
Чтобы выбрать ТОП 30 (только 0,3%), за прошедший год команда Mybridge сравнила почти 8800 проектов по машинному обучению с открытым исходным кодом.
Это чрезвычайно конкурентный список, и он содержит лучшие библиотеки с открытым исходным кодом для машинного обучения, наборы данных и приложения, опубликованные в период с января по декабрь 2017 года. Чтобы дать вам представление о качестве проектов, отметим, что среднее число звезд Github — 3558.
Проекты с открытым исходным кодом могут быть полезны не только ученым. Вы можете добавить что-то удивительное поверх ваших существующих проектов. Ознакомьтесь с проектами, которые вы, возможно, пропустили в прошлом году.

Осторожно, под катом много картинок и gif.
1. FastText
fastText – это библиотека для обучения представлениям слов и классификации предложений, позволяющая организовать автоматическое назначение категорий для произвольного текста с использованием методов машинного обучения. [11786 stars on Github]. Любезно предоставлено Facebook Research.

[ Muse: Multilingual Unsupervised or Supervised word Embeddings, на базе Fast Text. 695 stars on Github]

2. Deep Photo Style Transfer
Код и данные для научной работы Deep Photo Style Transfer [9747 stars on Github]. Описан подход к передаче фотографического стиля с одного изображения на другие с успешным подавлением искажения и сохранением фотореалистичности в самых разных сценариях, включая передачу особенностей времени суток, погоды, сезона и художественных изменений. Заслуга Fujun Luan, Ph.D. at Cornell University.

3. Face Recognition
«Самый простой в мире» API для распознавания лиц для Python. Модель имеет точность 99,38% в бенчмарке Labeled Faces in the Wild. Также предлагается простой инструмент, который позволяет распознавать лица с изображений в папке с помощью командной строки. Разработчик — Adam Geitgey [8672 stars on Github].

4. Magenta
Генерация искусства и музыки с помощью машинного обучения [8113 stars on Github].
5. Sonnet
Sonnet — это библиотека для машинного обучения, основанная на TensorFlow для построения сложных нейронных сетей. [5731 звезда на Github]. Предоставлено Malcolm Reynolds из Deepmind

6. deeplearn.js
deeplearn.js — это WebGL-accelerated JavaScript библиотека для машинного обучения с открытым исходным кодом от Nikhil Thorat из Google Brain.

7. Fast Style Transfer in TensorFlow
Быстрая передача стиля с помощью TensorFlow [4843 звезды на Github]. Logan Engstrom из MIT.

Добавьте стили известных художников на любую фотографию за долю секунды! Вы даже можете создавать видеоролики.
8. Pysc2: StarCraft II Learning Environment [3683 stars on Github], предоставлено Timo Ewalds из DeepMind

9. AirSim
AirSim — это симулятор для беспилотных летательных аппаратов, автомобилей и прочих транспортных средств, созданных на Unreal Engine. Это платформа с открытым исходным кодом для физически и визуально реалистичных симуляций. Цель — разработать платформу для исследований ИИ и экспериментов с алгоритмами глубокого обучения, компьютерного зрения и стимулированного обучения систем автономных транспортных средств. [3861 stars on Github]. Разработчик — Shital Shah из Microsoft
10. Facets
Сила машинного обучения связана с его способностью изучать закономерности в больших объемах данных. Понимание ваших данных имеет решающее значение для создания мощной системы машинного обучения. Проект Facets предлагает два надежных типа визуализации, которые помогают понять и проанализировать наборы данных: Facets Overview и Facets Dive.
Визуализация легко встраивается в отчеты Jupyter notebooks или веб-страницы (Polymer web components, backed by Typescript code).
[3371 stars on Github]. Courtesy of Google Brain
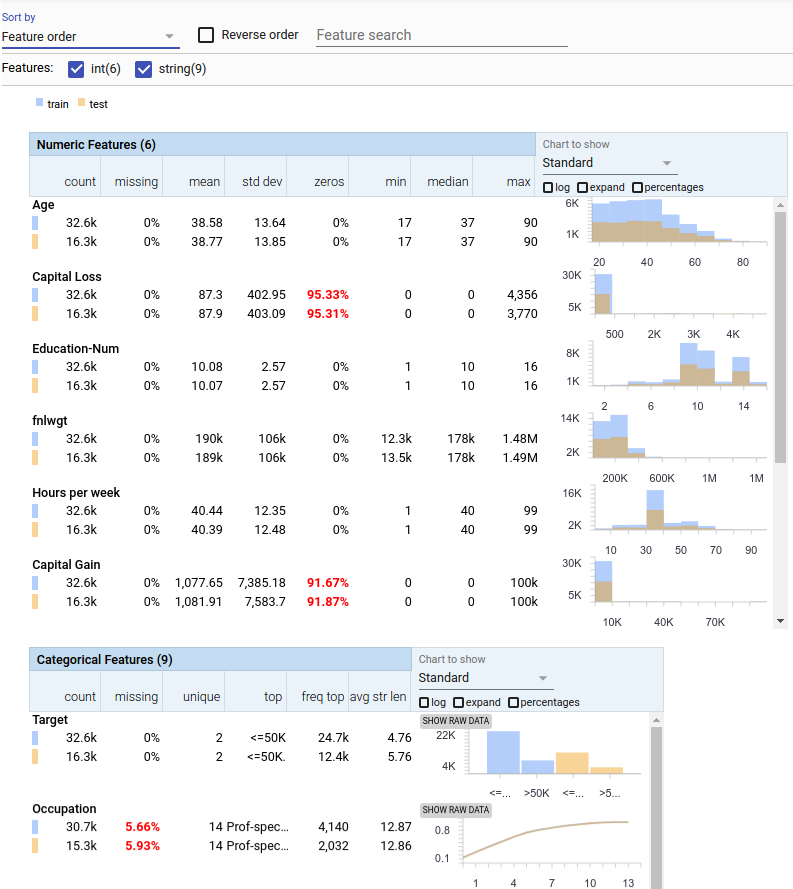
Пример отчета FACETS OVERVIEW
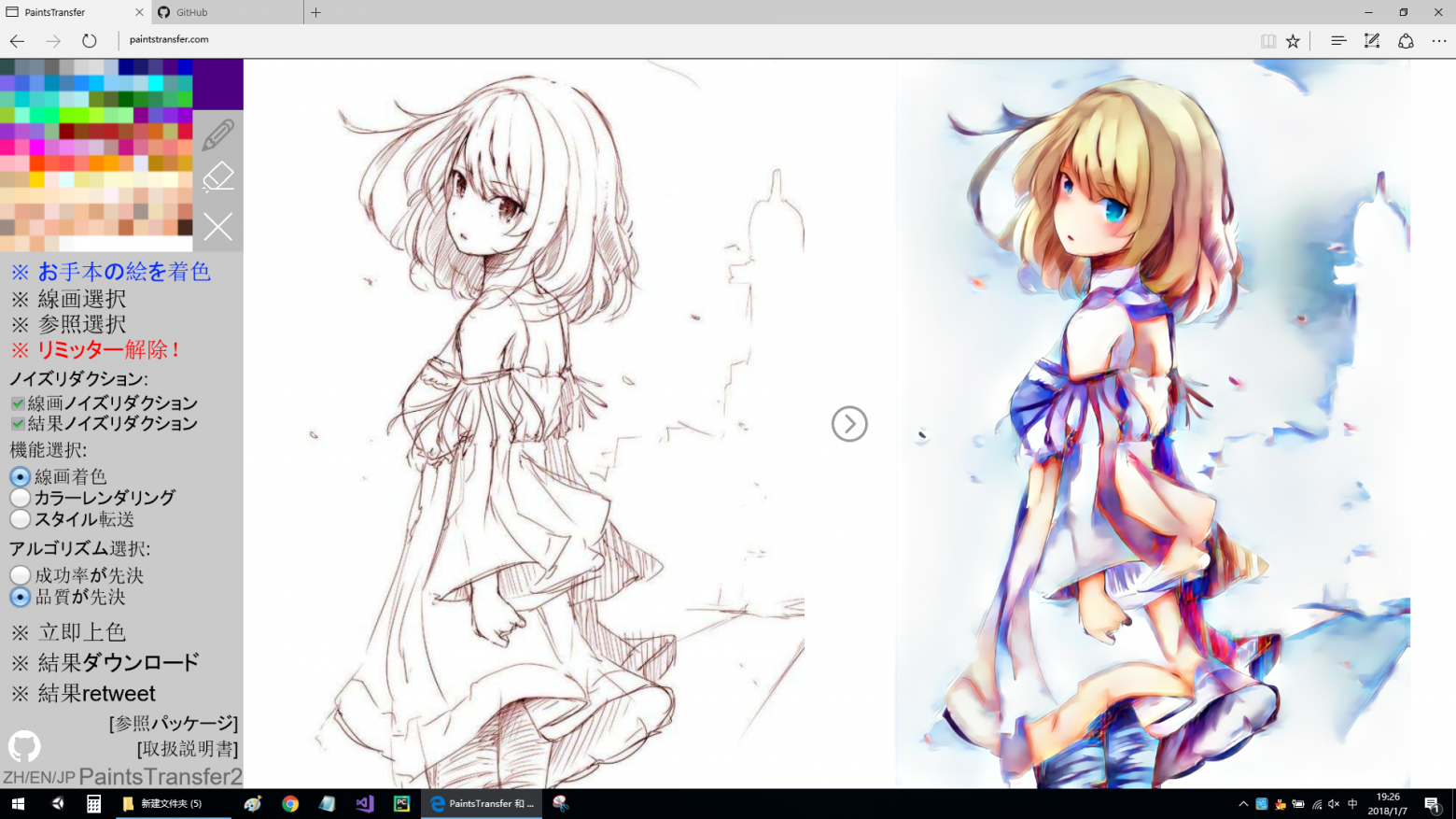
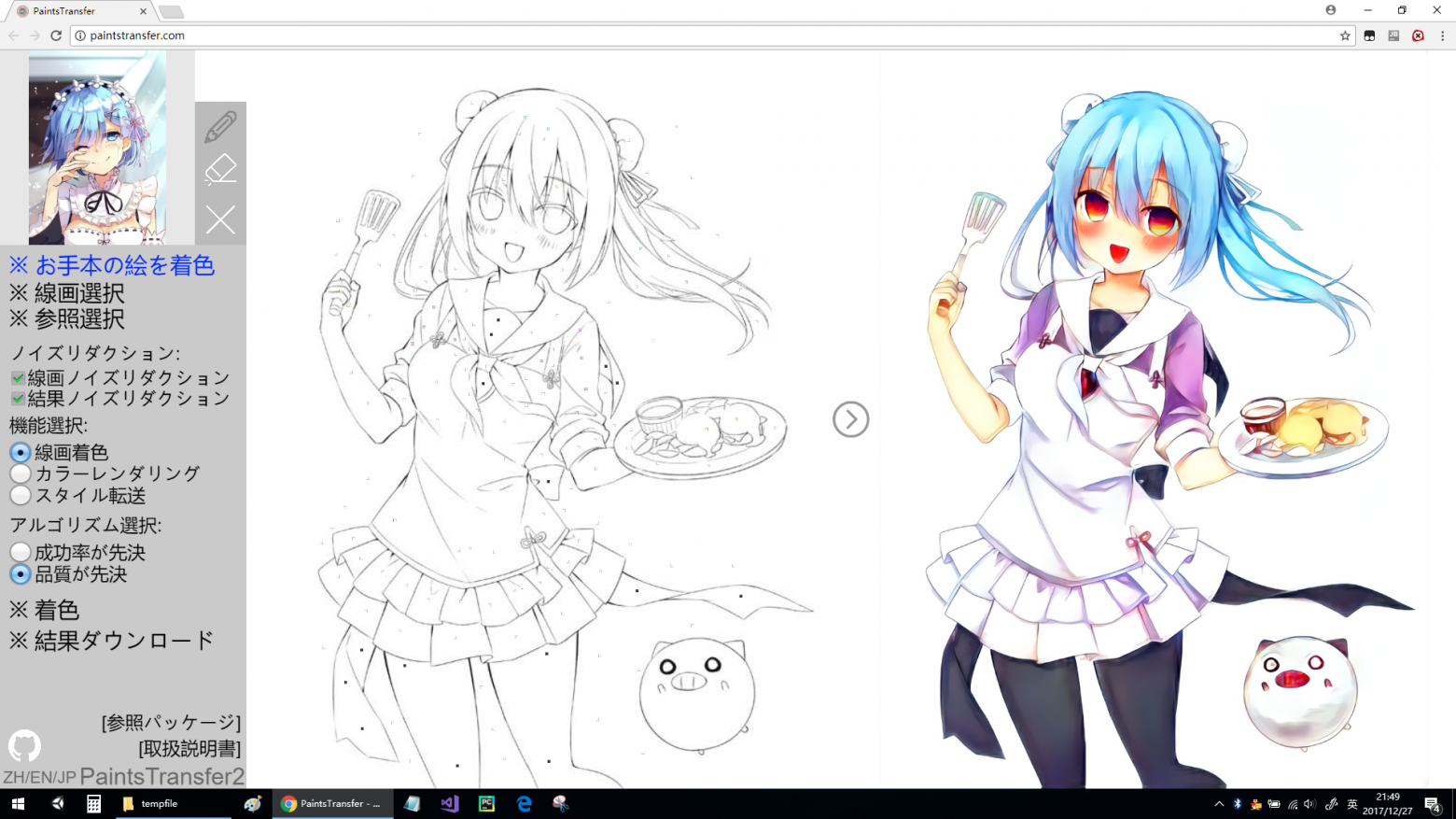
11. Style2Paints
AI-раскраска изображений [3310 stars on Github], может раскрасить в соответствии с конкретным цветовым стилем, создать свой собственный стиль для рисования или передать стиль иллюстрации-примера.

12. Tensor2Tensor
Авторы научной работы «Одна модель для обучения всему» из группы Google Brain Team задались естественным вопросом: «Можем ли мы создать унифицированную модель глубинного обучения, которая будет решать задачи из разных областей?»
Google сделала это — и открыла Tensor2Tensor для всеобщего пользования, код опубликован на GitHub. [3087 stars on Github.
В научной статье они описывают архитектуру MultiModel — единой универсальной модели глубинного обучения, которая может одновременно обучаться задачам из разных доменов.
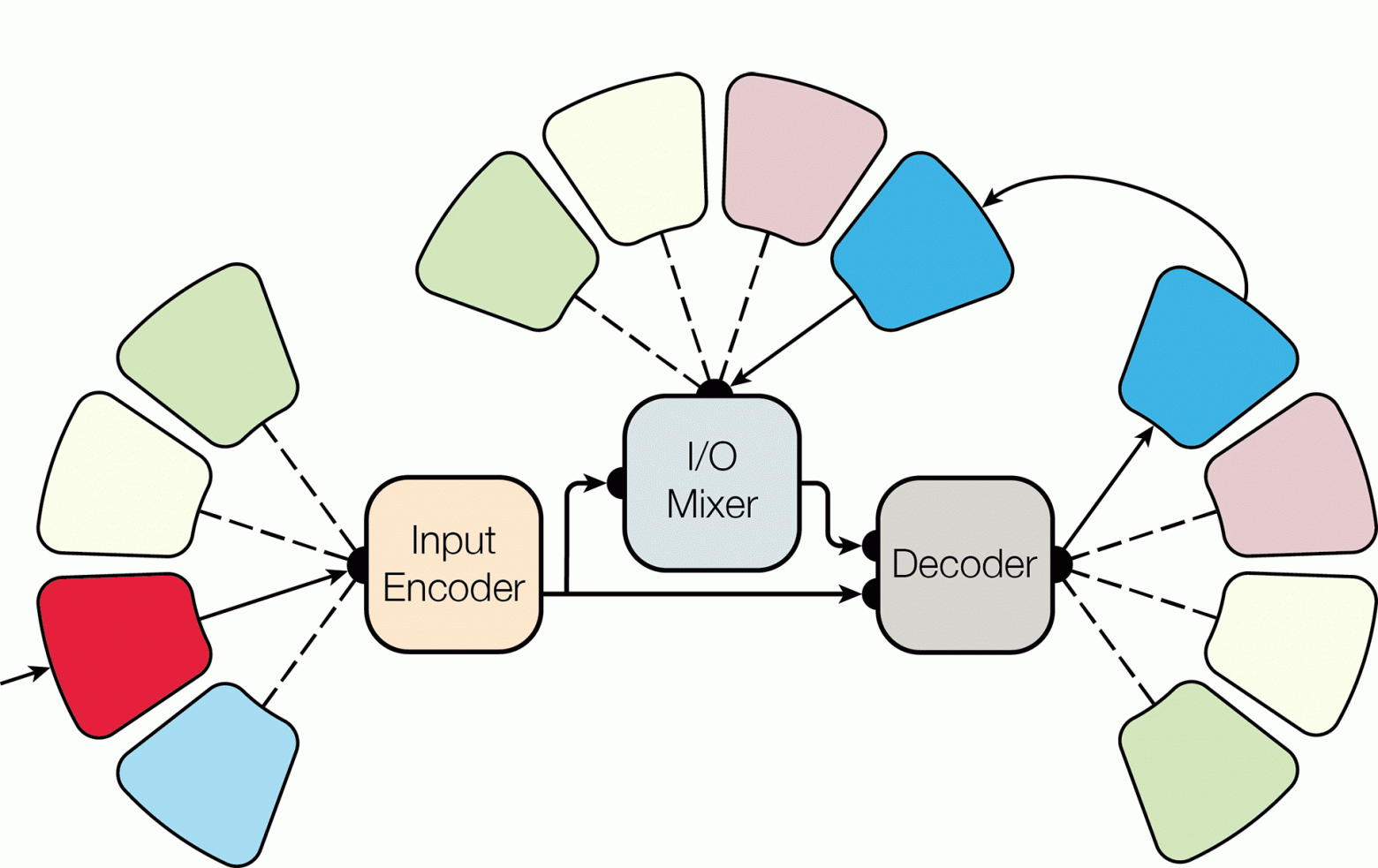
Архитектура MultiModel
В частности, исследователи для проверки обучали MultiModel одновременно на восьми наборах данных:
- Корпус распознавания речи WSJ
- База изображений ImageNet
- База обычных объектов в контексте COCO
- База парсинга WSJ
- Корпус перевода с английского на немецкий язык
- Обратное предыдущему: корпус перевода с немецкого на английский язык
- Корпус перевода с английского на французский язык
- Обратное предыдущему: корпус перевода с французского на английский язык
Подробнее тут.
13. Image-to-image translation in PyTorch (например, horse2zebra, edges2cats и так далее)
[2847 stars on Github]. Любезно предоставлено Jun-Yan Zhu, Ph.D at Berkeley

14. Faiss
Faiss — это библиотека для эффективного поиска подобия и кластеризации векторов [2629 stars on Github]. Довольно часто программисты и специалисты из области data science сталкиваются с задачей поиска похожих профилей пользователей или подбора схожей музыки. Решения могут сводиться к преобразованию объектов в векторную форму и поиску ближайших. Подробнее на Хабре.

Дано первое и последнее изображение, алгоритм вычисляет самый «гладкий путь» между ними из YFCC100M (95 миллионов изображений). Взято здесь.
15. Fashion-mnist, Han Xiao, Research Scientist Zalando Tech
Fashion-MNIST [2780 stars on Github] предлагается как замена БД MNIST (сокращение от «Mixed National Institute of Standards and Technology»), так как MNIST слишком прост. Fashion-MNIST имеет одинаковый размер изображений и структуру для обучения и тестирования.
MNIST — объёмная база данных образцов рукописного написания цифр. База данных является стандартом, предложенным Национальным институтом стандартов и технологий США с целью калибрации и сопоставления методов распознавания изображений с помощью машинного обучения в первую очередь на основе нейронных сетей. Данные состоят из заранее подготовленных примеров изображений, на основе которых проводится обучение и тестирование систем. База данных была создана после переработки оригинального набора черно-белых образцов размером 20x20 пикселей NIST. Создатели базы данных NIST, в свою очередь, использовали набор образцов из Бюро переписи населения США, к которому были добавлены ещё тестовые образцы, написанные студентами американских университетов. Образцы из набора NIST были нормализированы, прошли сглаживание и приведены к серому полутоновому изображению размером 28x28 пикселей.
База данных MNIST содержит 60000 изображений для обучения и 10000 изображений для тестирования. Половина образцов для обучения и тестирования были взяты из набора NIST для обучения, а другая половина — из набора NIST для тестирования.
Производились многочисленные попытки достичь минимальной ошибки после обучения по базе данных MNIST, которые обсуждались в научной литературе. Рекордные результаты указывались в публикациях, посвящённых использованию свёрточных нейронных сетей, уровень ошибки был доведён до 0,23 %. Сами создатели базы данных предусмотрели несколько методов тестирования. В оригинальной работе указывается, что использование метода опорных векторов позволяет достичь уровня ошибки 0,8 %.

Fashion-MNIST
16. ParlAI
ParlAI — это основа для обучения и оценки моделей ИИ на наборе данных из множества диалогов [2578 звезд на Github]. Предоставлено Александром Миллером из Facebook Research

17. Fairseq: Facebook AI Research Sequence-to-Sequence Toolkit [2571 stars on Github]
Команда Facebook AI Research (FAIR) опубликовала впечатляющие результаты работы по реализации сверточной нейронной сети для машинного перевода. Она утверждает, что fairseq, новый инструмент, работает в 9 раз быстрее традиционных рекуррентных нейронных сетей, при этом совсем незначительно уступая им в точности.

18. Pyro: Deep universal probabilistic programming with Python and PyTorch [2387 stars on Github]. Courtesy of Uber AI Labs

19. iGAN
Интерактивная генерация изображений [2369 stars on Github].

20. Deep-image-prior
Восстановление изображений с помощью нейронных сетей без обучения [2188 stars on Github]. Предоставлено Дмитрием Ульяновым, Ph.D at Skoltech

21. Face classification and detection from the B-IT-BOTS robotics team
Обнаружение лиц в реальном времени и эмоциональная + гендерная классификация с использованием наборов данных fer2013/IMDB [1967 stars on Github].
Точность гендерной классификации (IMDB): 96%.
Точность классификации эмоций (fer2013): 66%.

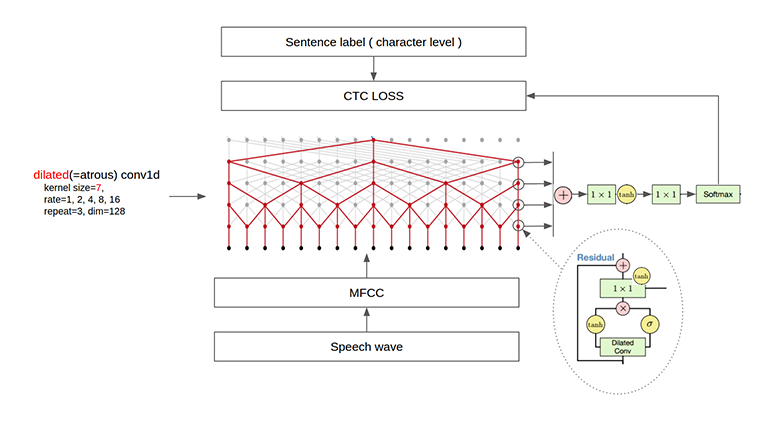
22. Speech-to-Text-WaveNet от Namju Kim из Kakao Brain
End-to-end распознование речи на английском языке с использованием DeepMind’s WaveNet and tensorflow [1961 stars on Github].
23. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation [1954 stars on Github]. Yunjey Choi at Korea University


24. Ml-agents: Unity Machine Learning Agents [1658 stars on Github]. Courtesy of Arthur Juliani, Deep Learning at Unity3D
Unity Machine Learning Agents позволяет исследователям и разработчикам создавать игры и имитационные среды для машинного обучения используя Unity Editor с помощью простого в использовании API Python.

25. DeepVideoAnalytics [1494 stars on Github]. Courtesy of Akshay Bhat, Ph.D at Cornell University
Платформа для поиска и аналитики визуальных данных.

26. OpenNMT: Open-Source Neural Machine Translation in Torch [1490 stars on Github].

27. Pix2pixHD: [1283 stars on Github]. Ming-Yu Liu at AI Research Scientist at Nvidia
Pix2pixHD создан для фотореалистичного синтеза или преобразования изображений с высоким разрешением (например, 2048x1024). Его можно использовать для превращения карт семантических меток в фотореалистичные изображения или для синтеза портретов с помощью карты меток лица.

28. Horovod: Distributed training framework for TensorFlow. [1188 stars on Github]. Courtesy of Uber Engineering

29. AI-Blocks [899 stars on Github]
Мощный и интуитивно понятный WYSIWYG-интерфейс, который позволяет любому создавать модели для машинного обучения.
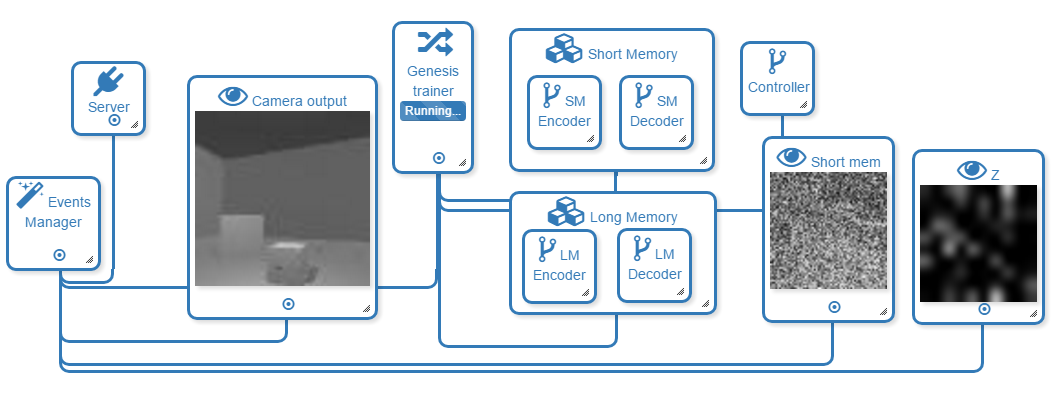
30. Deep neural networks for voice conversion (voice style transfer) in Tensorflow [845 stars on Github]. Dabi Ahn, AI Research at Kakao Brain

Цель проекта — передача стиля голоса или превращения чьего-то голоса в голос конкретного человека. Работа над этим проектом была направлена на преобразование в голос известной английской актрисы Кейт Уинслет.
Дисклеймер
Материалы, приведенные выше, несут исключительно научно-исследовательский характер. Использование результатов для достижения противоправных целей может повлечь за собой уголовную, административную и (или) гражданско-правовую ответственность. Автор не несет ответственность за подобные инциденты.

