Привет, Хабр!
Мы, Новицкий Никита и Миквельман Дарья специалисты Data Engineer и являемся участниками профессионального сообщества NTA. Расскажем как найти квартиру мечты с помощью методов регрессионного анализа.

В настоящее время найти квартиру себе по душе с идеальным расположением, площадью и инфраструктурой – одна из самых сложных и в то же время актуальных задач. Нужно обратить внимание на множество факторов – из каких материалов и как давно построен дом, в каком он состоянии, сколько в нем этажей, его расположение и, конечно, его стоимость. На данный момент сложившаяся в стране экономическая ситуация не предвещает снижения цен на недвижимость. Но что если рассмотреть зависимость стоимости квартиры от материала, из которого построен дом, или от количества этажей в нем на основе регрессионной модели и спрогнозировать стоимость на объекты недвижимости, опираясь на их свойства и параметры?
Для анализа ситуации на рынке недвижимости будем использовать готовый датасет, который состоит из списков уникальных объектов популярных порталов по продаже недвижимости в России. Набор данных содержит информацию о месторасположении дома, материале, из которого он построен (кирпичный, панельный, деревянный и т.д.), количестве этажей, площади квартиры и его стоимости.
Набор данных состоит из 13 полей:
date - дата публикации объявления;
time – время публикации;
geo_lon - широта
geo_lat - долгота
region - регион
building_type - 0 - Другой. 1 - Панельный. 2 - Монолитный. 3 - Кирпичный. 4 - Блочный. 5 - Деревянный
object_type - Тип квартиры. 1 - Вторичный рынок недвижимости; 2 - Новостройка;
level - этаж квартиры
levels - количество этажей в доме
rooms - количество жилых комнат. Если значение равно "-1", то это означает "однокомнатная квартира"
area - общая площадь квартиры
kitchen_area - площадь кухни
price - цена в рублях
from warnings import filterwarnings import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as sns filterwarnings('ignore')
Проведем предварительную корректирующую обработку данных для упрощения дальнейшего анализа и визуализации полученных результатов.
Для начала, проверим, есть ли в используемом наборе данных пропущенные значения:
Предварительно установим необходимые для обработки наших данных библиотеки:
for col in df.columns: pct_missing = np.mean(df[col].isna()) print(f'{col} - {round(pct_missing * 100)}%')
price - 0% date - 0% time - 0% geo_lat - 0% geo_lon - 0% region - 0% building_type - 0% level - 0% levels - 0% rooms - 0% area - 0% kitchen_area - 0% object_type - 0%
Пропущенные значения в данных отсутствуют.
Следующим шагом удалим из имеющейся таблицы записи, в которых цена отрицательна, так как такие записи не несут за собой никакого смысла. Также ограничим значения таких величин, как area – от 20 до 200 кв.м., kitchen – от 6 до 30 кв.м., и установим пределы для стоимости жилья – от 1,5 до 50 млн.руб, охватив таким образом большую часть рынка недвижимости.
MIN_AREA = 20 # Диапазон выбросов для площади пола MAX_AREA = 200 MIN_KITCHEN = 6 # Диапазон выбросов для площади кухни MAX_KITCHEN = 30 MIN_PRICE = 1_500_000 # Диапазон выбросов для цены на квартиру MAX_PRICE = 50_000_000
def clean_data(df: pd.DataFrame) -> pd.DataFrame: """The function removes unnecessary data, handles outliers.""" df.drop('time', axis=1, inplace=True) df['date'] = pd.to_datetime(df['date']) # Колонка фактически содержит значения -1 и -2, предположительно для однокомнатных квартир. df['rooms'] = df['rooms'].apply(lambda x: 0 if x < 0 else x) df['price'] = df['price'].abs() # Убираем отрицательные значения # Убираем выбросы в цене и площади df = df[(df['area'] <= MAX_AREA) & (df['area'] >= MIN_AREA)] df = df[(df['price'] <= MAX_PRICE) & (df['price'] >= MIN_PRICE)] # Убираем выбросы в колонке с площадью кухни # Но перед этим все "странные" значения мы заменим нулями df.loc[(df['kitchen_area'] >= MAX_KITCHEN) | (df['area'] <= MIN_AREA), 'kitchen_area'] = 0 # Рассчитаем площадь кухни на основе площади пола, но только не для однокомнатных квартир erea_mean, kitchen_mean = df[['area', 'kitchen_area']].quantile(0.5) kitchen_share = kitchen_mean / erea_mean df.loc[(df['kitchen_area'] == 0) & (df['rooms'] != 0), 'kitchen_area'] = \ df.loc[(df['kitchen_area'] == 0) & (df['rooms'] != 0), 'area'] * kitchen_share return df
def add_features(df: pd.DataFrame) -> pd.DataFrame: # Заменим "дату" числовыми характеристиками для года и месяца. df['year'] = df['date'].dt.year df['month'] = df['date'].dt.month df.drop('date', axis=1, inplace=True) # Этаж квартиры по отношению к общему количеству этажей. df['level_to_levels'] = df['level'] / df['levels'] # Средняя площадь комнаты в квартире. df['area_to_rooms'] = (df['area'] / df['rooms']).abs() df.loc[df['area_to_rooms'] == np.inf, 'area_to_rooms'] = \ df.loc[df['area_to_rooms'] == np.inf, 'area'] return df
df = df.pipe(clean_data) df = df.pipe(add_features)
df.head()

После обработки и очистки данных стало намного лучше. Можно переходить к визуализации.
Построим график распределения цены, а также найдем среднюю и медианную цены и стандартное отклонение.
mean_price = int(df['price'].mean()) median_price = int(df['price'].median()) std = int(df['price'].std()) min_price = int(df['price'].min()) max_price = int(df['price'].max()) print(f'Price range: {min_price} - {max_price}') print(f'Mean price: {mean_price}\nMedian price: {median_price}') print(f'Standard deviation: {std}') plt.hist(df['price'], bins=20) plt.axvline(mean_price, label='Mean Price', color='green') plt.axvline(median_price, label='Median Price', color='red') plt.legend() plt.xlabel('Apartment Price, Rubles') plt.title('Price Distribution') plt.show()
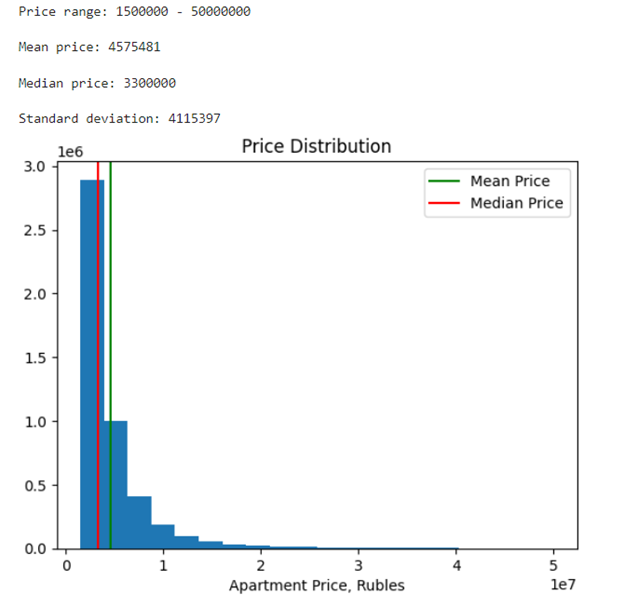
Таким образом, получаем среднюю стоимость квартиры – 4,575,481 руб.
Далее строим матрицу корреляций, чтобы убедиться в отсутствии мультиколлинеарности в данных, так как это может ухудшить качество будущей модели.
plt.figure(figsize=(15, 10)) sns.heatmap(df.corr(), center=0, cmap='mako', annot=True) plt.title('Correlation Matrix') plt.show()

Из представленной матрицы видно, что мультиколлинеарность отсутствует. Можно приступать к построению модели.
Зная основы ценообразования в сфере недвижимости, достаточно сложно и неразумно разрабатывать единую универсальную модель для всех регионов. Ведь такие факторы, как регион, условия местного рынка, экономические характеристики и т.д. оказывают достаточно сильное влияние на ценообразование на рынке недвижимости, поэтому цены на квартиры в разных городах и регионах могут отличаться в несколько раз.
В данном наборе данных отсутствует ряд важных характеристик, что приведет к большим ошибкам независимо от применяемых алгоритмов регрессии и качества модели, а именно:
Состояние: аналогичные по площади и месторасположению квартиры будут отличаться в цене, если одна из них полностью меблированная и в отличном состоянии, а другая – напротив, без отделки или без мебели
Высота потолков
Наличие балкона, террасы или выхода на крышу
Дополнительные уникальные свойства, обычно упоминаемые в описании квартиры, такие как дымоходы или подземные парковочные места, влияют на цену.
Принимая это во внимание, мы попытаемся разработать модель ценообразования для квартир, расположенных в Санкт-Петербурге.
Выберем из набора данных только те квартиры, которые находятся в Санкт-Петербурге, и перейдем к построению модели.
df = df.loc[df['region'] == 2661]
Для построения модели предсказания цены на квартиру будем использовать продвинутые методы машинного обучения, а именно - градиентный бустинг. Данный тип алгоритмов является крайне эффективным в задачах классификации или регрессии: он строит предсказания в виде ансамбля слабых деревьев решения, а затем слабые деревья собираются в одну сильную модель. Наиболее популярные реализации градиентного бустинга - XGBoost, LightGBM & CatBoost. Но в данной статье мы остановимся на XGBoost.
import xgboost as xgb from sklearn.metrics import r2_score from sklearn.model_selection import train_test_split
X, y = df.drop('price', axis=1), df['price'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=1) model = xgb.XGBRegressor() model.fit(X_train, y_train) predictions = model.predict(X_test)
Чтобы оценить качество работы будущей модели будем использовать метрику R2, или коэффициент детерминации:

Данный коэффициент измеряет долю дисперсии, которая была объяснена моделью в общей дисперсии целевой переменной. Иными словами, данная метрика — это нормированная среднеквадратичная ошибка. Если данная метрика будет близка к единице, то модель отлично объясняет данные, если же она близка к нулю, то прогнозы будут сопоставимы по качеству с константным предсказанием.
print(f'R^2 score: {r2_score(y_test, predictions):.3f}')
R^2 score: 0.809
Модель со стандартными параметрами уже показала довольно неплохой результат, но давайте улучшим его.
Для подбора гиперпараметров будем использовать библиотеку Optuna, которая использует байесовские оптимизации над гиперпараметрами.
import optuna
def objective(trial): params = { 'tree_method':'gpu_hist', 'sampling_method': 'gradient_based', 'lambda': trial.suggest_loguniform('lambda', 7.0, 17.0), 'alpha': trial.suggest_loguniform('alpha', 7.0, 17.0), 'eta': trial.suggest_categorical('eta', [0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]), 'gamma': trial.suggest_categorical('gamma', [18, 19, 20, 21, 22, 23, 24, 25]), 'learning_rate': trial.suggest_categorical('learning_rate', [0.01,0.012,0.014,0.016,0.018, 0.02]), 'colsample_bytree': trial.suggest_categorical('colsample_bytree', [0.3,0.4,0.5,0.6,0.7,0.8,0.9, 1.0]), 'colsample_bynode': trial.suggest_categorical('colsample_bynode', [0.3,0.4,0.5,0.6,0.7,0.8,0.9, 1.0]), 'n_estimators': trial.suggest_int('n_estimators', 400, 1000), 'min_child_weight': trial.suggest_int('min_child_weight', 8, 600), 'max_depth': trial.suggest_categorical('max_depth', [3, 4, 5, 6, 7]), 'subsample': trial.suggest_categorical('subsample', [0.5,0.6,0.7,0.8,1.0]), 'random_state': 42 } model = xgb.XGBRegressor(**params) model.fit(X_train, y_train) predictions = model.predict(X_test) return r2_score(y_test, predictions)
study = optuna.create_study(direction="maximize") study.optimize(objective, n_trials=25)
print("Number of finished trials: {}".format(len(study.trials))) print("Best trial:") trial = study.best_trial print("Value: {}".format(trial.value)) print("Params: ") for key, value in trial.params.items(): print("{}: {}".format(key, value))

Подбор гиперпараметров произведен. В результате получены наилучшие параметры для модели и наилучший коэффициент детерминации. Настало время обучить модель с полученными параметрами и посмотреть, как изменилась производительность нашей модели.
best_model = xgb.XGBRegressor(**study.best_params) best_model.fit(X_train, y_train) predictions_best = best_model.predict(X_test) print(f'R^2 score: {r2_score(y_test, predictions_best):.3f}')
R^2 score: 0.879
Исходя из полученных результатов, очевиден существенный прирост в качестве модели, а это значит, что построенная модель будет намного лучше объяснять данные, следовательно, и прогнозная стоимость какой-либо квартиры будет намного корректнее.
Рассмотрели метод построения модели предсказания цен на рынке недвижимости на примере г.Санкт-Петербург на основе градиентного бустинга. Результаты показали, что построенная модель имеет коэффициент детерминации, близкий к единице, что говорит о высокой точности прогнозирования цен на недвижимость.

