ML и консенсус между людьми: берём от обоих подходов лучшее
5 мин
Перевод

Введение в категоризацию классификаций
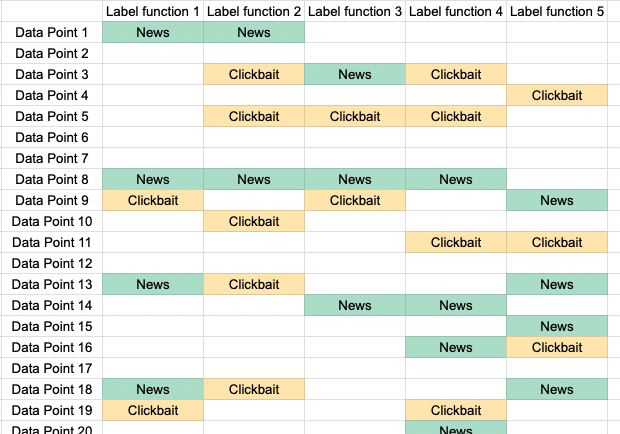
У вас были когда-нибудь проблемы с поиском товара в продуктовом магазине? Например, вы могли искать замороженный картофель фри в отделе замороженных завтраков, но на самом деле он находился в отделе замороженных овощей. Или вы искали соевый соус в отделе азиатской еды, а он находился в отделе приправ.
Одна из самых больших трудностей для розничных магазинов и торговых площадок — создание каталога путём категоризации миллионов продуктов в сложную систему из тысяч категорий, также называемых классификациями (taxonomies). В реальных магазинах подробная категоризация нужна для логичного упорядочивания стеллажей. В эпоху электронной коммерции и цифровых торговых площадок правильная категоризация обеспечивает множество преимуществ, в том числе улучшенные поисковые рекомендации, более подходящие предложения товаров на замену, а также более строгое соблюдение региональных и федеральных требований.
Категоризация классификаций сложна не только из-за существования в мире бесчисленного количества продуктов, образующих глубоко вложенные иерархические категории, но и из-за постоянно меняющейся природы классификаций. Невозможно найти одного специалиста в предметной области, понимающего весь каталог достаточно хорошо для того, чтобы категоризировать каждый отдельный товар, а процесс обучения команды специалистов недостаточно быстр и масштабируем по современным стандартам. Более того, входные данные никогда не идеальны, и из-за отсутствия информации иногда невозможно понять, относится ли продукт к конкретной классификации.