
И снова здравствуй, Хабр! Сегодня поговорим об актуальной для многих из нас проблеме при работе с базами данных. В ходе работы над разными проектами часто приходится создавать базу данных (командное пространство, песочница и т.п.), которую использует как сам автор, так и/или коллеги для временного хранения данных. Как у любого «помещения», в нашей «песочнице» есть своё ограничение по объёму выделенного места для хранения данных. Периодически бывает так, что вы или ваши коллеги забываете об этом маленьком ограничении, из-за чего, к сожалению, заканчивается объём выделенной памяти.
В этом случае можно применить маленький лайфхак, который позволит оперативно просмотреть, какая таблица больше всего занимает место, кто её владелец, как долго она находится в общей песочнице и т.д. Используя его, вы оперативно сможете почистить место в песочнице, предварительно согласовав действия с владельцем данных без нанесения вреда данным остальных коллег. Кроме того, этот инструмент позволит периодически проводить мониторинг наполняемости вашей общей песочницы.

Этап 1
Для начала импортируем нужные нам модули библиотек для Python и определим путь к нашей песочнице.
import subprocess import sys, getopt import re import pandas as pd %matplotlib inline pd.set_option('display.max_colwidth', -1) path = 'hdfs://arnsdpsbx/user/team/team_sandbox/hive'
Модуль subprocess в Python предоставляет простые функции, которые позволяют нам запускать новый процесс и получать их коды возврата.
Модуль getopt — один из вариантов анализа аргументов командной строки. В основном используется для анализа последовательности аргументов.
Модуль re в Python — функции в этом модуле позволяют проверить, соответствует ли строка заданному регулярному выражению (или соответствует ли данное регулярное выражение определённой строке, что сводится к тому же самому).
Модуль pandas — программная библиотека для обработки и анализа данных. Команда %matplotlib inline позволяет построить и вывести нужный вам график прямо в Jupiter notebook (далее в статье).
Этап 2
Далее мы пропишем функции, которые позволят нам сформировать статистику по заполняемости нашей песочницы:
- для определения размера используемой памяти (human_readable_size)
def human_readable_size(size, decimal_places=2): for unit in ['B', 'KiB', 'MiB', 'GiB', 'TiB', 'PiB']: if size < 1024.0 or unit == 'PiB': break size /= 1024.0 return f'{size:.{decimal_places}f} {unit}'
- для поиска и формирования списка пользователей в песочнице (get_ipa_login)
def get_ipa_login(domain, login): if domain == 'Ваш_домен_IPA': return f'{login}_Ваш_домен_IPA' return ''
- для определения территориального подразделения (get_tb)
def get_tb(dept): try: return dept.split('/')[2] except: return '-'
- для определения наименования таблицы в песочнице (get_table_name)
def get_table_name(path): try: return path.split('/')[-1] except: return '-'
- для определения владельца таблицы (get_owner_name)
def get_owner_name(owner, name): return f'{owner} ({name})'
- для определения таблиц «фантомов» без определения владельца
def get_fix_cmd(merge, path, table_name): if merge == 'right_only': return f'DROP TABLE {table_name}' elif merge == 'left_only': return f'hdfs dfs -rm -f -R -skipTrash {path}' return ''
Этап 3
Далее мы создаем Dataframe, содержащий информацию о данных, размещённых в песочнице (данные о владельце, группе, дате, времени, пути размещения таблицы).
out = subprocess.Popen(['hdfs', 'dfs', '-du', path], stdout=subprocess.PIPE, stderr=subprocess.STDOUT) stdout, stderr = out.communicate() if 'GSSException' in stdout.decode('utf-8'): print('GSSException! Run kinit') exit(1) lines = stdout.decode('utf-8').split('\n') list_du = [] for line in lines: m = re.match(r'^(\d+)\s+(\d+)\s+(.*)$', line) if m: list_du.append([ int(m.group(1)), int(m.group(2)), m.group(3) ]) df_du = pd.DataFrame(list_du, columns=['fsize', 'disk_space_consumed', 'path']) out = subprocess.Popen(['hdfs', 'dfs', '-ls', path], stdout=subprocess.PIPE, stderr=subprocess.STDOUT) stdout, stderr = out.communicate() lines = stdout.decode('utf-8').split('\n') del lines[0] list_ls = [] for line in lines: list_ls.append(line.split()) df_ls = pd.DataFrame(list_ls, columns=['permission', 'links', 'owner', 'group', 'size', 'date', 'time', 'path']) df_ls.dropna(how='all', inplace=True) df_ls.drop(['permission', 'links', 'size'], axis=1, inplace=True)
По написанному коду мы получаем данные о владельце, группе, дате, времени, пути размещения таблицы.
Этап 4
Не забывая о коллегах, мы добавляем в наш Dataframe подробную информацию о пользователях, которым предоставлены права и которые используют нашу «песочницу». В нашем случае данные о пользователях и их принадлежности к территориальному подразделению мы взяли из сsv файла. В целом скрипт можно улучшить, настроив выгрузку на получение данных из системы учёта пользователей IPA (в нашем случае это Red HAT Identity Management).
df_users = pd.read_csv('ad_users.csv', encoding='windows-1251', sep='|', header=None, names=['domain', 'login', 'tn', 'full_name', 'position', 'dept'], index_col=False) df_users['ipa_login'] = df_users.apply(lambda row: get_ipa_login(row.domain, row.login), axis=1)
Этап 5
После формирования баз с необходимой для нас информацией о таблицах и пользователях мы объединяем эти данные в единую базу данных.
df_hdfs = pd.merge(df_du, df_ls, on='path') df_hdfs['fsize_h'] = df_hdfs['fsize'].apply(lambda x: human_readable_size(x)) df_hdfs['disk_space_consumed_h'] = df_hdfs['disk_space_consumed'].apply(lambda x: human_readable_size(x)) df_hdfs = df_hdfs.reindex(columns=['path', 'owner', 'group', 'fsize', 'fsize_h', 'disk_space_consumed', 'disk_space_consumed_h', 'date']) df_hdfs = pd.merge(df_hdfs, df_users, how='left', left_on='owner', right_on='ipa_login') df_hdfs['owner_name'] = df_hdfs.apply(lambda row: get_owner_name(row.owner, row.full_name), axis=1) df_hdfs['tb'] = df_hdfs['dept'].apply(lambda x: get_tb(x)) df_hdfs['table_name'] = df_hdfs['path'].apply(lambda x: get_table_name(x))
Этап 6
Делаем ещё пару шагов для получения более точного наименования таблиц, размещённых в нашей «песочнице», собирая воедино и «отсекая» ненужную информацию.
out = subprocess.Popen([ 'beeline', '--outputformat=csv2', '--silent=true', '--showHeader=false', '--verbose=false', '--showWarnings=false', '-u', '"jdbc:hive2://<URL JUPITER HUB без https:// >:10000/default;principal=hive/_HOST@ВАШ домен"', '-e', '"show tables in Наименование Песочницы (башей базы);"' ], stdout=subprocess.PIPE, stderr=subprocess.STDOUT) stdout,stderr = out.communicate() lines = stdout.decode('utf-8').split('\n') list_tables = [] for line in lines: if 'warning:' not in line: list_tables.append(line) df_tables = pd.DataFrame(list_tables, columns=['table_name']) df_tables.dropna(how='all', inplace=True)
В результате написанный код формирует наименование таблицы, установленное пользователем при её создании.
После проведения подготовительных мероприятий по написанию кода и создания нужных нам данных в DataFrame перейдём к самому интересному — к просмотру результатов и анализу заполняемости нашей «песочницы».
Начнём с самого простого и выведем топ-10 таблиц по размерам использования памяти в «песочнице» с информацией о коллегах, которые их создали.
df_hdfs_top = df_hdfs.sort_values(by=['fsize'], ascending=False).head(10)[['path', 'fsize_h', 'owner_name']] df_hdfs_top

Теперь давайте посмотрим на пользователей, которые больше всего занимают место в «песочнице», и выведем топ-10 из них.
df_hdfs_size_by_owner = df_hdfs.groupby('owner_name')['fsize'].sum().reset_index().sort_values(by=['fsize']).tail(10) df_hdfs_size_by_owner.plot(x='owner_name', y='fsize', kind='barh')

Одновременно посмотрим на заполняемость «песочницы» в разрезе территориальных подразделений.
df_hdfs_size_by_tb = df_hdfs.groupby('tb')['fsize'].sum().reset_index().sort_values(by=['fsize']) df_hdfs_size_by_tb.plot(x='tb', y='fsize', kind='barh')
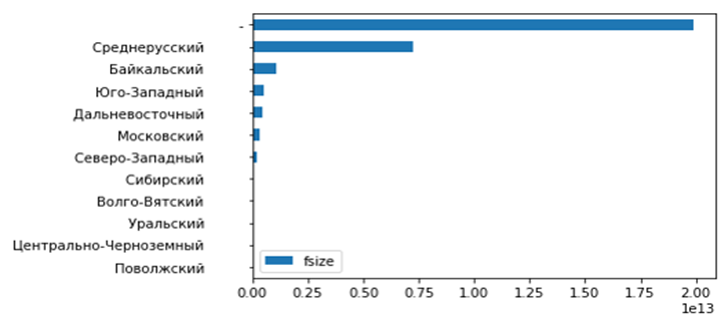
При необходимости посмотрим на наши таблицы по дате их создания, для уточнения у коллег их актуальности и планов по дальнейшему использованию.
df_hdfs_oldest = df_hdfs[df_hdfs.fsize > 10000].sort_values(by=['date'], ascending=False).tail(50) df_hdfs_oldest

Для более подробного просмотра результатов выгрузим данные в отдельный файл, который более подробно нам покажет информацию о таблицах, их объёме и владельцах.
df_hdfs_top = df_hdfs[df_hdfs.fsize > 10000].sort_values(by=['fsize'], ascending=False) df_hdfs_top.to_csv('team_sandbox.csv', index=False)
Что ещё?
Также вы можете столкнуться с ситуацией, когда в вашей «песочнице» находятся HDFS файлы «фантомы» — таблицы без каталога и/или каталог без таблицы, а также файлы без принадлежности к определённому владельцу. Для их определения воспользуемся следующим кодом:
df_fantoms = pd.merge(df_hdfs, df_tables, how='outer', on='table_name', indicator=True).sort_values(by=['fsize'], ascending=False) df_fantoms['fix_cmd'] = df_fantoms.apply(lambda row: get_fix_cmd(row._merge, row.path, row.table_name), axis=1) df_fantoms = df_fantoms.reindex(columns=['path', 'table_name', 'owner_name', 'fsize', 'fsize_h', 'fix_cmd', '_merge'])
- для просмотра таблиц без каталога сформируем запрос
df_fantoms[df_fantoms._merge=='right_only']
- для просмотра каталогов без таблиц сформируем следующий запрос
print(human_readable_size(df_fantoms[df_fantoms._merge=='left_only']['fsize'].sum())) df_fantoms[(df_fantoms._merge=='left_only') & (df_fantoms.fsize > 1000000000)]
- для более подробного просмотра и анализа «фантомов» выгрузим данные в отдельный файл
df_fantoms[(df_fantoms._merge=='left_only') & (df_fantoms.fsize > 1000000000)].to_csv('team_sandbox_fantoms.csv', index=False)
Данный подход является не единственным способом найти СЛОНА в «песочнице»: существует множество вариантов его реализации, от использования команд HDFS c её различными параметрами до написания Python кода под другим «углом» в зависимости от особенностей ведения вашей базы.
