Введение
Многозадачное обучение (Multi-task learning) - это машинное обучение, где модель обучается на нескольких задачах сразу. Это отличается от обычного обучения на одной задаче, где модель обучается только на одной задаче. Многозадачное обучение может предоставить большую эффективность и более хорошую обобщающую способность, поскольку модель изучает общую концепцию между задачами.
Однако, многозадачное обучение может представлять проблемы для управления моделями, такие как:
Сложность обучения и тестирования модели на нескольких задачах
Отсутствие общей метрики для оценки производительности модели на всех задачах
Отсутствие способа отслеживать и сравнивать результаты различных экспериментов
Сложность интерпретации и объяснения модели на нескольких задачах
MLflow предоставляет ряд инструментов для управления многозадачным обучением, включая:
Отслеживание экспериментов: отслеживание и сравнение результатов различных экспериментов на каждой задаче
Упаковка моделей и обслуживание их: упаковка многозадачной модели для легкого обмена и развертывания
Интеграция с популярными фреймворками и облачными платформами для управления многозадачного обучения
Ввод MLflow как решения для этих проблем, позволяет более эффективно управлять многозадачным обучением, с возможностью отслеживания и сравнения экспериментов, упаковки моделей и интеграции с другими инструментами и платформами.
Многозадачное обучение с независимыми моделями
В чем отличие многозадачное обучение с независимыми моделями от обычного? В обычном многозадачном обучении модель обучается на нескольких задачах сразу, используя одну и ту же модель для каждой задачи. Идея многозадачного обучения звучит очень круто, но на практике она не всегда хорошо работает. Иногда обучение отдельной модели для каждой задачи работает лучше из-за того, что обновления градиента для разных задач мешают или конфликтуют друг с другом, получится не эффективно. Это называется отрицательным трансфером.
Кроме того, с отдельно обученными моделями проще иметь дело. Это многозадачное обучение с независимыми моделями может быть полезным для отслеживания и сравнения результатов, упаковки и деплоя независимых моделей для каждой задачи индивидуально. Давайте сразу рассматривать на практике.
Задание
Предлагаю сразу взять готовый пример задачи и решения Multi-Task Learning for Classification with Keras, изменить некоторый конвейер и код, чтобы переходило с одной модели на две независимых моделей для каждой задачи.
Задача многоклассовой классификации: модель должна классифицировать изображение в одну из нескольких категорий животных и транспортных средств (кошка, собака, лошадь, автомобиль, грузовик и другие).
Задача бинарной классификации: модель должна определять, является ли изображение только животным или транспортным средством.
Загрузка набора данных
Сначала найти известный готовый набор данных, то код проще импортировать фреймворк TensorFlow, чтобы получить и распределенных набор обучающих и тестовых данных:
import tensorflow as tf (x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
CIFAR-10 содержит 60000 изображений 32x32x3 в 10 конкретных классах: 0 - самолет, 1 - автомобиль, 2 - птица, 3 - кошка, 4 - олень, 5 - собака, 6 - лягушка, 7 - лошадь, 8 - корабль, 9 - грузовик.
Предобработка
Еще одна функция получения набор бинарного набор данных помогает преобразовать с одного выхода изображения на 2 выхода, получатся два набор данных бинарного(животные и транспорт) и многоклассовой (10 классов) классификации.
def generate_binary_labels(yy, animal_classes): yy_2 = [0 if y in animal_classes else 1 for y in yy] return yy_2 # 0 = animal, 1 = vehicle y_train_2 = generate_binary_labels(y_train_1, [2, 3, 4, 5, 6, 7]) y_test_2 = generate_binary_labels(y_test_1, [2, 3, 4, 5, 6, 7])
Для многозадачного обучения важно, что метки обучения специфичны для каждой задачи. Поэтому, при n-задачном обучении, будут определены n массивов различных меток. В этом случае первая задача требует, чтобы метки были целыми числами от 0 до 9 (одно число для каждого класса, т.е. многоклассная классификации), а вторая задача требует метки 0 и 1 (так как это бинарная классификация). Данные были ранее предварительно обработаны, так что метки являются цифрами от 0 до 9, и, как и ожидалось, метки для бинарной классификации будут созданы на основе исходных меток 0-9, так что если экземпляр соответствует животному(3 - кошка, 4 - олень, 5 - собака, 6 - лягушка, 7 - лошадь), он будет иметь метку 0, а если соответствует транспортному средству(0 - самолет, 1 - автомобиль, 8 - корабль, 9 - грузовик) - метку 1.
from tensorflow.keras.utils import to_categorical def preprocess_data_cifar10(x_train, y_train_1, x_test, y_test_1): # 0 = animal, 1 = vehicle y_train_2 = generate_binary_labels(y_train_1, [2, 3, 4, 5, 6, 7]) y_test_2 = generate_binary_labels(y_test_1, [2, 3, 4, 5, 6, 7]) n_class_1 = 10 n_class_2 = 2 y_train_1 = to_categorical(y_train_1, n_class_1) y_test_1 = to_categorical(y_test_1, n_class_1) y_train_2 = to_categorical(y_train_2, n_class_2) y_test_2 = to_categorical(y_test_2, n_class_2) return x_train, y_train_1, y_train_2, x_test, y_test_1, y_test_2 x_train, y_train_1, y_train_2, x_test, y_test_1, y_test_2 = preprocess_data_cifar10(x_train, y_train, x_test, y_test)
После получения бинарного набора данных выполняется to_categorical это функция из модуля keras.utils библиотеки TensorFlow, которая преобразует классы в категориальный формат, т.е. в матрицу из нулей и единиц, где каждая строка соответствует одному примеру и индекс с единицей соответствует классу этого примера. В данном случае используется функция для преобразования массива y_train_1 и y_test_1 в категориальный формат с n_class_1 бинарными классами, а также y_train_2 и y_test_2 в категориальный формат с n_class_2 классами. Это необходимо для использования в машинном обучении.
В итоге функция возвращает тренировочные и тестовые данные и два массива меток для двух задач классификации: многоклассовой классификации с метками от 0 до 9 и бинарной классификации с метками 0 и 1. Метки 0 и 1 соответствуют животным и транспортным средствам соответственно.
Обучение первой и второй моделей
Создать отдельно две сверточных нейронные модели, см. архитектуру обычного многозадачного обучения из статьи Multi-Task Learning for Classification with Keras , у которого один вход изображения и два выхода: 2 класса и 8 классов, а у меня 2 класса и 10 классов.
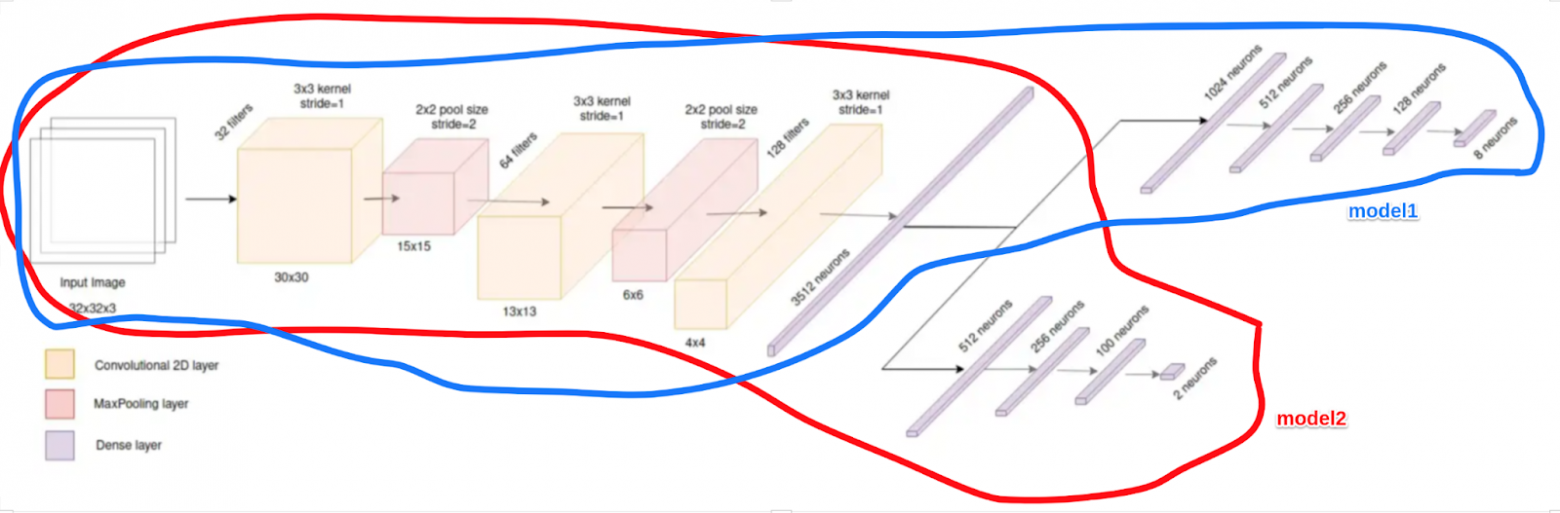
Функция создания модели сверточных нейронных сетей многоклассовой классификации model1
def create_task_learning_model(x_train_shape, y_train_shape): inputs = tf.keras.layers.Input(shape=(x_train_shape[1], x_train_shape[2], x_train_shape[3]), name='input') main_branch = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), strides=1)(inputs) main_branch = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(main_branch) main_branch = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), strides=1)(main_branch) main_branch = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(main_branch) main_branch = tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), strides=1)(main_branch) main_branch = tf.keras.layers.Flatten()(main_branch) main_branch = tf.keras.layers.Dense(3512, activation='relu')(main_branch) task_1_branch = tf.keras.layers.Dense(1024, activation='relu')(main_branch) task_1_branch = tf.keras.layers.Dense(512, activation='relu')(task_1_branch) task_1_branch = tf.keras.layers.Dense(256, activation='relu')(task_1_branch) task_1_branch = tf.keras.layers.Dense(128, activation='relu')(task_1_branch) task_1_branch = tf.keras.layers.Dense( y_train_shape[1], activation='softmax')(task_1_branch) model = tf.keras.Model(inputs = inputs, outputs = [task_1_branch]) model.summary() return model
После функция создания функция компиляции model.compileиспользуется для конфигурирования модели для обучения.
model = create_task_learning_model(x_train.shape, y_train.shape) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
В данном случае используется оптимизатор Adam, функция потерь categorical_crossentropy для многоклассовой классификации и метрика accuracy для оценки качества модели.
Дальше model.fit() использует набор данныхx_train и y_train для обучения в течение 50 эпох с batch_size = 128. В процессе обучения не выводится информация о прогрессе verbose=0.
model2_history = model.fit(x_train, y_train, epochs=50, batch_size=128, verbose=0)
Результаты обучения сохраняются в переменной model2_history.
После того, как функция создания модели сверточных нейронных сетей бинарной классификации model1 и как выше есть описание, но немного разные архитектура модели и параметры компиляции для задачи бинарной классификации следующие разницы:
Убрать один слой с 1000 нейронами
Бинарный выход модели сверточных сетей
binary_crossentropy- функция потерь для бинарной классификации.
def create_task_learning_model(x_train_shape, y_train_shape): inputs = tf.keras.layers.Input(shape=(x_train_shape[1], x_train_shape[2], x_train_shape[3]), name='input') main_branch = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), strides=1)(inputs) main_branch = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(main_branch) main_branch = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), strides=1)(main_branch) main_branch = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(main_branch) main_branch = tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), strides=1)(main_branch) main_branch = tf.keras.layers.Flatten()(main_branch) main_branch = tf.keras.layers.Dense(3512, activation='relu')(main_branch) task_2_branch = tf.keras.layers.Dense(512, activation='relu')(main_branch) task_2_branch = tf.keras.layers.Dense(256, activation='relu')(task_2_branch) task_2_branch = tf.keras.layers.Dense(100, activation='relu')(task_2_branch) task_2_branch = tf.keras.layers.Dense(y_train_shape[1], activation='sigmoid')(task_2_branch) model = tf.keras.Model(inputs = inputs, outputs = [task_2_branch]) model.summary() return model model = create_task_learning_model(x_train.shape, y_train.shape) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model2_history = model.fit(x_train, y_train, epochs=50, batch_size=128, verbose=0)
Если проблема с детерминизм для обучения, см. stackoverflow, которое решено на моей практике:
import tensorflow as tf import random import os SEED = 0 def set_seeds(seed=SEED): os.environ['PYTHONHASHSEED'] = str(seed) random.seed(seed) tf.random.set_seed(seed) np.random.seed(seed) def set_global_determinism(seed=SEED): set_seeds(seed=seed) os.environ['TF_DETERMINISTIC_OPS'] = '1' os.environ['TF_CUDNN_DETERMINISTIC'] = '1' tf.config.threading.set_inter_op_parallelism_threads(1) tf.config.threading.set_intra_op_parallelism_threads(1) # Call the above function with seed value set_global_determinism(seed=SEED)
Это для чего? Это может быть полезно в случаях, когда вам нужно воспроизвести результаты эксперимента или дебажить модель, которая использует случайность. Без этого кода случайные числа будут генерироваться с разными начальными значениями каждый раз, когда код запускается, и результаты будут отличаться. Поэтому если вы хотите повторно получить тот же самый результат в вашем коде, необходимо явно установить seed чтобы генератор использовал одинаковое начальное значение. Это может быть полезно для отладки, и позволит вам воспроизвести результаты.
Сохранение обученных моделей
model.save(PATH_MODEL) new_model = tf.keras.models.load_model(PATH_MODEL) new_model.summary()
Этот код сохраняет первую обученную модель в указанный файл. Затем загружает ее и выводит ее описание для проверки. Это позволяет использовать обученную модель в дальнейшем без необходимости повторного обучения, так же как и для второй обученной модели
Общая оценка
import tensorflow as tf model1 = tf.keras.models.load_model(PATH_MODEL_1) model1.summary() model2 = tf.keras.models.load_model(PATH_MODEL_2) model2.summary() e1 = model1.evaluate(x_test, y_test_1) print('Task1 evaluate: ', e1) e2 = model2.evaluate(x_test, y_test_2) print('Task2 evaluate: ', e2) sum_loss = e1[0] + e2[0] print('Multi task evaluate sum loss: ', sum_loss) ave_acc = (e1[1] + e2[1])/2 print('Multi task evaluate average accurate: ', ave_acc)
В коде используется загрузка обученных моделей с ранее сохраненных путей PATH_MODEL_1 и PATH_MODEL_2, затем выводится информация о моделях с помощью summary(). Далее происходит оценка качества моделей на тестовых данных x_test и y_test_1 и y_test_2 с использованием evaluate() с расчетом итоговой суммы потери и средней точности. MLflow покажет их. Для более быстрого обучения модели рекомендуется включить GPU (при его наличии), установив переменную среды окружения export CUDA_VISIBLE_DEVICES='0'.
Направленный ациклический граф конвейера()
Направленный ациклический граф конвейера( сокращение pipeline DAG) получился с нуля загрузки набора данных до общей оценки с помощью фреймворка DVC для оркестрации и платформы DagsHub для визуального графа
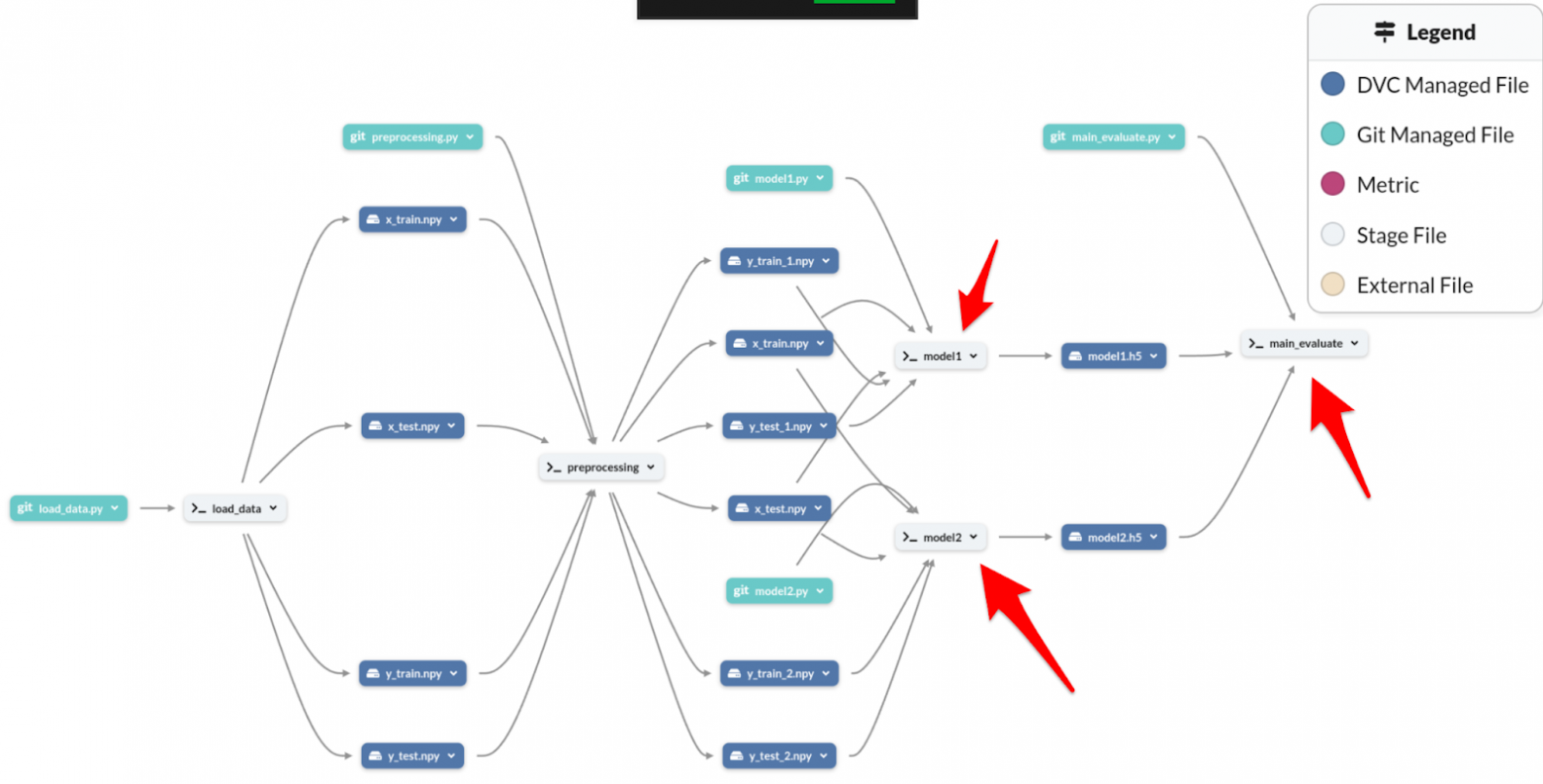
Видные красные стрелки к файлам этапа (Stage File) будут рассмотрены в MLflow далее.
MLflow: отслеживание экспериментов с независимыми моделями
MLflow может использоваться для управления многозадачным обучением с независимыми моделями, так же как и для обычного многозадачного обучения. Хотя есть множество статей о MLflow на хабре, не буду писать подробное руководство по нему. В данном случае я покажу просто различные параметры и результаты экспериментов, но не буду рассматривать настройку моделей обучения.
API-код
Для отслеживания экспериментов нужно добавить несколько строк кода:
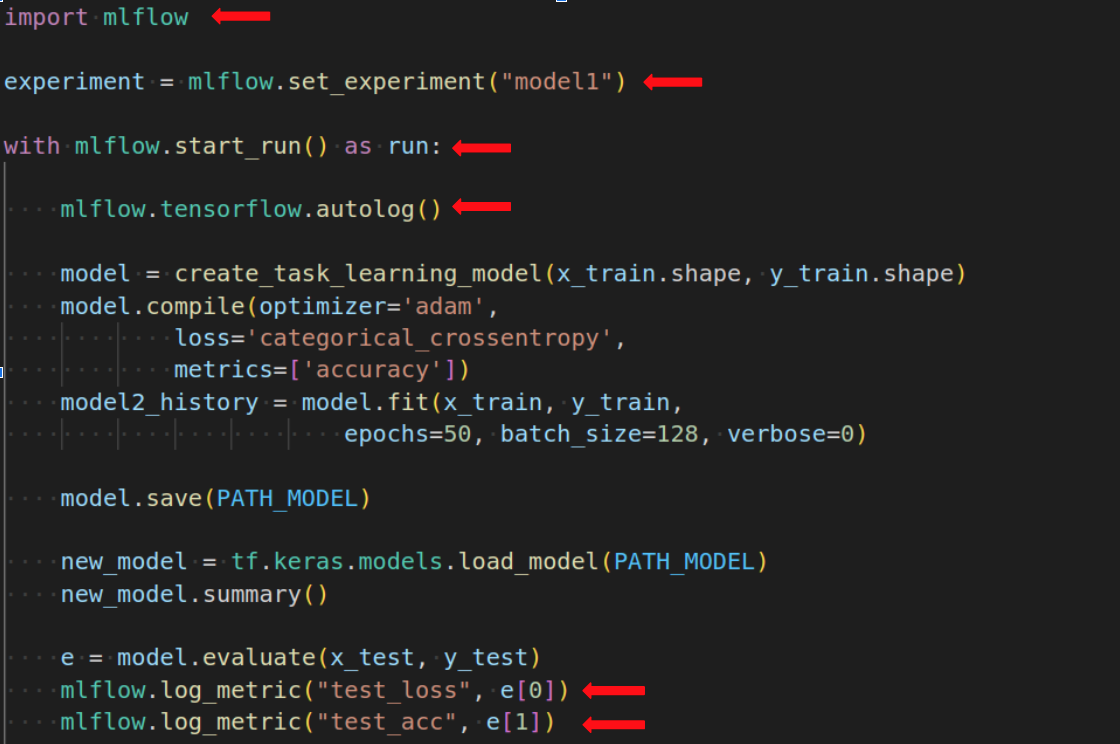
Библиотека MLflow используется для отслеживания экспериментов mlflow.set_experiment("model1") устанавливает имя эксперимента в MLflow. mlflow.start_run() начинает новую сессию запуска, которая используется для отслеживания метрик и параметров модели. Интересно mlflow.tensorflow.autolog() автоматически отслеживает метрики и параметры модели в ходе выполнения кода обучения, но не обязательно. mlflow.log_metric("test_loss", e[0]) и mlflow.log_metric("test_acc", e[1]) записывает метрики тестовой потери и точности в сессию запуска.
Для второй модели model2 нужно добавить такой же код для отслеживания ее экспериментов в MLflow. Но для каждой модели нужно задавать свой эксперимент, поэтому нужно будет изменитьmodel1 на model2 или любое другое название, чтобы отделять эксперименты для разных моделей.
Для общей оценки многозадачного обучения добавить немного по другому:
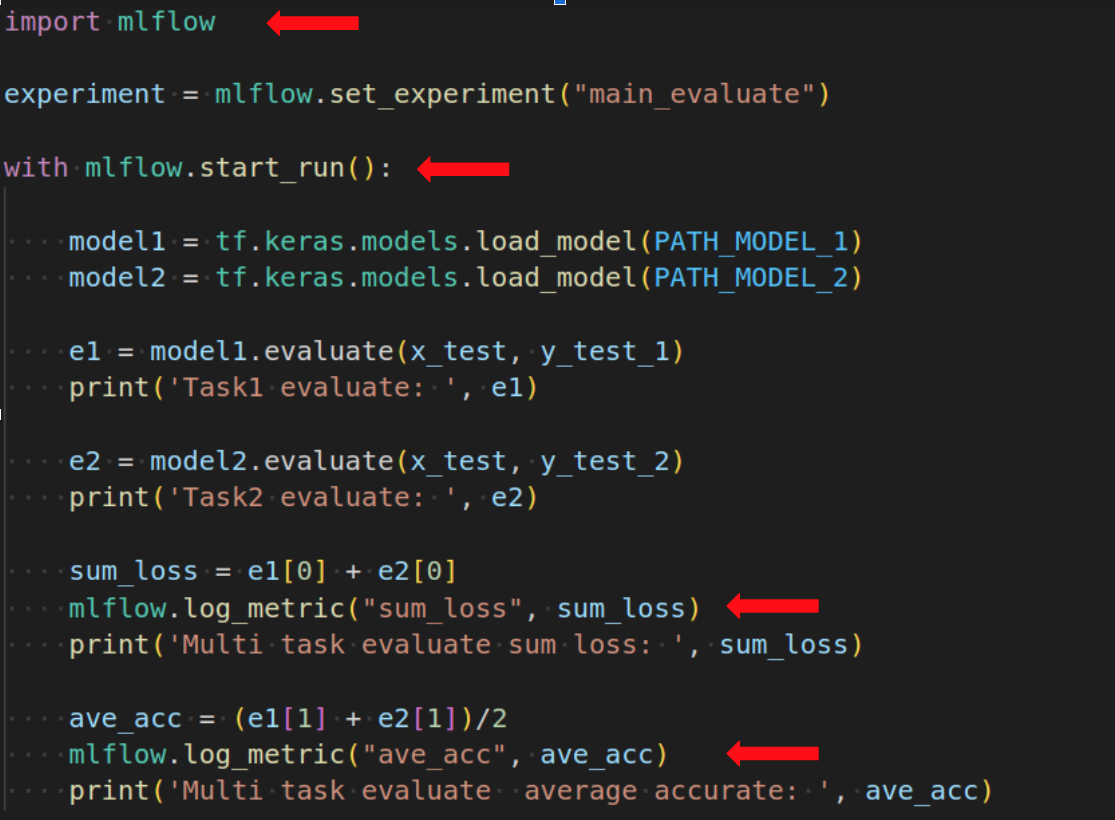
В последнем коде cначала создается эксперимент с именем main_evaluate, затем запускается run с помощью контекстного менеджера. Далее загружаются модели model1 и model2 с путями PATH_MODEL_1 и PATH_MODEL_2 соответственно. Затем модели оцениваются на тестовых данных с помощью model1.evaluate и model2.evaluate. После этого считается суммарная потеря и средняя точность и записывается в логи с помощью mlflow.log_metric("sum_loss", sum_loss) и mlflow.log_metric("ave_acc", ave_acc) соответственно.
Интерфейс отслеживания экспериментов
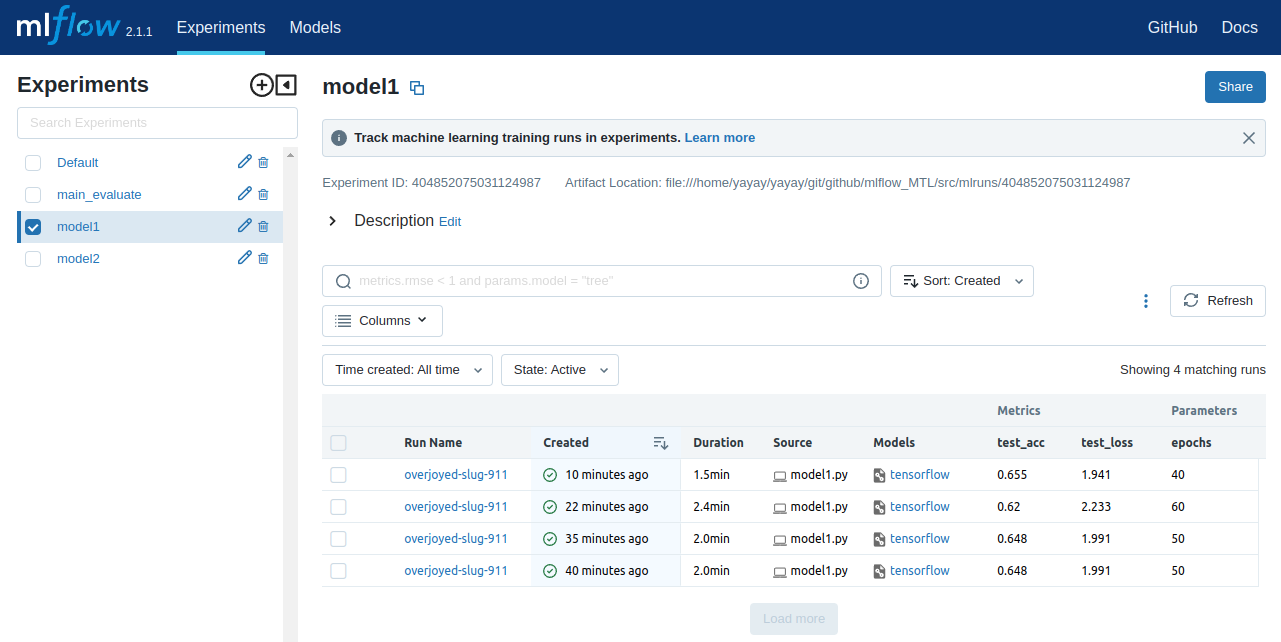
Чтобы проверить MLflow UI, необходимо запустить команду "mlflow ui" в терминале или консоли. Это запустит веб-сервер на локальной машине на порту 5000. После этого вы можете открыть браузер и перейти по адресу http://localhost:5000, чтобы просмотреть интерфейс MLflow. В интерфейсе можно увидеть все эксперименты, которые были запущены с помощью MLflow, в том числе три эксперимента для каждой модели и общей оценки обучения, это будет показано как три строки в каждом интерфейсе, смотрите первую модель:
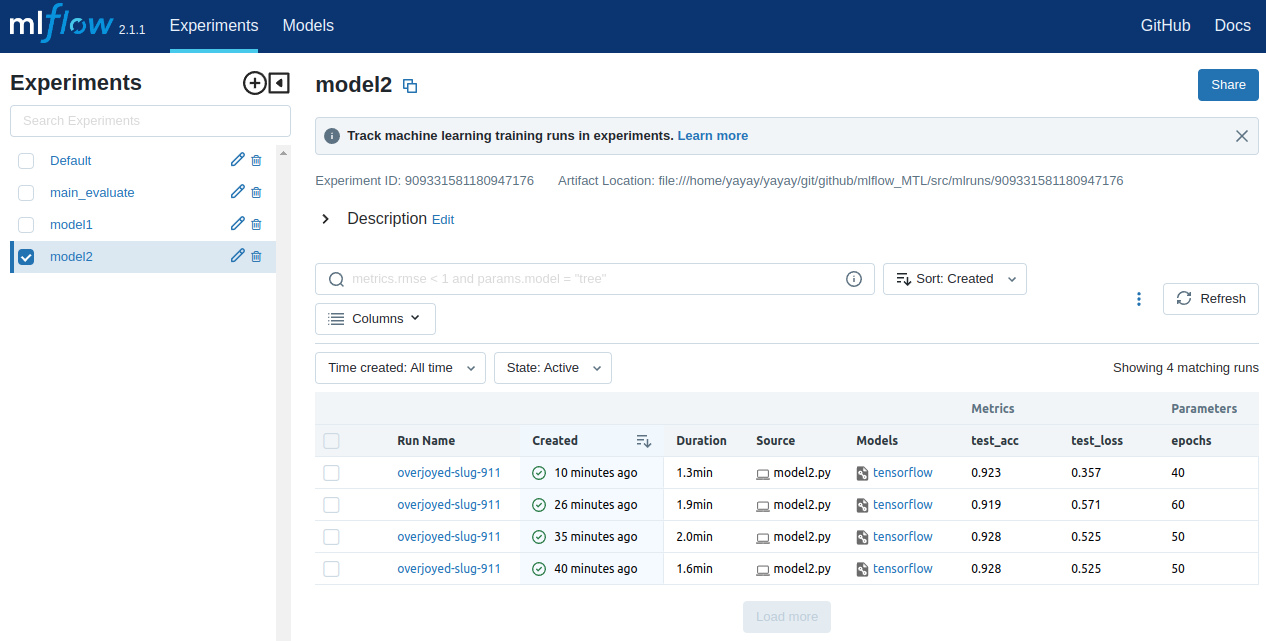
Смотрите вторую модель:
И смотрите общую оценку обучения:
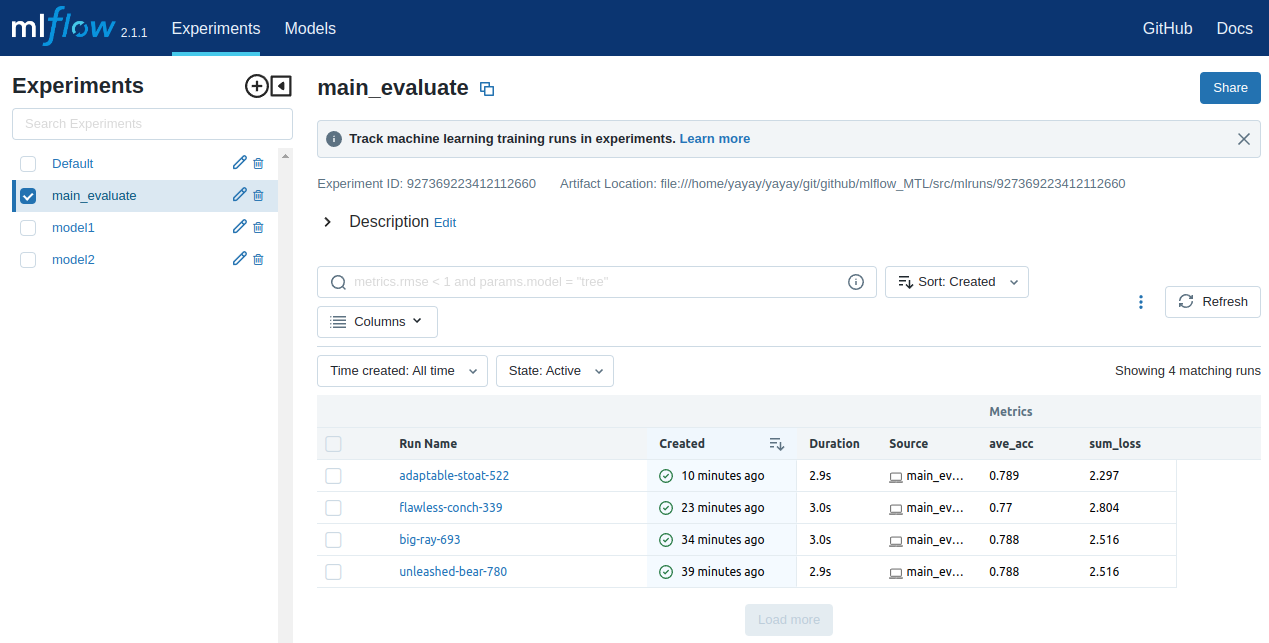
В интерфейсах MLflow для двух моделей и общей оценки обучения отображаются четыре эксперимента. В каждом интерфейсе в последних двух строках показаны одинаковые результаты и параметры. Это связано с решением проблемы детерминизма, как было рассказано выше. Изменение параметра epochs в двух моделях приведет к изменению результатов в первых двух строках в каждом интерфейсе.
Мне кажется, что вы теперь знаете, как использовать инструмент MLflow для многозадачного обучения и можете перейти к более подробному руководству. Далее мы рассмотрим обслуживание моделей.
MLflow: Обслуживание моделей
Обслуживание моделей(Model serving) - это процесс обслуживания модели, который делает доступным для использования и внедрения модели в реальном мире. Может включать в себя предоставление API-интерфейса для запросов, обработку входных данных, использование вычислительной мощности и ресурсов, мониторинг модели в процессе использования.
MLflow может использоваться для запуска сервера, который поддерживает независимые модели. Это позволяет легко обновлять и управлять моделями, а также иметь возможность обслуживать несколько моделей одновременно. Он также предоставляет инструменты для мониторинга и отслеживания использования модели в реальном времени, что помогает обеспечить качество и надежность модели.
Управление использованием GPU и CPU
Чтобы улучшить производительность и избежать проблемы с двумя моделями на
одной видеокарте, рекомендуется использовать команду export для выключения GPU во время обслуживания.
CUDA_VISIBLE_DEVICES=''
Однако, не забывайте включить GPU при обучении, как указано в подразделе
"Общая оценка" выше. Для переключения между GPU для обучения и CPU для
обслуживания, можно использовать различные методы автоматического переключения между GPU для обучения и CPU для обслуживания, например, с помощью argparser
для передачи аргументов внутрь кода, которые можно преобразовать в переменные ниже.
import os if control_GPU==1: os.system("export CUDA_VISIBLE_DEVICES='0'") else: os.system("export CUDA_VISIBLE_DEVICES=''")
Запуск сервера
Поэтому необходимо выключить GPU. Затем необходимо перейти в интерфейс MLflow, копировать путь(file:///<path>/mlruns/run_id/uuid/artifacts/model) к лучшей модели из столбца "Run Name" и использовать его для запуска сервера с помощью команды mlflow models serve --no-conda -m file:///<path>/mlruns/run_id/uuid/artifacts/model -h 0.0.0.0 -p 8001. Для второй модели нужно запустить команду mlflow models serve с теми же аргументами, но на другом порте, например: mlflow models serve --no-conda -m file:///<path>/mlruns/run_id/uuid/artifacts/model -h 0.0.0.0 -p 8002. Это позволит запустить вторую модель на другом порте, не конфликтуя с первой моделью.
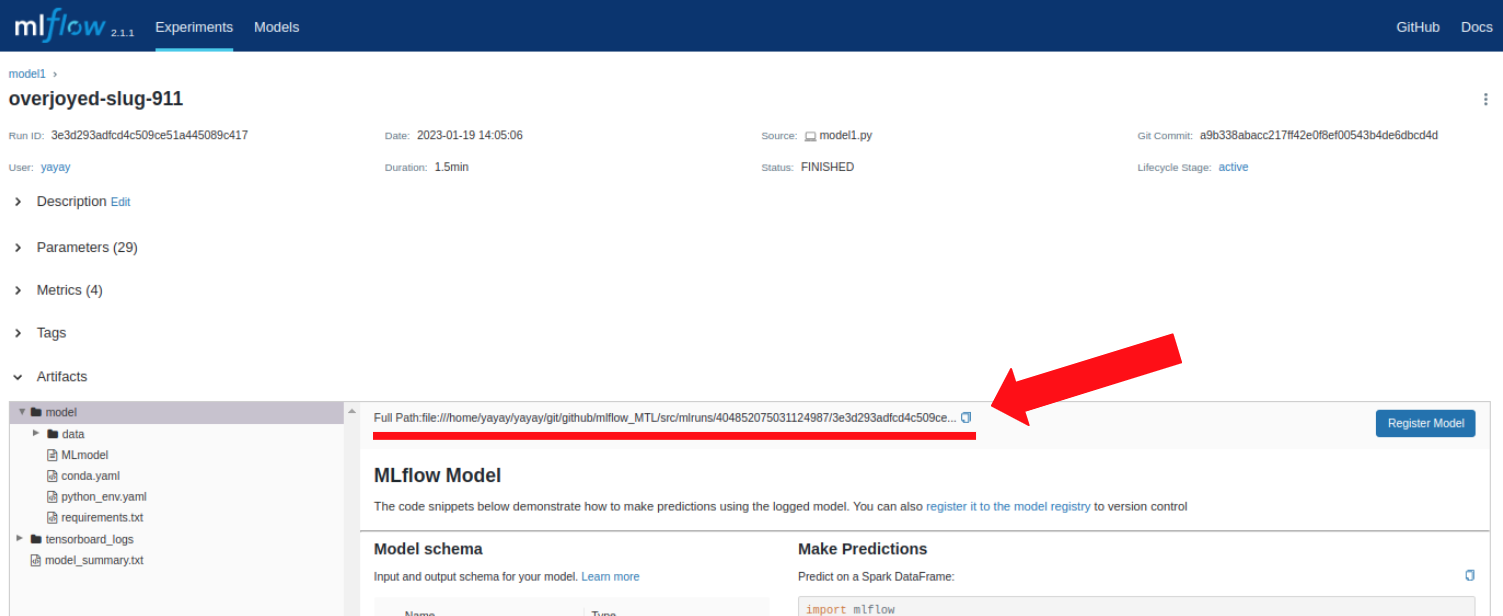
Вот пример команды запуска для первой модели:
mlflow models serve --no-conda -m file:///home/yayay/yayay/git/github/mlflow_MTL/src/mlruns/404852075031124987/3e3d293adfcd4c509ce51a445089c417/artifacts/model -h 0.0.0.0 -p 8001
Для второй модели используйте другой путь на другом порте:
mlflow models serve --no-conda -m file:///home/yayay/yayay/git/github/mlflow_MTL/src/mlruns/909331581180947176/db0f2cbb10a64aeeb768d5408fcb9cca/artifacts/model -h 0.0.0.0 -p 8002
К сожалению, MLflow не позволяет использовать разные роутеры для каждой модели на одном порте, например, 0.0.0.0/model1, 0.0.0.0/model2 и т.д. Как показано на Stackoverflow. В качестве альтернативы, можно использовать другие инструменты для развертывания моделей, такие как Selder, FastAPI и другие.
Проверка запросов и ответов
Проверка запроса и ответа с моделями может быть выполнена с использованием библиотеки requests. Эта библиотека предоставляет инструменты для отправки HTTP-запросов и обработки ответов сервера.
Например, можно отправить POST-запрос на адрес сервера, на котором развернута модель, используя код:
import requests r2 = requests.post('http://0.0.0.0:8002/invocations', json=j) print(r2.status_code) dict_r2 = r2.json() print( "predicted binary labels:", dict_binary_label[np.argmax(dict_r2["predictions"][0])] ) r1 = requests.post('http://0.0.0.0:8001/invocations', json=j) print(r1.status_code) dict_r1 = r1.json() print( "predicted multiclass labels:", dict_multiclass_label[np.argmax(dict_r1["predictions"][0])], )
Вывод кода статуса 200(работает http) и ответа для животных и лошади:

Все задание и решение завершены, и можно просмотреть полный код, чтобы убедиться, что он работает корректно.

