
«Мы сделаем вас счастливыми! Вы будете счастливыми!»
«Отроки во Вселенной» (1974)
Менеджеры в большинстве компаний хотят примерно одного и того же. Чтобы сложные вещи объяснялись простым языком, а все можно было свести к спидометрам, градусникам и светофорам.
Аллегория вполне понятная, пытаться объяснять что-либо — в 99% случаев процедура бессмысленная и энергозатратная. Поэтому ниже пример, как двумя экранами кода можно быстренько превратить временные ряды, которые почти всегда встречаются в больших количествах, в светофор.
Приступаем к процессу «осчастливливания».
Потребуются клей, бумага, скотч, и немного R.
Обычно временные ряды проглядывают на глубину 2-4 недель. Рядов может быть много, ОЧЕНЬ много и их надо как-то привести к светофорной раскраске.
Воспользуемся фактом небольшой глубины и соберем на коленке пульверизатор на основе линейной регрессии. Коэффициент $k$ нам определит цвет краски (красный/зеленый), а стат. значимость даст необходимый желтый для нестабильного поведения. Поскольку пишем на R, то никаких циклов. Базовую идею подсматриваем в книге «R for Data Science», глава «Many models».
library(tidyverse) library(lubridate) library(glue) library(scales) library(stringi) library(jsonlite) library(RColorBrewer) library(extrafont) library(hrbrthemes) library(DBI) library(anytime) library(tictoc) library(checkmate) library(data.table) library(ggplot2) library(ggthemes) library(cli) library(gt) library(lme4) # modeling
Подготовим 12 временных рядов. 4 с отрицательным трендом, 4 с положительным, 4 — случайные флуктуации. Период небольшой (две недели), поэтому при анализе не будем рассматривать возможную сезонность. Она просто не видна на таком периоде.
В случае, когда компактен и лаконичен, помещается на экран и оперирует только локальными данными, управляться с таким кодом и поддерживать его становится гораздо проще.
Сформируем каркасы 12 функций.
set.seed(12) raw_df <- 1:12 %>% tibble(id = ., k = (id - 1) %/% 4 - 1, b = runif(length(.), 10, 30)) %>% rowwise() %>% mutate(data = list( tibble(x = 0:13, y = k * runif(1, 0, 3)*x + b)) )

Сформируем датасет в именах и значениях реальных данных.
signal_tbl <- raw_df %>% unnest(data) %>% mutate(date_msk = today() + x, value = y + rnorm(nrow(.), sd = 3.5)) %>% mutate_at("id", as.factor) signal_tbl %>% ggplot(aes(date_msk, value, group = id)) + geom_point() + facet_wrap(~id, ncol = 4)

Строим регрессию для каждого объекта (в примере датасеты никак не связаны между собой, поэтому иерархические методы тут не помогут).
lm_tbl <- signal_tbl %>% select(id, date_msk, value) %>% nest(-id) %>% mutate(model = map(data, ~lm(value ~ date_msk, data = .x))) %>% mutate(m_params = map(model, broom::tidy)) %>% unnest(m_params) %>% filter(term == "date_msk") %>% setDT() %>% .[, id_trend := fifelse(estimate < 0, "Падение показателя", "Рост показателя")] %>% .[p.value > 0.05, id_trend := "Достоверно неизвестно"] %>% as_tibble()
Рисуем внятную табличку с большими буквами.
lm_tbl %>% select(id, estimate, std.error, p.value, id_trend) %>% mutate(grp = p.value < 0.05) %>% arrange(desc(grp), desc(estimate)) %>% gt() %>% cols_hide(columns = grp) %>% fmt_number( columns = p.value, decimals = 4, use_seps = FALSE ) %>% data_color( c(estimate), colors = scales::col_numeric( c("#f87274", "white", "#63be7b"), na.color = "transparent", domain = NULL ) ) %>% # снимем раскраску с незначимых строк tab_style( style = list( cell_fill(color = "white"), cell_text(color = "black") ), locations = cells_body(rows = p.value > 0.05) )

Строим финальную картинку, согласуем цвета с корпоративным брендбуком.
lm_tbl %>% select(id, data, estimate, id_trend) %>% unnest(data) %>% ggplot(aes(date_msk, value, colour = id_trend, group = id)) + geom_point(alpha = 0.8) + ggthemes::scale_colour_tableau() + geom_smooth(se = FALSE, alpha = 0.5) + scale_x_date(labels = scales::date_format("%d.%m"), breaks = scales::date_breaks("2 days"), guide = guide_axis(n.dodge = 2)) + scale_y_continuous(labels = scales::label_percent(accuracy = 1), breaks = scales::breaks_pretty(n = 3)) + facet_wrap(~id, ncol = 3, scales = "free") + theme_ipsum_rc() + labs(x = "Дата", y = "Показатель", colour = "Динамика")
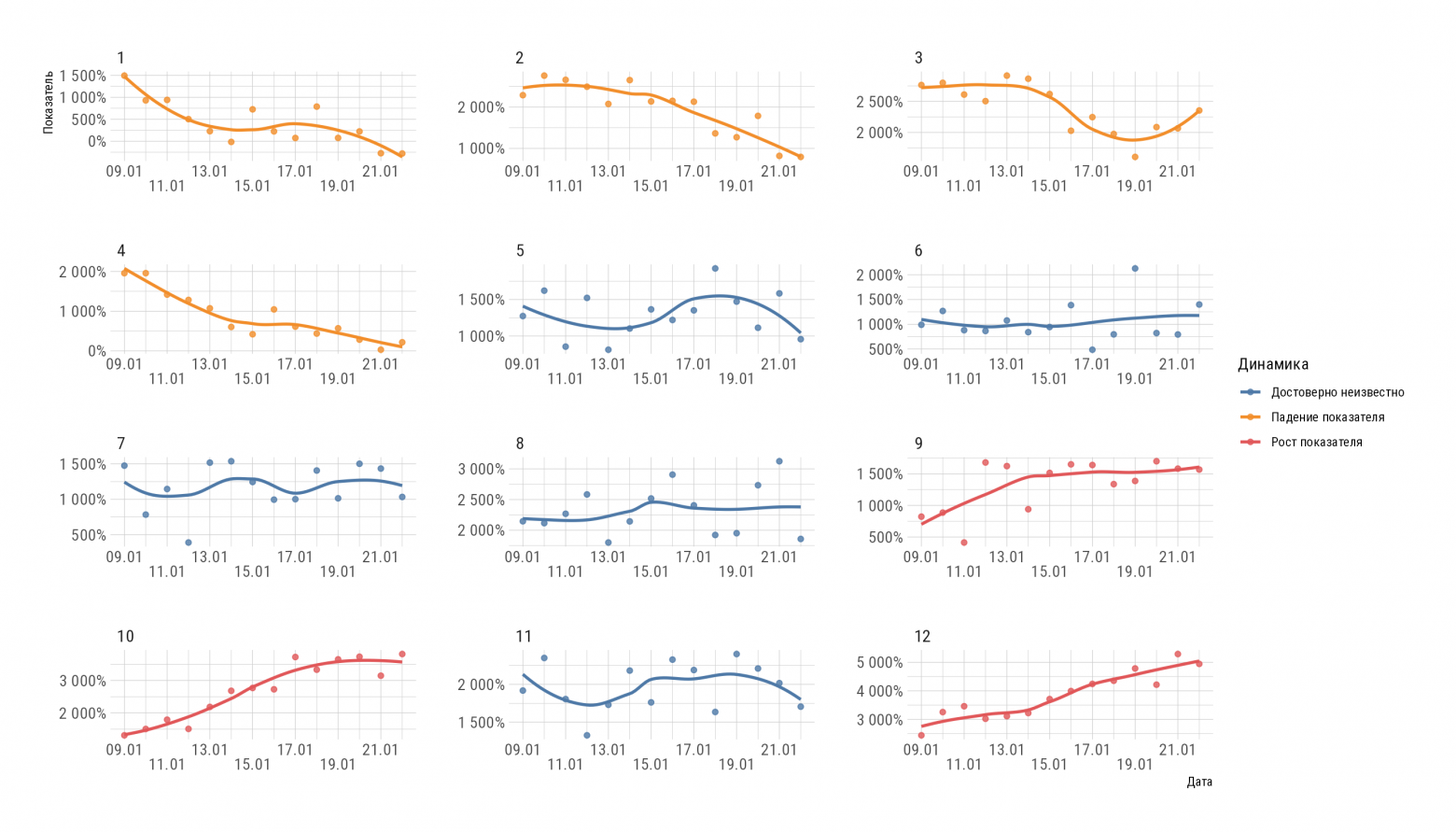
Собственно говоря, все.
Предыдущая публикация — «Важно ли DS аналитику знать про software development?»

