 Каждый день поступает все больше заказов, и их нужно как-то распределять по исполнителям. Вроде ничего сложного: пришёл заказ – отдай его клинеру. Но не всё так просто, как кажется. У наших клинеров нет фиксированного графика работы, они могут работать, когда захотят, отказываться практически от любых заказов (и это клинеры, увы, делают довольно часто). Поэтому распределение заказов – одна из самых сложных задач, над которой мы работаем.
Каждый день поступает все больше заказов, и их нужно как-то распределять по исполнителям. Вроде ничего сложного: пришёл заказ – отдай его клинеру. Но не всё так просто, как кажется. У наших клинеров нет фиксированного графика работы, они могут работать, когда захотят, отказываться практически от любых заказов (и это клинеры, увы, делают довольно часто). Поэтому распределение заказов – одна из самых сложных задач, над которой мы работаем.ОСНОВНЫЕ ПРОБЛЕМЫ
Одна из самых больших проблем – это ручное распределение. У нас скапливается много заказов, которые нужно оперативно распределить. Откуда берутся эти заказы?
- Клиент может заказать уборку в последний момент, прямо на сегодняшний день.
- Клиент может перенести заказ на любой день.
- Клинер может соскочить с заказа в последний момент.
Такие заказы мы называем “горящие”. Их бывает достаточно много, и надеяться на то, что клинеры разберут их в приложении не стоит. Поэтому мы распределяем их вручную. Сотрудники колл-центра обзванивают клинеров и предлагают им заказы. Это трудоемкий процесс, требующий времени и ресурсов.
В день распределяется от 50 заказов вручную, в сезон случается и вовсе адище – может быть и 300. Это занимает много времени и ресурсов.
Другая проблема – невыполненные заказы. Каждый день мы не выполняем примерно 2% заказов потому, что не можем или не успеваем найти на них клинеров. Если мы их не выполняем, дарим клиенту бесплатную уборку. Каждый день мы дарим около 20 бесплатных уборок, а в сезон эта цифра может достигать 200-300.
Как мы решаем эти проблемы?
1. Клинерское приложение
Клинеры могут самостоятельно разбирать заказы с помощью приложения, в котором есть лента с заказами на каждый день.
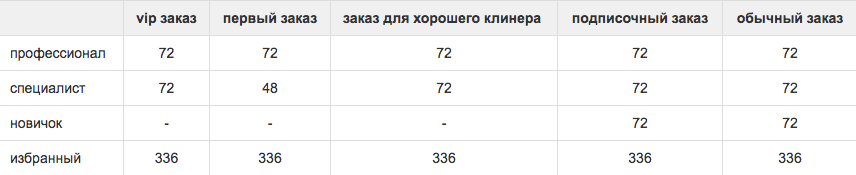
Эти ленты различаются для разных сегментов клинеров. Например, клинеры-новички никогда не увидят заказы наших постоянных клиентов. Эту видимость мы регулируем матрицей. Числа означают, за какое время клинер видит заказ в приложении.
Есть и другие ограничения, мы за ними следим, и каждое из них влияет на наши метрики.
2. Автоназначение
Вместе со стремительным ростом заказов, растет и число “плохих” заказов. “Плохие” – это те, которые в конечном итоге не состоятся или будут отменены. Нам нужно было что-то с этим делать, и поэтому мы решили немного хайпануть и заюзать ML, чтобы предсказать такие заказы.
Особенно мудрить мы не стали. Придумали около 30 различных признаков: время от момента создания заказа, время с последнего заказа, сколько клиент до этого отменял заказов, сколько он принес нам денег за всё время и так далее.
Взяли готовые библиотеки
import numpy as np
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_scoreЗагрузили фичи
features = pd.read_csv('train/train.csv', header = 0)
X = features.drop(['cancel'], axis=1)
y = features.cancelРазделили выборку на обучающую и тестовую
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=1234)Обучили градиентным бустингом
gb_clf = GradientBoostingClassifier(learning_rate=0.2, n_estimators=70, max_depth=3, verbose=False, random_state=241)
gb_clf.fit(X_train, y_train)Проверили на тестовой выборке
y_true = y_test
y_pred = final_gb_clf.predict_proba(X_test)[:,1]
roc_auc=roc_auc_score(y_true, y_pred)roc-auc: 0.881929812245
Сделали прогноз
features = pd.read_csv('predict_features.csv', header = 0, index_col='order_id')
y_predict = gb_clf.predict_proba(features)[:,1]
print(y_pred)Получили неплохую roc-auc = 0.88. И закинули в продакшн.
Теперь каждое утро нам в базу данных падает оценка вероятности отмены заказа.
Экспертным путем мы выбрали пороговое значение для оценки вероятности: 0.7.
Теперь мы активно используем модель в наших бизнес-процессах. Например, такие плохие заказы обзваниваем заранее и у них отдельный флоу в клинерском приложении.
Для разных тестов мы иногда её вырубаем, и это влияет на наши бизнес-метрики.
Например, 7 апреля словили кучу невыполненных заказов, потому что до этого выключили модель.

Решили пойти дальше и распределять заказы автоматически. Но тут же столкнулись с тем, что не знаем, какие клинеры и когда будут работать.
Запилили им расписание. Но, как в итоге оказалось, клинеры в принципе его не соблюдают. А заставлять их – противоречит нашим устоям.
Еще раз заюзали ML. Сделали аналогичную модель, но предсказывающую нам вероятность выхода клинера на работу. Теперь у нас крутятся две модельки, каждый день мы имеем актуальную инфу о заказах и клинерах и можем их распределять.
Алгоритм
Ищем заказы, которые нужно распределить, вычищаем из них “плохие” c помощью полученной оценки вероятности отмены. Подбираем потом на каждый заказ клинеров. Сначала тех, которых хочет видеть клиент – избранных – и назначаем их на заказ. Если все они заняты, то подбираем других клинеров, которые уже были у клиента, но просто не были никак оценены. Если и они заняты, просто ищем ближайшего свободного клинера.
Результаты
Мы ожидали существенного снижения ручного распределения и нам удалось его снизить в два раза. Также мы думали, что автоназначение снизит нам процент невыполненных заказов, но этого не произошло, так как основной вклад в решение этой задачи внесла модель оценки вероятности отмены заказы.
Выводы
Не бойтесь использовать ML в своих задачах — сделать простую модель не составляет труда. На написание моделей у нас ушло всего пару дней работы одного аналитика. Зато теперь мы можем использовать её в наших бизнес-процессах.
Задавайте вопросы в комментариях, будем рады на них ответить.
