Хорошо, если у вас небольшие (сотни гигабайт) базы, а ночью или в выходные вы можете себе позволить иметь 'maintenance window' и дефрагментировать таблицы. А если нет? В любом случае дефрагментация многих терабайт может занять дни, так что существование maintenance window становится непринципиальным.
Case study: многие терабайты данных, деятельность связанная с процессингом карт (24/7, maintenance window нет в принципе), MSSQL. Разумеется, Enterprise Edition, разумеется AlwaysOn.
Миф: у нас SSD, поэтому дефрагментация нам не нужна. Еще как нужна! Часто в высоко нагруженных системах не делают дефрагментацию, потому что это сложно. В итоге процент фрагментации выходит на уровень почти 100%, и таблицы занимают в два раза больше страниц, чем нужно. В два раза больше места - это в два раза хуже Buffer Cache Hits Ratio. Это в два раза больше размер full backups. Это в два раза дольше full table scans. Это выше CPU (потому что страницы перемещаются с помощью процессора, а не сами по себе)
Итак, приступим.
Немного теории
В данном случае - без Enterprise edition никуда. А значит, у нас есть замечательная опция ALTER INDEX ... REBUILD (ONLINE=ON). И даже еще более замечательная опция (ONLINE=ON, RESUMABLE=ON). Не для всех индексов возможно использовать RESUMABLE, и даже ONLINE можно использовать не для всех, но мы будем оптимистами.
Если идет rebuild, то мы можем его приостановить командой
ALTER INDEX ... PAUSE
В таком состоянии недоперестроенный индекс виден в таблице
SELECT total_execution_time, percent_complete, name,state_desc, last_pause_time,page_count FROM sys.index_resumable_operations;
В таком состоянии rebuild может даже переехать на другую ноду в AlwaysOn! Проверено!
Также обратите внимание на замечательное поле percent_complete. (для filtered индексов, правда, это значение врет тем больше, чем сильнее отфильтрован индекс)
Командой ALTER INDEX ... RESUME мы можем продолжить выполнение операции (на самом деле RESUME это синтаксический сахар, просто повторяется команда REBUILD и перестроение продолжается. Вы можете это использовать исходную команду REBUILD вместо RESUME, но важно указать в точности все те же опции - по ходу дела поменять опции уже не получится, например, начав с MAXDOP=4 уже не получится его поменять), а командой ALTER INDEX ... ABORT можно прибить операцию.
В режиме RESUMABLE транзакции очень малы, так что нет причин боятся того, что лог (LDF) должен будет вместить в себя всю операцию по созданию новой версии индекса.
Первая попытка, неудачная
Ну что же, сгенерим скрипт с кучей ALTER INDEX, или напишем программу, или скрипт на SQL, который обходит все таблицы в цикле, и вперед! Это на несколько дней, поэтому запустим в пятницу и в понедельник проверим, как идут дела.
Можно закрывать ноут. А что это люди забегали? Про тормоза какие-то говорят... И что это за алерты пришли по длине очереди AlwaysOn? Интересно, связано это с тем, что я делаю? Так, а это уже серьезнее, какие-то крики про "все висит, блокировки, идут таймауты". Ох, они нашли мою коннекцию с REBUILD как ту, что блокирует других. А что это за паника что 'вообще все не работает, все висит и все индикаторы в Zabbix красные?'
И вот уже начальство с налитыми кровью глазами требует прибить этот жуткий REBUILD и больше никогда - слышите, никогда! его не запускать...
Я хочу спасти вас от этой ситуации. Итак, мы словили 4 проблемы, и будем с ними разбираться:
Сильная нагрузка на CPU (и IO)
Блокировки (!!!)
Рост размера LDF
Проблемы с AlwaysOn Queue
Придушивание (throttling)
Начнем с простого. При запуске мы не указали MAXDOP, а это принципиально. Отпущенный на волю с максимальным MAXDOP ребилд индекса может потребить сколько угодно ресурсов. Поэтому обязательно указываем MAXDOP, я рекомендую следующие значения:

В смысле не совсем то, но почти так:
MAXDOP=1 - ласково и нежно (но медленно)
MAXDOP=2 - нормальный режим
MAXDOP=4 - агрессивный режим
(без ограничения) - NIGHTMARE!
Стало много лучше, мы решили проблему с CPU (при MAXDOP=2 вы сожрете максимум две коровы, а у вас на боевом сервере их много). Но другие проблемы остались.
Например, в режиме MAXDOP=4 мощный сервер способен заполнять LDF со скоростью 1Gb/sec и более (гигабайт, а не гигабит). Это означает, что за 10 минут (что может быть промежутком между transaction log backup), мы заполним 600Gb в LDF, что довольно много. Хуже того, 1Gb/sec в LDF это 10 гигабит в секунду для AlwaysOn. 10 гигабит не так много для локальной сети, но ведь у вас реплики AlwaysOn расположены далеко, в других ДЦ?
На практике у нас ночью иногда забивался канал между ДЦ, и очередь росла. Итак, мы должны наблюдать за тем, сколько заполнено в LDF и каков размер очереди AlwaysOn. Если $db - это база, то рекомендую запрос:
USE [$db]; SELECT convert(int,sum(size/128.0)) AS CurrentSizeMB, convert(int,sum(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0)) AS FreeSpaceMB, (select sum(log_send_queue_size)+sum(redo_queue_size) from sys.dm_hadr_database_replica_states where database_id=DB_ID('$db')) as QueueLen FROM sys.database_files WHERE type=1
Таким образом, мы не можем воспользоваться sqlcmd, студией или SQL server job - мы должны написать скрипт с двумя тредами - один будет выполнять команды, а другой наблюдать за обстановкой и, если надо, делать PAUSE/RESUME. Коннекцию, которая делает REBUILD, лучше пометить program_name=уникальное имя, чтобы любым скриптам было бы легко ее находить.
По запросу выше имеет смысл ввести thresholds:
Максимальный размер занятого места в LDF (CurrentSizeMb-FreeSpaceMb)
Процент занятого места, если вы не предполагаете autogrowth LDF (FreeSpacemb/CurrentSizeMb)
Максимальный размер очереди QueueLen, рекомендую поиграть значениями в несколько миллионов.
Вот как это выглядит у меня, скрипт написан на PowerShell, будь он неладен:

Секунду, скажете вы. А почему вместо PAUSE автор использует команду kill? Потому что она короче и позволяет сэкономить несколько байт (нет). На самом деле причина важнейшая, и будет описана в следующем разделе.
Блокировки
Несмотря на то, что мы делаем REBUILD с ONLINE=ON, возможны блокировки с обеих сторон:
процесс(ы) в базе --> INDEX REBUILD --> процесс в базе
Правая часть нас не беспокоит. Наш rebuild может и подождать. Единственная проблема, это вопли плохо настроенной системы алертов, которая обнаружит процесс, который долго ждет блокировки. Вы помните, что мы пометили нашу коннекцию с помощью program_name=Rebuild? Это позволит нам добавить исключение (WHERE ... AND program_name not like 'Rebuild%') в систему алертов, чтобы игнорировать наш процесс. Если ваша система алертов полагается на датчики PerfMon, а не на запросы, то по этому поводу я уже ругался тут.
А вот левая часть важнее. Если мы блокируем какой-то процесс или процессы, то мы должны немедленно уступить, сделав PAUSE, а потом, через некоторое время, можно снова попробовать сделать RESUME.
Но главная проблема возникает, если одновременно возникают оба плеча блокировки. То есть наш процесс заблокирован (правое плечо), а потом возник процесс, который ждет нас. Мы вызываем команду PAUSE и... и ничего не происходит, потому что наш процесс заблокирован, а PAUSE доделывает последнюю порцию работы и только тогда останавливается.
Именно здесь нас выручает kill. Мы теряем последнюю порцию работы (порядка пары секунд), но мы гарантированно и быстро уступаем. После kill индексирование корректно переходит в статус PAUSED и его можно продолжить.
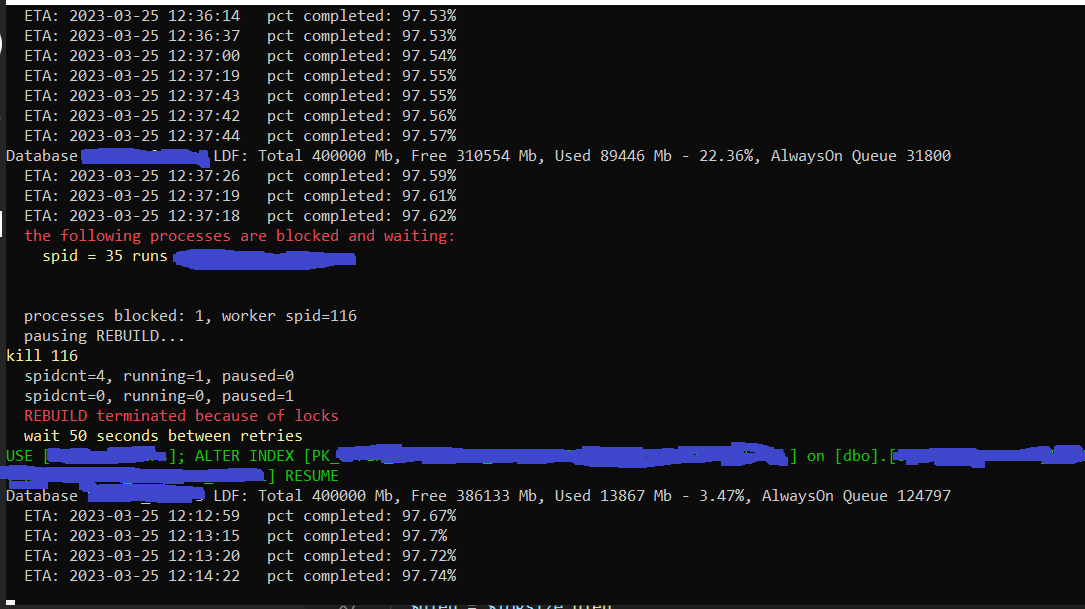
На скриншоте вы видите, как процесс уступает по блокировке (после kill коннекция завершилась не сразу (spidnct - количество записей в sysprocesses, running и paused - это количество операций в sys.index_resumable_operations в разных статусах)
Больше всего блокировок возникают на этапе подмены разделов, когда 100% работы выполнено и операция пытается завершиться
Общий план работ
Мы рассмотрели как делать INDEX REBUILD. А когда его лучше делать? Когда делать REORGANIZE, а когда REBUILD? Какие уровни фрагментации смотреть?
Начнем того, что не подвергается сомнению.
COLUMNSTORE лучше дефрагментировать с помощью REORGANIZE (список эвристик ниже только для обычных таблиц)
REORGANIZE всегда идет спокойно потому что работает в MAXDOP=1
REORGANIZE имеет смысл обернуть в тот же скрипт слежения.
Для маленьких таблиц (page_count<50) нормально иметь высокий уровень фрагментации даже после REBUILD
Теперь то, с чем вы можете не согласиться - это эвристики, которые я выработал для себя:
Если frag_pct менее 7%, то ничего делать и не надо
Если frag_pct в диапазоне 7%-20%, то делаем REORGANIZE
Если frag_cpt в диапазоне 20%-40%, то мы не делаем ничего, хотя это и может показаться странным. Для REORG уже слишком поздно, а для REBUILD слишком рано. Таблица выскочила за наш первую линию защиты, ну пусть тогда фрагментация растет дальше
Если frag_pct больше 40%, то делаем REBUILD ONLINE=ON, RESUMABLE=ON.
Если индекс большой и эти опции невозможны, то попробуем без них. Если пойдут блокировки, то добавим этот индекс в плохие ребята, которые дефрагментировать не будем.
Проверим состояние таблиц, например, через неделю. Учтите, что анализ уровня фрагментации даже в самом простом режиме 'LIMITED' может занять много часов и даже более суток.
Как правило, на больших базах рост фрагментации не так быстр, а в таблицах, где данные дописываются "в хвост", вообще минимален. Однако вы встретите индексы, которые приходят в глубоко фрагментированное состояние уже за сутки. Вы можете поиграть опциями индекса, но скорее всего, такой индекс надо просто записать в 'плохие ребята' и оставить его в покое. Непрерывные попытки дефрагментации не ускорят, а ухудшат общую производительность - надо подавить в себе перфекционизм и не пытаться наполнить водой ведро с дырками.
Вообще борьба с фрагментированными индексами выглядит так:

с тем исключением, что высунувшиеся зверьки сами не прячутся обратно.

