

Всем привет! Меня зовут Александр Шерман, я тимлид в команде CRM в Самокате. Мы в первую очередь известны по своей модели доставки заказов от 15 минут. Чтобы укладываться в такой норматив, у нас достаточно жёсткие SLA (2,5 минуты на сборку заказа), что, в свою очередь, диктует строгие требования к надёжности и быстродействию сервисов.
Часть проектов у нас написана на Ruby. Если раньше в качестве web-сервера для них мы использовали Puma (который уже стал de-facto стандартом) и горя не знали, то в определённый момент нам его производительности стало не хватать. В статье, сделанной по мотивам моего доклада на конференции Ruby Russia 2022 расскажу, как и зачем мы переехали на другой веб-сервер.
Причины нагрузочного тестирования
Для продуктов, использующих Kubernetes, вопросы нагрузки обычно решаются включением автоскейлинга и горизонтальным масштабированием.
В привычной обстановке вы просто выкатываетесь на прод с Puma. Некоторые Ruby-сервисы не дорастают до нагрузок, при которых в принципе имеет смысл думать про оптимизацию, для других оптимизация производительности происходит путём добавления ресурсов в облако.
Однако задумываемся ли мы, насколько эффективно мы используем запрошенные ресурсы? Возможно, мы зря тушим пожар нагрузки деньгами?
Ситуация в Самокате отличается от обычной тем, что автоскейлинга у нас нет — мы живём на своём железе, а не в облаках, так что просто добавить ресурсов мы не можем — нам надо понимать, сколько ещё необходимо докупать оборудования etc.
А ещё есть команда PerfOps, которая разрабатывает и распространяет по продуктовым командам фреймворк для организации нагрузочного тестирования наших сервисов. Фреймворк позволяет, используя собственный DSL, создавать тестовые сценарии, приближённые к реальному профилю работы пользователей.
ПРИМЕЧАНИЕ. Если вы хотите узнать подробнее о нашем подходе к PerfOps, рекомендую вам статью моего коллеги Кирилла Юркова. Добавлю, что в качестве инструмента подачи нагрузки мы используем JMeter.
Тестирование
В Самокате нагрузочное тестирование обязательно перед вводом сервиса в эксплуатацию. В нашей практике SRE мы начинаем подбирать конфигурацию для прода с минимально разумных значений на одном инстансе исходя из трёхкратной расчётной нагрузки (для mission critical сервисов этот коэффициент может быть ещё больше). Расчётной нагрузкой на сервис мы посчитали 100 RPS (requests per second — запросов в секунду), а тестировали сервис на нагрузке в 300 RPS. Для Ruby-сервисов сотни, а не тысячи запросов в секунду — это нормально, да и мы подбираем минимально квантуемую конфигурацию, которую сможем потом пропорционально наращивать.
Мы хотели протестировать один наиболее нагруженный ресурс. Например, GET /orders, который отдаёт нашему пользователю список заказов.
ПРИМЕЧАНИЕ. Названия ресурсов выдуманы, все совпадения случайны.
Однако, в реальной жизни профиль работы выглядит примерно так:
Получить JWT в /auth
Ходить с этим JWT в /orders
При этом есть некоторое соотношение в количестве запросов в /auth, /orders, которое тоже нужно учитывать (например, на 1 запрос /auth приходится 1000 запросов /orders).
Наш тест сконфигурирован таким образом, чтобы давать нагрузку от 50 до 300 rps ступенчато, чтобы увидеть предел, после которого наше приложение развалится. Нагрузка подаётся по открытой модели — это, скорее, стресс-тестирование, т.е. мы пытаемся моделировать реальное пользовательское поведение.
Конфигурация тестового стенда:
2 CPU
1024 Mb RAM
1 instance
Конфигурация веб-сервера Puma:
Threads: 5:5
Workers: 2
Почему именно так? В нашей практике SRE мы начинаем подбирать конфигурацию для прода с минимально разумных значений на одном инстансе. Сначала мы добиваемся полной утилизации ресурсов одного инстанса без скейлинга, затем решаем, сколько инстансов запускать.
Кроме того, со стороны SRE применяется требование, чтобы один инстанс приложения генерировал не больше 10 коннекшенов к БД, поэтому получается такая конфигурация: 2 воркера * 5 тредов = 10 коннекшенов. Почему десять? Нам нужен понятный триггер к горизонтальному масштабированию. Пока не упёрлись в коннекты, можно масштабироваться вертикально, когда упёрлись — приходится масштабироваться горизонтально. Внутри БД десять соединений приводит к понятному потреблению ресурсов, так что мы договорились, что квантуем по десять.
Результаты тестирования
Итак, мы запустили тест… и получили жуткий разброс между минимальными и максимальными значениями, а также совершенно неприемлемое время ответа в 90, 95 и 99 перцентилях. Процент ошибок тоже зашкаливает. Соответственно, нагрузочное тестирование не пройдено, на прод в таком виде катиться нельзя.

Основные результаты теста:
50% запросов завершилось с ошибками.
Все ошибки связаны с недоступностью нашего веб-сервера.

Рассмотрим на собранную информацию детально.

Самый интересный график — корреляция между RPS, Error Rate и Response time. Наш фреймворк настроен так, чтобы любыми средствами достичь желаемых RPS (в нашем случае — 300). Поэтому, если приложение начинает отвечать медленнее (т. е. RPS падает), JMeter докидывает тредов в пул и тем самым достигает целевого значения RPS, при этом, естественно, «закапывая» наш веб-сервер ещё больше — он эмулирует реальную нагрузку от пользователей.
На графике видно, что, когда нагрузка достигла примерно 170 rps, наше приложение ещё какое-то время справлялось (нулевое количество ошибок (красная область)). Но при этом latency (жёлтая область) стала лавинообразно расти и почти одновременно с её пиком взлетели throughput (голубая кривая) и количество ошибок (красная область), а latency упала до нуля. Это повторилось несколько раз.

На этом графике мы видим, что количество занятых тредов Puma растёт при повышении RPS и на определённом этапе (когда на предыдущем графике начинает расти latency) упирается в максимум, после чего падает до нуля. Кроме того, на графике виден обрыв телеметрии и картина с занятыми тредами повторяется, причём восстановление происходит не плавно, а резким скачком до максимального количества.
Очевидно, что если все треды Puma сейчас заняты, то новые запросы ставятся в очередь: сначала - в todo Puma, затем - в socket backlog, который тоже не бесконечный и может накопить только 1024 запроса по умолчанию, соответственно, все следующие не будут приняты.
Мы начали разбираться с обрывами в телеметрии и зубчатым характером графика в целом и посмотрели на метрику перезапусков пода в контейнере. Оказалось, что во время теста он был перезапущен, поэтому появились провалы в метриках.

Но почему он перезагружался? Потребление CPU не поднималось выше 1 (при установленном лимите 2). При этом троттлинга не было (график лежит на нуле).

График потребления RAM показывает, что все хорошо и нигде не «протекает». Провалы в 0 указывают на моменты перезапуска пода.

Так почему же приложение перезагружалось, если использовало не более половины от запрошенных ресурсов?
Ответ прост и спрятан на графике, который показывает полностью забитый бэклог веб-сервера. Поскольку наш liveness probe в k8s тоже ходит в этот же веб-сервер, чтобы удостовериться, что он живой, то он точно так же, как и запросы от JMeter, попадает сначала в бэклог, а затем в unaccepted connections и k8s перезагружает под.

Гипотеза
Каковы причины такого поведения? В качестве одной из рабочих версий мы приняли, что ответ может крыться в особенностях веб-сервера Puma. Puma — это threaded web server, а это значит, что GVL переключает контекст между тредами через равные промежутки времени (по таймеру).
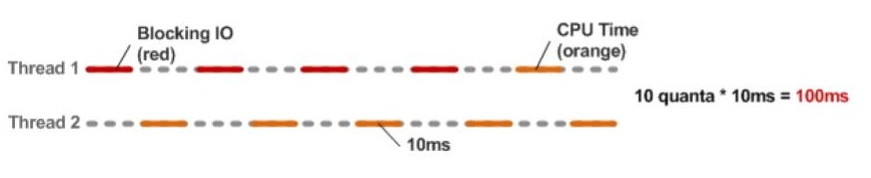
Вспомним, что из себя представляет наш тест:
авторизация (в нашей архитектуре это поход в API соседнего сервиса по сети);
запрос списка заказов из БД.
Оба этих действия порождают синхронные вызовы, блокирующие наш текущий тред (процесс вынужден ждать результата выполнения запросов).
Поскольку у нас нет возможности программно влиять на то, как переключать контекст выполнения программы между тредами, GVL (он же global interpreter lock, GIL) делает это равными квантами. И, если контекст переключился на тред, который по-прежнему чем-то заблокирован, мы просто потеряли этот квант времени впустую.
Кроме того, помимо возможных потерь из-за блокировок, не стоит забывать о capacity самого веб-сервера, который в случае с Puma равен максимальному количеству тредов веб-сервера RAILS_MAX_THREADS (они же - максимальное количество коннектов к БД).
Мы решили проверить гипотезу с IO и изменили тест таким образом, чтобы наше приложение не выполняло никаких полезных операций, а сразу давало клиенту отбивку на любой запрос.

Latency начинает расти чуть позже — с 250 rps вместо 170 rps с IO, но в целом картина с перезапуском пода повторилась.
При этом увеличение RAILS_MAX_THREADS для Puma до максимально допустимых значений ничего не дало, а только позволило немного отсрочить момент, когда Puma уже не справляется.
Получается, что Puma просто захлёбывается запросами, поэтому нужен способ увеличить capacity нашего приложения. Очевидно, что треды не позволят нам этого добиться, поэтому мы решили найти другой выход.
Falcon
Мы решили посмотреть, что нам может дать другой application server, и наш выбор пал на Falcon — fiber-based web server, который мало кто использовал до выхода третьей версии Ruby из-за отсутствия в языке нативного планировщика файберов.
Процесс переезда был достаточно безболезненным:
Сперва мы настроили Sequel (мы используем Sequel вместо AR),
Затем подключили fiber concurrency.
Ни одной строчки кода приложения в процессе переезда не пострадало!
И вот мы запускаем два процесса Falcon — по количеству CPU на тестовом стенде. Время ответа 95% уменьшилось с 1.46 s до 609 ms, но самое важное — полностью исчезли ошибки!

Можно посмотреть поведение приложения под нагрузкой: latency начинает расти примерно в районе 330 rps (против 170 rps у Puma), но рост остановился, а далее веб-сервер держал честные 350 rps и не зафейлил ни один запрос!
JMeter упёрся в ограничение в сто тредов, чего ему хватило для эмуляции целевой нагрузки.

ПРИМЕЧАНИЕ. Далее мы посмотрим, что с такой конфигурацией приложения делает большее количество тредов JMeter-а.
График потребления памяти выглядит несколько по-иному, нежели у Puma, Falcon набирал память плавно по мере роста нагрузки.

CPU добирается до 1.4 из 2.0. Троттлинга нет.

Сводные результаты теста Falcon и Puma:

* Мы считаем это пределом при 2 CPU лимита. В настоящее время мы проверяем, связано ли такой уровень потребления с багом в ядре Linux.
Напомним, что эти результаты получены без каких-либо изменений кодовой базы вообще и на одинаковой конфигурации тестового сервера.
Можно ли ещё быстрее? Как оказалось, можно, но надо программировать. Хотя мы и взяли fiber-based веб-сервер, но само приложение (точнее, connection pool к PG) это не учитывает и преимущества файберов не использует. Мы решили это поправить и «накидали» собственный простенький FiberConnectionPool.

Resp. time 95% уменьшился с 600 ms до 350 ms, avg — с 200 ms до 150 ms. Ошибок и таймаутов нет.
Рассмотрим, где приложение начало задыхаться. Latency пополз вверх в районе 400 rps (без fiber connection pool было 330).

Характер графика потребления памяти практически не изменился. На графике виден момент, когда Falcon начал активно набирать память, что совпадает с наращиванием JMeter количества одновременных тредов.

Утилизация CPU всё так же дошла до 1,3 и и на этом остановилась, начался троттлинг.

Напомним, что это всё без единой переделки в бизнес-логике приложения (не понадобилось ничего переписывать в application логике или обвязке, и пришлось написать только Fiber Connection Pool).
Итоги тестирования:

Можно ли разломать Falcon?
В текущей конфигурации теста мы не смогли «завалить» Falcon.

JMeter пытается достичь целевых RPS любыми средствами. Если приложение не справляется, JMeter будет повышать количество своих потоков. Но в наших тестах было установлено максимальное количество потоков = 100. На графиках выше видно (сиреневый пунктир), что в районе 400 rps latency приложения начинает расти, и чтобы компенсировать это и продолжать наращивать суммарный throughput, JMeter пытается увеличивать количество потоков, но очень быстро упирается в 100 и больше не может выжать из приложения ничего (при этом оно всё ещё работает, хоть время ответа и деградировало до 300 ms).
Чтобы разломать Falcon, мы разрешили JMeter использовать до 1000 потоков, и вот какую картинку мы увидели (на файбер-пуле). В районе 400 rps latency начала расти, а RPS падать. JMeter тут же начал добавлять потоки, чтобы это компенсировать. Но одновременно с этим начало расти и время ответа.

На иллюстрации увеличен один из пиков с ошибкой, но Falcon стойко держался в течение нескольких минут и сдался, только когда супервайзер k8s перезапустил под по причине недоступности liveness probe, точно так же, как это происходило с Puma. С той лишь разницей, что у Puma это случилось на 120 RPS и 70 потоках JMeter, а у Falcon- на 600 RPS и 730 потоках JMeter! На графике красная область — это ошибки 503 Service Unavailable из-за перезапуска пода.
Чтобы убедиться, что эта конфигурация линейно масштабируется, мы удвоили количество CPU и провели такой же тест.

Уровень деградации вырос примерно на 800 RPS, что вполне метчится с 400 RPS на 2 CPU.
Подводные камни и выводы
Ну а теперь постараюсь резюмировать:
Пришлось отказаться от yabeda-puma-plugin, а для Falcon нет плагина для Prometheus.
Метрики не лежат на поверхности, в Falcon надо их «копать».
В Falcon нет таймаутов по умолчанию, все соединения персистентные. Таймауты задаются в рантайме отдельно написанной нами middleware.
Middleware также пришлось написать для переработки в рабочий вид body params.
Мы для себя оцениваем вероятность сделать Falcon дефолтным веб-сервером в платформе Ruby как весьма высокую, и точно будем продолжать эксперименты с ним.
Конфигурация Falcon + Fiber Connection Pool в проде только пилотируется, а вот Falcon + Threaded Connection Pool уже работает в проде больше месяца.
Что можем посоветовать? Файберы — перспективная история, и, чем больше людей будет пользоваться, тем перспективнее будет.
Проект Socketry активно развивается, а буквально на днях появился новый репозиторий db-active_record, где, судя по всему, появится асинхронный адаптер для ActiveRecord, что сделает работу с файберами более доступной для большинства приложений на Rails.
В Falcon есть экспериментальный гибридный режим (как Puma в cluster mode), что может дать дополнительный прирост производительности (но мы этого ещё не пробовали).
В заключение хотелось бы поблагодарить коллег, которые провели исследование, по материалам которого написана эта статья, — Виталия Печерина и Дениса Лукьянова.
