Node.js — вещь, вокруг которой сейчас много шума, восторженных отзывов и гневливых выкриков. При этом, по моим наблюдениям, в умах людей закрепилось следующее представление о том что же такое Node.js: «это штука, позволяющая писать на JavaScript на серверной стороне и использующая JavaScript-движок от Google Chrome». Поклонники языка восторженно вздохнули: «Ах! Сбылось!», противники же процедили сквозь зубы: «Ну вот только еще этой ерунды с прототипами и динамической типизацией нам на серверах не хватало!». И дружно побежали ломать копья в блоги и форумы.
При этом многие представители обоих лагерей придерживаются мнения, что Node.js — это эзотерическая игрушка, веселая задумка для переноса языка браузерных сценариев на «новые колеса». Дабы быть до конца честным, признаюсь, что я так же придерживался подобной точки зрения. В один прекрасный момент, я набрался духу и решил «копнуть поглубже». Выяснилось, что создатель Node.js Райан Дал далеко не фанатик, а человек, пытающийся решить реальную проблему. А его творение — не игрушка, а применимое на практике решение.
Так что же такое Node.js? На официальном сайте красуется надпись: «Evented I/O for V8 JavaScript». Не очень то содержательно, верно? Ну что ж, давайте попробуем «изобрести велосипед» и «придумаем» этот самый пресловутый «Evented I/O for V8 JavaScript». Конечно же мы не будем писать никакого кода (бедняге Райану все таки пришлось это делать), а лишь попробуем построить цепочку умозаключений, которые приведут нас к замыслу создания Node.js и тому как он должен быть устроен.
Keep it simple, stupid
Итак, вы знаете, что web-приложения используют клиент-серверную программную модель. Клиентом выступает браузер пользователя, а сервером — например, одна из машин в датацентре некоторого хостера (выберите любого на ваш вкус). Браузер запрашивает какой-то ресурс у сервера, тот, в свою очередь, его отдает клиенту. Такой способ общения клиента и сервера называется «client pull», т. к. клиент буквально дергает (англ. pull) сервер — «Дай-ка мне вон ту страничку, ну дай...». Сервер «обдумывает» ответ на вопрос назойливого клиента и отдает ему его в удобоваримом виде.
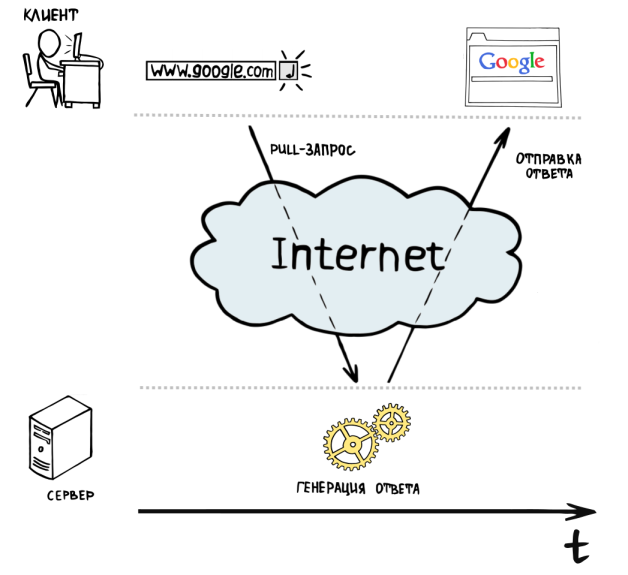
Итак, у нас есть модель простейшего веб-сервера — программа, которая принимает запросы от клиентов-браузеров, обрабатывает их и возвращает ответ.
Parallel universe
Здорово, но такой простейший сервер умеет одновременно общаться лишь с одним пользователем. Если в момент обработки запроса к нему обратиться еще один клиент, то ему придется ждать пока сервер ответит первому. Значит нам нужно распараллелить обработку запросов от пользователей. Очевидное решение: обрабатывать запросы пользователей в отдельных потоках или процессах операционной системы. Давайте назовем каждый такой процесс или поток — worker'ом (англ. рабочий).
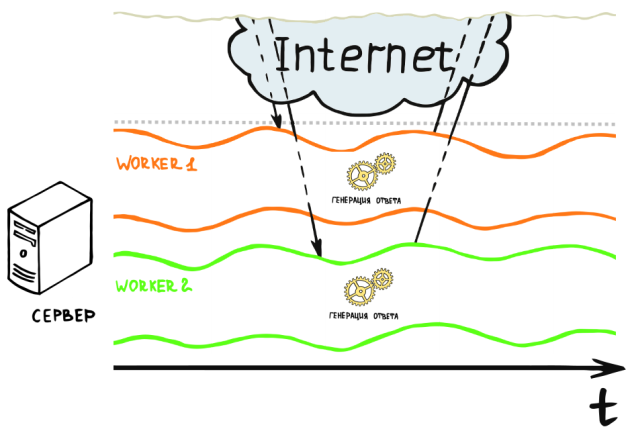
В том или ином виде данного подхода придерживаются многие наиболее популярные сегодня веб-серверы (например, Apache и IIS). Данная модель относительно проста в реализации и при этом может удовлетворить потребности большинства малых и средних веб-ресурсов на сегодняшний день.
Но данная модель совершенно не дееспособна, если вам нужно обрабатывать тысячи запросов одновременно. Причин для этого несколько. Во-первых, создание и процессов и потоков — вещь чертовски накладная для любой операционной системы. Но мы можем пойти на хитрость и создавать потоки или процессы заранее и использовать их по мере надобности. OK, мы только что придумали механизмы под названием «thread pool» для потоков и «prefork» для процессов. Это поможет нам не тратить лишний раз ресурсы на создание процессов и потоков, поскольку эта накладная операция может быть выполнена, например, при запуске сервера. Во-вторых, что делать, если все созданные worker'ы заняты? Создать новые? Но мы и так по полной загрузили все ядра процессора нашего сервера, если мы добавим еще несколько потоков или процессов, то они будут конкурировать за процессорное время с уже исполняющимися потоками и процессами. А значит и те и другие будут работать еще медленней. Да, и как отмечалось ранее, создание и обслуживанием потоков и процессов — вещь затратная в плане потребления оперативной памяти и если мы будем создавать поток для каждого из тысячи пользователей, то вскоре можем оказаться в ситуации, когда памяти на сервере попросту не останется, а worker'ы будут находится в состоянии постоянного соревнования за аппаратные ресурсы.
Бесконечность — не предел!
Казалось бы мы оказались в неразрешимой ситуации при имеющихся у нас вычислительных ресурсах. Единственное решение — масштабирование аппаратных ресурсов, что затратно во всех отношениях. Давайте попробуем взглянуть на проблему с другой стороны: чем же заняты большинство наших worker'ов? Они принимают запрос от клиента, создают ответ и отправляют его клиенту. Так где же тут слабое звено? Их здесь целых два — прием запроса от клиента и отправка ответа. Что бы понять что это так, достаточно всего лишь вспомнить среднюю скорость интернет-соединения на сегодняшний день. Но ведь подсистема ввода/вывода может работать в асинхронном режиме, а следовательно может не блокировать worker'ов. Хм, тогда получается фактически единственное чем будут заниматься наши worker'ы — это генерация ответа для клиента и управление заданиями для подсистемы ввода/вывода. Ранее каждый worker мог обслуживать лишь одного клиента одновременно, т. к. брал на себя обязанности по исполнению всего цикла обработки запроса. Теперь же когда сетевой ввод/вывод мы делегировали подсистеме ввода/вывода, то один worker может одновременно обслуживать несколько запросов, например, генерируя ответ для одного клиента, пока ответ для другого отдается подсистемой ввода/вывода. Получается теперь нам не нужно выделять поток для каждого из пользователей, а мы можем создавать по одному worker'у на процессор сервера, предоставляя ему, таким образом, максимум аппаратных ресурсов.
На практике такое делегирование реализуется с использованием парадигмы событийно-ориентированного программирования. Программы, разработанные согласно данной парадигме могут быть реализованы как конечный автомат. Определенные события переводят данный автомат из одного состояния в другое. В нашем случае сервер будет реализован в виде бесконечного цикла, который будет генерировать ответы для клиентов, опрашивать дескрипторы подсистемы ввода/вывода на предмет их готовности для выполнения той или иной операции, и, в случае успеха, передавать им новое задание. Процесс опроса дескрипторов подсистемы ввода/вывода называется «polling». Дело в том, что эффективные реализации polling'а на сегодняшний день имеются лишь в *nix-системах, т.к. последние предоставляют очень быстрые системные вызовы c линейным временем исполнения для данных целей (например, epoll в Linux и kqueue в BSD-системах). Это очень эффективная модель сервера, т. к. позволяет использовать аппаратные ресурсы по-максимуму. Фактически, ни одна из подсистем сервера не простаивает без дела, в чем можно легко убедиться посмотрев на рисунок.
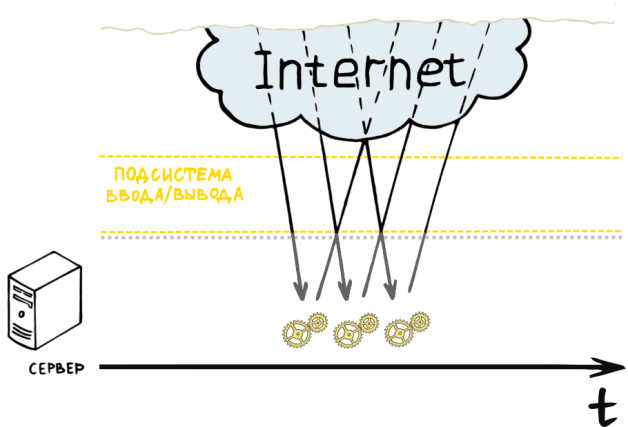
Подобную концепцию используют такие серверы, как nginx и lightppd, отлично зарекомендовавшие себя в высоконагруженных системах.
Let's come together
Но (всегда же есть «одно но»), до этого мы отталкивались от идеи, что генерация ответа занимает на порядок меньше времени чем общение с клиентом. И это отчасти верно. Тем не менее, генерация ответа порою может быть сложной и комплексной задачей, которая может включать в себя чтение и запись на диск, работу с базой данных (которая так же может находиться на удаленном сервере). Что же, получается мы фактически вновь вернулись к исходной проблеме. На практике она разрешается следующим образом: система разбивается на две части — front-end и back-end. Front-end — это сервер, с которым непосредственно общается клиент. Как правило это сервер с асинхронной событийной моделью, который умеет быстро устанавливать связь с клиентами и отдавать им результаты запроса (например, nginx). Back-end — это сервер с блокирующей моделью ввода/вывода (например, Apache), которому front-end делегирует создание ответа для клиента, точно так же как он это делает с подсистемой ввода/вывода. Подобный front-end так же называют «reverse proxy», т. к. по сути это обычный proxy-сервер, но установленный в том же серверном окружении, что и сервер, к которому он перенаправляет запросы.
Если проводить аналогии с реальной жизнью, то front-end — это менеджер с блестящими от белизны зубами и в дорогом костюме, back-end — группа рабочих на заводе, а подсистема ввода/вывода — транспортный отдел компании, на которую работает менеджер и которой принадлежит завод. Клиенты обращаются к менеджеру, отправляя ему письма через транспортный отдел. Менеджер заключает сделку с клиентом на поставку партии изделий и направляет указание рабочим изготовить партию. Сам менеджер, в свою очередь, не ожидает пока рабочие закончат исполнение заказа, а продолжает заниматься своими непосредственными обязанностями — заключает сделки с клиентами и следит за тем, что бы весь процесс происходил согласованно и ладно. Периодически менеджер связывается с рабочими что бы осведомиться о степени готовности заказа, и, если партия готова, то дает указание транспортному отделу отправить заказ клиенту. Ну и, естественно, периодически следит, что бы товар дошел до клиента. Вот так придуманная тысячи лет назад идея разделения труда нашла неожиданное применение в высоких технологиях.
И жнец, и швец, и на дуде игрец (казалось бы, причем тут JavaScript?)
Что же, все это прекрасно работает, но как то наша система чрезвычайно усложнилась, не находите? Да, хоть мы и делегируем генерацию ответа другому серверу, это все равно не самый быстрый процесс, т. к. в ходе него могут происходить блокировки из-за файлового ввода/вывода и работы с базой данных, что неминуемо приводит к простою процессора. Так как же нам вернуть системе целостность и при этом ликвидировать узкие места в процессе генерации ответа? Элементарно, Ватсон — сделаем весь ввод/вывод и работу с базой данных неблокирующими, построенными на событиях (да-да, то самое evented I/O)!
«Но это же меняет всю парадигму создания веб-приложений, и большинство имеющихся framework'ов уже не применимы или применимы, но решения с их использованием не элегантны!» — скажите вы и будете правы. Да, и нельзя исключать человеческий фактор — применяя закон Мерфи можно утверждать, что «если имеется возможность использовать функции блокирующего ввода/вывода, то кто-нибудь рано или поздно это сделает», поломав таким образом всю первоначальную задумку. Это лишь вопрос времени, объемов проекта и квалификации программистов. «Be careful making abstractions. You might have to use them.» (англ. «Будьте осторожны в создании абстракций, ведь, возможно, вам придется их использовать») — говорит Райан в своем выступлении на Google Tech Talk. Так давайте будем придерживаться минимализма и создадим лишь фундамент, который позволит нам разрабатывать веб-приложения и при этом будет настолько хорошо заточен под асинхронную модель программирования, что у нас не будет возможности, а главное — желания, от нее отступить. Так какой же минимум нам нужен?
Очевидно, что для начала нам нужна исполняющая среда, основные требования к которой — быстрое исполнение кода генерации ответа и асинхронный ввод/вывод. Какой современный язык программирования заточен под событийную модель, известен всем веб-разработчикам и при этом имеет быстрые и активно развивающиеся реализации? Ответ очевиден — это JavaScript. Более того у нас в распоряжении есть JavaScript-движок V8 от Google, распространяемый под очень либеральной BSD-лицензией. V8 прекрасен во многих аспектах: во-первых, он использует JIT-компиляцию и множество других приемов оптимизации, а во-вторых, это образец добротно сделанного, продуманного и активно-развивающегося программного продукта (обычно я привожу V8 в качестве примера по-настоящему качественного кода на C++ для коллег на работе). Добавим ко всему этому библиотеку libev, которая позволит нам легко организовать событийный цикл и предоставит более высокоуровневую обертку для механизмов polling'а (так что нам не придется заботиться об особенностях его реализации для различных операционных систем). Так же нам понадобится библиотека libeio для быстрого асинхронного файлового ввода/вывода. Отлично, на этом нашу исполняющую среду можно считать готовой.
И, конечно же, нам нужна стандартная библиотека, которая будет содержать JavaScript-обертки для всех базовых операций ввода/вывода и функций, без которых в веб-разработке далеко не уйдешь (например, парсинг HTTP-заголовков и URL, подсчет хэшей, DNS-резолвинг и т. д.).
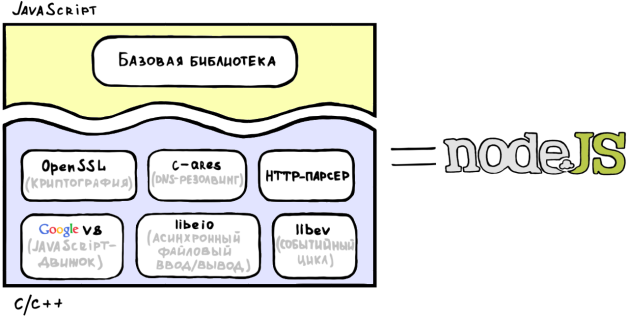
Наверное, стоит нас поздравить — мы только что придумали концепцию очень быстрого сервера — Node.js.
I'm just sayin'
Резюмируя, хочется сказать, что Node.js – это очень молодой проект, который при правильном использовании может в свое время произвести революцию в мире веб-разработки. Сегодня у проекта есть ряд еще нерешенных проблем, осложняющих его использование в реальных высоконагруженных системах (хотя уже имеются прецеденты). Например, Node.js представляет собой по сути лишь один worker. Если у вас, допустим, двухядерный процессор, то единственный способ по полной использовать его аппаратные ресурсы с Node.js — это запустить два экземпляра сервера (по одному на каждое ядро) и использовать reverse proxy (например, тот же nginx) для балансировки нагрузки между ними.
Но, все подобные проблемы разрешимы и над ними ведется активная работа, а вокруг Node.js уже строится огромное коммьюнити и многие крупные компании уделяют немалое внимание данной разработке. Остается лишь пожелать мистеру Далу довести его дело до конца (в чем, кстати, можно ему помочь), а тебе, дорогой читатель, — провести много приятного времени за разработкой под Node.js.
