
Привет! Меня зовут Константин Евтеев, я работаю в Авито руководителем юнита DBA. Наша команда развивает системы хранения данных Авито, помогает в выборе или выдаче баз данных и сопутствующей инфраструктуры, поддерживает Service Level Objective для серверов баз данных, а еще мы отвечаем за эффективность использования ресурсов и мониторинг, консультируем по проектированию, а возможно и разрабатываем микросервисы, сильно завязанные на системы хранения, или сервисы для развития платформы в контексте хранилищ.
Я хочу рассказать, как мы решили один из вызовов микросервисной архитектуры — проведение бизнес-транзакций в инфраструктуре сервисов, построенных с помощью паттерна Database per service. С докладом на эту тему я выступал на конференции Highload++ Siberia 2018.

Теория. Максимально кратко
Я не буду подробно описывать теорию саг. Дам лишь краткие вводные, чтобы вы понимали контекст.
Как было раньше (со старта Авито до 2015 – 2016 годов): мы жили в условиях монолита, с монолитными базами и монолитными приложениями. В определенный момент эти условия стали мешать нам расти. С одной стороны, мы уперлись в производительность сервера с главной базой, но это не основная причина, так как вопрос производительности можно решить, например с помощью шардирования. С другой стороны, у монолита очень сложная логика, и на определенном этапе роста доставка изменений (релизов) становится очень длительной и непредсказуемой: много неочевидных и сложных зависимостей (все тесно связано), тестировать тоже трудоемко, в общем масса проблем. Решение — перейти на микросервисную архитектуру. На этом этапе у нас появился вопрос с бизнес транзакциями, сильно завязанными на ACID, предоставленными монолитной базой: нет ясности как мигрировать данную бизнес логику. При работе с Авито возникает множество различных сценариев, реализованных несколькими сервисами, когда целостность и согласованность данных очень важна, например покупка премиальной подписки, списание денег, применение услуг к пользователю, приобретение VAS-пакетов — в случае непредвиденных обстоятельств или аварий все неожиданно может пойти не по плану. Решение мы нашли в сагах.
Мне нравится техническое описание саг, которое в 1987 году привели Кеннет Салем и Гектор Гарсия-Молина — один из нынешних членов совета директоров Oracle. Как формулировалась проблема: есть сравнительно небольшое количество долгоживущих транзакций, которые длительное время препятствуют выполнению небольших, менее требовательных к ресурсам и более частых операций. В качестве желаемого результата можно привести пример из жизни: наверняка многие из вас стояли в очереди отксерокопировать документы, и оператор ксерокса, если у него была задача копировать целую книгу или просто много экземпляров копий, время от времени делал копии других членов очереди. Но утилизация ресурсов — это только часть проблем. Ситуацию усугубляют и длительные блокировки при выполнении ресурсоемких задач, каскад из которых выстроится в вашей СУБД. Кроме того, в процессе длительного выполнения транзакции могут возникать ошибки: транзакция не завершится и начнется откат. Если транзакция была длинной, то откат тоже будет идти долго, и вероятно, еще будет retry от приложения. В общем, «все достаточно интересно». Решение, предложенное в техническом описании «SAGAS»: разбить длинную транзакцию на части.
Мне кажется, многие подходили к этому, даже не читая этот документ. Мы неоднократно рассказывали про наши defproc (deferred procedures, реализованные при помощи pgq). Например, при блокировке пользователя за fraud — быстро выполняем короткую транзакцию и отвечаем клиенту. В этой короткой транзакции, в том числе, ставим задачу в транзакционную очередь, а потом асинхронно, небольшими партиями, например по десять объявлений блокируем его объявления. Мы это делали с помощью реализации транзакционных очередей от Skype.
Но наша сегодняшняя история немного отличается. Нужно посмотреть на эти проблемы с другой стороны: распил монолита на микросервисы, построенные с помощью паттерна database per service.
Один из самых важных параметров для нас — достижение максимальной скорости распила. Поэтому мы решили переносить старую функциональность и всю логику как есть в микросервисы, вообще ничего не меняя. Дополнительные требования, которые нам нужно было выполнить:
- обеспечивать зависимые изменения данных для бизнес-критичных данных;
- иметь возможность задавать строгий порядок;
- соблюдать стопроцентную консистентность — согласовывать данные даже при авариях;
- гарантировать работу транзакций на всех уровнях.
Под вышеописанные требования наиболее оптимально подходит решение в виде оркестрируемой саги.
Реализация оркестрируемой саги в виде сервиса PG Saga
Так выглядит сервис PG Saga.

PG в названии, потому что как хранилище сервиса используется синхронный PostgreSQL. Что еще есть внутри:
- API;
- executor;
- checker;
- healthchecker;
- compensator.
На схеме также изображен сервис-владелец саг, а внизу — сервисы, которые будут выполнять шаги саги. У них могут быть разные хранилища.
Как это работает
Рассмотрим на примере покупки VAS-пакетов. VAS (Values-added services) — платные услуги для продвижения объявления.
Сначала сервис владелец саги должен зарегистрировать создание саги в сервисе саг

После этого он генерирует класс саги уже с Payload.

Далее уже в сервисе саг executor поднимает из хранилища ранее созданный вызов саги и начинает выполнять ее по шагам. Первый шаг в нашем случае — покупка премиальной подписки. В этот момент в сервисе биллинга резервируются деньги.

Потом в сервисе пользователя применяются VAS-операции.

Затем уже действуют VAS-сервисы, и создаются пакеты васов. Дальше возможны и другие шаги, но они не так важны для нас.

Аварии
В любом сервисе могут произойти аварии, но есть известные приемы, как к ним подготовиться. В распределенной системе об этих приемах знать важно. Например, одно из самых важных ограничений — сеть не всегда надежна. Подходы, которые позволят решить проблемы взаимодействия в распределенных системах:
- Делаем retry.
- Маркируем каждую операцию идемпотентным ключом. Это нужно, чтобы избежать дублирования операций. Больше об идемпотентных ключах можно прочитать в этом материале.
- Компенсируем транзакции — действие, характерное для саг.
Компенсация транзакций: как это работает
Для каждой положительной транзакции мы должны описать обратные действия: бизнес-сценарий шага на случай, если что-то пойдет не так.
В нашей реализации мы предлагаем такой сценарий компенсации:
Если какой-то шаг саги завершился неуспешно, а мы сделали множество retry, то есть шанс, что последний повтор операции удался, но мы просто не получили ответ. Попробуем компенсировать транзакцию, хотя этот шаг не обязателен, если сервис-исполнитель проблемного шага действительно сломался и совсем недоступен.
В нашем примере это будет выглядеть следующим образом:
- Выключаем VAS-пакеты.

- Отменяем операцию пользователя.

- Отменяем резервирование средств.

Что делать, если и компенсация не работает
Очевидно, что надо действовать по примерно такому же сценарию. Опять применять retry, идемпотентные ключи для компенсирующих транзакций, но если ничего не выходит и в этот раз, например, сервис не доступен, надо обратиться к сервису-владельцу саги, сообщая, что сага сфейлилась. Дальше уже более серьезные действия: эскалировать проблему, например, для ручного разбирательства или запуска автоматики по решению подобных проблем.
Что еще важно: представьте, что какой-нибудь шаг сервиса саги недоступен. Наверняка же еще инициатор этих действий будет делать какие-то retry. И в итоге, ваш сервис саг делает первый шаг, второй шаг, а его исполнитель недоступен, вы отменяете второй шаг, отменяете первый шаг, а еще могут возникнуть аномалии, связанные с отсутствием изоляции. В общем, сервис саг в этой ситуации занимается бесполезной работой, которая еще порождает нагрузку и ошибки.
Как надо делать? Healthchecker должен опросить сервисы, которые выполняют шаги саг, и посмотреть, работают ли они. Если сервис стал не доступен, то есть два пути: саги, которые в работе, — компенсировать, а новые саги — либо не давать создать новые экземпляры (вызовы), либо создавать, не беря их в работу executer’ом, чтобы сервис не занимался лишними действиями.
Еще один сценарий с аварией
Представьте, что мы опять делаем ту же самую премиальную подписку.
- Покупаем VAS-пакеты и резервируем деньги.

- Применяем к пользователю услуги.

- Создаем VAS пакеты.

Вроде бы хорошо. Но внезапно, когда транзакция завершилась, выясняется, что в сервисе пользователей используется асинхронная репликация и на мастер базе произошла авария. Может быть несколько причин отставания реплики: наличие специфичной нагрузки на реплику, которая либо снижает скорость проигрывания репликации, либо блокирует проигрывание репликации. Кроме того, источник (мастер) бывает перегружен, и появляется лаг отправки изменений на стороне источника. В общем, по каким-то причинам реплика отставала, и изменения успешно пройденного шага после аварии внезапно пропали (результат/состояние).

Для этого реализуем еще один компонент в системе — используем checker. Checker проходит по всем шагам успешных саг через время заведомо большее, чем все возможные отставания (например, через 12 часов), и проверяет, действительно ли они до сих пор успешно выполнены. Если шаг внезапно оказывается не выполнен, сага откатывается.




Могут быть еще ситуации, когда через 12 часов отменять уже и нечего — все меняется и движется. В таком случае вместо сценария отмены, решением может быть сигнализация сервису владельца саги, что эта операция не выполнилась. Если операция отмены невозможна, скажем, нужно сделать отмену после начисления денег пользователю, а его баланс уже нулевой, и деньги списать нельзя. У нас такие сценарии решаются всегда в сторону пользователя. У вас может быть другой принцип, это согласуется с представителями продукта.
В итоге, как вы могли заметить, в разных местах для интеграции с сервисом саг нужно реализовать много различной логики. Поэтому когда клиентские команды захотят создать сагу, у них встанет весьма большой набор весьма неочевидных задач. Прежде всего, создаем сагу так, чтобы не получилось дублирования, для этого работаем с какой-то идемпотентной операцией создания саги и ее трекинга. Также в сервисах требуется реализовать способность отслеживать каждый шаг каждой саги, для того чтобы с одной стороны два раза его не выполнить, а с другой стороны, уметь ответить, действительно ли он был выполнен. А еще все эти механизмы надо как-то обслуживать, чтобы хранилища сервисов не переполнились. Кроме того, есть много языков, на которых могут быть написаны сервисы, и огромный выбор хранилищ. На каждом этапе нужно разобраться в теории и имплементировать всю эту логику на разных частях. Если этого не сделать, можно совершить целую кучу ошибок.
Правильных путей много, но ситуаций, когда вы можете «отстрелить себе конечность» — не меньше. Чтобы саги работали корректно, нужно все вышеописанные механизмы инкапсулировать в клиентских библиотеках, которые будут их прозрачно реализовывать для ваших клиентов.
Пример логики генерации саги, которую можно скрыть в клиентской библиотеке
Можно сделать иначе, но я предлагаю следующий подход.
- Получаем request ID, по которому мы должны создать сагу.
- Идем в сервис саг, получаем ее уникальный идентификатор, сохраняем его в локальном хранилище в связке с request ID из пункта 1.
- Запускаем сагу с payload в сервис саг. Важный нюанс: я предлагаю локальные операции сервиса, который создает сагу, оформлять, как первый шаг саги.
- Возникает некая гонка, когда сервис саг может выполнить этот шаг (пункт 3), и наш backend, инициирующий создание саги, тоже будет его выполнять. Для этого везде делаем идемпотентные операции: кто-то один его выполняет, а второй вызов просто получит «ОК».
- Вызываем первый шаг (пункт 4) и только после этого отвечаем клиенту, который инициировал это действие.
В этом примере мы работаем с сагой как с базой данных. Вы же можете отправить запрос, а далее соединение может и оборвется, но действие будет выполнено. Здесь примерно такой же подход.
Как это все проверить
Нужно покрыть весь сервис саг тестами. Вероятнее всего, вы будете вносить изменения, и тесты, написанные на старте, помогут избежать нежданных сюрпризов. Кроме того, необходимо проверять и сами саги. Например, как у нас устроено тестирование сервиса саг и тестирование последовательности саг в рамках одной транзакции. Тут есть разные блоки тестов. Если мы говорим про сервис саг, он умеет выполнять положительные транзакции и транзакции компенсации, если компенсация не работает сообщает сервису владельцу саг. Мы пишем тесты в общем виде, на работу с абстрактной сагой.
С другой стороны, положительные транзакции и компенсационные транзакции на сервисах, которые выполняют шаги саг, это же простое API, и тесты этой части в зоне ответственности команды-владельца этого сервиса.
А далее уже команда владелец саги пишет end-to-end тесты, где она проверяет, что вся бизнес-логика корректно работает при выполнении саги. Еnd-to-end тест проходит на полноценном dev-окружении, поднимаются все экземпляры сервисов, в том числе сервис саг, и там уже проходит проверку бизнес-сценарий.

Итого:
- написать побольше юнит-тестов;
- написать интеграционные тесты;
- написать end-to-end тесты.
Следующий шаг — CDC. Микросервисная архитектура влияет на специфику тестов. В Авито мы приняли следующий подход к тестированию микросервисной архитектуры: Consumer-Driven Contracts. Этот подход помогает, прежде всего, подсветить проблемы, которые можно выявить на end-to-end тестах, но end-to-end тест «очень дорогой».
В чем суть CDC? Есть сервис, который предоставляет контракт. У него есть API — это provider. А есть другой сервис, который вызывает API, то есть пользуется контрактом — consumer.
Сервис-consumer пишет тесты на контракт provider’а, причем тесты, которые будет проверять только контракт, — не функциональные тесты. Нам важно гарантировать, что при изменении API у нас не сломаются шаги в данном контексте. После того как мы написали тесты, появляется еще один элемент сервис-брокер — в нем регистрируется информация о CDC-тестах. При каждом изменении сервиса провайдера он будет поднимать изолированное окружение и запускать тесты, которые написал consumer. Что в итоге: команда, которая генерирует саги, пишет тесты на все шаги саги и регистрирует их.

О том, как в Авито реализовали CDC-подход для тестирования микросервисов рассказывал Фрол Крючков на РИТ++. Тезисы можно найти на сайте Backend.conf — рекомендую ознакомиться.
Виды саг
По порядку вызова функций
а) неупорядоченная — функции саги вызываются в любом порядке и не ждут завершения друг друга;
б) упорядоченная — функции саги вызываются в заданном порядке, друг за другом, следующая не вызывается пока не завершится предыдущая;
в) смешанная — для части функций задан порядок, а для части нет, но задано перед или после каких этапов их выполнять.
Рассмотрим конкретный сценарий. В том же сценарии покупки премиальной подписки первым шагом будет резервирование денег. Теперь изменения у пользователя и создание премиальных пакетов мы можем выполнить параллельно, а пользователю отправим уведомления только когда закончатся эти два шага.

По получению результата вызова функций
а) синхронная — результат функции известен сразу;
б) асинхронная — функция возвращает сразу «ОК», а результат возвращается потом, через обратный вызов API сервиса саг из клиентского сервиса.
Хочу вас предостеречь от ошибки: лучше не делать синхронные шаги саг, особенно при реализации оркестрируемой саги. Если вы будете делать синхронные шаги саг, то сервис саг будет ждать, пока выполниться этот шаг. Это лишняя нагрузка, лишние проблемы в сервисе саг, поскольку он один, а участников саг много.
Масштабирование саг
Масштабирование зависит от размеров планируемой вами системы. Рассмотрим вариант с одним экземпляром хранилища:
- один обработчик шагов саг, обрабатываем шаги батчами;
- n обработчиков, реализуем «расческу» — берем шаги по остатку от деления: когда каждый executor получает свои шаги.
- n обработчиков и skip locked — будет еще эффективнее и более гибко.
И только потом, если вы заранее знаете, что упретесь в производительность одного сервера в СУБД, нужно делать шардинг — n инстансов баз, которые будут работать со своим набором данных. Шардирование можно скрыть за API сервиса саг.
Больше гибкости
Кроме того, в этом паттерне, по крайней мере в теории, клиентский сервис (выполняющий шаг саги) может обращаться к сервису саг и вписываться в него, а участие в саге может быть в том числе и опциональным. Еще может быть и другой сценарий: если вы уже отправили электронное письмо, компенсировать действие невозможно — вернуть письмо назад нельзя. Но можно отправить новое письмо, что предыдущее было неправильным, и выглядит подобное так себе. Лучше использовать сценарий, когда сага будет проигрываться только вперед, без каких-либо компенсаций. Если она не проигрывается вперед, то надо сообщать сервису владельцу саги о проблеме.
Когда нужен лок
Небольшое отступление про саги в целом: если вы можете сделать свою логику без саги, то делайте. Саги — это сложно. С локом примерно то же самое: лучше всегда избегать блокировок.
Когда я пришел в команду биллинга рассказывать про саги, они сказали, что им нужен лок. У меня получилось им объяснить, почему лучше обойтись без него и как это сделать. Но если лок все-таки вам потребуется, то это стоит предусмотреть заранее. До сервиса саг мы уже в рамках одной СУБД реализовывали блокировки. Пример с defproc и сценарием асинхронной блокировки объявлений и синхронной блокировкой аккаунта, когда сначала синхронно делаем часть операции и ставим блокировку, а потом асинхронно в фоне завершаем батчами оставшуюся работу.
Как это сделать? В рамках одной СУБД вы можете сделать некую таблицу, в которой будете сохранять записи о блокировке, и далее в триггере, при выполнении операций над объектом этой блокировки подсматривать в эту таблицу, и, если кто-то попытается его поменять во время блокировки, генерировать исключения. Примерно то же самое можно сделать и в сервисе саг. Главное соблюсти порядок. Я предлагаю следующий подход: сначала мы делаем блокировку в сервисе саг, если мы хотим реализовать сагу с локом, а потом уже ее спускаем до клиентского сервиса с помощью вышеописанного подхода.
Можно и по-другому, но важно, чтобы был правильный порядок. И нужно понимать, что если у вас появились блокировки, значит появятся и дедлоки. Если появятся дедлоки, значит, нужно делать детектор дедлоков. А еще блокировки могут быть эксклюзивные и разделяемые. Но не советую планировать многоуровневую блокировку — это достаточно сложная история, а сервис должен быть простым, ведь он единственная точка отказа всех ваших транзакций.
ACID — без изоляции
У нас есть атомарность, поскольку все шаги либо выполнятся, либо компенсируются. Есть консистентность за счет сервиса саг и локальных хранилищ в сервисе саг. И устойчивость — благодаря локальным хранилищам и их механизмам durability. Изоляции у нас нет. В отсутствие изоляции у нас будут возникать различные аномалии. Они возникнут, когда мы можем потерять обновления. Вы прочитаете какие-то данные, потом кто-то другой что-то запишет, а ваша исходная транзакция возьмет и перепишет эти изменения

Могут происходит грязные чтения — когда вы в процессе выполняете какую-то сагу, сделали что-то одно, записали, кто-то эти изменения уже прочитал, а ваша сага еще не закончена. Вы записываете еще раз, что-то меняете, а кто-то прочитает неправильные состояния.

Случаются неповторяющиеся чтения — когда вы в течение одной и той же саги будете получать разные состояния вашего объекта.

Как этого избежать:
- Работать с версией объекта, держать некую версию, например, у пользователя, и ее инкрементировать при каждом изменении.
- Проверять, что вы все еще работаете с ней же. Или же смотреть то состояние, которое вы хотите поменять, например статус, и следить, что вы применяете его к тому самому статусу, который до этого хотели сменить.
- Можно выстроить блокировки и сериализовывать все изменения вокруг главного объекта саги.
- Передавать в payload саги только события и не работать с состоянием. Эта история об eventual consistency — если вы передадите состояние объявления сервису пользователей, может быть, оно уже поменяется к тому моменту, когда событие дойдет до адресата. Нужно передавать информацию о том, что произошла, например, регистрация пользователей или мы применили пользователю премиум-услугу.
Мониторинг
Нужно мониторить выполнение саг с разбивкой по всем шагам и по всем статусам. Мы собираем всю телеметрию, в том числе как долго выполняется каждый шаг саги и сами саги. Все то же самое мы должны смотреть и для компенсирующих транзакций. К тому же не забывать про checker. А еще хорошо бы обложить сервис саг метриками на каждом шаге. Вот примеры графиков, которые мы собираем.
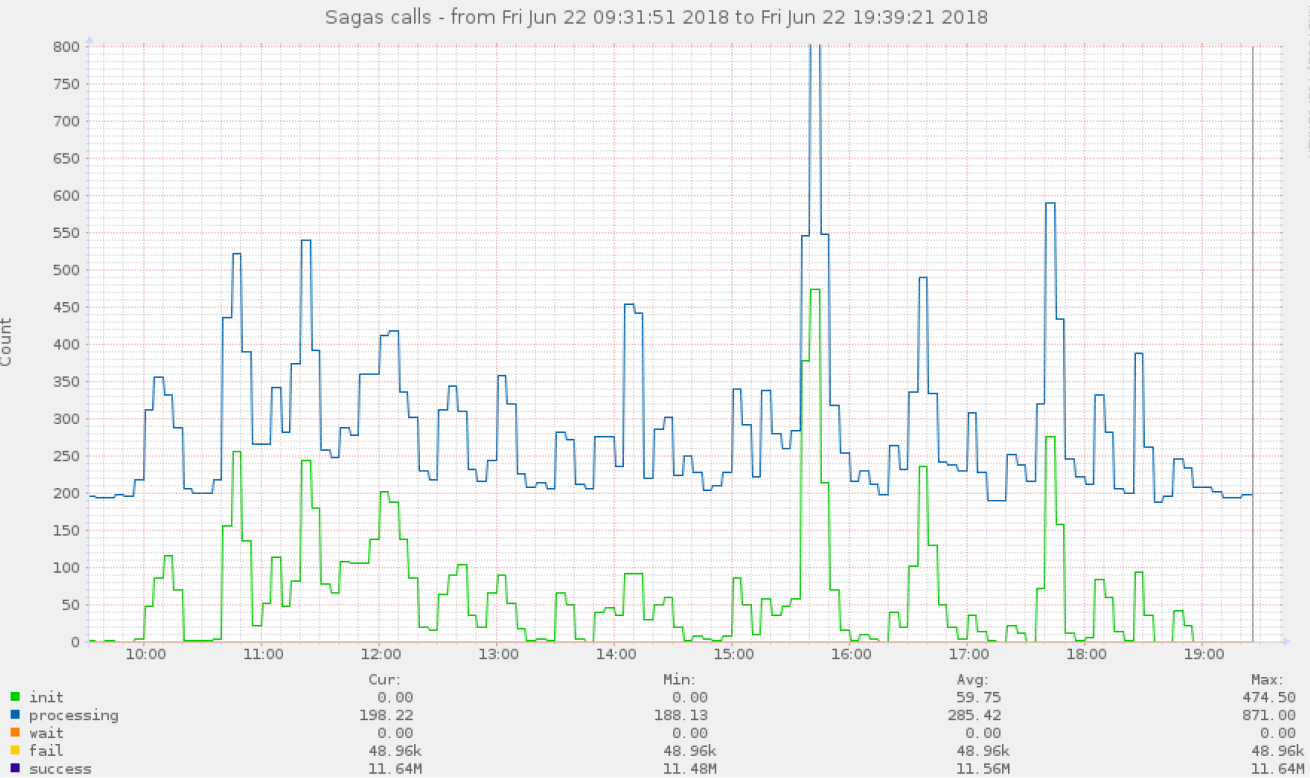
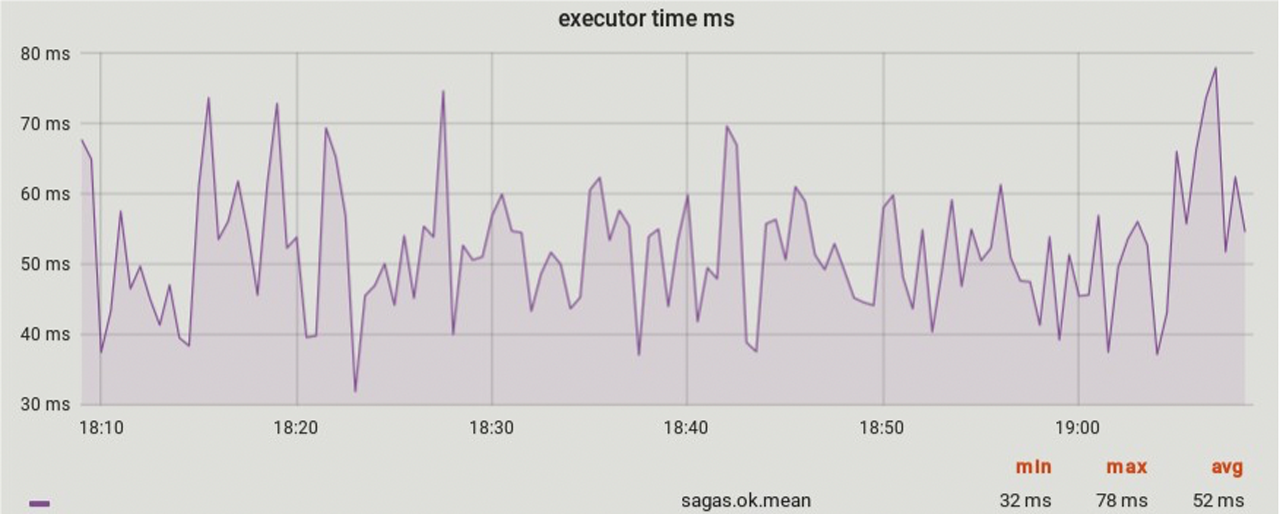
В первую очередь смотрим на перцентили (50%, 75%, 95%, 99%), потому что по ним вы раньше всего узнаете, если что-то пошло не так.
Как определить место поломки, если сага поломалась — как я уже сказал, мы собираем метрики с разбивкой по шагам и далее. На все эти шаги саг мы можем повесить алерты. Если определенные шаги саги копятся, значит что-то пошло не так. Но возможно, что сага еще совсем не сломалась — просто произошел всплеск нагрузки в одном из сервисов исполнителей шагов саги.
Еще одна ситуация. Как определить, что какой-то шаг саги (сервис вышел из строя) совсем не работает. В данном случае healthchecker проверяет все endpoint’ы info (keep-alive) клиентских сервисов.
Ну и третий пример. Может быть авария со стороны бизнес-сценария. Ответственность бизнес-сценария, что ваша бизнес-транзакция выполняется корректно, уже полностью лежит на команде владельца саги и командах владельцев сервисов-исполнителей шагов саги. В этой ситуации владелец отдельно взятой саги, когда он ее проектирует, должен покрыть ее тестами, в том числе end-to-end. Далее нужен мониторинг на различные бизнес-метрики саги. Команда, которая сгенерировала эту сагу, должна у себя отслеживать метрики — это зона ее ответственности.
Сам сервис саг также тщательно мониторим. А еще хорошо бы реализовать автофейловер для локального хранилища сервиса саг.
На что стоит обратить внимание:
Избегать паразитных нагрузок
Выше я уже говорил, что нужно строить healthchecker, и если какой-то узел вышел из строя, нужно прекращать выполнять эти саги. Потому что сервис саг один, а клиентов много. Вы просто излишне перегрузите ваш сервис саг.
Избегать сложной логики избыточной функциональности в сервисе саг
Как только вы ввязываетесь в эту историю, сервис саг становится самой критичной точкой вашей инфраструктуры. Если он откажет, последствия могут быть ровно такими, какую вы функциональность на него накрутите. А мы хотим на него завязать самую критичную функциональность. Поэтому choreography паттерн саг смотрится выгоднее — там сервис саг участвует только когда что-то пошло не так. В общем виде, даже если ваш сервис саг в choreography-паттерне сломается, у вас все будет продолжать работать. Сервис саг в choreography критически нужен, например при выполнении отката. Если мы делаем оркестрируемую сагу, то с выходом из строя сервиса саг из строя выйдет все. Соответственно, чем меньше логики вы туда вкрутите, тем проще и быстрее он будет работать, и тем надежнее будет вся система.
Интегрироваться с клиентами
Обучить все ваши команды работе с сервисом саг. Этот пласт теории надо прочитать, поскольку не всем может быть очевидно, как правильно работать с персистентными системами в контексте саг. Подумайте, как сделать удобной работу с локальным хранилищем + работу с различными языками в контексте саг и как это все скрыть в клиентских библиотеках.
Версионность API
В нашей реализации, когда в сервисе-исполнителе клиентского шага мы хотим что-то поменять (новая версия API сервиса), мы создаем новую сагу, в которой используем новую версию API. После этого переводим всех на новую сагу и старую сагу можно удалять и далее старый метод API также можно удалить. Тут нужно быть внимательным — изменения в том числе могут неявно затрагивать логику компенсации. В том числе перед удалением старых классов саг и методов API шагов саг, нужно подождать интервал времени, когда уже 100% по старым методам не может пройти компенсация.
Ну и естественно, если придется менять сервис саг, и изменения будут обратно несовместимыми, необходимо будет поправить все сервисы, которые взаимодействуют с сервисом саг. Серебряной пули нет — все зависит от того, насколько велик характер изменений, которые вы собираетесь внести. Но таких случаев у нас пока не было.
Компенсация при авариях
При проектировании компенсационных транзакций, в случае различных аварий, когда невозможно выполнить сагу, внимательно изучите с представителем продукта вероятные сценарии и опишите их. Важно искать компромисс между автоматизацией решения инцидентов (предпочтительный вариант) и передачей их на анализ и принятие решения человеком.
Отсутствие изоляции
Лучше заранее изучить различные сценарии, кто работает с тем или иным объектом вашей саги или частью саги, конкретного шага, и что может пойти не так, если он прочитает данные в процессе выполнения саги.
Блокировки
Лучше их избегать. Скорее всего, если не получается это сделать, вам нужен другой инструмент.
Трейсинг по saga call ID
У нас все состояния хранятся в хранилище сервиса саг. Есть API в сервисе саг, которое по идентификатору конкретного экземпляра саги возвращает текущее состояние саги.
Итог — что выбирать
Сагу-оркестратор мы используем как возможность рефакторинга legacy кода. Но если бы была возможность написания всего с нуля, мы использовали бы хореографическую сагу (в том числе в планах реализация паттерна «хореограф» и перевода на него части функциональности но это уже другая история и там есть свои нюансы). Что тут является «узким горлышком»? Если вы хотите как-то поменять сагу, вам надо пойти к команде, которая владеет этой сагой, договориться о том, что вы собираетесь что-то менять, потому что у нее в том числе тесты могут быть. Но в любом случае вам, как минимум, надо с ними договориться или законтрибьютить в их сервис тот код, который теперь будет генерировать сагу с вашим дополнительным шагом. И таким образом получается, что это достаточно «узкое горлышко», потому что очень плохо масштабируется, если у вас очень много команд и различной бизнес-логики. Это минус. Плюс — это удобство переноса текущей функциональности. Все потому, что мы можем заранее жестче тестировать и гарантировать порядок выполнения.
Я за прагматичный подход к разработке, поэтому для написания сервиса саг, инвестиция в написание такого сервиса должна быть оправдана. Более того, вероятнее всего, многим нужна только часть из того, что я описал, и эта часть решит текущие потребности. Главное, заранее понять, что именно из всего этого нужно. И как много ресурсов у вас есть.
Если у вас есть вопросы или вам интересно узнать больше про саги, пишите в комментариях. С радостью отвечу.
