
Привет, Хабр! На связи Рустем, IBM Senior DevOps Engineer & Integration Architect. Сегодня я хотел бы поговорить о хаос-инженерии в Kubernetes, и поможет нам с этим Litmus.
Хаос-инжиниринг – это подход к тестированию отказоустойчивости программного обеспечения, который намеренно вызывает ошибки в реальных реализациях. Он содержит элемент случайности, имитирующий непредсказуемость большинства реальных сбоев.
Хаос-инженерия создает эффект иммунного ответа. Это похоже на то, как мы вакцинируем здоровых людей. Вы намеренно вводите угрозу, потенциально вызывающую краткосрочные, но ощутимые проблемы, чтобы развить более сильное долгосрочное сопротивление.
Litmus — это набор инструментов для создания хаоса в облаке. Litmus предоставляет инструменты для управления хаосом в Kubernetes, чтобы помочь SRE найти слабые места в деплойментах. SRE используют Litmus для запуска экспериментов с хаосом сначала в тестовой среде, а затем в рабочей среде для поиска ошибок и уязвимостей. Последующее исправление слабых мест приводит к повышению устойчивости системы.
Litmus предлагает нам следующие привлекательные функции:
Нативные CRD Kubernetes для управления хаосом. Используя API хаоса — оркестрацию, планирование и комплексное управление рабочими процессами можно организовать декларативно.
Большинство общих экспериментов с хаосом легко доступны для нас, чтобы мы могли начать работу с нашими первоначальными потребностями в хаос-инженерии.
SDK доступен для GO, Python и Ansible. Базовая структура хаос-эксперимента создается быстро с помощью SDK, а разработчикам и SRE достаточно добавить логику хаоса, чтобы провести новый эксперимент.
Litmus использует собственный облачный подход для создания, управления и мониторинга хаоса. Хаос организован с использованием Custom Resource Definitions (CRD) Kubernetes:
ChaosEngine: ресурс для связи приложения Kubernetes или узла Kubernetes с ChaosExperiment. ChaosEngine наблюдает Chaos-Operator Litmus, который затем вызывает Chaos-Experiments.
ChaosExperiment: ресурс для группировки параметров конфигурации эксперимента хаоса. CR ChaosExperiment создаются оператором, когда эксперименты вызываются ChaosEngine.
ChaosResult: ресурс для хранения результатов эксперимента с хаосом. Экспортер Хаоса считывает результаты и экспортирует метрики на настроенный сервер Prometheus.
В этой лабораторной работе вы узнаете, какы:
Сконфигурируем Litmus в Kubernetes.
Настроим эксперименты Litmus, RBAC и подготовим Chaos Engine.
Проведем эксперименты с хаосом.
Пронаблюдаем за Chaos Engine.
Давайте начнем с вывода информации о кластере и helm
Любой набор приложений можно сделать подходящей целью для такой системы хаоса, как Litmus. Для этой практики мы установим стандартное приложение NGINX и сделаем его целевым. Установим NGINX в пространство имен по умолчанию:
Установим оператор Litmus
Есть несколько способов установить Litmus. Мы будем использовать Helm, следуя инструкциям по установке Litmus с помощью Helm.
Пререквизиты:
Движок Litmus хранит свои данные о состоянии в Mongo, и это хранилище данных должно быть привязано к тому(Volume) объемом не менее 20 Гигабайт. Создайте директорию для хранилища прямо здесь, на мастер ноде(control plane node):

Свяжите этот путь с PersistentVolume, на который может проклеймить Mongo:
kind: PersistentVolume apiVersion: v1 metadata: name: pv0001 labels: type: local spec: capacity: storage: 20Gi accessModes: - ReadWriteOnce hostPath: path: "/tmp/data01"

Теперь добавим Litmus Helm Repo:

Установим Litmus ChaosCenter:

Litmus также предлагает нам весьма удобный WebUI, который ранится на NodePort 31000, но перед этим мы должны запустить его:
apiVersion: v1 kind: Service metadata: name: chaos-litmus-frontend-service-fixed annotations: meta.helm.sh/release-name: chaos meta.helm.sh/release-namespace: litmus labels: app.kubernetes.io/component: litmus-frontend app.kubernetes.io/instance: chaos app.kubernetes.io/name: litmus app.kubernetes.io/part-of: litmus app.kubernetes.io/version: 2.7.2 litmuschaos.io/version: 2.7.0 spec: type: NodePort ports: - name: http nodePort: 31000 port: 9091 protocol: TCP targetPort: 8080 selector: app.kubernetes.io/component: litmus-frontend sessionAffinity: None

Теперь откройте дэшборд по порту 31000(дефолтные логин и пароль admin / litmus) :


Проверим наличие Litmus ChaosCenter.
В пространстве имен litmus находятся компоненты плоскости управления для движка Litmus.

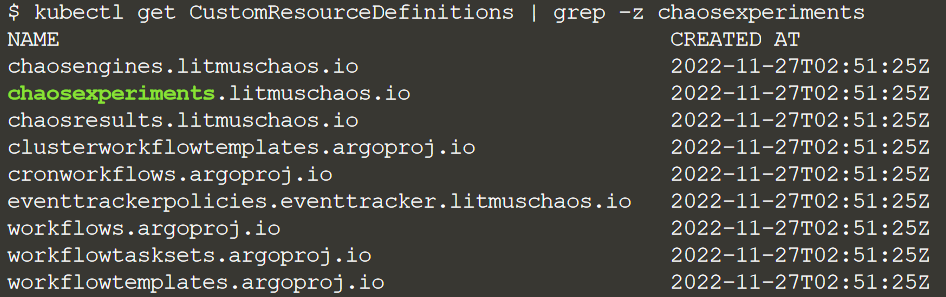
После того, как мы получили доступ к WebUI - запускается оператор Litmus, и появляются следующие CustomResourceDefinitions:
В следующем шаге мы определим новый эксперимент с kind: ChaosExperiment.
Хаос эксперименты устанавливаются в вашем кластере как объявления ресурсов Litmus в форме CRD Kubernetes. Поскольку эксперименты с хаосом — это всего лишь YAML-манифесты Kubernetes, эти эксперименты публикуются на Chaos Hub.
Мы же попробуем один из самых распространенных экспериментов, который убивает поды Подробнее об этом эксперименте можно узнать здесь.
Давайте рассмотрим поподробнее на детали эксперимента, прежде чем его запустить:

apiVersion: litmuschaos.io/v1alpha1 description: message: | Deletes a pod belonging to a deployment/statefulset/daemonset kind: ChaosExperiment metadata: name: pod-delete labels: name: pod-delete app.kubernetes.io/part-of: litmus app.kubernetes.io/component: chaosexperiment app.kubernetes.io/version: 2.7.0 spec: definition: scope: Namespaced permissions: # Create and monitor the experiment & helper pods - apiGroups: [""] resources: ["pods"] verbs: ["create", "delete", "get", "list", "patch", "update", "deletecollection"] # Performs CRUD operations on the events inside chaosengine and chaosresult - apiGroups: [""] resources: ["events"] verbs: ["create", "get", "list", "patch", "update"] # Fetch configmaps details and mount it to the experiment pod (if specified) - apiGroups: [""] resources: ["configmaps"] verbs: ["get", "list"] # Track and get the runner, experiment, and helper pods log - apiGroups: [""] resources: ["pods/log"] verbs: ["get", "list", "watch"] # for creating and managing to execute comands inside target container - apiGroups: [""] resources: ["pods/exec"] verbs: ["get", "list", "create"] # deriving the parent/owner details of the pod(if parent is anyof {deployment, statefulset, daemonsets}) - apiGroups: ["apps"] resources: ["deployments", "statefulsets", "replicasets", "daemonsets"] verbs: ["list", "get"] # deriving the parent/owner details of the pod(if parent is deploymentConfig) - apiGroups: ["apps.openshift.io"] resources: ["deploymentconfigs"] verbs: ["list", "get"] # deriving the parent/owner details of the pod(if parent is deploymentConfig) - apiGroups: [""] resources: ["replicationcontrollers"] verbs: ["get", "list"] # deriving the parent/owner details of the pod(if parent is argo-rollouts) - apiGroups: ["argoproj.io"] resources: ["rollouts"] verbs: ["list", "get"] # for configuring and monitor the experiment job by the chaos-runner pod - apiGroups: ["batch"] resources: ["jobs"] verbs: ["create", "list", "get", "delete", "deletecollection"] # for creation, status polling and deletion of litmus chaos resources used within a chaos workflow - apiGroups: ["litmuschaos.io"] resources: ["chaosengines", "chaosexperiments", "chaosresults"] verbs: ["create", "list", "get", "patch", "update", "delete"] image: "litmuschaos/go-runner:2.7.0" imagePullPolicy: Always args: - -c - ./experiments -name pod-delete command: - /bin/bash env: - name: TOTAL_CHAOS_DURATION value: '15' # Period to wait before and after injection of chaos in sec - name: RAMP_TIME value: '' - name: FORCE value: 'true' - name: CHAOS_INTERVAL value: '5' ## percentage of total pods to target - name: PODS_AFFECTED_PERC value: '' - name: LIB value: 'litmus' - name: TARGET_PODS value: '' ## it defines the sequence of chaos execution for multiple target pods ## supported values: serial, parallel - name: SEQUENCE value: 'parallel' labels: name: pod-delete app.kubernetes.io/part-of: litmus app.kubernetes.io/component: experiment-job app.kubernetes.io/version: 2.7.0
Обратите внимание, что TOTAL_CHAOS_DURATION составляет 15 секунд, а CHAOS_INTERVAL — 5 секунд. Это означает, что под nginx будет удаляться каждые 5 секунд в течение 15 секунд, 3 раза.
Установим наш эксперимент:

Проверим установку:

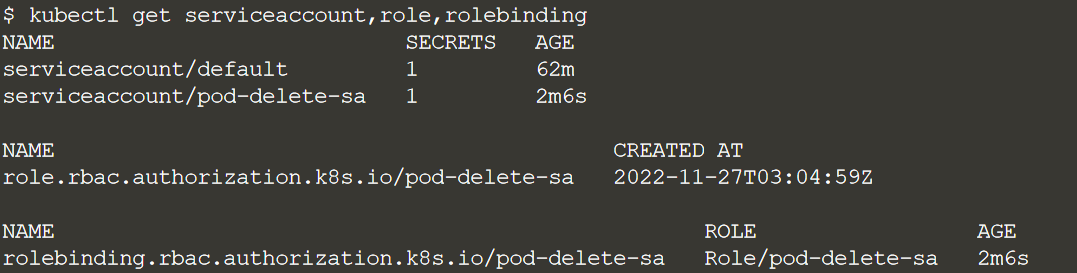
Нам необходимо будет создать сервис аккаунт, чтобы ChaosEngine мог проводить эксперименты в пространстве имен нашего приложения.
Примените role-base access control (RBAC) для эксперимента:

Убедимся, что для pod-delete-sa применены правила RBAC ServiceAccount:
Приложение может сообщить Litmus, что оно является подходящей целью для эксперимента. Один из способов — аннотировать приложение. В этом случае мы аннотируем деплоймент NGINX с помощью litmuschaos.io/chaos="true":

Это выборочное нацеливание является мерой безопасности и средством контроля радиуса действия эксперимента. Убедимся, что аннотация была применена:

Убедимся, что под приложения готов. Этот под является целью эксперимента в радиусе действия нашего хаоса:

Мы запускаем Эксперимент
Эксперимент развернут, и цель эксперимента установлена. Все, что осталось сделать, это дать команду движку начать эксперимент:

Начинаем смотреть поды в пространстве имён по умолчанию:

Через мгновение запустится модуль nginx-chaos-runner. Этот Pod создан движком Litmus на основе критериев эксперимента. Через мгновение ранер хаоса создаст новый под с именем pod-delete-<hash>. Этот под отвечает за фактическое удаление пода. Вскоре после запуска пода pod-delete-<hash> мы заметим, что под NGINX убит. Разумеется, контроллер развертывания Kubernetes перезапустит новый под NGINX. Во время эксперимента мы сможем увидеть, как состояние модулей меняется с «Running» на «Container Creating», «Completed» на «Terminating» в зависимости от примененного хаоса.Именно во время завершения и перезапуска этого модуля наши пользователи почувствуют сбои. Поскольку только один под обслуживает весь подразумеваемый пользовательский трафик, этот эксперимент покажет, что у нас недостаточно масштабируемых экземпляров для беспрепятственной обработки трафика без сбоев во время ошибок или сбоев.
Результаты эксперимента накапливаются в объекте ChaosResult, связанном с экспериментом. Мы можем проверить результаты:

В ходе эксперимента статусу status.verdict присваивается значение «Awaited», которое в конечном итоге меняется на «Pass» или «Fail».
Пользуясь случаем, приглашаю на открытое занятие по устройству kubernetes. На этом уроке изучим, из каких основных и вспомогательных частей состоит кластер-kubernetes, и поймем, чем отличаются компоненты и как взаимодействуют друг с другом. Регистрируйтесь по ссылке.

