Понятно что в зависимости от проекта такой подход может быть как хорош так и не очень, но вот что будет незыблемо: автор этого проекта будет в катарсисе, а новые люди приходящие на проект, будут считать все это чумой поглотившей проект
Для меня основной выигрыш от ORM в том ,что она избавляет от надобности писать маппинги сущностей кода в сущности базы. А билдеры запросов это уже приятное дополнение. Или не очень приятное, как например в питоновском django)
а почему там требовалось создавать в разных местах экземпляры?
Да вот и я тем же вопросом был озадачен.
вручную sql для миграций выглядит как костыль
А почему как костыль, вроде самый наглядный и контроллируемый вариант. Там же не нужна универсальность, вряд ли понадобится менять СУБД и переносить весь проект на новую БД. Atlas как то страшновато использовать. Обновишь этот пакет и мало ли чего он решит добавить в табличку весом с половину диска.
У нас тоже была интересная история. Пришел парень, причем тоже пару лет назад, может один и тот же (шутка)? И сказал что наш DI - полное Г, что на го так не пишут. И сервисы слоеные наши тоже какое то Г, что так не надо делать, что это "не go-way". А я люблю дать свободу человеку, когда он идеи толкает. Ни у говорю - ок, сделай кусок кода под свою задачку как считаешь нужным. Может и вправду будет лучше и мы тогда возьмем это и намотаем себе на ус.
Он интересно в итоге сделал: накопировал в несколько мест создание экземпляров вместо того чтобы 1 раз описать в DI. А данные из БД прямо в мапки грузил. Вот тут я и вспомнил с ностальгической слезой PHP4 и мы с ним на этом распрощались.
А вы про пхп говорите будто бы в негативном контексте. А язык между тем довольно хороший. И объектная модель там хорошая, и код там можно писать наглядно и аккуратно. Про пхп плохо говорят от того что много разработчиков писали лука-код. Да и объекты там не сразу появились. Но сейчас это один из удобных языков. Если бы не производительность, то вообще был бы огонь-язык.
Когда надо протестировать более менее крупный кусок логики, который использует несколько источников для данных, то уже неудобно, надо мокать несколько вещей. А если данные запрашиваются несколько раз за вызов, то надо еще и в правильном порядке подсовывать нужные данные. Это еще неудобнее. Если в процессе делаются и сохранения и выборки на основе сохраненного, то по тестам это тоже усложнение. А если в код, который покрыт такими тестами, вносятся изменения, например, добавляется запрос данных из нового источника, то и тест приходится ворошить. А он уже навороченный. И править тест уже прилично сложнее чем основной код, получается что на задачку тратим 1 час, и на тест еще 4. И при этом код который пишет/читает из базы сам по себе не особо сложный, там мало где ошибиться можно. Поэтому на мой взгляд проще отделять код который выполняет какие то сложные вычисления (получает уже выбранные из БД данные, обрабатывает их, и возвращает результат), и покрывать тестами его.
А чтобы логгер влиял на скорость, лично я такого ни разу и не замечал. Дело в том, что библиотеки логгеров бывает сравнивают себя с другими библиотеками и в сравнении делают упор на скорость работы. Зачем это делают - мне правда не понятно. Логов либо пишешь относительно мало чтобы визуально было легко разобрать что к чему, либо складываешь их в какое-то хранилище чтобы потом в нем можно было искать нужное. Но узким местом тогда уже становится не логгер, а запись в хранилище. Да и если 1M записей в минуту в stdout пишется без проблем, не создавая значительную нагрузку на процессор или память, то вопрос скорости тут и не должен подниматься на мой взгляд.
Да, явный вполне хороший вариант. А я уже как-то сдружился с IoC и не хочется менять подход, плюс спокойней когда знаешь что при надобности можно все же легко подменить серисы. Проблем с ним на практике не возникает.
Да просто удобный интерфейс для настройки, логирования, и по умолчанию удобный вывод сообщений. А других требований к логгеру особо и не предъявляю.
Паники не будет. Но ShouldBindQuery() возвращает ошибки. Так что да, тут надо обрабатывать, я пожалуй допишу в этом примере попозже.
Если что, то я отказываться от репозиториев не призываю, в 90% моих проектах есть этот слой. Если проект потенциально планируется большой, то на мой взгляд лучше перестраховаться и оставить репозитории. А для проектов поменьше вполне нормально обойтись и без него. Оба решения на моей личной практике не играют большой роли в скорости разработки и ни один подход не дает других значительных преимуществ. Просто немного удобнее когда код более компактный.
На днях этот же плагин опробовал. С ним у меня получается сгенерировать небольшие полезные кусочки кода по 5-10 строк. Это конечно тоже довольно хорошо. Но вот не получилось пока добиться чтобы этот интеллект создавал файлили по аналогии с другими, но для новых сущностей. Интересно, есть что-то для таких запросов?
Удалось попробовать TimescaleDB на ZFS с LZ4. Проблем не замечено, все примерно как и без ZFS, только экономнее диск используется. А встроенное сжатие от TimesacleDB не подошло из-за чрезмерной загрузки процессора при частом чтении.
Мне такое не известно. Но как вариант можно попробовать сгенерировать docx и его через апи импортировать в гугл док. Если вдруг будете так делать, будет инетересно узнать, получается ли так.
Интересный проект. Мне он не попадался. Похож на легаси, но все равно удивительно что за столько лет проект не набрал популярность сравнимую с phpoffice при такой функциональности.

Вы настоящий оракул!
Ох, это не просто. Как это делаете?
Да, вот минималистичный пример чтения, тут горм заботится о том чтобы поля базы мапились на поля струкруты.
Понятно что в зависимости от проекта такой подход может быть как хорош так и не очень, но вот что будет незыблемо: автор этого проекта будет в катарсисе, а новые люди приходящие на проект, будут считать все это чумой поглотившей проект
Для меня основной выигрыш от ORM в том ,что она избавляет от надобности писать маппинги сущностей кода в сущности базы. А билдеры запросов это уже приятное дополнение. Или не очень приятное, как например в питоновском django)
Да вот и я тем же вопросом был озадачен.
А почему как костыль, вроде самый наглядный и контроллируемый вариант. Там же не нужна универсальность, вряд ли понадобится менять СУБД и переносить весь проект на новую БД. Atlas как то страшновато использовать. Обновишь этот пакет и мало ли чего он решит добавить в табличку весом с половину диска.
У нас тоже была интересная история. Пришел парень, причем тоже пару лет назад, может один и тот же (шутка)? И сказал что наш DI - полное Г, что на го так не пишут. И сервисы слоеные наши тоже какое то Г, что так не надо делать, что это "не go-way". А я люблю дать свободу человеку, когда он идеи толкает. Ни у говорю - ок, сделай кусок кода под свою задачку как считаешь нужным. Может и вправду будет лучше и мы тогда возьмем это и намотаем себе на ус.
Он интересно в итоге сделал: накопировал в несколько мест создание экземпляров вместо того чтобы 1 раз описать в DI. А данные из БД прямо в мапки грузил. Вот тут я и вспомнил с ностальгической слезой PHP4 и мы с ним на этом распрощались.
А вы про пхп говорите будто бы в негативном контексте. А язык между тем довольно хороший. И объектная модель там хорошая, и код там можно писать наглядно и аккуратно. Про пхп плохо говорят от того что много разработчиков писали лука-код. Да и объекты там не сразу появились. Но сейчас это один из удобных языков. Если бы не производительность, то вообще был бы огонь-язык.
Когда надо протестировать более менее крупный кусок логики, который использует несколько источников для данных, то уже неудобно, надо мокать несколько вещей. А если данные запрашиваются несколько раз за вызов, то надо еще и в правильном порядке подсовывать нужные данные. Это еще неудобнее. Если в процессе делаются и сохранения и выборки на основе сохраненного, то по тестам это тоже усложнение. А если в код, который покрыт такими тестами, вносятся изменения, например, добавляется запрос данных из нового источника, то и тест приходится ворошить. А он уже навороченный. И править тест уже прилично сложнее чем основной код, получается что на задачку тратим 1 час, и на тест еще 4. И при этом код который пишет/читает из базы сам по себе не особо сложный, там мало где ошибиться можно. Поэтому на мой взгляд проще отделять код который выполняет какие то сложные вычисления (получает уже выбранные из БД данные, обрабатывает их, и возвращает результат), и покрывать тестами его.
А чтобы логгер влиял на скорость, лично я такого ни разу и не замечал. Дело в том, что библиотеки логгеров бывает сравнивают себя с другими библиотеками и в сравнении делают упор на скорость работы. Зачем это делают - мне правда не понятно. Логов либо пишешь относительно мало чтобы визуально было легко разобрать что к чему, либо складываешь их в какое-то хранилище чтобы потом в нем можно было искать нужное. Но узким местом тогда уже становится не логгер, а запись в хранилище.
Да и если 1M записей в минуту в stdout пишется без проблем, не создавая значительную нагрузку на процессор или память, то вопрос скорости тут и не должен подниматься на мой взгляд.
Да, явный вполне хороший вариант. А я уже как-то сдружился с IoC и не хочется менять подход, плюс спокойней когда знаешь что при надобности можно все же легко подменить серисы. Проблем с ним на практике не возникает.
Да просто удобный интерфейс для настройки, логирования, и по умолчанию удобный вывод сообщений. А других требований к логгеру особо и не предъявляю.
Паники не будет. Но
ShouldBindQuery()возвращает ошибки. Так что да, тут надо обрабатывать, я пожалуй допишу в этом примере попозже.Да, лучше наверх прокинуть.
Если что, то я отказываться от репозиториев не призываю, в 90% моих проектах есть этот слой. Если проект потенциально планируется большой, то на мой взгляд лучше перестраховаться и оставить репозитории. А для проектов поменьше вполне нормально обойтись и без него. Оба решения на моей личной практике не играют большой роли в скорости разработки и ни один подход не дает других значительных преимуществ. Просто немного удобнее когда код более компактный.
На днях этот же плагин опробовал. С ним у меня получается сгенерировать небольшие полезные кусочки кода по 5-10 строк. Это конечно тоже довольно хорошо. Но вот не получилось пока добиться чтобы этот интеллект создавал файлили по аналогии с другими, но для новых сущностей. Интересно, есть что-то для таких запросов?
Известно ли сколько часов работает этот ноут на аккумуляторе?
Удалось попробовать TimescaleDB на ZFS с LZ4. Проблем не замечено, все примерно как и без ZFS, только экономнее диск используется. А встроенное сжатие от TimesacleDB не подошло из-за чрезмерной загрузки процессора при частом чтении.
Про название: https://golang.org/doc/faq#go_or_golang
Про поиск:
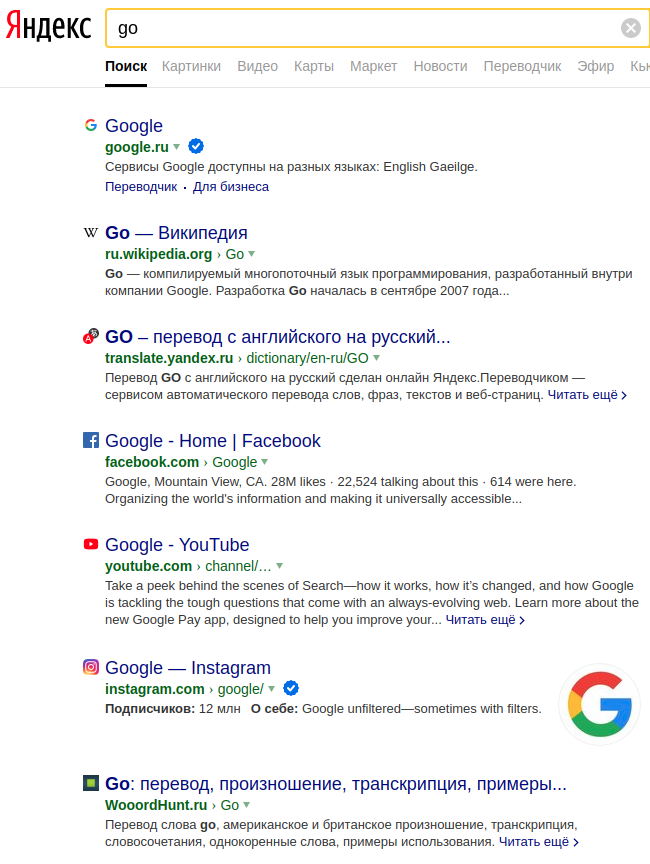
Вот ещё несколько источников:
Согласен
Мне такое не известно. Но как вариант можно попробовать сгенерировать docx и его через апи импортировать в гугл док. Если вдруг будете так делать, будет инетересно узнать, получается ли так.
Интересный проект. Мне он не попадался. Похож на легаси, но все равно удивительно что за столько лет проект не набрал популярность сравнимую с phpoffice при такой функциональности.
Спасибо, добавил все варианты названий, которые только нашел)