений
Тем же самым ядром можно воспользоваться и для работы с N-мерными тензорами. Это гибкий подход, позволяющий обойтись без написания множества ядер, каждое из которых отвечало бы за ввод с конкретным количеством измерений. Идея проста: во вспомогательной функции переформируем имеющийся тензор в одномерный, а затем переформируем выходной тензор.
Такая операция по переформированию не потребует много времени, так как мы всего лишь изменяем значения шагов в классе tensor. Ниже показана модифицированная вспомогательная функция.
def add(arr1: torch.Tensor, arr2: torch.Tensor): input_shape = arr1.shape arr1 = arr1.view(-1) arr2 = arr2.view(-1) output = torch.empty_like(arr1) N = output.numel() grid = lambda meta: (triton.cdiv(N, BLOCK_SIZE),) add_kernel[grid](arr1, arr2, output, N) output = output.view(input_shape) return output
А затем вызываем функцию точно так же, как и раньше.
arr_size = (100, 100, 100) arr1 = torch.rand(arr_size, device='cuda') arr2 = torch.rand(arr_size, device='cuda') pytorch_out = arr1 + arr2 triton_out = add(arr1, arr2) print(torch.sum(torch.abs(pytorch_out - triton_out)))
Вывод
❯ python main.py tensor(0., device='cuda:0')
Мы разобрали простой пример. Но в более сложных случаях, скажем, при перемножении матриц, производительность сильнейшим образом зависит от того, как именно вы разделите данные. В документации по Triton есть руководство, поясняющее, как написать ядро для эффективного перемножения матриц – там все рассказано в подробностях.
Это было краткое руководство, благодаря которому вы познакомились с основами программирования для GPU и с Triton. Подробнее почитать о проекте Triton можно в openai/github.

