Программист обязательно ставит на тумбочку у кровати два стакана: один полный, на случай, если он проснётся и захочет пить, а другой пустой — вдруг он не захочет. Так гласит известный анекдот. Но в реальной жизни часто работают законы Мерфи, и предусмотренные планы рушатся. Что же делать программисту на случай, если он проснётся и не поймёт, хочет он пить или нет?
Наверное, самый зубдробительный для меня темой в курсах Высшей Математики была Алгебра. Это не та милая, ламповая школьная алгебра, плавно переходящая в любимые мной диффуры, да ещё если в исполнении Киселёва... Нет. Это множества, дурацкие полуочевидные теоремы, странные термины, идеалы, ¡алгебры!, кольца (йуный ум скорее задумается об обручальных, право слово). В общем, за исключением полей, для нас, агрономов, это были вещи настолько же нудные, насколько и бесполезные. Прямо как с Военной Кафедрой: есть, ¡есть! методики преподать даже самый интересный и увлекательный предмет так, чтобы всем слушателям без исключения просто сводило скулы от скуки.
А можно ли позорный недуг в подвиг определить? В конце-концов, скучность алгебры в её совершенной оторванности от жизни, абстрактности, приближающейся к известному плагиату картины А. Алле «Combat de negres dans une cave, pendant la nuit». Абстрактность, абстрагирование, обобщение, «для всех вместе и никого в частности...» Вроде бы общие понятия на то и общие, что должны быть применимы просто везде?
«Ну вот и попробуй, примени.» — с этими словами к себе, я и начну рассказ.
Решётки и полурешётки
Всего полгода назад, благодаря чудеснейшему сайту https://github.com/true-grue/Compiler-Development ( @true-grue, ¡СПА-СИ-БО!), а также одноимённому каналу, я начал познавать чудесный мир производства группы А для ИТ. Выражаясь проще, полупрочёл чудесный учебник Anders'а Møller'а „Static Program Analysis“ (https://cs.au.dk/~amoeller/spa/). Увы, не до конца. В оправдание могу лишь прохрипеть как Бильбо у Голлума «Время! Время!». Но, как сказал Пендальф другому хоббиту, «самую суть-то ты ухватил».
A. Møller в книге блестяще сводит различные варианты анализа программ (почти всё, за исключением вывода типов), к работе с разнообразными решётками. Тут нам и анализ знаков, и определение неинициализированных переменных, и liveness анализ... И всё это разное великолепие сводится к решёткам, то есть частично-упорядоченным множествам, у любой пары элементов из которых есть точные верхняя и нижняя граница.
Кстати, странно, что ЧУМы не изучаются в школе — во-первых, они приучают к мысли, что не всегда можно найти «самое лучшее» (типичный вопрос у малышей какая машина лучше?), а во-вторых, название смешное: вроде высоколобые математики, а у них ЧУМ. Может и яранга с оленями?
Более формально, решётка — это множество, на котором определена операция ≤, но не обязательно между любыми двумя элементами с тремя свойствами: транзитивностью (a ≤ b, b ≤ c => a ≤ c), антисимметричностью (a ≤ b и b ≤ a => a=b) и рефлексивностью (a ≤ a). Причём для любых двух элементов a, b, даже если они не сравнимы, есть элемент c, что не меньше их обоих: a ≤ c и b ≤ c. А также существует d, который не превосходит a и b: d ≤ a, d ≤ b.
Эти c и d называются верхней и нижней гранью, а самые «поджимающие» пару a, b, то есть самый «маленький» из разных c и самый «большой» из разных d — точной верхней и точной нижней гранью. Для решётки, собственно, необходимо наличие именно точных граней.
В принципе, и в Википедии на данный момент что-то более-менее правильное написано, но у Møller'а тема раскрыта сильно лучше. Наверное, где-то ещё лучше, но нам достаточно буквально самых начал.
Ладно, всё это слова, мы же любим картинки. Картинки для решёток рисуются исключительно просто, это так называемые диаграммы Хассе. Точки — это элементы множества, рёбра — отношения ≤ (какие есть), а кто выше, то и больше (так, по крайней мере, у математиков в северном полушарии). Вот примеры решёток:
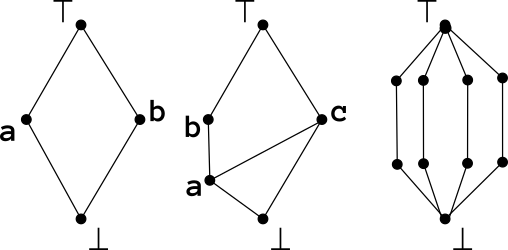
А вот примеры ЧУМ, которые не решётки (последняя решётка, но не полная):

А вот полностью линейно-упорядоченное множество вроде ℝ или ℕ на такой диаграмме будет крайне скучно рисовать, поэтому я не буду. @ReadOnlySadUser — вот вам и упражнение на понимание. :-)
Ну решётки — вещь чудесная, только обещал я использовать лишь половину, а не целую решётку (как говорят в ФТИ РАН „вы столько времени занимаетесь полупроводниками, пора бы и на полные проводники перейти“). Полурешётка — это просто ЧУМ, где есть только верхние грани или только нижние грани. Вот, к примеру:

Совершенно естественно решётки появляются когда у нас есть какое-то множество и мы рассматриваем его всевозможные подмножества. Тут я совершенно беспардонно тисну картинку у Møller'а для множества {0,1,2,3}, потому что Андерс об этом никогда не узнает:

Всё это замечательно, но где же практика, где же слайды? Честно говоря, я всю жизнь пытался держать от зубодробительной практики вроде применений 1С в сельском хозяйстве как можно дальше, поэтому пример может показаться наивным.
Классификация
Допустим, у нас есть пушистый чёрный кот, который ест только рыбу (а пить предпочитает валерьянку, но это неважно). А в добавок к нему есть собака и черноухий кролик. Собака, понятно дело, ест и рыбу, и мясо, а кролик — только морковку. Если мы, чтобы закодировать содержимое холодильника, введём тип

data Еда = Мясо | Рыба | Морковка
то этот тип не будет в полной мере «описывать предметную область». Но вот если мы
достаточно механически начнём строить полурешётку на этом базисе, введя
дополнительно Рыбо-мясо, то станет веселее:
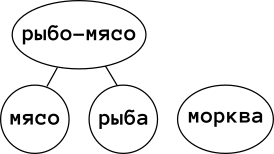
То есть, кот может есть рыбу, собака «Рыбо-мясо», а кролик — морковь. Ладно, со зверьми разобрались, а как же я? Я ведь лучше собаки, и могу есть, собственно, всё. Достроим полурешётку до конца, введя вершину «еда» (мужская, 1кг):
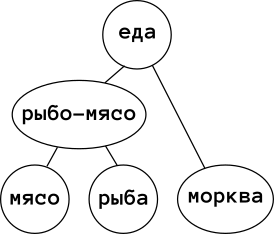
А что эта диаграмма даёт? Фактически, мы построили некоторое «обратное дерево решений». Например, если жена, открыв холодильник, говорит, что «ну зверям есть чем закусить», я знаю, что сам с голоду точно не помру. Или, если осталась еда на кота, а сам кот уехал на дачу, то можно покормить собаку.
Но это мы разобрали случай, когда у нас есть вся информация, всё хорошо и понятно, просто «потребители» разные. Давайте теперь рассмотрим случай, когда у нас наоборот, «что делать?» — кристально понятно, но вот информации об окружении либо недостаточно, либо избыточно (с противоречиями).
Неполная информация
Представим мысленно участок леса, поскольку на полях здесь недостаточно места, чтобы его нарисовать. В лесу растут ёлки, сосны, берёзы и осины. Куда их применять, очевидно: берёзу в баню, осину в колодец, сосну на мачту, а ёлку на Новый Год. Только хочется узнать, сколько же каких деревьев в нашем лесу. И вот некий Вася идёт считать и насчитывает 20 ёлок, 10 сосен, 15 берёз и 17 осин. И всё бы ничего, но ещё 8 деревьев он записал как «пих», дескать иголки у них странные, а ещё 9 как «карельский дуб», дескать какие-то листья у них странные.
В общем, по-хорошему, данные в мусор, Васю в лес, день потерян. Но, может всё-таки, можно что-то вытащить? Мы же знаем, что ещё 8 хвойных, а 9 — точно лиственных. Значит, мы можем тоже построить полурешётку:
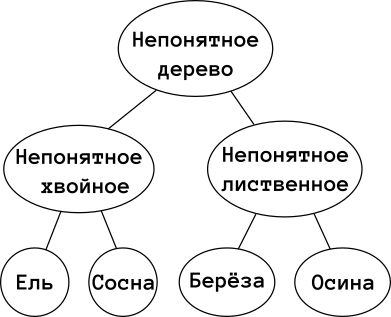
То есть, дополним наш изначальный ADT, который мы держали в уме
data Дерево = Ель | Сосна | Берёза | Осина
ещё двумя позициями: «НепонятноеХвойное», «НепонятноеЛиственное». Ну и для полноты можем добавить «НепонятноеДерево». Фактически, мы использовали что-то вроде полурешётки всевозможных подмножеств, но не совсем:«НепонятноеХвойное = Хвойное \ (Сосна и Ель)».
Эту полурешётку ещё очень удобно использовать для обновления данных. Скажем, сегодня вечером мы классифицировали каждое найденное Васей дерево по этой решётке. А наутро Вася ещё раз сходил в лес и воротился с вестью, что дерево у дороги — это не берёза, а осина. Веры ему на этот раз, конечно, нет, поэтому мы дерево у дороги перезапишем не как осину, а как «НепонятноеЛиственное» — уж листья с иголками Вася наверняка не перепутает. Дальше, конечно, сами можем сходить и уточнить.
А что же позволяет такое кодирование? Мы старались, сберегали информацию, должны и получить какую-то выгоду. И получим! Конечно, мы не можем ответить точно на вопрос «сколько же у нас ёлок?», но зато мы можем совершенно точно ответить на вопросы
а зелёным ли будет лес зимой?
а сколько надо посадить осин, чтобы точно хватило на 45 колодцев?
а хватит ли у нас ёлок для 25 празднеств, если там всё равно напьются и не отличат сосну от ели?
А этих ведь ответов не было, если бы мы просто выбросили «грязные» данные. Да, без сомнения, полная информация была бы лучше, но можем ли мы её заполучить?
То есть, полурешётки и решётки очень удобны для аппроксимации, то есть приближения дискретных данных. Они, фактически, вводят формально понятие неточного дискретного значения. Это широко используется в стат. анализаторах.
Заключение
А задача, которая послужила поводом к статье — классифицировать заголовочные файлы библиотек на интерфейсные (, ) и внутренние (../bits/*). Человеку, знакомому с законами Мерфи сразу понятно, что обязательно будет «серая зона» — когда мы что-то про заголовок знаем, но как-то неотчётливо. И вот для того, чтобы сразу, на этапе прикидок проектирования поймать эту «серую зону», втиснуть её в жёсткие рамки формализации, очень удобны решётки. То есть, когда мы видим какую-то классификацию и знаем, что тут законы Мерфи действительно работают, нужно сразу же прикинуть, а какую решётку, подобную «лесной» тут есть смысл построить?
Так что же с программистом? Конечно, надо поставить стакан с пивом!
P.S.
На КДВП изображён чум, а буквы лямбда схематично обозначают оленей.

