По теме данного дистрибутива и его пакетов.
В описании написано что пакеты монолитные, то есть они собраны так что либы в бинарник входят или как? Пояснить почему так сделано (я примерно понимаю почему, но чтоб для всех), с какого размера либы не имеет смысла пихать в бинарник или при любом размере лучше монолит, или это от частоты обращения зависит (например в либе тяжелый вычислительный код и ее функции в разных тредах запускаются имеет ли смысл ее в один фаил включать?). И нет ли мыслей прикладное ПО отделить вообще от дистрибутива, если оно все с собой несет
Так как это пособие является практическим, описание совмещения блокировок компилятором и про-
становки маловероятных чтений в спекулятивный режим будет пропущено.
И как без описания понять что это такое? Про линейные участки и префетчь хоть понятно примерно, а вот что такое "совмещение блокировок" да еще каким то программным способом — непонятно.
И это еще быстрее. А VLIW сложил два числа и ждет соседний load.
Конвейризованные архитектуры так не работают, там команда за командой запускается каждый такт и никто никого не ждет, но если у тебя следующая команда оперирует теми же регистрами на которых ты в предыдущем такте сложение или лоад запустил, то она будет ждать пока регистры не будут готовы. Арифметика имеет фиксированное число стадий исполнения поэтому легко предугадывается в коде, и до нее можно еще пихнуть команд. Ну а нечего пихнуть можно выровнять нопами.
Другое дело лоад, при котором неизвестно где данные окажутся и первая же команда которая обращается к этому регистру, заблокирует конвеер на ожидании готовности. У оут-оф-ордера есть преимущество — он может отложить все операции которые зависят от лоада. Вот только тут тоже есть вопросы: у интела конвееры в 14 или даже больше стадий, когда данные загрузятся он опять все эти команды через все стадии прогонит получается. Не получится ли так что влив который постоял/покурил подождал подготовки регистров, засчет своей ширины и готовности конвеера по времени догонит то что интел наисполнял между задержками, пока он опять загоняет команды в конвеер, к тому же они все полностью или частично все равно зависимые.
Так что преимущество не очевидно так как ОоО тоже далек от идеала.
если Вы представили идеальный простой VLIW-процессор, то сравнивайте с идеальным простым обычным процессором
Я представил существующий в железе и работающий эльбрус, и можно его же представить в виде обычного риск процессора, просто выписав все инструкции из широких команд в линеечку — декодер будет такой же, просто во вливе он широкий параллельный а в риске маленький на одну инструкцию.
а как у эльбруса обрабатывается обращение к памяти, вызвавшее промах кэша? ЕМНИП, тормозится исполнение всего потока команд.
Никак, да, боль и унижение. Хотя вообще то мог бы на другом конвеере что то исполнять в таких случаях, у него их там несколько штук для подготовки колов/переходов.
процессор с SMT в таком случае может пока исполнять задания из параллельного потока.
Если у тебя две задачи запущены на одном ядре, то одно не заблокирует другое вот и все. Но так же оно у тебя и на физических ядрах не заблокируется, а больше ничего SMT и не дает, скорее как раз отнимает интерфейс памяти у одного потока, так бы он мог несколько загрузок сделать и что то уже посчитать пока тут на регистры загружается, а так у тебя другой поток каналы чтения записи в кэш забрал и отнять их теперь нельзя.
ИМХО правильнее делать суперскалярность на основе потока мелких команд с явно прописанными зависимостями, условно говоря, как в makefile
Еще один плюс VLIW на нем наглядней видно как все работает и гораздо быстрее все усваивать. Процессоры устроены немного сложней
Команда пришла, есть где ее исполнять — отдаем, нет — сохраняем и парсим следующую.
Это обычный суперскаляр с конвеером так работает, а внеочередное исполнение вытаскивает наиболее потенциально долгие команды (например лоады или деление) и исполняет их как можно раньше не дожидаясь даже проверки условия (здравствуй spectre) или откладывая эксепшн в случае деления на ноль.
будет работать быстрее, чем VLIW-фронтенд, обрабатывающий пакет команд, следовательно команда сможет уйти на выполнение раньше и отработать быстрее.
Как он может быть быстрее, если во вливе ассемблер это практически уже микрокод который прям как написан так и исполняется, декодирование там настолько простое что команда за один такт должна оказаться на конвеере иначе код просто ломается.
тот же SMT целиком и полностью существует за счёт этой самой суперскалярности.
Это вопрос каверзный, из за того что ОоО-суперскаляр не может загрузить свои исполнительные блоки ему придумывают SMT, чтоб хоть забить его разными потоками. Влив в такой парадигме существовать не обязан если тебе надо много потоков — делай влив с небольшим числом устройств и пусть их будет много, а то и вообще оставь одно большое и окружи его кучей мелких как будто у тебя IBM cell
VLIW, конечно имеет свои плюсы, в первую очередь он гораздо проще, за счёт этого тем же числом транзисторов в числодробилках можно большей производительности достичь, но числодробилки — это далеко не все задачи.
Ну вот статически откомпилированные программы только в числодробилках хорошо работают? Нет, но какие то вещи на них делать сложнее чем на динамических языках, а какие то вещи (как например ООП в плюсах) так и вовсе оказалось можно вполне реализовать статически без рантайма и как то это работает вполне успешно.
Вот так же и с вливом примерно
В чем железное внеочередное исполнение может быть хуже? В потреблении энергии что ли?
Ну да, оно ведь профили программ не составляет и код в оптимальном порядке никуда не сохраняет, сколько раз ему одно и то же сунешь он столько же раз его будет перепланировать расходуя ток. И здесь проявляется второй недостаток — планировщик очень ограниченный и не видит инструкции которые еще не прошли через фронтенд и не попали в буфер переупорядочивания. Последнее частично фиксится оптимальным выстраиванием потока инструкций компилятором, но система команд полноценно это делать не позволяет. Ну и как следствие устройств много не натыкаешь так как планировщик усложняется в след за их добавлением.
Не имелось в виду то что выше написал. В эльбрусах и итаниумах как такового внеочередного исполнения вообще нет они строго in-order superscalar, но там есть возможность переставить команды
с помощью компилятора и т.п.
и таким образом реализуется внеочередное исполнение. И его нельзя напрямую сравнивать с железным внеочередным исполнением, они разные и в чем-то лучше один, а в чем-то другой.
Если по чесноку то ничего, x86 это система команд (или архитектура в терминах интела), которая реализовывалась поверх самых разных микроархитектур в том числе и без внеочередного исполнения (например старые атомы). Так что у интела суперскалярность и внеочередное исполнение часть микроархитектуры конкретного семейства и появилось оно впервые не 20 лет назад а больше, в процессорах пентиум если я не ошибаюсь да и чуть ли не позже чем оно появилось у всех остальных.
А вот как раз спекулятивность/суперскалярность на уровне системы команд (как в эльбрусе) появилась в итаниуме 20лет назад. Поэтому даты верные, сравнения не верные.
Взяли пару удачных вещей
Взяли просто x86 от которого они уже поняли что не избавятся и посадили на итаниумовскую шину и все остальное так появилось поколение i7-i5, а сам итаниум и легаси x86 платформу закопали. AMD кстати свой HyperTransport купила у трансметы (надеюсь не надо говорить кто это), да и технологии всякие типа nxBit тоже оттуда понатасканы, так что вклад внесен немалый.
В итоге винты, конденсаторы, светодиоды, резисторы, вентиляторы, блок питания — комплектующие иностранного происхождения — составляют 6,5% от стоимости СХД BITBLAZE Sirius 8000. В 94,5% стоимости входит корпус, печатные платы, материнская плата, процессор, световоды, произведенные в России.
Экономическая мерка это конечно весомый аргумент для чиновника в минпромторге, но всенародно об этом объявлять лучше не стоит. В не искушенной графиками экономической эффективности голове обывателя сразу рисуется пустой корпус и прикрученный текстолит с дорожками, без россыпи, без процессора (так как он тоже на Тайване делается и 100% российским его считать нельзя) без контроллеров, без дисков, без вентиляторов/радиаторов и блока питания. Где же это 90% если половины необходимых для работы сервера частей нет. А если еще учитывать что фактически все самое сложное и трудоемкое в замещении нуждается, то и больше половины. А так можно и одни болты сделать по цене в полстоимости всей системы произведенной в китае и объявить о локализации 50%.
Но то что честно и открыто даете разъяснения насчет цифр это в целом хороший знак, кликбейт можно простить и понять, но если вместо ответов льют воду (как представители всяких байкалов и моих офисов) — такое уже не прощается.
Профессионалы, которые могли нам помочь, заняты в основном на предприятиях оборонно-промышленного комплекса. С ними достаточно сложно построить отношения с точки зрения бизнеса, поскольку разговариваем мы на разных языках.
У представителей российского бизнеса и прочих деловых российских кругов с народом тоже как правило язык и образы мышления разные. Не знаю с чем это связано, но может в этом все дело.
"По нормальному" это как? Бухгалтерша пойдет в DNS и на свои купит 1000 пк-рен, а ей с зарплаты отдадут? В крупных закупках так не работает, во первых там нет денег "сразу" там есть договорное-обязательство их перечислять в такие то сроки такими то долями. То есть компьютерщик вася и бухгалтерша лена с компьютерным магазином идут лесом, тут нужна организация которая это все исполнит и возьмет на себя полную ответственность.
Это просто в крупных закупках в какой нибудь крупной организации, она может там в случае чегокакие нибудь риски принимать соглашаться подождать еще как то договорится, а в бюджетной подозреваю такой свободы нет так как это не их деньги а казенные и подотчетные (собственно поэтому их и воруют потому что ни что так не соблазняет на воровство как казенное имущество, это не у пети украсть последнее это из общака стырить себе на нештяки)
Вся элементная база у нас была своя. Так же, как конструктивы и технология. Заимствовали основы архитектуры, а главное, идеологию операционных систем, чтобы обеспечить совместимость с зарубежным программным обеспечением. Под требования совместимости приходилось подстраиваться и СМ, и ЕС. И это была настоящая творческая работа.
Господи, какое непрекрытое вранье! У него на СМ 1700 был полностью ворованный софт, с затерными копирайтами, откуда он взял «свою» элементарную базу — отдельный вопрос, она ведь тоже была копией западной.
Мерзский тип, сейчас нет сил дочитывать его вранье, завтра подробнее прочитаю интервью этого жулика.
Элементарная база это транзисторы/резисторы итд итп. кроме того тут же прямо написано что делали так чтоб софт под пдп или под что там запускался.
По какому поводу вы собственно воспламенились? Рискну предположить что кому то неприятно от истории рассказывающих с кем он по роду деятельности встречался и общался. С чьей то картиной мира видимо не состыкуется.
Они vendor_id приделали нарочно что бы винда цепляла драйвер. У них же железо еще и винду запускать умеет.
В свое время игрался с хакинтошем, так вот что бы дрова на сеть и звук цеплялись приходилось патчить драйвер тупой заменой чужого айди на айди своих сетевух/звуковух. Естественно там это все через загрузчик на лету делается, но факт в том что даже если у тебя сетевушка и звук под стандарты High Definition Audio и гигабит эзернет сделаны, то стандартные драва все равно могут не работать если в них проверка vendor_id и даже device_id как в макоси стоит. И нигде никак программно левые айди не подсунуть, поэтому хакинтошники как уж только эту ос через загрузчик не научились налюбливать, а кексты патчат до сих пор.
Так вот, до конца понять что же такое каналы в терминологии Эльбруса, не удалось. Рискну предположить, что это связано уже с принципом vliw, когда можно указать, какое именно alu используется, ведь в этом типе архитектуры одной из особенностей является наличие нескольких независимых вычислительных устройств.
Жаль, я думал вы расскажете какие у них там секреты есть и что они от нас скрывают
В центральной части видно ALC c номерами это такие конвейеры параллельные и у каждого подписаны какие типы типы операций могут быть. В ассемблере это выглядит примерно так (тут две широкие команды типа):
Но это естественно не так все просто, там очень много нюансов которые надо изучить — четыре загрузки можно только короткие слова, ldd тобишь двойные только два вроде. Деление только в 5 канале, но это на диаграме выше видно. Сравнение в 0 и вот этого на диаграме нет как и много чего еще. В любом случае в каналах как я понимаю только операции связанные с вычислениями ну и с ld/st, то есть это далеко не вся структура ШК еще. У вас в документации наверняка написано намного больше.
регистров по которым у него ездит окно — 192
плюс еще есть 32 глобальных регистра и 32 регистра с однобитными значениями
у него есть три дополнительных конвеера и три регистра передачи управления (ctpr1,2,3):
Перед тем как куда то прыгнуть, надо задолго до перехода назначить грузить код в один из параллельный конвееров
disp %ctpr3, $_ZNSsC1EPKcRKSaIcE; ipd 2
что бы потом прыгнуть без задержек
call %ctpr3, wbs = 0x1d
после запятой это я так понимаю количество регистров текущего окна которое будет доступно со всеми их значениями в следующей процедуре. Когда он перейдет окно сдвинется вперед что бы сохранить контекст текущей процедуры, там посчитает, вернется окно сдвинется назад на исходную.
ретерн осуществляется аналогично -
return %ctpr3; ipd 2
положили адрес возврата
ct %ctpr3
вышли передали управление
То есть где какие тут должны быть переключения контекстов я не очень понимаю.
А, тогда извини. Ну там это "работающее решение" каждый год поддержку требует во первых (см. видео внизу), во вторых его не выкидывают на свалку же. В статье синьюз 2016г писалось что айбиэмку куда то в более нагруженное место встроить собирались.

Уныло, я думал на эльбрусе так гораздо быстрей, тогда создавать и поддерживать свой дистрибутив имело бы больше смысла.
А там кроcскомпилятор в дистре есть или опять не положили?
Перестать оправдываться перед всеми и начать жить. Не предложение а просто совет мимокрока.
По теме данного дистрибутива и его пакетов.
В описании написано что пакеты монолитные, то есть они собраны так что либы в бинарник входят или как? Пояснить почему так сделано (я примерно понимаю почему, но чтоб для всех), с какого размера либы не имеет смысла пихать в бинарник или при любом размере лучше монолит, или это от частоты обращения зависит (например в либе тяжелый вычислительный код и ее функции в разных тредах запускаются имеет ли смысл ее в один фаил включать?). И нет ли мыслей прикладное ПО отделить вообще от дистрибутива, если оно все с собой несет
И как без описания понять что это такое? Про линейные участки и префетчь хоть понятно примерно, а вот что такое "совмещение блокировок" да еще каким то программным способом — непонятно.
Конвейризованные архитектуры так не работают, там команда за командой запускается каждый такт и никто никого не ждет, но если у тебя следующая команда оперирует теми же регистрами на которых ты в предыдущем такте сложение или лоад запустил, то она будет ждать пока регистры не будут готовы. Арифметика имеет фиксированное число стадий исполнения поэтому легко предугадывается в коде, и до нее можно еще пихнуть команд. Ну а нечего пихнуть можно выровнять нопами.
Другое дело лоад, при котором неизвестно где данные окажутся и первая же команда которая обращается к этому регистру, заблокирует конвеер на ожидании готовности. У оут-оф-ордера есть преимущество — он может отложить все операции которые зависят от лоада. Вот только тут тоже есть вопросы: у интела конвееры в 14 или даже больше стадий, когда данные загрузятся он опять все эти команды через все стадии прогонит получается. Не получится ли так что влив который постоял/покурил подождал подготовки регистров, засчет своей ширины и готовности конвеера по времени догонит то что интел наисполнял между задержками, пока он опять загоняет команды в конвеер, к тому же они все полностью или частично все равно зависимые.
Так что преимущество не очевидно так как ОоО тоже далек от идеала.
Я представил существующий в железе и работающий эльбрус, и можно его же представить в виде обычного риск процессора, просто выписав все инструкции из широких команд в линеечку — декодер будет такой же, просто во вливе он широкий параллельный а в риске маленький на одну инструкцию.
Если у тебя две задачи запущены на одном ядре, то одно не заблокирует другое вот и все. Но так же оно у тебя и на физических ядрах не заблокируется, а больше ничего SMT и не дает, скорее как раз отнимает интерфейс памяти у одного потока, так бы он мог несколько загрузок сделать и что то уже посчитать пока тут на регистры загружается, а так у тебя другой поток каналы чтения записи в кэш забрал и отнять их теперь нельзя.
Еще один плюс VLIW на нем наглядней видно как все работает и гораздо быстрее все усваивать. Процессоры устроены немного сложней
Это обычный суперскаляр с конвеером так работает, а внеочередное исполнение вытаскивает наиболее потенциально долгие команды (например лоады или деление) и исполняет их как можно раньше не дожидаясь даже проверки условия (здравствуй spectre) или откладывая эксепшн в случае деления на ноль.
Как он может быть быстрее, если во вливе ассемблер это практически уже микрокод который прям как написан так и исполняется, декодирование там настолько простое что команда за один такт должна оказаться на конвеере иначе код просто ломается.
Это вопрос каверзный, из за того что ОоО-суперскаляр не может загрузить свои исполнительные блоки ему придумывают SMT, чтоб хоть забить его разными потоками. Влив в такой парадигме существовать не обязан если тебе надо много потоков — делай влив с небольшим числом устройств и пусть их будет много, а то и вообще оставь одно большое и окружи его кучей мелких как будто у тебя IBM cell
Ну вот статически откомпилированные программы только в числодробилках хорошо работают? Нет, но какие то вещи на них делать сложнее чем на динамических языках, а какие то вещи (как например ООП в плюсах) так и вовсе оказалось можно вполне реализовать статически без рантайма и как то это работает вполне успешно.
Вот так же и с вливом примерно
Ну да, оно ведь профили программ не составляет и код в оптимальном порядке никуда не сохраняет, сколько раз ему одно и то же сунешь он столько же раз его будет перепланировать расходуя ток. И здесь проявляется второй недостаток — планировщик очень ограниченный и не видит инструкции которые еще не прошли через фронтенд и не попали в буфер переупорядочивания. Последнее частично фиксится оптимальным выстраиванием потока инструкций компилятором, но система команд полноценно это делать не позволяет. Ну и как следствие устройств много не натыкаешь так как планировщик усложняется в след за их добавлением.
Не имелось в виду то что выше написал. В эльбрусах и итаниумах как такового внеочередного исполнения вообще нет они строго in-order superscalar, но там есть возможность переставить команды
и таким образом реализуется внеочередное исполнение. И его нельзя напрямую сравнивать с железным внеочередным исполнением, они разные и в чем-то лучше один, а в чем-то другой.
Если по чесноку то ничего, x86 это система команд (или архитектура в терминах интела), которая реализовывалась поверх самых разных микроархитектур в том числе и без внеочередного исполнения (например старые атомы). Так что у интела суперскалярность и внеочередное исполнение часть микроархитектуры конкретного семейства и появилось оно впервые не 20 лет назад а больше, в процессорах пентиум если я не ошибаюсь да и чуть ли не позже чем оно появилось у всех остальных.
А вот как раз спекулятивность/суперскалярность на уровне системы команд (как в эльбрусе) появилась в итаниуме 20лет назад. Поэтому даты верные, сравнения не верные.
Взяли просто x86 от которого они уже поняли что не избавятся и посадили на итаниумовскую шину и все остальное так появилось поколение i7-i5, а сам итаниум и легаси x86 платформу закопали. AMD кстати свой HyperTransport купила у трансметы (надеюсь не надо говорить кто это), да и технологии всякие типа nxBit тоже оттуда понатасканы, так что вклад внесен немалый.
В итаниуме — да, как и другие "ноу-хау" в других архитектурах по отдельности, но не в x86.
В x86 внезапно, EFI QPI и наработки по компилятору все перетекли в x86 из итаниума.
В китае есть свои фабы, самый передорвой до 14нм
https://ru.wikipedia.org/wiki/SMIC
Экономическая мерка это конечно весомый аргумент для чиновника в минпромторге, но всенародно об этом объявлять лучше не стоит. В не искушенной графиками экономической эффективности голове обывателя сразу рисуется пустой корпус и прикрученный текстолит с дорожками, без россыпи, без процессора (так как он тоже на Тайване делается и 100% российским его считать нельзя) без контроллеров, без дисков, без вентиляторов/радиаторов и блока питания. Где же это 90% если половины необходимых для работы сервера частей нет. А если еще учитывать что фактически все самое сложное и трудоемкое в замещении нуждается, то и больше половины. А так можно и одни болты сделать по цене в полстоимости всей системы произведенной в китае и объявить о локализации 50%.
Но то что честно и открыто даете разъяснения насчет цифр это в целом хороший знак, кликбейт можно простить и понять, но если вместо ответов льют воду (как представители всяких байкалов и моих офисов) — такое уже не прощается.
У представителей российского бизнеса и прочих деловых российских кругов с народом тоже как правило язык и образы мышления разные. Не знаю с чем это связано, но может в этом все дело.
"По нормальному" это как? Бухгалтерша пойдет в DNS и на свои купит 1000 пк-рен, а ей с зарплаты отдадут? В крупных закупках так не работает, во первых там нет денег "сразу" там есть договорное-обязательство их перечислять в такие то сроки такими то долями. То есть компьютерщик вася и бухгалтерша лена с компьютерным магазином идут лесом, тут нужна организация которая это все исполнит и возьмет на себя полную ответственность.
Это просто в крупных закупках в какой нибудь крупной организации, она может там в случае чегокакие нибудь риски принимать соглашаться подождать еще как то договорится, а в бюджетной подозреваю такой свободы нет так как это не их деньги а казенные и подотчетные (собственно поэтому их и воруют потому что ни что так не соблазняет на воровство как казенное имущество, это не у пети украсть последнее это из общака стырить себе на нештяки)
стопэ, производились то где? Если в СССР, то это и есть своя элементарная база, чей бы они там дизайн защищенный/незащищенный не копировали.
Впрочем подозреваю для кибертараса это не аргумент, так как дело принципа, а на истину плевать.
Потенциально этим занимается практически все проприетарное ПО, ненавидь всех.
Элементарная база это транзисторы/резисторы итд итп. кроме того тут же прямо написано что делали так чтоб софт под пдп или под что там запускался.
По какому поводу вы собственно воспламенились? Рискну предположить что кому то неприятно от истории рассказывающих с кем он по роду деятельности встречался и общался. С чьей то картиной мира видимо не состыкуется.
Они vendor_id приделали нарочно что бы винда цепляла драйвер. У них же железо еще и винду запускать умеет.
В свое время игрался с хакинтошем, так вот что бы дрова на сеть и звук цеплялись приходилось патчить драйвер тупой заменой чужого айди на айди своих сетевух/звуковух. Естественно там это все через загрузчик на лету делается, но факт в том что даже если у тебя сетевушка и звук под стандарты High Definition Audio и гигабит эзернет сделаны, то стандартные драва все равно могут не работать если в них проверка vendor_id и даже device_id как в макоси стоит. И нигде никак программно левые айди не подсунуть, поэтому хакинтошники как уж только эту ос через загрузчик не научились налюбливать, а кексты патчат до сих пор.
Жаль, я думал вы расскажете какие у них там секреты есть и что они от нас скрывают
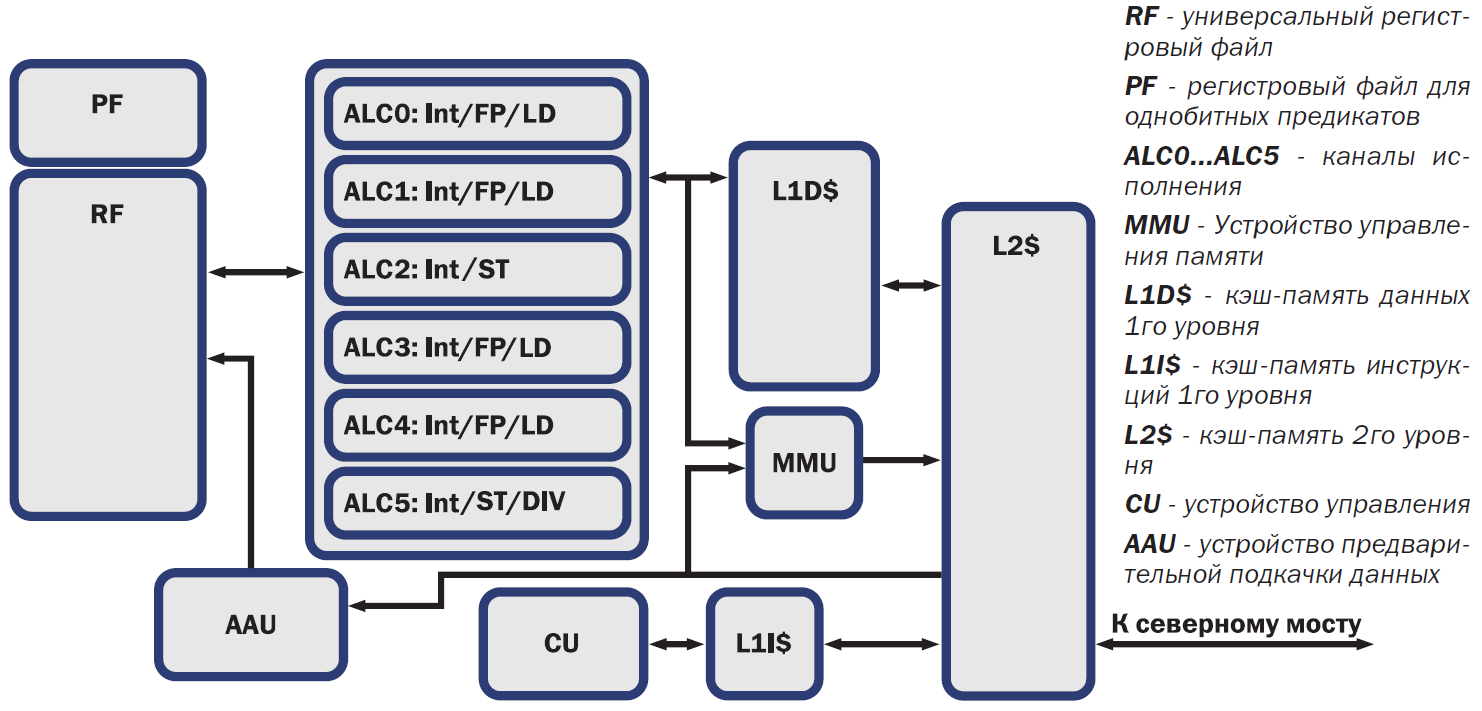
В центральной части видно ALC c номерами это такие конвейеры параллельные и у каждого подписаны какие типы типы операций могут быть. В ассемблере это выглядит примерно так (тут две широкие команды типа):
Но это естественно не так все просто, там очень много нюансов которые надо изучить — четыре загрузки можно только короткие слова, ldd тобишь двойные только два вроде. Деление только в 5 канале, но это на диаграме выше видно. Сравнение в 0 и вот этого на диаграме нет как и много чего еще. В любом случае в каналах как я понимаю только операции связанные с вычислениями ну и с ld/st, то есть это далеко не вся структура ШК еще. У вас в документации наверняка написано намного больше.
Сразу оговорюсь что я не системный программист и не специалист, могу чего то недопонимать:
пример программы на ассемблере эльбруса
Эльбрус процессор с регистровыми окнами, входя в процедуру он задает окно регистров:
регистров по которым у него ездит окно — 192
плюс еще есть 32 глобальных регистра и 32 регистра с однобитными значениями
у него есть три дополнительных конвеера и три регистра передачи управления (ctpr1,2,3):
Перед тем как куда то прыгнуть, надо задолго до перехода назначить грузить код в один из параллельный конвееров
что бы потом прыгнуть без задержек
после запятой это я так понимаю количество регистров текущего окна которое будет доступно со всеми их значениями в следующей процедуре. Когда он перейдет окно сдвинется вперед что бы сохранить контекст текущей процедуры, там посчитает, вернется окно сдвинется назад на исходную.
ретерн осуществляется аналогично -
положили адрес возврата
вышлипередали управлениеТо есть где какие тут должны быть переключения контекстов я не очень понимаю.
А, тогда извини. Ну там это "работающее решение" каждый год поддержку требует во первых (см. видео внизу), во вторых его не выкидывают на свалку же. В статье синьюз 2016г писалось что айбиэмку куда то в более нагруженное место встроить собирались.