

Любой специалист, который когда-либо работал с Big Data знает, что в подобных проектах большой не только объем данных. Также это внушительные вычислительные ресурсы, разветвленный технологический стек и мощная инфраструктура. Поэтому Big Data-проекты часто реализовывают в облаке.
Меня зовут Алексей Бестужев, я архитектор VK Cloud, и в этой статье мы обсудим нюансы и неочевидные особенности запуска процессов при работе с большими данными в облаке.
Материал подготовлен на основе нашего совместного вебинара с Кириллом Сливчиковым, управляющим партнером компании 7RedLines.
Почему компании выбирают облака для работы с большими данными
Начну с того, что реализация Big Data-проектов — часто длительный и сложный процесс. В исследовании «Как компании реализуют Big Data-проекты в России?» мы определили, что сложности внедрения типовые. Основные — недостаток компетенций в команде и плохая каталогизация данных. Среди барьеров компании также называют затруднения при выборе технологического стека, неготовность ИТ-инфраструктуры и недостаточное финансирование Big Data-проектов. Некоторые организации сталкиваются со сложностью оценки ROI (Return on Investment, коэффициент возврата инвестиций) — универсальной модели расчета не существует.

С какими сложностями сталкиваются компании при реализации Big Data-проектов
Работа с облачными сервисами для Big Data-проектов позволяет обойти большинство из перечисленных ограничений, об этом поговорим ниже; а сейчас вернемся к нулевой точке, когда компания решила, что «бигдате — быть» и начала движение в сторону реализации проекта.
Эволюция пользы Big Data-проектов
Классическое внедрение проекта по работе с Big Data состоит из пяти этапов:
- разработка концепции управления данными;
- разработка архитектуры;
- определение инфраструктуры и стека;
- реализация;
- сопровождение и развитие.
Проект важно начинать с разработки концепции управления данными: определить, на каком этапе работы с ними компания сейчас находится, и начать поступательное движение именно с этой точки. Путь от первого этапа к последнему — эволюционный: перепрыгнуть через любую из ступеней не получится, это отразится на качестве аналитики. Каждый этап аналитики ценен для бизнеса и предполагает уровень подготовки данных, экспертизы, инфраструктуры и инструментов.
- Описательная аналитика. Это первый этап работы с Big Data, на котором компании важно внедрить на организационном уровне подходы к работе с данными: организовать их сбор, очистку и структурирование. Это позволит создавать стандартные и Ad-hoc-/OLAP-отчеты для оценки произошедшего. Например, так можно обнаружить, что один из этапов воронки продаж является «узким горлышком», которое мешает достичь цели по выручке.
- Предиктивная аналитика. Если данные систематически собираются, соблюдается политика Data Quality, данные полны, достоверны и связаны, то можно переходить к предиктивной аналитике. Такой подход позволит моделировать сценарии развития событий на основе собранных данных. Например, прогнозировать, как корректировка определенной метрики в воронке продаж могла бы повлиять на выручку компании в прошедших периодах, и уже на основе этого анализа корректировать дальнейшие действия.
- Предиктивное моделирование. После освоения работы с предиктивной аналитикой можно переходить к предиктивному моделированию и пытаться прогнозировать будущее. Например, какой будет динамика продаж компании с учетом множества переменных: внешних событий и внутренних факторов? Достоверность прогноза на этом этапе зависит от качества и полноты данных, качества моделей, а целесообразность применения такой аналитики — от готовности компании интегрировать результаты предиктивного анализа в бизнес-процессы и принимать решения с опорой на прогнозы.
- Прескриптивное управление. Прескриптивное управление позволяет находить наилучший вариант решения проблемы и отвечает на вопрос «Что нужно, чтобы…?». Метод позволяет получать аналитику на основе исторических и текущих данных о бизнес-процессах: он помогает построить множество сценариев развития событий в режиме реального времени и выбрать из них наиболее подходящий. Например, при каких условиях продажи увеличатся на n % в ситуации, когда на рынок оказывают влияние факторы a, b, c, d, x, а ситуация в компании обстоит определенным образом?
Определяемся с типом архитектуры
В Big Data-проектах большое значение имеет концепция архитектуры хранилища. Она зависит от модели данных, алгоритма работы потоков и сложности проекта. Наиболее распространены четыре архитектуры DWH:
- Архитектура Ральфа Кимбалла. Простой вариант. Согласно концепции, хранилище — это набор витрин данных и ничего больше.
- Архитектура Билла Инмона. Усовершенствованная модель. Подразумевает наличие не только витрин, но и корпоративного слоя данных, который выполнен в модели 3NF или приближен к нему.
- Архитектура Дэна Линстедта. Модель хранилища, в которой с помощью архитектурных решений и выделения таблиц разных типов, в том числе для хранения историчности, стоимость вносимых изменений сильно снижена. Такая архитектура динамичнее предыдущих, удобнее в работе и не требует постоянной доработки.
- Архитектура EAV. Динамическая модель, в которой структура хранилища меняется добавлением не колонок, а строк. Это позволяет расширять модель практически бесконечно и дешево. Реализует принцип колоночного управления структурой данных и адаптирована для работы с колоночными СУБД.

Типы архитектур хранилища данных
Выбираем стек ПО под архитектуру
Для каждого из этапов работы с большими данными важно подобрать оптимальный набор инструментов с учетом нагрузки и задач.
В облаке подбирать технологии удобно, поскольку в нем есть готовые инструменты для работы с данными (DataPaaS) — от преднастроенного Hadoop до сервисов BI-аналитики. Поэтому в облаке удобно как тестировать пилотные проекты и апробировать технологический стек, так и разворачивать полноценные решения для работы с данными.
Администрирование инфраструктуры и Managed-сервисов выполняет провайдер, а бизнес может не расширять собственный ИТ-отдел для этих задач. Более того, у провайдера можно запрашивать экспертизу и рекомендации по реализации проекта.
Рассмотрим один из вариантов архитектуры Big Data-решения с применением технологического стека на основе облачных сервисов на платформе VK Cloud.
| Этап |
Компонент |
Сервис VK Cloud |
| Источник |
Передача данных или файлов разных форматов от устройств, систем и БД |
Система-источник на стороне клиента |
| Озеро данных |
Хранение и обработка неструктурированных данных |
Arenadata Hadoop |
| Корпоративное хранилище данных |
Хранение структурированных данных |
Arenadata DB (на базе Greenplum) |
| Витрины данных |
Подготовка предметно-ориентированных выборок данных |
ClickHouse |
| BI-системы |
Подготовка отчетов и выгрузок данных, их визуализация для бизнес-пользователей |
Apache Superset |
В Big Data-проектах могут понадобиться дополнительные сервисы для инженеров данных и Data Scientists.
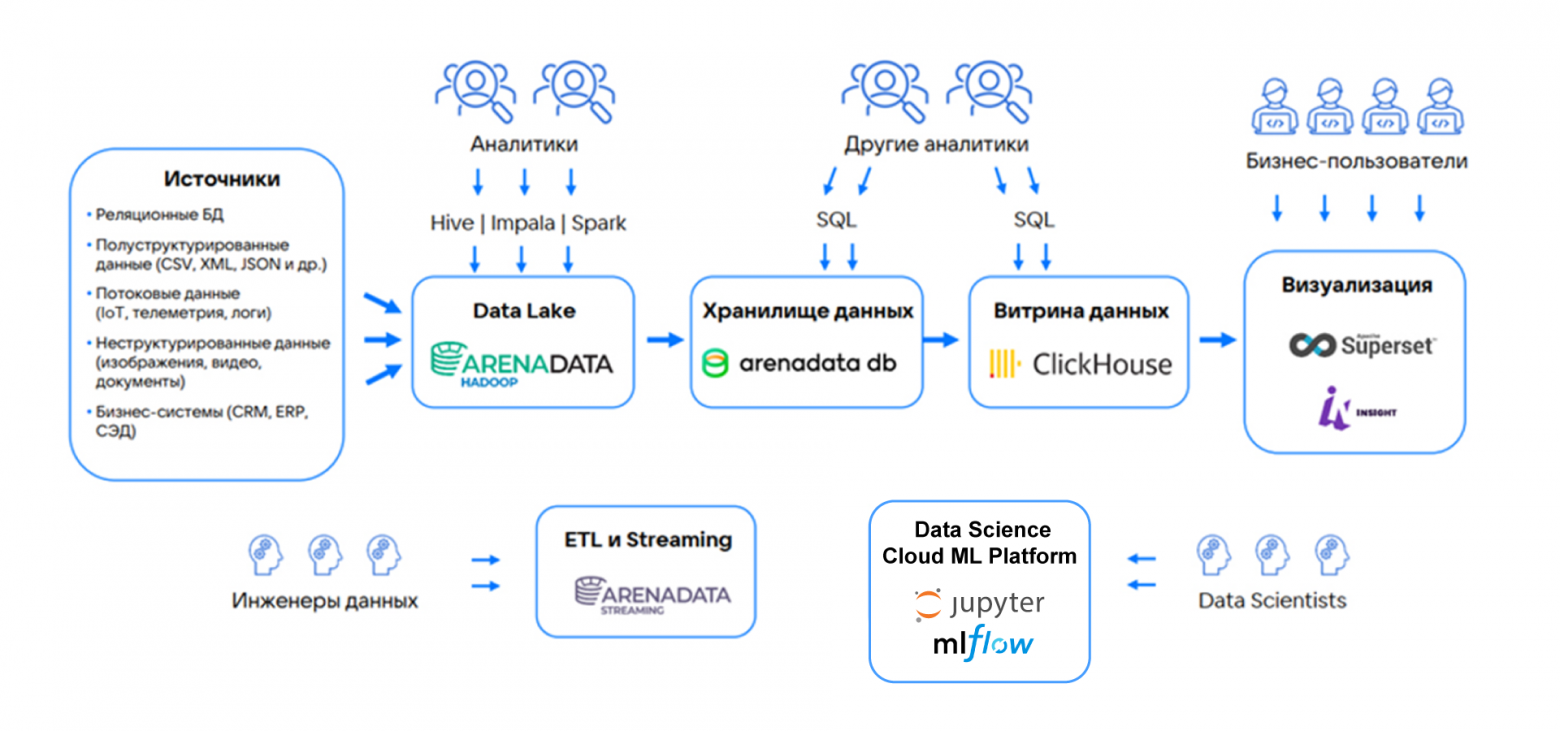
Пример архитектуры облачного Big Data-проекта с применением сервисов VK Cloud
Особенности развертывания проектов на облачной инфраструктуре
При реализации Big Data-проектов в облаке еще на этапе планирования или раннего внедрения надо учесть несколько моментов.
Обеспечить сетевую связность. Некоторые компании, у которых уже есть своя инфраструктура, хотят продолжать ее использовать в связке с облачной. Это можно организовать, но надо обеспечить сетевую связность: настроить коммуникацию, проработать алгоритм передачи данных от железа к облаку и учесть пропускную способность каналов.
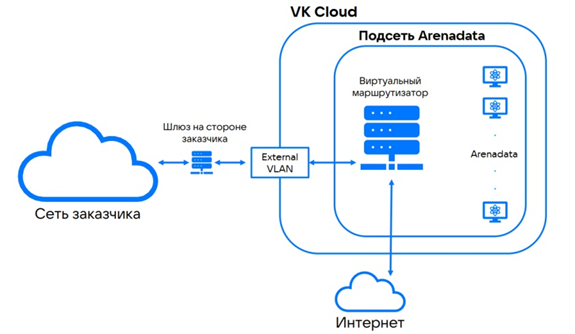
Пример схемы реализации сетевой связности в облаке VK Cloud
Выбрать и согласовать меры информационной безопасности (ИБ). Перед развертыванием Big Data-проекта в облаке надо разработать и согласовать со службой информационной безопасности меры защиты данных. В том числе: какие данные будут передаваться, через какие каналы (выделенные или публичные), каким требованиям ИБ должно соответствовать облако (например, в VK Cloud инфраструктура соответствует требованиям 152-ФЗ и УЗ-1). Отдельно надо прорабатывать и соблюдать меры внутренней защиты, которые не входят в зону ответственности облачного провайдера. Например, настроить резервное копирование и сбор логов, разделение ролей и прав доступа, добавить средства аутентификации и авторизации и др.
Проработать план миграции. Перенос данных без плана почти всегда обречен на провал. В плане надо учесть: какие данные надо перенести, сколько и в каком порядке, какие каналы использовать, когда именно переносить. При этом надо учитывать, можно ли остановить сервис — источник данных на период миграции.
Учитывать технические ограничения облака. Чтобы при реализации Big Data-проектов не возникло трудностей, еще на этапе планирования надо учесть технические возможности облачного провайдера. Например: пропускную способность, скорость подключения, предельные параметры виртуальных машин (ВМ), дисков, процессоров и отдельных компонентов. Эти ограничения будут влиять на формат архитектуры и стек технологий.
Использовать экспертизу облачного провайдера. Специалисты облачного провайдера зачастую имеют опыт участия в проектах с применением технологий для работы с Big Data. Их советы могут оказаться ценными для реализации проекта. Например, клиенты VK Cloud могут получить консультацию архитекторов, которые помогут подобрать оптимальную архитектуру и технологический стек, рассчитать необходимый объем ресурсов и не только.
Что учесть и запомнить
Внедрение Big Data-проектов — не быстрый процесс. Согласно исследованию VK Cloud, на это зачастую уходит от одного до двух лет. Реже — от двух лет.

Внедрение состоит из пяти этапов: разработка концепции управления данными, разработка архитектуры, определение инфраструктуры и стека, реализация, развитие и сопровождение.

На каждом из этапов внедрения надо решить много задач, каждая из которых требует определенной экспертизы. Поэтому для реализации проекта или его отдельных этапов компании нередко привлекают внешних интеграторов.

При внедрении Big Data-проектов некоторые компании создают отдел управления данными, для которого нужны специалисты разных направлений — от архитекторов до специалистов по качеству данных. Эта практика позволяет повысить эффективность внедрения проекта.

При реализации Big Data-проектов в облаке зоны ответственности разделены между заказчиком, интегратором и облачным провайдером. Умелое применение экспертизы каждого из участников и их слаженная работа с учетом опыта каждой их сторон позволяет эффективнее реализовать Big Data-проекты любой сложности.

За что конкретно отвечает заказчик, интегратор и облако при разделении зон ответственности
В облаке удобно реализовывать Big Data-проект. Необходимые вычислительные ресурсы и сервисы для работы с данными можно получить в несколько кликов, что значительно ускоряет запуск и реализацию проектов. Не нужно покупать и настраивать оборудование, готовить инфраструктуру, закупать и устанавливать ПО: облачный провайдер предложит преднастроенные инструменты и мощности для вашего проекта. Оплата облачных ресурсов — по модели Pay-as-you-go (только за фактически используемые ресурсы), а еще компания может заменить капитальные вложения (CAPEX) на операционные расходы (OPEX).
Облака позволяют легко, часто автоматически, масштабировать объем используемых ресурсов для хранения данных, их обработки или аналитики. Причем в сторону как увеличения, так и уменьшения, когда нагрузка снижается. При этом оплата начисляется по модели Pay-as-you-go. С физической инфраструктурой это невозможно: оборудование надо закупать впрок с учетом пиковых нагрузок, что не всегда оправдано и допустимо по бюджету.
Вы можете попробовать облачные сервисы VK Cloud для работы с Big Data. Для тестирования мы предоставляем расширенный грант, в рамках которого вы сможете использовать наши сервисы и инфраструктуру с оплатой по модели Pay-as-you-go, чтобы собрать прототип проекта и оценить его эффективность для своего бизнеса. Также мы предоставляем бесплатную консультацию архитектора (поможем выбрать стек технологий, построить архитектуру, расскажем про варианты на основе Open Source и проприетарного ПО) и поделимся, как работать с чувствительными данными в облаке и строить системы по требованиям ИБ.
