Не понял про версии тестов. Я про то, что тесты лежат совсем отдельно от основного кода, в отдельном проекте. Стек .NET.
Почему отсутствие документации на код сразу делает его говнокодом? Слишком сильное утверждение.
Мы вот, например, стараемся писать самодокументируемый код. Вполне себе не говнокод получается, но отдельного файла с документацией рядом с кодом нет.
Да и вообще я такого никогда не видел.
Спасибо, но не надо.
При разбиении по принципу per layer проще контролировать сохранность архитектуры – репозитории (DAL-уровень) находятся в своём проекте, сервисы (BLL) – в своём, контроллеры (PL) – в своём. Отсутствие протечек можно контролировать на код-ревью (например, через namespaces), можно и архитектурные тесты написать (ищите выступления Дениса Цветциха).
Если файлы из разных архитектурных слоёв будут свалены в одну папку, то уровни не то что протекут – всё просто хлынет. Гарантировано.
А вот в рамках одного уровня (например, бизнес-логики) можно и по принципу per feature всё складывать, здесь проблем не вижу.
Забавно – как раз сейчас читаю предыдущую инкарнацию этой книги (Прайс — C# 7 и .NET Core. Кросс-платформенная разработка для профессионалов) и как раз сегодня с утра читал эту главу =D.
Бывают же совпадения )))
Брокер сообщений выглядит как узкое место системы. Если генераторов и потребителей событий может быть сколько угодно и их можно масштабировать, то общаются они все через одного брокера. Мало того, брокер может и упасть, что приведёт к полной остановке системы.
Или есть варианты с пулом брокеров?
Создаётся впечатление, что Вы не увидели сути в публикации и критикуете инструмент по визуализации диаграмм баз данных
Я даже не знаю, каким Вы инструментом пользовались, и в данном контексте это вообще не важно.
Услыште меня, я уже устал повторять одно и тоже — Вы неправильно используете нотацию crow foot, в тексте у Вас связь обозначена как обязательная, а на схеме — как необязательная. И эта ошибка повторена неоднократно.
И это может сбить с толку неопытных читателей Вашей статьи (джунов, студентов и т.п.), только поэтому я за этот момент и зацепился. Детей жалко :)
А Вы можете сколько угодно оставаться в мире своих заблуждений. Я бы порекомендовал Вам поразбираться с этой нотацией, но что-то мне подсказывает, что Вы этого делать не захотите.
За сим всё-таки окончательно откланиваюсь, ничего конструктивного Вы так и не сказали (но за SSMS отдельное спасибо, хорошее настроение у меня на весь день обеспечено :)).
Вау, Вы меня впечатлили! )))))
Я, вообще-то, говорил о нотации crow foot (которую Вы использовали в статье).
А то, что SSMS использует какую-то свою, совсем другую — это все знают. Ну, или не все… =D
Не хочу задеть, но у меня сложилось впечатление, что Вы теоретик и оперируете академическими понятиями из ВУЗа, где так много уделялось видам стрелок с кружком и без.
Ошибаетесь, я — практик. И если уж мы тут начали пиписками меряться, то моя нынешняя должность называется "Эксперт по разработке". (А вообще Ваша тирада выглядит странно — наличие большого опыта исключает возможность делать ошибки или заблуждаться?)
И как практик я знаю, что всевозможные схемы (в т.ч. различные схемы БД) служат, в первую очередь, для передачи знаний между членами команды. И если Вы в голове держите "1 или N", а на схеме нарисовали "0 или N", то другой разработчик при имплементации какой вариант реализует, как думаете?
Если Вы мне советуете это почитать, то зря — я как раз-таки понимаю разницу между концептуальной, логической и физической моделями базы данных.
И не могут при переходе между уровнями модели внезапно изменяться свойства связи — мощность, обязательность и т.д.
Поэтому если Вы на концептуальном уровне указали, что на данном конце связи должно быть "ноль или один" — в таком виде это у Вас и доедет до физической модели.
Так что тут Вы опять ошиблись.
И всё равно всё вышесказанное Вами не отменяет того факта, что у Вас в статье схемы не соответствуют тексту. Заканчивайте уже выискивать какие-то странные оправдания в виде размытых фраз.
На всякий случай подытожу — вдруг в будущем эту статью будут читать студенты, надо их предостеречь :) — и больше уже возвращаться не буду.
В нотации crow foot значки и имеют разный смысл, так же, как и и , и в статье много неверных схем в том смысле, что они не соответствуют тексту, например, в тексте речь идёт про обязательность, а на схеме этот конец связи с "ноликом".
В зависимости от потребностей можно выбирать один из правильных вариантов, например, при связи "1:1" хранить всё в одной таблице или в двух связанных.
Какие потребности могут заставить выбрать неправильный вариант, я не представляю.

Вообще-то американский MM-DD-YYYY, Ваш пример выглядит в нём как "12-24-2020". А это формат ISO-8601.
Всплакнул...
Мы вот, например, стараемся писать самодокументируемый код. Вполне себе не говнокод получается, но отдельного файла с документацией рядом с кодом нет.
Да и вообще я такого никогда не видел.
Спасибо, но не надо.
При разбиении по принципу per layer проще контролировать сохранность архитектуры – репозитории (DAL-уровень) находятся в своём проекте, сервисы (BLL) – в своём, контроллеры (PL) – в своём. Отсутствие протечек можно контролировать на код-ревью (например, через namespaces), можно и архитектурные тесты написать (ищите выступления Дениса Цветциха).
Если файлы из разных архитектурных слоёв будут свалены в одну папку, то уровни не то что протекут – всё просто хлынет. Гарантировано.
А вот в рамках одного уровня (например, бизнес-логики) можно и по принципу per feature всё складывать, здесь проблем не вижу.
Будет, ибо:
Хаб "ASP" видимо по ошибке указан.
Будет ли совместима по расширениям с VS2019? Или опять полгода ждать, пока авторы расширений перепишут их под новую студию?
Забавно – как раз сейчас читаю предыдущую инкарнацию этой книги (Прайс — C# 7 и .NET Core. Кросс-платформенная разработка для профессионалов) и как раз сегодня с утра читал эту главу =D.
Бывают же совпадения )))
И всё таки "стандартный текст" бьёт по глазам. По смыслу очень далеко от "текста стандарта".
Брокер сообщений выглядит как узкое место системы. Если генераторов и потребителей событий может быть сколько угодно и их можно масштабировать, то общаются они все через одного брокера. Мало того, брокер может и упасть, что приведёт к полной остановке системы.
Или есть варианты с пулом брокеров?
Понятно, спасибо.
Скажите, пожалуйста, а как вы замеряете Line Coverage только для нового кода?
Я даже не знаю, каким Вы инструментом пользовались, и в данном контексте это вообще не важно.
Услыште меня, я уже устал повторять одно и тоже — Вы неправильно используете нотацию crow foot, в тексте у Вас связь обозначена как обязательная, а на схеме — как необязательная. И эта ошибка повторена неоднократно.
И это может сбить с толку неопытных читателей Вашей статьи (джунов, студентов и т.п.), только поэтому я за этот момент и зацепился. Детей жалко :)
А Вы можете сколько угодно оставаться в мире своих заблуждений. Я бы порекомендовал Вам поразбираться с этой нотацией, но что-то мне подсказывает, что Вы этого делать не захотите.
За сим всё-таки окончательно откланиваюсь, ничего конструктивного Вы так и не сказали (но за SSMS отдельное спасибо, хорошее настроение у меня на весь день обеспечено :)).
Вау, Вы меня впечатлили! )))))
Я, вообще-то, говорил о нотации crow foot (которую Вы использовали в статье).
А то, что SSMS использует какую-то свою, совсем другую — это все знают. Ну, или не все… =D
Ошибаетесь, я — практик. И если уж мы тут начали пиписками меряться, то моя нынешняя должность называется "Эксперт по разработке". (А вообще Ваша тирада выглядит странно — наличие большого опыта исключает возможность делать ошибки или заблуждаться?)
И как практик я знаю, что всевозможные схемы (в т.ч. различные схемы БД) служат, в первую очередь, для передачи знаний между членами команды. И если Вы в голове держите "1 или N", а на схеме нарисовали "0 или N", то другой разработчик при имплементации какой вариант реализует, как думаете?
Если Вы мне советуете это почитать, то зря — я как раз-таки понимаю разницу между концептуальной, логической и физической моделями базы данных.
И не могут при переходе между уровнями модели внезапно изменяться свойства связи — мощность, обязательность и т.д.
Поэтому если Вы на концептуальном уровне указали, что на данном конце связи должно быть "ноль или один" — в таком виде это у Вас и доедет до физической модели.
Так что тут Вы опять ошиблись.
И всё равно всё вышесказанное Вами не отменяет того факта, что у Вас в статье схемы не соответствуют тексту. Заканчивайте уже выискивать какие-то странные оправдания в виде размытых фраз.
На всякий случай подытожу — вдруг в будущем эту статью будут читать студенты, надо их предостеречь :) — и больше уже возвращаться не буду. и
и  имеют разный смысл, так же, как и
имеют разный смысл, так же, как и  и
и  , и в статье много неверных схем в том смысле, что они не соответствуют тексту, например, в тексте речь идёт про обязательность, а на схеме этот конец связи с "ноликом".
, и в статье много неверных схем в том смысле, что они не соответствуют тексту, например, в тексте речь идёт про обязательность, а на схеме этот конец связи с "ноликом".
В нотации crow foot значки
В том-то и дело, что у Вас схема 2.1.2 выглядит так:
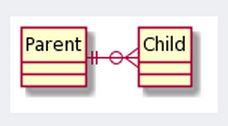
Именно это я и пытаюсь до Вас донести.
В зависимости от потребностей можно выбирать один из правильных вариантов, например, при связи "1:1" хранить всё в одной таблице или в двух связанных.
Какие потребности могут заставить выбрать неправильный вариант, я не представляю.
Не совсем понимаю, как проблема с несобираемыми данными связана с неправильной в данном конкретно случае структурой БД.