YTsaurus SPYT: как мы перешли от форка Apache Spark к использованию оригинальной версии

Всем привет! Меня зовут Александр Токарев, я работаю в Yandex Infrastructure и занимаюсь интеграцией Apache Spark (далее просто Spark) с YTsaurus. В этой статье я расскажу про то, как мы сначала форкнули и пропатчили Spark, а потом вернулись к использованию оригинальной версии и поддержали совместимость с множеством других версий.
YTsaurus — это разработанная Яндексом система для хранения и обработки больших объёмов данных. Она активно развивается с 2010 года, а в 2023 году была выложена в опенсорс. Подробнее почитать про историю создания и выход YTsaurus в опенсорс можно в статье Максима Бабенко.
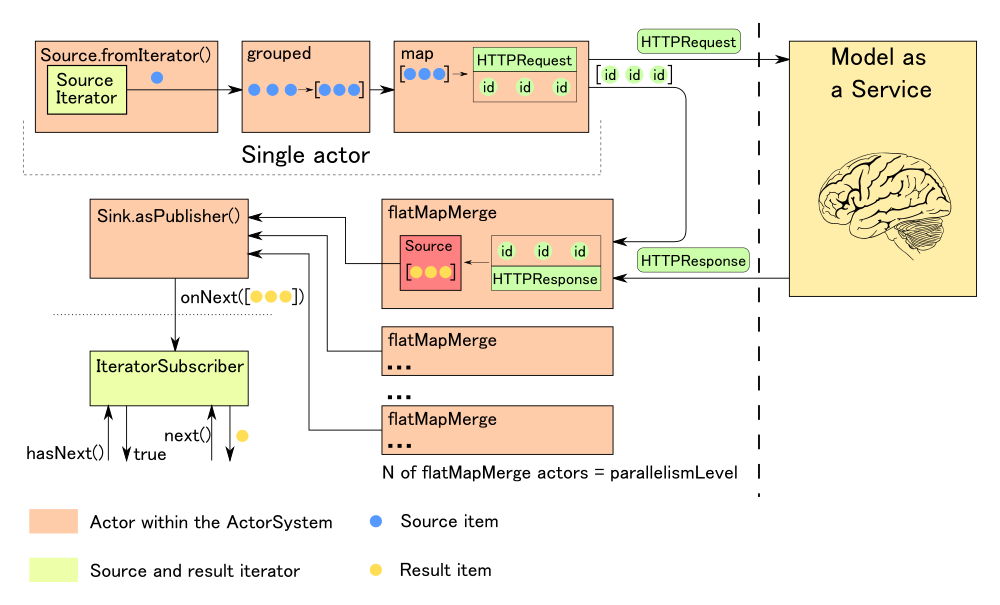
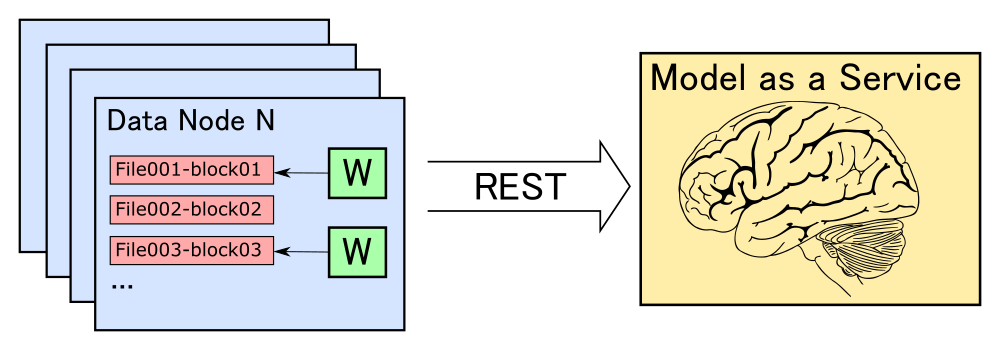
В какой‑то момент мы решили подружить YTsaurus и Spark. Так и родился проект SPYT powered by Apache Spark (далее просто SPYT), который активно развивается с 2019 года. Основательница проекта Саша Белоусова уже рассказывала, как были реализованы SPI Spark для работы со структурами данных YTsaurus — это набор классов, интерфейсов, методов, которые мы расширяем или реализуем. Во многом эта статья и моё выступление на HighLoad++ 2024 являются продолжением её доклада.