Контекст
Примерно полтора года назад я попросил у своей бывшей компании разрешения поработать над проблемой, влиявшей на возможности отладки нашего проекта: gdbserver не мог отлаживать многопоточные приложения, работающие на архитектуре PowerPC32. Подключение к gdbserver было поломано, и он больше не мог контролировать сессию отладки. Разные люди исследовали эту проблему до меня, и у меня уже был неплохой фундамент, но мы всё равно не знали точно, в каком конкретно программном компоненте таится проблема: это мог быть тулчейн, gdbserver, ядро Linux или собственные патчи, которые мы устанавливали поверх дерева ядра. От нахождения первопричины мы находились довольно далеко.
Исследование проблемы
Изучив уже имевшиеся результаты анализа этой проблемы и воспользовавшись своими навыками гугл-фу, я сделал первое открытие: электронную переписку, в которой не только описывались те же симптомы, что и у нашей проблемы, но и указывался конкретный коммит, с которого она появилась. Патч, вносивший баг, перемещал определение thread_struct thread из середины task_struct в конец — казалось бы, невинное изменение.
После отладки этой проблемы Холгер Бранк заметил следующее:
По моим наблюдениям, gdbserver отправляет для каждого потока SIGSTOP ядру и ждёт ответа. Ядро получает все сигналы, но в случае ошибки отвечает только на некоторые из них. Затем это сопоставляется с моим выводом “ps”, так как я вижу, что некоторые потоки находятся не в состоянии pthread_stop, а потом gdbserver переходит в состояние ожидания.
На низком уровне проблема заключалась в том, что после взаимодействия с gdbserver некоторые потоки находились в ошибочном состоянии процесса и gdbserver больше не мог ими управлять.
Я потратил 3-4 дня на чтение описаний коммитов, связанных с архитектурой и с изменениями в task_struct, пытаясь разобраться, была решена ли эта проблема в последующих версиях ядра (спойлер: не была). Я перемещал thread_struct thread, чтобы определить, когда возникла проблема, и использовал pahole для изучения структуры task_struct. Я воспользовался ftrace, чтобы разобраться, когда диспетчеризировались потоки отлаживаемого процесса, и так понял, что это может быть проблема повреждения памяти: зависавшие потоки, в отличие от всех других, диспетчеризировались только один раз. Изначально я отказался от мысли, что это может быть проблема повреждения памяти, потому что в исходной переписке говорилось следующее:
содержимое буфера всегда равно нулю и не меняется. То есть, по крайней мере, никто не записывает ненулевые значения в буфер.
И вот что я получил за то, что не проверил, что структура не переписывается нулевыми байтами (всегда проверяйте свои допущения).
Я помнил, что в архитектуре x86 есть отладочные регистры , которые можно использовать для срабатывания контрольных точек записи данных. На самом деле, именно так я устранил баг в своём прошлом разработчика ПО. Разумеется, PowerPC тоже реализует подобную функциональность при помощи регистра DABR.
Я изучил, как можно использовать аппаратные контрольные точки в Linux, и в конечном итоге реализовал по этому прекрасному ответу на StackOverflow модуль ядра Linux. Это позволило мне установить аппаратную контрольную точку на поле __state, чтобы определить, что же выполняет в него запись.
Поиск бага
И именно так я нашёл проблему: мой модуль ядра показал трассировки стека из мест, где выполнялась запись в поле __state структуры task_struct. Я обратил внимание на странность, выявившую переполнение буфера в ptrace_put_fpr (используемого POKEUSER API). Это привело к переписываю важных полей из task_struct, например __state, в котором хранится состояние процесса и которое также используется ядром для отслеживания того, какие процессы остановлены отладчиком.
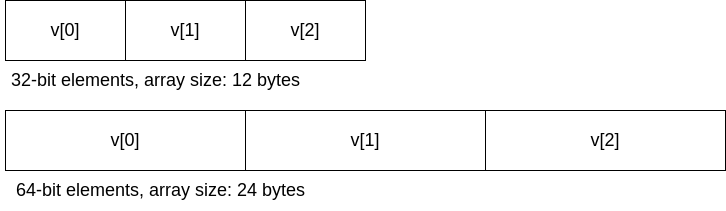
Что же было причиной этого переполнения? Получение индекса, который должен был использоваться с массивом 32-битных элементов и индексирование массива 64-битных элементов. Было 64 индексов, адресующих FPR, то есть общая адресуемая память составляла 64 * 8 = 512 байтов. Но в массиве fp_state.fpr было только 32 записи, то есть доступной памяти имелось всего 32 * 8 = 256 байтов. Это позволяло пользователю (то есть gdbserver), записывать до 256 байтов после конце массива.

Отправка патча апстрим
Я отправил патч команде безопасности ядра (security@kernel.org), потому что решил перестраховаться: проблема повреждения памяти, способная переписывать состояния процессов, может иметь последствия для безопасности. К сожалению, список рассылки приватный, так что я не могу дать ссылку на исходный патч, отправленный мной. Мне ответил мейнтейнер PowerPC Майкл Эллерман, сказав, что свяжется со мной лично, чтобы разобраться в проблеме. Я отправил ему два патча с устанением проблемы: исходный, который отправил в список рассылки безопасности, и ещё одну версию (достаточно сильно отличающуюся от первой), в которой реализовывались некоторые предложения, полученные в ответе на мой первый патч. Второй патч был основан на уже существующем коде ядра, эмулирующем операции PowerPC32 на PowerPC64 (да, там индексирование FPR реализовано верно). Ни один из них не был принят Майклом Эллерманом и вместо этого он реализовал собственную версию исправления. Я сказал ему, что был бы очень признателен, если он примет патч от меня, чтобы я получил свидетельство об устранении этой проблемы и стал контрибьютором ядра. Кроме того, я был открыт к работе с ним, отвечал на его отзывы и отправлял последующие версии патчей. Он сказал примерно следующее (передаю общий смысл):
Простите, но моя версия лучше. Если вы хотите быть контибьютором ядра Linux, то вот проблема, которую можно решить.
Мне показалось это очень непонятным и оскорбительным. Вместо того, чтобы признать мой вклад в решение проблемы, он лишь дал мне ещё больше работы. Моя компания и я должны были получить надлежащую репутацию за решение этой проблемы, особенно учитывая объём приложенных усилий.
Я считаю очень несправедливым, что нам выдали только тэг Reported-by. Вот в чём заключается предназначение этого тэга:
Тэг Reported-by позволяет отдать должное людям, которые находят баги и сообщают о них; его цель — вдохновлять таких людей помогать нам в будущем.
Ну, лично я точно не вдохновился на помощь сообществу разработки ядра. Напротив, я ощущаю себя униженным и разгневан, что моя работа не получила должного признания.
Заключение
Я потратил много времени и труда на анализ первопричины, устранение бага, тестирование и валидацию исправления, получение обратной связи от других инженеров моей компании, адаптацию исправления под последнюю версию ядра и отправку двух патчей мейнтейнеру PowerPC Майклу Эллерману. Вместо того, чтобы принять мой патч или подсказать направление к верному решению, он реализовал собственное исправление, поблагодарив только за отчёт о проблеме (о которой уже сообщали шестью годами ранее).
Мой первый вклад в ядро был очень разочаровывающим и досадным опытом, я столкнулся с людьми, которые не считают важным отдать тебе должное за твою работу.

