
В статье мы рассмотрим, как в Kubernetes-кластере под управлением Deckhouse удобно и быстро настраивать мониторинг с уведомлениями в Telegram. Воспользуемся VictoriaMetrics для хранения метрик, добавим дашборд в Grafana, создадим алерт и настроим оповещение.

Подготовка окружения
Нам потребуются:
Кластер Kubernetes с установленным Deckhouse и включенным модулем мониторинга.
kubectl. Команды можно выполнять как на master-узле, так и с любого другого устройства, настроив доступ к API кластера.
Учетная запись Telegram.
Установка VictoriaMetrics
Развернём VictoriaMetrics в пространстве имен victoria-metrics-test, выполнив следующие команды для установки из Helm-чарта с конфигурацией по умолчанию:
helm repo add vm https://victoriametrics.github.io/helm-charts/ && \ helm repo update && \ helm upgrade --install victoria-metrics vm/victoria-metrics-single --namespace victoria-metrics-test --create-namespace
Подключение VictoriaMetrics к Prometheus
Внешнее хранилище метрик в Deckhouse подключается с помощью CustomResource PrometheusRemoteWrite:
--- apiVersion: deckhouse.io/v1 kind: PrometheusRemoteWrite metadata: name: victoria-metrics spec: url: http://victoria-metrics-victoria-metrics-single-server.victoria-metrics-test.svc.cluster.local:8428/api/v1/write
В минимальной конфигурации в ресурсе PrometheusRemoteWrite достаточно указать адрес VictoriaMetrics. Также при необходимости можно ввести данные для аутентификации и настроить преобразование label’ов перед отправкой данных.
Все использованные конфигурационные файлы доступны в репозитории.
Применим конфигурационный файл в кластере:
kubectl create -f https://raw.githubusercontent.com/flant/examples/master/2023/03-monitoring/prometheus-remote-write.yaml
Здесь мы использовали подготовленный заранее template из репозитория на GitHub. Это не обязательно — применить файл с нужным содержимым в кластере можно любым удобным способом.
Подождем несколько минут и убедимся, что метрики поступают в кластер. Для этого достаточно посмотреть статус базы данных метрик на master-узле с помощью следующей команды:
curl $(kubectl --namespace victoria-metrics-test get ep -l "app=server" -o jsonpath="{.items[0].subsets[0].addresses[0].ip}"):8428/api/v1/status/tsdb
В результате должно отобразиться примерно следующее:
{"status":"success","data":{"totalSeries":100477,"totalLabelValuePairs":1099074,"seriesCountByMetricName":[{"name":"apiserver_request_slo_duration_seconds_bucket","value":15576},{"name":"apiserver_request_duration_seconds_bucket","value":8496},{"name":"etcd_request_duration_seconds_bucket","value":4284},{"name":"apiserver_response_sizes_bucket","value":3080},{"name":"apiserver_watch_events_sizes_bucket","value":1872},{"name":"trivy_vulnerability_id","value":1541},{"name":"workqueue_queue_duration_seconds_bucket","value":1089},{"name":"workqueue_work_duration_seconds_bucket","value":1089},{"name":"container_memory_failures_total","value":904},{"name":"scheduler_plugin_execution_duration_seconds_bucket","value":903}],"seriesCountByLabelName":[{"name":"__name__","value":100477},{"name":"prometheus","value":100477},{"name":"job","value":100171},{"name":"instance","value":99736},{"name":"tier","value":81434},{"name":"service","value":57725},{"name":"le","value":51720},{"name":"resource","value":36606},{"name":"version","value":34823},{"name":"namespace","value":33844}],"seriesCountByFocusLabelValue":[],"seriesCountByLabelValuePair":[{"name":"prometheus=deckhouse","value":100475},{"name":"tier=cluster","value":81434},{"name":"service=kubernetes","value":45705},{"name":"instance=192.168.199.9:6443","value":45196},{"name":"job=kube-apiserver","value":45196},{"name":"component=apiserver","value":31879},{"name":"version=v1","value":19859},{"name":"scope=cluster","value":19344},{"name":"container=kube-rbac-proxy","value":17796},{"name":"__name__=apiserver_request_slo_duration_seconds_bucket","value":15576}],"labelValueCountByLabelName":[{"name":"__name__","value":1870},{"name":"name","value":693},{"name":"resource","value":538},{"name":"le","value":379},{"name":"type","value":323},{"name":"secret","value":282},{"name":"hook","value":201},{"name":"kind","value":198},{"name":"controller_name","value":173},{"name":"installed_version","value":167}]}}
"status":"success" указывает на то, что все работает как нужно; если totalSeries больше нуля, то данные уже начали накапливаться.
Проконтролировать сбор метрик можно через веб-интерфейс VictoriaMetrics. Для этого пробросьте порт VictoriaMetrics на свой компьютер:
export POD_NAME=$(kubectl get pods --namespace victoria-metrics-test -l "app=server" -o jsonpath="{.items[0].metadata.name}") && kubectl --namespace victoria-metrics-test port-forward $POD_NAME 8428
Для успешного выполнения этой команды на машине, с которой выполняется запрос, должен быть настроен удаленный доступ для kubectl.
Веб-интерфейс станет доступен по адресу http://localhost:8428:

Перейдем на адрес http://localhost:8428/api/v1/status/tsdb — там также должен быть отображен статус "status":"success"; значение totalSeries больше нуля будет сигнализировать об успешном сборе метрик:

Теперь метрики хранятся в VictoriaMectrics. Подключим это хранилище к Grafana.
Подключение VictoriaMetrics к Grafana
Добавление нового datasource
Подключение datasource к Grafana в Deckhouse выполняется с помощью CustomResource GrafanaAdditionalDatasource:
--- apiVersion: deckhouse.io/v1 kind: GrafanaAdditionalDatasource metadata: name: victoria-metrics spec: access: Proxy basicAuth: false jsonData: timeInterval: 30s type: prometheus url: http://victoria-metrics-victoria-metrics-single-server.victoria-metrics-test.svc.cluster.local:8428/
Применим его в кластере:
kubectl create -f https://raw.githubusercontent.com/flant/examples/master/2023/03-monitoring/grafana-additional-datasource.yaml
Deckhouse перезапустит Grafana с новой конфигурацией, проверим ее готовность:
kubectl -n d8-monitoring get po -l app=grafana
Статус должен быть Running:
kubectl -n d8-monitoring get po -l app=grafana NAME READY STATUS RESTARTS AGE grafana-56df555c67-glzqr 3/3 Running 0 67s
Проверка подключения
Зайдем в веб-интерфейс Grafana и перейдем на вкладку Configuration -> Data sources:

В списке доступных источников должен отображаться victoria-metrics:

Откроем меню Explore:

Выберем victoria-metrics в качестве источника данных:

Раскроем Metrics browser: в нем должен отобразиться список метрик, полученных из VictoriaMetrics:
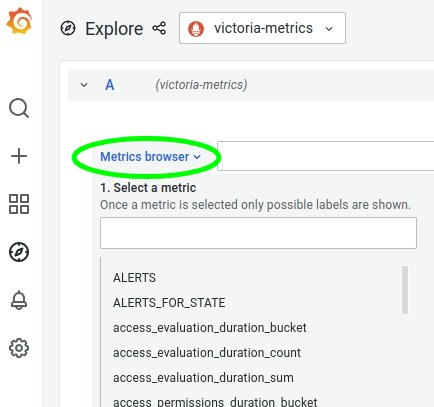
Все настроено и готово к работе.
Добавление алерта
Настроим уведомление о событиях, создав новый алерт.
В Deckhouse алерты описываются в CustomResource CustomPrometheusRules:
--- apiVersion: deckhouse.io/v1 kind: CustomPrometheusRules metadata: name: always-firing-alert spec: groups: - name: cluster-state-alert.rules rules: - alert: PrometheusCanScrapeTragets annotations: description: This is a fake alert only for a demo. summary: The alert shows that Prometheus can scrape targets. expr: | up{job="deckhouse"}
Созданный алерт «бесполезный» — он всегда активный, но хорошо подходит для целей тестирования.
Применим его в кластере:
kubectl create -f https://raw.githubusercontent.com/flant/examples/master/2023/03-monitoring/custom-prometheus-rule.yaml
Для проверки перейдем в Prometheus по адресу <адрес_Grafana>/prometheus/ и откроем вкладку Alerts. В строке поиска введем имя алерта — PrometheusCanScrapeTragets:

Алерт создан.
Добавление дашборда в Grafana
Создадим дашборд Services Up в каталоге Services (через CustomResource GrafanaDashboardDefinition):
--- apiVersion: deckhouse.io/v1 kind: GrafanaDashboardDefinition metadata: name: up-services spec: folder: Services definition: | { "annotations": { "list": [ { "builtIn": 1, "datasource": { "type": "grafana", "uid": "-- Grafana --" }, "enable": true, "hide": true, "iconColor": "rgba(0, 211, 255, 1)", "name": "Annotations & Alerts", "target": { "limit": 100, "matchAny": false, "tags": [], "type": "dashboard" }, "type": "dashboard" } ] }, "editable": false, "fiscalYearStartMonth": 0, "graphTooltip": 0, "id": 31, "links": [], "liveNow": false, "panels": [ { "datasource": { "type": "prometheus", "uid": "P0D6E4079E36703EB" }, "fieldConfig": { "defaults": { "color": { "mode": "palette-classic" }, "custom": { "axisLabel": "", "axisPlacement": "auto", "barAlignment": 0, "drawStyle": "bars", "fillOpacity": 15, "gradientMode": "none", "hideFrom": { "legend": false, "tooltip": false, "viz": false }, "lineInterpolation": "linear", "lineWidth": 10, "pointSize": 5, "scaleDistribution": { "type": "linear" }, "showPoints": "never", "spanNulls": false, "stacking": { "group": "A", "mode": "normal" }, "thresholdsStyle": { "mode": "off" } }, "mappings": [], "thresholds": { "mode": "absolute", "steps": [ { "color": "green", "value": null }, { "color": "red", "value": 80 } ] } }, "overrides": [] }, "gridPos": { "h": 26, "w": 24, "x": 0, "y": 0 }, "id": 2, "options": { "legend": { "calcs": [ "lastNotNull" ], "displayMode": "table", "placement": "right" }, "tooltip": { "mode": "single", "sort": "none" } }, "pluginVersion": "8.5.2", "targets": [ { "datasource": { "type": "prometheus", "uid": "P0D6E4079E36703EB" }, "editorMode": "code", "exemplar": false, "expr": "sum by (job, scrape_endpoint, scrape_source) (up)", "format": "time_series", "instant": false, "legendFormat": "{{ job }} {{ scrape_source }}", "range": true, "refId": "A" } ], "title": "Up", "transformations": [], "type": "timeseries" } ], "refresh": "30s", "schemaVersion": 36, "style": "dark", "tags": [], "templating": { "list": [] }, "time": { "from": "now-3h", "to": "now" }, "timepicker": { "refresh_intervals": [ "30s" ] }, "timezone": "", "title": "Services Up", "uid": "f_8jGXenz", "version": 1, "weekStart": "" }
И применим его в кластере:
kubectl create -f https://raw.githubusercontent.com/flant/examples/master/2023/03-monitoring/grafana-dashboard-definition.yaml
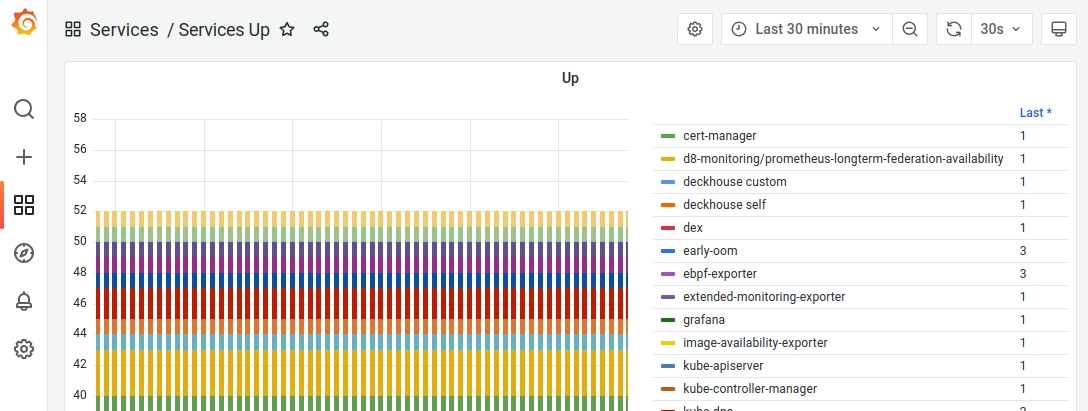
Проверим, что все отработало, перейдя по пути Services -> Services Up на вкладке Dashboards:

В созданном дашборде отобразится вот такой «частокол» алертов, привязанных ко всем сервисам Deckhouse в кластере:
Настройка уведомлений в Telegram
Подключение к Telegram
Если у вас уже есть ID чата, в который вы хотите получать уведомления, и токен бота, через которого вы хотите отправлять уведомления, то следующий этап можно пропустить и перейти сразу к настройке.
Создание бота и получение ID чата
Подробную инструкцию по созданию бота можно найти в документации Telegram.
В строке поиска клиента Telegram введем адрес https://t.me/botfather и найдем бота @BotFather. Не перепутайте его с другими — у настоящего отображается значок верификации:

Выберем его и нажмем Start. Затем отправим боту сообщение /newbot и ответим на поступившие вопросы, введя имя создаваемого бота и его ник.
Пример диалога создания бота @mytestalert2023bot:

Мы получим токен бота и ссылку. Пройдем по ней к диалогу с созданным ботом (в примере это http://t.me/mytestalert2023bot) и нажмем Start.
Теперь нужно узнать ID чата, куда будут отправляться сообщения.
Это могут быть как личные сообщения, так и группа или канал в Telegram. Во втором случае нужно предварительно добавить в них бота, а в конфиге указывать ID канала.
Узнаем ID учетной записи. Сделать это можно, выбрав бота @getmyid_bot и нажав Start. В ответ отобразится ID учетной записи Telegram:

Проверим работу сообщений через API Telegram.
Выполним следующую команду, указав вместо XXX токен бота (обратите внимание на префикс bot — токен идет после него), а вместо YYY — ID учетной записи Telegram:
curl -X POST "https://api.telegram.org/botXXX/sendMessage" -d "chat_id=YYY&text=text for test"
В ответ отобразится сообщение об успешной отправке:
{"ok":true,"result":{"message_id":2,"from":{"id":2222222222,"is_bot":true,"first_name":"mytestbot","username":"mytestalert2023bot"},"chat":{"id":2222222222,"first_name":"Joe","type":"private"},"date":1674327896,"text":"text for test"}}
… а нам придет личное сообщение от созданного бота.
Настройка отправки уведомлений
Создадим Secret telegram-bot-secret, указав токен бота:
kubectl create secret generic -n d8-monitoring telegram-bot-secret --from-literal=token=XXX
Создадим ресурс CustomAlertmanager:
--- apiVersion: deckhouse.io/v1alpha1 kind: CustomAlertmanager metadata: name: telegram spec: type: Internal internal: route: groupBy: [ 'job' ] groupWait: 30s groupInterval: 5m repeatInterval: 12h receiver: 'telegram' receivers: - name: telegram telegramConfigs: - botToken: key: token name: telegram-bot-secret chatID: 111
Применим его в кластере:
kubectl create -f https://raw.githubusercontent.com/flant/examples/master/2023/03-monitoring/alertmanager.yaml
В пространстве имен db-monitoring запустится Pod с AlertManager. Проверим, что он имеет статус Running:
kubectl -n d8-monitoring get po -l alertmanager
Пример вывода:
NAME READY STATUS RESTARTS AGE alertmanager-telegram-0 3/3 Running 1 (4m1s ago) 3m57s
Сейчас в журнале Alertmanager’а будут ошибки отправки, т. к. не указан ID чата, в который нужно отправлять сообщения. Посмотреть лог можно командой:
kubectl -n d8-monitoring logs alertmanager-telegram-0 -c alertmanager
ID чата указывается в параметре spec.internal.receivers.telegramConfigs.chatID CustomAlertmanager.
Ресурс можно либо отредактировать вручную (kubectl edit customalertmanager telegram), либо воспользоваться следующей командой, указав в переменной CHAT_ID ID учетной записи Telegram:
CHAT_ID=2222222222 && \ kubectl patch customalertmanager telegram --type json -p "[{\"op\": \"replace\", \"path\": \"/spec/internal/receivers/0/telegramConfigs/0/chatID\", \"value\": ${CHAT_ID}}]"
Alertmanager обновит свою конфигурацию и пришлет сообщение об алерте PrometheusCanScrapeTragets, созданном ранее, а также сообщения о других алертах, активных в кластере.

Убираем за собой
Для удаления созданных выше ресурсов выполните:
kubectl delete prometheusremotewrite victoria-metrics kubectl delete grafanaadditionaldatasource victoria-metrics kubectl delete customprometheusrules always-firing-alert kubectl delete grafanadashboarddefinitions up-services kubectl delete customalertmanager telegram helm uninstall victoria-metrics -n victoria-metrics-test kubectl delete ns victoria-metrics-test
Заключение
Мы рассмотрели, как подключить новое хранилище метрик к кластеру под управлением Deckhouse, создать алерт и настроить уведомления в Telegram. Здесь стоит обратить внимание, что все действия и настройки выполняются через custom resources. Такой декларативный подход соответствует общему тренду, при котором описание конфигурации инфраструктуры хранится в репозитории и последний используется как единственный источник настроек (GitOps).
С предложениями и вопросами ждем вас в комментариях, а также в Telegram-чате deckhouse_ru, где вам всегда помогут. Также будем рады Issues (и, конечно, звёздам) в GitHub-репозитории Deckhouse.
P.S.
Читайте в нашем блоге:
