«Некоторые называют нас «Плюшкиными» — мне нравится говорить, что мы архивисты.»
Директор Wayback Machine Марк Грэм изложил масштаб всеми любимого архива

Просматриваем Wayback Machine на конференции Online News Association 2018
Остин, Техас. Как бы сильно абонентские услуги не хотели вас в этом убедить, но не все можно найти на Amazon или Netflix. Хотите, например, прочитать книгу судьи Бретта Кавано (или даже их скандально известный ежегодник)? Любопытно посмотреть кучу винтажных рекламных постеров с курением? Как насчет просмотра самой большой коллекции тибетской буддийской литературы в мире? На сегодняшний день есть одно место, где вы можете все это сделать, и это не Google или какие-то пиратские сайты, которые вы наверняка (часто) посещаете.
«У меня есть правительственное видео о том, как мыть руки или готовиться к ядерной войне, — говорит Марк Грэм, директор Wayback Machine в Internet Archive. «Мы могли бы легко составить список .ppt-файлов на всех сайтах с доменом .mil, Military Industrial PowerPoint Complex».
Грэм недавно поговорил с несколькими небольшими группами участников конференции Online News Association 2018 и Ars Technica повезло быть там. Позже он сделал полную презентацию конференции, которая теперь доступна в аудиоформате. И основная мысль заключается в том, что масштаб Internet Archive сегодня может быть так же трудно понять, как масштаб самого интернета.
Некоммерческое физическое пространство по-прежнему остается легким для понимания, по крайней мере, так задумывал его Грэм. Сегодня вся деятельность Интернет Архива ведется из одной старой церкви (даже скамьи не убрали) в Сан-Франциско силами примерно двхусот человек. В архиве также находится ближайший склад для хранения физических носителей, не только книг, но и таких вещей, как виниловые пластинки. Грэм шутит, что там основной единицей измерения является «контейнер для доставки». Архив получает такое количество материала каждые две недели.
В настоящее время компания является вторым по величине сканером книг в мире, после Google. Грэм добился того, чтобы текущая сумма сканирований насчитывала свыше четырех миллионов. В архиве даже есть список желаний для его следующих 1,5 миллионов сканирований, включая все, что цитируется в Википедии. Wayback Machine старается защитить вас от, того, что выскочит 404 ошибка во время перехода по ссылокам из Википедии (Грэм недавно сказал BBC, что боты Wayback восстановили почти шесть миллионов страниц, потерянных из-за сбоя ссылок ради этого). Сегодня книги, опубликованные до 1923 года, можно бесплатно скачать через Internet Archive, и впоследствии можно позаимствовать цифровую копию многих из этих книг

Перевод твита:
Internet Archive: Более 9 миллионов неправильных ссылок в Википедии исправлены
WikiResearch: Так благодарны за необыкновенную работу, которую проделывают наши друзья в @internetarchive для борьбы с 404 ошибкой и в цифровом виде сохраняют миллионы ссылок на сайты и источники, которые цитируют википедиане, поскольку они создают самую большую в мире энциклопедию.
Конечно, в наши дни Internet Archive предлагает гораздо больше, чем просто текст. Его сборник новостей охватывает более 1,6 млн. новостных программ с такими инструментами, как возможность поиска слов в титрах и доступа к последним новостям (трансляции становятся доступными через 24 часа, а затем предоставляются посетителям в виде двухминутных отрывков с возможностью поиска). Растущая аудио и музыкальная часть Internet Archive охватывает радио-новости, подкастинг и физические медиа (например, сборник из 200 000 экземпляров 78-х годов, недавно пожертвованный библиотекой Бостона). И, как пишет Ars, организация может похвастаться обширной классической коллекцией видеоигр, которую каждый может загружать в эмулятор на основе браузера для исследований или отдыха. Официально этот раздел включает в себя около 300 000+ наименований, «поэтому вы можете фактически играть в Oregon Trail на старом компьютере Apple C computer в браузере прямо сейчас — нет рекламы, нет отслеживания пользователей», — говорит Грэм.
«Некоторые могут назвать нас «Плюшкиными»», — говорит он. «Мне нравится говорить, что мы архивисты».
В целом, Грэм говорит, что в Internet Archive добавляется четыре петабайта информации в год (это четыре миллиона гигабайт для контекста). Текущие данные организации составляют 22 петабайта, но Internet Archive фактически владеет 44 петабайтами. «Потому что мы параноики, — говорит Грэм. «Машины могут выйти из строя, а у нас есть репутация». Это кредо в духе NASA помогло некоммерческой организации выжить после ущерба нанесенного огнем, который обошелся почти в 600 000 долларов — все это без потери архивных данных.

30 000 входных данных? Неплохо, и кажется, что боты Wayback Machine, безусловно, увеличили свою привязанность к Ars.
С помощью Wayback Machine вы можете вспомнить и задуматься о том как Ars скрыл смерть Стива Джобса еще в октябре 2011 года.
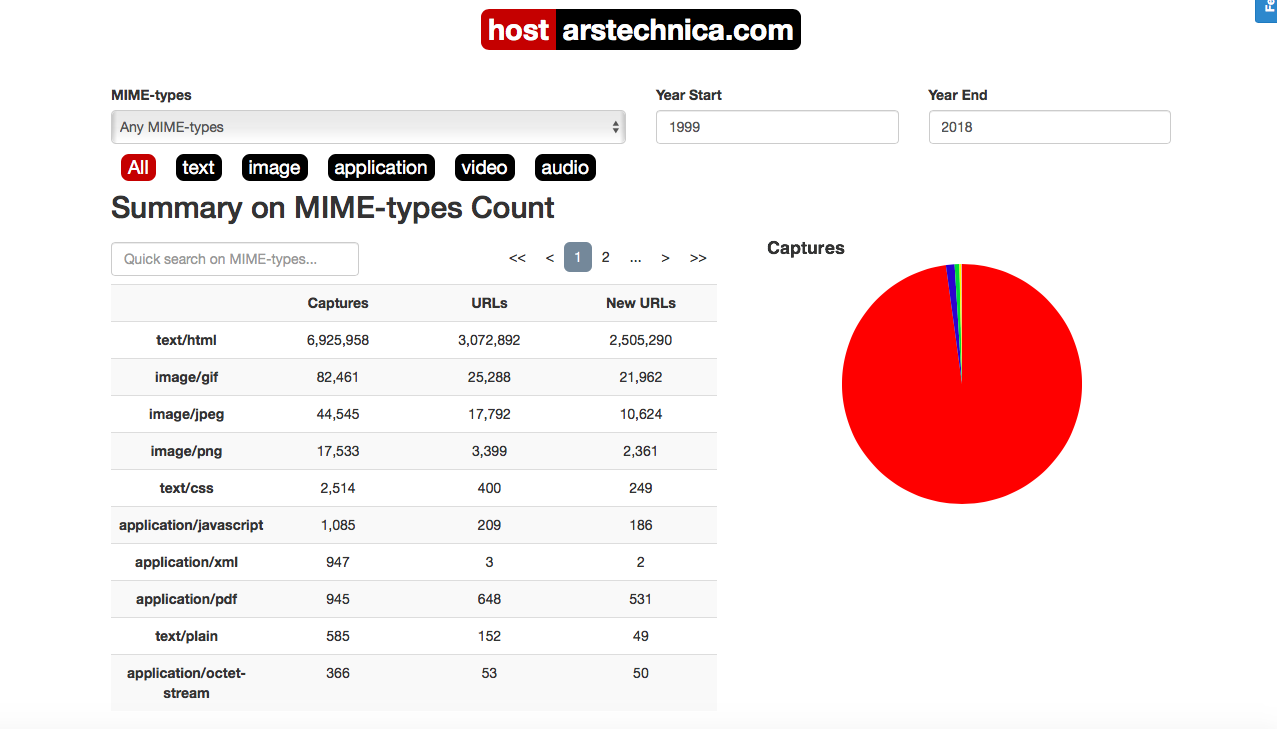
Хм… может быть, у меня все еще есть шанс стать Arsian/арсианином, чтобы загрузить 1000-й PDF-файл, захваченный Internet Archive.
Универсальный доступ к знаниям (и к фактам, к огромному количеству фактов)
Общая концепция деятельности Internet Archive на протяжении последних 22 лет была простой: «универсальный доступ ко всем знаниям». В эпоху интернета это означает, конечно, внедрение небольшой армии ботов, и Грэм отмечает, что в Internet Archive всегда есть программное обеспечение собирающее контент. Примерно 7 000 одновременных процессов охватывают всю сеть, чтобы в итоге получать 1,5 миллиарда разных вещей в неделю. Некоторые вещи, такие как домашние страницы Google или The New York Times, могут просматриваться много раз в день; другие можно просматривать менее часто.
«Мы пытаемся получить все, но это сложно, — отмечает Грэм. «Embeds, Javascripts, интерактивные приложения — мы не можем получить некоторые из этих материалов, но мы работаем над этим».
В кэш-память вещей, над которыми мы работаем, входят эфемерные медиа, такие как Snapchat или публичные группы Telegram, а Wayback Machine поддерживает локальные контакты в местах, где некоторые медиа-архивы или серверы могут подвергаться риску (в последнее время Грэм отмечает партнеров в Египте, например).
Результатом всего этого является то, что Wayback Machine превратилась во что-то гораздо более полезное, чем просто былые забавные поездки в LiveJournals. Ars использовал его много раз для разных целей, начиная от перехвата изменений в чистом нейтралитете Comcast, заканчивая тем фактом, что организационное описание Defense Distributed эволюционировало. И Грэм указывает на недавнюю полемику 2018 года, когда президент Трамп написал в твиттере, что Google не способствует хорошему отношению к Соединенным Штатам Америки на своей домашней странице (как это было в прошлом). Прежде чем Google смогли на это ответить, компания обратилась к Internet Archive с простым вопросом — есть ли копия?
«Я люблю Google, но их работа не заключается в том, чтобы делать копии домашней страницы каждые 10 минут», — говорит Грэм. «Это наша работа».
Грэм поделился информацией о том, что Wayback Machine фактически захватила 835 экземпляров главной страницы Google в январе 2018 года. «Таким образом, мы смогли помочь поднять записи. Мы не принимаем ничью сторону, но мы за правду».
Сайт сыграл аналогичную роль, когда Белый дом не так давно удалил все архивы своих бюллетеней, а ряд организаций (не только новостных, но также экологических организации или ACLU), нуждались в них. И материалы, полученные из Wayback Machine, были использованы как доказательства в суде. «Существует много событий, которые происходят с точки зрения времени, — добавляет он. Как бывший вице-президент NBC News (отсюда и его желание присутствовать на ONA, возможно), Грэм также с гордостью указывает на то, что на сайт ссылаются примерно пять раз в день в средствах массовой информации.
Грэм говорит, что для того чтобы улучшить сайт Wayback Machine усердно работает над улучшением своих пользовательских инструментов. В нижней левой части главной страницы Wayback Machine вы найдете, например, общедоступные API. Грэм указывает на то, что люди используют их для создания таких вещей, как дифференциатор, где вы можете взять два скана, расположить бок о бок и увидеть изменения. Другой инструмент, созданный пользователем, который привлек его внимание, позволяет взглянуть на сайт и сделать радиальный древовидный график, чтобы увидеть, как его структура меняется со временем.
Хотя, возможно, самый простой и эффективный инструмент для всех это технология непосредственно от Wayback Machine — сайт позволяет кому-либо вручную отправлять ссылку на Internet Archive для архивирования прямо со своей домашней страницы. «Если я выгуливаю свою кошку в саду, и я вижу историю в новостях Google, вы можете отправить ее на печать. Но сегодня вы также можете отправить ее в Internet Archive», — говорит Грэм. По его оценкам, в итоге может получиться около миллиона снимков в неделю.
«Мы выискиваем информацию в действительно большой сети без обмана, — говорит он. И вне зависимости от того находят что-то боты, или преданный любитель-пользователь архива, все остальные могут просто оценить способность находить контент, что кстати и является изначальной миссией Ars Technica. (К счастью, спустя 20 лет, никто еще не сообщил нам об «очень плохих вещах, таких как NT, Linux и BeOS-контент под одной крышей».)
Перевод: Диана Шеремьёва

Про #philtech
#philtech (технологии + филантропия) — это открытые публично описанные технологии, выравнивающие уровень жизни максимально возможного количества людей за счёт создания прозрачных платформ для взаимодействия и доступа к данным и знаниям. И удовлетворяющие принципам филтеха:
1. Открытые и копируемые, а не конкурентно-проприетарные.
2. Построенные на принципах самоорганизации и горизонтального взаимодействия.
3. Устойчивые и перспективо-ориентированные, а не преследующие локальную выгоду.
4. Построенные на [открытых] данных, а не традициях и убеждениях
5. Ненасильственные и неманипуляционные.
6. Инклюзивные, и не работающие на одну группу людей за счёт других.
Акселератор социальных технологических стартапов PhilTech — программа интенсивного развития проектов ранних стадий, направленных на выравнивание доступа к информации, ресурсам и возможностям. Второй поток: март–июнь 2018.
Чат в Telegram
Сообщество людей, развивающих филтех-проекты или просто заинтересованных в теме технологий для социального сектора.
#philtech news
Телеграм-канал с новостями о проектах в идеологии #philtech и ссылками на полезные материалы.
Подписаться на еженедельную рассылку
1. Открытые и копируемые, а не конкурентно-проприетарные.
2. Построенные на принципах самоорганизации и горизонтального взаимодействия.
3. Устойчивые и перспективо-ориентированные, а не преследующие локальную выгоду.
4. Построенные на [открытых] данных, а не традициях и убеждениях
5. Ненасильственные и неманипуляционные.
6. Инклюзивные, и не работающие на одну группу людей за счёт других.
Акселератор социальных технологических стартапов PhilTech — программа интенсивного развития проектов ранних стадий, направленных на выравнивание доступа к информации, ресурсам и возможностям. Второй поток: март–июнь 2018.
Чат в Telegram
Сообщество людей, развивающих филтех-проекты или просто заинтересованных в теме технологий для социального сектора.
#philtech news
Телеграм-канал с новостями о проектах в идеологии #philtech и ссылками на полезные материалы.
Подписаться на еженедельную рассылку
