Продолжаем цикл наших статей «SOC for beginners». В прошлый раз мы говорили о том, как внедрить в компании Threat Intelligence и не пожалеть. Сегодня хотелось бы поговорить о том, как организовать процессы, чтобы обеспечить непрерывный мониторинг инцидентов и оперативное реагирование на атаки.
В первом полугодии 2017 г. совокупный среднесуточный поток событий ИБ, обрабатываемых SIEM-системами и используемых Solar JSOC для оказания сервиса, составлял 6,156 миллиардов. Событий с подозрением на инцидент – в среднем около 960 в сутки. Каждый шестой инцидент – критичный. При этом для наших клиентов, в числе которых «Тинькофф Банк», «СТС Медиа» или «Почта Банк», вопрос оперативности информирования об атаке и получения рекомендаций по противодействию стоит очень остро.
Мы решили рассказать, как мы решали эту задачу, с какими проблемами столкнулись, и какой метод организации работы в итоге используем.

Формирование команды
Очевидно, что для успешного управления инцидентами необходимо создать нечто вроде диспетчерской службы, которая будет координировать устранение инцидентов и служить единой точкой контакта с заказчиком.
Для разграничения обязанностей и ответственности внутри службы мы разбили ее на несколько уровней, которые со временем масштабировались в соответствии с новыми задачами. После многочисленных попыток и подходов к снаряду у нас получилась следующая картина:
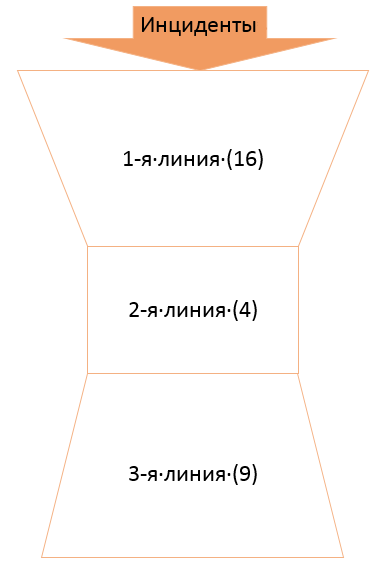
Первая линия Solar JSOC – это инженеры мониторинга, которые отвечают за своевременную реакцию на возникший инцидент и его анализ, фильтрацию ложных срабатываний, а также за подготовку аналитической справки по всем типизированным инцидентам. Своевременной считается реакция, соответствующая требованиям SLA. Первая линия работает посменно, чтобы обеспечить реагирование и разбор инцидентов в режиме 24х7.
Вторая линия – это инженеры реагирования, специалисты по конкретным продуктам и направлениям ИБ, на которых падают нетиповые инциденты в соответствии с областью их экспертизы.
Обычно служба Service Desk имеет структуру «перевернутой пирамиды», а у нас, как видите, получились «песочные часы». Дело в том, что с третьей линией возникла несколько нетипичная история. Третью линию составляют аналитики, закрепленные за конкретными заказчиками и владеющие наиболее полной информацией по их инфраструктуре и внутренним процессам. Эскалация на них происходит в следующих ситуациях:
Для обеспечения мониторинга в режиме 24x7 на ночь, выходные и праздники выделяется дежурный аналитик. Так вот, оказалось, что при росте числа заказчиков и масштабировании сервиса в первую очередь растет необходимость именно в аналитиках.
Особняком стоит команда специалистов по форензике и реверс-инжинирингу вредоносного ПО. Они подключаются, если инцидент связан с вирусным заражением или атакой с проникновением.
Чтобы оставаться эффективным, сервис центра мониторинга должен постоянно развиваться. Например, качество мониторинга сильно зависит от контента SIEM-системы, поэтому необходимо постоянно разрабатывать новые сценарии выявления инцидентов и оптимизировать существующие. Помимо этого, надо оставаться в курсе новых технологий и оценивать возможные преимущества от их применения в рамках сервиса. Например, ретроспективный анализ индикаторов компрометации средствами SIEM занимает слишком много времени, и необходимо найти инструмент, который выполнит эту задачу быстрее. Мы создали отдельную группу, которая состоит из трех человек и занимается исключительно развитием сервиса.
Важно уточнить, что контент необходимо адаптировать под каждого Заказчика: донастроить правила, чтобы снизить количество ложных срабатываний, собрать профиль подключений по новому сегменту и т.п. С таким объемом работ выделенная группа уже не справится, поэтому исполнителями данной задачи мы назначили аналитиков из третьей линии, которые досконально изучили особенности своих заказчиков и знают, где и что у них болит.
Разобравшись с внутренней структурой, мы стали выстраивать процессы взаимодействия с заказчиками помимо коммуникаций в рамках расследования инцидентов. Другими словами, нужно было выстроить SLA management, который позволил бы контролировать уровень сервиса и удовлетворенность заказчика. На этом этапе возникла роль еще одна группа специалистов – сервис-менеджеры, которые занимаются контролем параметров качества услуги, заранее прописанных в договоре. Эти параметры всегда должны быть измеримыми, то есть представимыми в виде числовых метрик.
Вот какие метрики для контроля качества сервиса мониторинга выбрали мы:
В процессе оказания сервиса помимо непосредственно мониторинга инцидентов выявились еще две достаточно часто встречающиеся активности – подключение нового источника событий и запуск/доработка сценария выявления инцидента. Чтобы поставить на контроль данные операции мы завели две новые метрики:
Ну, и последняя метрика касается доступности сервиса. Для упрощения контроля мы объединили совокупность показателей доступности всех технических средств, задействованных в оказании сервиса, в один – доступность платформы.
Посмотрим, что за команду мы в итоге собрали:





Первые проблемы
Казалось бы, процессы регламентировали, роли расписаны, взаимодействие налажено, пора в бой. Но, запустив сервис и подключив первых заказчиков, мы начали сталкиваться с валом проблем. Поскольку весь поток инцидентов сваливается сначала на первую линию, трудности начали проявляться именно с ней.
Первая линия в любом случае имеет квалификацию ниже остальных и работает в режиме 24х7. В таких условиях всегда есть риск ошибки: например, закрытие боевого инцидента как false positive. Если это приведет к серьезным последствиям для заказчика, никто не будет искать виновного, и репутационный ущерб ляжет на всю команду.
Отсюда важный вопрос: как проконтролировать качество разбора и анализа кейсов? При желании упростить себе жизнь специалист может выбрать инцидент попроще или ближе к той теме, в которой он лучше разбирается. При таком подходе может появиться “нежеланный” инцидент, который никто не захочет взять, и он потихоньку уплывет за границы SLA, станет просроченным, а то и вовсе не будет разобран.
Следующий риск относится только к коммерческим центрам мониторинга. Оператор вынужден обрабатывать сплошной поток алертов, приходящих от большого количества заказчиков, и может в суматохе оправить ответ не по адресу. Каковы последствия, думаю, пояснять не требуется.
А что делать, если нагрузка возросла, и первая линия начинает тонуть под потоком инцидентов?
Что ж, начнем по порядку:
Для облегчения работы первой линии мы разработали подробные инструкции и правила обработки всех типовых инцидентов. В инструкции описаны:

Инструкции сильно помогают инженеру соблюдать SLA по инцидентам и быстро принимать решение о том, стоит ли эскалировать кейс дальше или можно справиться собственными силами.
Чтобы решить вопрос контроля работы первой линии, мы разработали систему оценки отработанных кейсов, включающую в себя более десятка категорий. Например, информативность оповещения, корректность анализа и заполнения карточки инцидента и т.д.
В обязанности каждого аналитика третьей линии входит еженедельный обзор нескольких десятков инцидентов, разобранных первой линией. По результатам обзора аналитик может высказать свои замечания по проработке вышеуказанных категорий. Чтобы обзор был максимально полезным, мы разработали четкие критерии выбора кейсов:
Краткое ревью может выглядеть следующим образом:
Результаты оценок учитываются в мотивационной схеме первой линии как в положительную, так и в отрицательную сторону. Такое решение проблемы, безусловно, является весьма затратным. Однако для нас это оптимальный вариант, т.к. последствия пропущенного инцидента обойдутся нам гораздо дороже. Также практикуются публичные разборы некорректно обработанных инцидентов, чтобы допущенные ошибки больше не повторялись.
Чтобы не возникал соблазн выбрать инцидент попроще, мы лишили инженеров первой линии возможности выбирать кейс для разбора. За него решает скоринговая система, которая распределяет каждый инцидент в одну из трех зон: зеленую, желтую или красную. Распределение происходит с учетом 5 показателей:
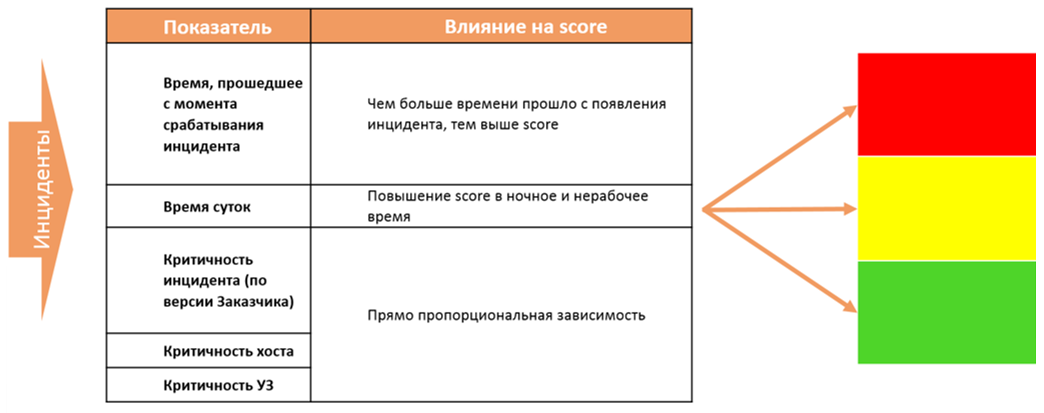
В итоге свободный инженер автоматически получает инцидент с наибольшим score.
Риск отправки ответа не по адресу мы минимизировали благодаря тому, что оператор не работает непосредственно с электронной почтой. Для автоматизации работы службы мониторинга мы выбрали HelpDesk-систему Kayako, адаптировали ее под нашу специфику, интегрировали с почтой и посадили за нее службу мониторинга. При отправке ответа срабатывают преднастроенные профили уведомления, в которых прописаны маршруты на соответствующих специалистов заказчика. Для того чтобы можно было проанализировать инцидент, в тикете прикрепляется ссылка на него в консоли SIEM-системы.

Нагрузку мы прогнозируем, отталкиваясь от текущей загрузки смены, планового времени решения и плотности потока входящих алертов. Тут мы опять используем распределение по зонам: если накопилось много «красных» инцидентов, значит, пора тушить пожар всеми доступными силами. В случае необходимости к первичному разбору кейсов подключаются специалисты 2-ой линии, или в критической ситуации – дежурный аналитик.
Что в итоге
Конечно же это не все проблемы, которое встретились на нашем пути, и не все из них нам удалось до конца решить. Например, вот несколько «подвешенных» вопросов: что делать с инцидентом, если заказчик не предоставил на него обратной связи? Надо ли закрыть его через день или оставить в неизменном состоянии до получения ответа? Что делать, если заказчик отчитался об устранении инцидента, а через день он возникает вновь? Или от заказчика нет обратной связи, а инцидент возникает ежедневно?
Но, тем не менее, пройденный путь и результаты позволяют сказать, что мы достигли достаточно высокого уровня зрелости в организации процессов.
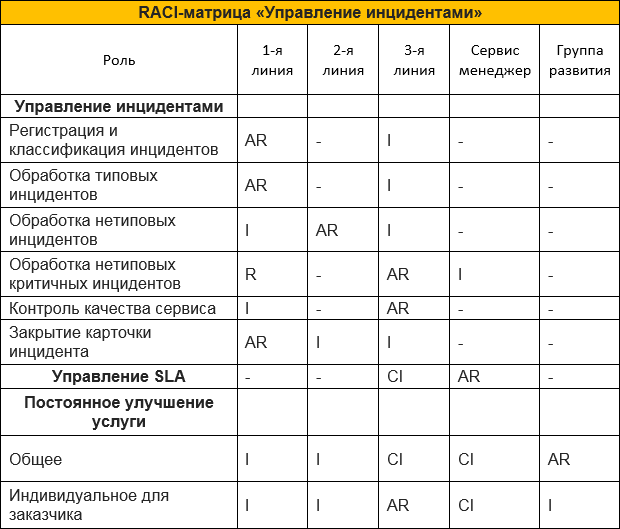
В качестве итога попробуем наложить все описанные роли и задачи на RACI-матрицу распределения ответственности. Сразу оговоримся, что эта таблица описывает только маленький кусочек задач и ответственности SOC (если честно, целиком она слишком огромная и страшная, чтобы публиковать ее в статье):
Построение SOC – это долгий путь, на котором можно собрать массу разнообразных граблей, даже не подступившись к техническим аспектам. Надеюсь, мне удалось указать на некоторые из них и предложить пути обхода. К сожалению, гарантировать, что вы не встретите уникальные для вас проблемы, я не могу. Но, как мы уже неоднократно говорили, дорогу осилит идущий. Ну, и готовьте лоб :).
В первом полугодии 2017 г. совокупный среднесуточный поток событий ИБ, обрабатываемых SIEM-системами и используемых Solar JSOC для оказания сервиса, составлял 6,156 миллиардов. Событий с подозрением на инцидент – в среднем около 960 в сутки. Каждый шестой инцидент – критичный. При этом для наших клиентов, в числе которых «Тинькофф Банк», «СТС Медиа» или «Почта Банк», вопрос оперативности информирования об атаке и получения рекомендаций по противодействию стоит очень остро.
Мы решили рассказать, как мы решали эту задачу, с какими проблемами столкнулись, и какой метод организации работы в итоге используем.
Формирование команды
Очевидно, что для успешного управления инцидентами необходимо создать нечто вроде диспетчерской службы, которая будет координировать устранение инцидентов и служить единой точкой контакта с заказчиком.
Для разграничения обязанностей и ответственности внутри службы мы разбили ее на несколько уровней, которые со временем масштабировались в соответствии с новыми задачами. После многочисленных попыток и подходов к снаряду у нас получилась следующая картина:
Первая линия Solar JSOC – это инженеры мониторинга, которые отвечают за своевременную реакцию на возникший инцидент и его анализ, фильтрацию ложных срабатываний, а также за подготовку аналитической справки по всем типизированным инцидентам. Своевременной считается реакция, соответствующая требованиям SLA. Первая линия работает посменно, чтобы обеспечить реагирование и разбор инцидентов в режиме 24х7.
Вторая линия – это инженеры реагирования, специалисты по конкретным продуктам и направлениям ИБ, на которых падают нетиповые инциденты в соответствии с областью их экспертизы.
Обычно служба Service Desk имеет структуру «перевернутой пирамиды», а у нас, как видите, получились «песочные часы». Дело в том, что с третьей линией возникла несколько нетипичная история. Третью линию составляют аналитики, закрепленные за конкретными заказчиками и владеющие наиболее полной информацией по их инфраструктуре и внутренним процессам. Эскалация на них происходит в следующих ситуациях:
- Анализ аномальных активностей с целью выявления инцидентов.
- Реагирование на нетиповые критичные инциденты своих заказчиков.
- Участие в расследовании инцидентов ИБ, не зафиксированных мониторингом.
- Также аналитики занимаются техническим обследованием, подключением и адаптацией настроек источников.
Для обеспечения мониторинга в режиме 24x7 на ночь, выходные и праздники выделяется дежурный аналитик. Так вот, оказалось, что при росте числа заказчиков и масштабировании сервиса в первую очередь растет необходимость именно в аналитиках.
Особняком стоит команда специалистов по форензике и реверс-инжинирингу вредоносного ПО. Они подключаются, если инцидент связан с вирусным заражением или атакой с проникновением.
Чтобы оставаться эффективным, сервис центра мониторинга должен постоянно развиваться. Например, качество мониторинга сильно зависит от контента SIEM-системы, поэтому необходимо постоянно разрабатывать новые сценарии выявления инцидентов и оптимизировать существующие. Помимо этого, надо оставаться в курсе новых технологий и оценивать возможные преимущества от их применения в рамках сервиса. Например, ретроспективный анализ индикаторов компрометации средствами SIEM занимает слишком много времени, и необходимо найти инструмент, который выполнит эту задачу быстрее. Мы создали отдельную группу, которая состоит из трех человек и занимается исключительно развитием сервиса.
Важно уточнить, что контент необходимо адаптировать под каждого Заказчика: донастроить правила, чтобы снизить количество ложных срабатываний, собрать профиль подключений по новому сегменту и т.п. С таким объемом работ выделенная группа уже не справится, поэтому исполнителями данной задачи мы назначили аналитиков из третьей линии, которые досконально изучили особенности своих заказчиков и знают, где и что у них болит.
Разобравшись с внутренней структурой, мы стали выстраивать процессы взаимодействия с заказчиками помимо коммуникаций в рамках расследования инцидентов. Другими словами, нужно было выстроить SLA management, который позволил бы контролировать уровень сервиса и удовлетворенность заказчика. На этом этапе возникла роль еще одна группа специалистов – сервис-менеджеры, которые занимаются контролем параметров качества услуги, заранее прописанных в договоре. Эти параметры всегда должны быть измеримыми, то есть представимыми в виде числовых метрик.
Вот какие метрики для контроля качества сервиса мониторинга выбрали мы:
- Время реакции на инцидент с момента его фиксации – время, прошедшее с момента поступления и регистрации запроса до момента начала работ. Этот показатель отражает то, как быстро мы обязуемся обрабатывать поток входящих алертов. В нашем случае это 20 минут для критичных инцидентов.
- Время анализа и подготовки аналитической справки по инциденту – время, прошедшее с момента фактического начала работ над проблемой до закрытия заявки. Тут все просто – Заказчик должен понимать, как быстро мы сможем проанализировать ситуацию и дать рекомендации по противодействию. Наш SLA подразумевает, что это время не должно превышать 60 минут для рядового инцидента и 40 – для критичного.
В процессе оказания сервиса помимо непосредственно мониторинга инцидентов выявились еще две достаточно часто встречающиеся активности – подключение нового источника событий и запуск/доработка сценария выявления инцидента. Чтобы поставить на контроль данные операции мы завели две новые метрики:
- Время выполнения работ по подключению новых типовых источников. Наш стандарт – 24 часа.
- Время выполнения запроса на доработку сценария. В соответствии с SLA мы должны решать эту задачу за 72 часа.
Ну, и последняя метрика касается доступности сервиса. Для упрощения контроля мы объединили совокупность показателей доступности всех технических средств, задействованных в оказании сервиса, в один – доступность платформы.
Посмотрим, что за команду мы в итоге собрали:
Первые проблемы
Казалось бы, процессы регламентировали, роли расписаны, взаимодействие налажено, пора в бой. Но, запустив сервис и подключив первых заказчиков, мы начали сталкиваться с валом проблем. Поскольку весь поток инцидентов сваливается сначала на первую линию, трудности начали проявляться именно с ней.
Первая линия в любом случае имеет квалификацию ниже остальных и работает в режиме 24х7. В таких условиях всегда есть риск ошибки: например, закрытие боевого инцидента как false positive. Если это приведет к серьезным последствиям для заказчика, никто не будет искать виновного, и репутационный ущерб ляжет на всю команду.
Отсюда важный вопрос: как проконтролировать качество разбора и анализа кейсов? При желании упростить себе жизнь специалист может выбрать инцидент попроще или ближе к той теме, в которой он лучше разбирается. При таком подходе может появиться “нежеланный” инцидент, который никто не захочет взять, и он потихоньку уплывет за границы SLA, станет просроченным, а то и вовсе не будет разобран.
Следующий риск относится только к коммерческим центрам мониторинга. Оператор вынужден обрабатывать сплошной поток алертов, приходящих от большого количества заказчиков, и может в суматохе оправить ответ не по адресу. Каковы последствия, думаю, пояснять не требуется.
А что делать, если нагрузка возросла, и первая линия начинает тонуть под потоком инцидентов?
Что ж, начнем по порядку:
Для облегчения работы первой линии мы разработали подробные инструкции и правила обработки всех типовых инцидентов. В инструкции описаны:
- Базовая информация по инциденту (цель, источники событий, название).
- Логика срабатывания.
- Признаки ложного срабатывания.
- Возможные последствия инцидента.
- Рекомендации по противодействию и т.д.
Инструкции сильно помогают инженеру соблюдать SLA по инцидентам и быстро принимать решение о том, стоит ли эскалировать кейс дальше или можно справиться собственными силами.
Чтобы решить вопрос контроля работы первой линии, мы разработали систему оценки отработанных кейсов, включающую в себя более десятка категорий. Например, информативность оповещения, корректность анализа и заполнения карточки инцидента и т.д.
В обязанности каждого аналитика третьей линии входит еженедельный обзор нескольких десятков инцидентов, разобранных первой линией. По результатам обзора аналитик может высказать свои замечания по проработке вышеуказанных категорий. Чтобы обзор был максимально полезным, мы разработали четкие критерии выбора кейсов:
- Инциденты высокой критичности.
- Инциденты, связанные с критичными источниками (например, банковский АРМ КБР и похожие высококритичные АРМ).
- Инциденты профилирования (в случае, если не отнесены к первым двум категориям).
- Сработки по фидам Threat Intelligence.
- Новые сценарии инцидентов (менее 1 месяца с момента запуска в первую линию).
Краткое ревью может выглядеть следующим образом:
Результаты оценок учитываются в мотивационной схеме первой линии как в положительную, так и в отрицательную сторону. Такое решение проблемы, безусловно, является весьма затратным. Однако для нас это оптимальный вариант, т.к. последствия пропущенного инцидента обойдутся нам гораздо дороже. Также практикуются публичные разборы некорректно обработанных инцидентов, чтобы допущенные ошибки больше не повторялись.
Чтобы не возникал соблазн выбрать инцидент попроще, мы лишили инженеров первой линии возможности выбирать кейс для разбора. За него решает скоринговая система, которая распределяет каждый инцидент в одну из трех зон: зеленую, желтую или красную. Распределение происходит с учетом 5 показателей:
В итоге свободный инженер автоматически получает инцидент с наибольшим score.
Риск отправки ответа не по адресу мы минимизировали благодаря тому, что оператор не работает непосредственно с электронной почтой. Для автоматизации работы службы мониторинга мы выбрали HelpDesk-систему Kayako, адаптировали ее под нашу специфику, интегрировали с почтой и посадили за нее службу мониторинга. При отправке ответа срабатывают преднастроенные профили уведомления, в которых прописаны маршруты на соответствующих специалистов заказчика. Для того чтобы можно было проанализировать инцидент, в тикете прикрепляется ссылка на него в консоли SIEM-системы.
Нагрузку мы прогнозируем, отталкиваясь от текущей загрузки смены, планового времени решения и плотности потока входящих алертов. Тут мы опять используем распределение по зонам: если накопилось много «красных» инцидентов, значит, пора тушить пожар всеми доступными силами. В случае необходимости к первичному разбору кейсов подключаются специалисты 2-ой линии, или в критической ситуации – дежурный аналитик.
Что в итоге
Конечно же это не все проблемы, которое встретились на нашем пути, и не все из них нам удалось до конца решить. Например, вот несколько «подвешенных» вопросов: что делать с инцидентом, если заказчик не предоставил на него обратной связи? Надо ли закрыть его через день или оставить в неизменном состоянии до получения ответа? Что делать, если заказчик отчитался об устранении инцидента, а через день он возникает вновь? Или от заказчика нет обратной связи, а инцидент возникает ежедневно?
Но, тем не менее, пройденный путь и результаты позволяют сказать, что мы достигли достаточно высокого уровня зрелости в организации процессов.
В качестве итога попробуем наложить все описанные роли и задачи на RACI-матрицу распределения ответственности. Сразу оговоримся, что эта таблица описывает только маленький кусочек задач и ответственности SOC (если честно, целиком она слишком огромная и страшная, чтобы публиковать ее в статье):
Построение SOC – это долгий путь, на котором можно собрать массу разнообразных граблей, даже не подступившись к техническим аспектам. Надеюсь, мне удалось указать на некоторые из них и предложить пути обхода. К сожалению, гарантировать, что вы не встретите уникальные для вас проблемы, я не могу. Но, как мы уже неоднократно говорили, дорогу осилит идущий. Ну, и готовьте лоб :).
