Вчера я шёл куда-то по городу и вдруг задумался, как можно реализовать на JavaScript деление строки по символам при помощи регулярного выражения и с полным учётом Юникода.
После перехода от Perl к JavaScript много лет тому назад, я всё испытывал за свой новый язык некоторый комплекс неполноценности из-за недостаточной поддержки Юникода. За всё то время, пока JavaScript совершал в этом направлении свой большой скачок (при переходе от ES5 к ES6), у меня в закладках осталось несколько хороших статей.
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
JavaScript has a Unicode problem
Unicode-aware regular expressions in ECMAScript 6
ES6 Strings (and Unicode, ) in Depth
В последней из них предлагался рецепт разбиения строки на символы с учётом Юникода при помощи нового оператора

И вот я вчера задумался, можно ли реализовать то же самое при помощи новых регулярных выражений. В голову пришла простая идея, которая на поверку оказалась верна:
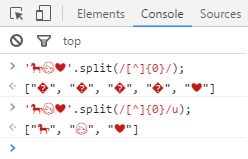
Сегодня я внезапно понял, что вчера как раз был день рождения Далай-ламы. Поэтому мне показалось, что завершить эту заметку можно небольшой шуткой на JavaScript в честь виновника торжества.

P.S. Попробовал сравнить по скорости оба метода:
Node.js 6.3.0
Google Chrome Canary 54.0.2790.0
Firefox Nightly 50.0a1
В V8 выигрывает регулярное выражение (быстрее в два раза и более), в SpiderMonkey выигрывает оператор spread (ненамного).
P.P.S. Вместо
После перехода от Perl к JavaScript много лет тому назад, я всё испытывал за свой новый язык некоторый комплекс неполноценности из-за недостаточной поддержки Юникода. За всё то время, пока JavaScript совершал в этом направлении свой большой скачок (при переходе от ES5 к ES6), у меня в закладках осталось несколько хороших статей.
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
JavaScript has a Unicode problem
Unicode-aware regular expressions in ECMAScript 6
ES6 Strings (and Unicode, ) in Depth
В последней из них предлагался рецепт разбиения строки на символы с учётом Юникода при помощи нового оператора
... Например (хабровский парсер не даёт почему-то ввести этот пример кодом, скрывая символы выше BMP):И вот я вчера задумался, можно ли реализовать то же самое при помощи новых регулярных выражений. В голову пришла простая идея, которая на поверку оказалась верна:
Сегодня я внезапно понял, что вчера как раз был день рождения Далай-ламы. Поэтому мне показалось, что завершить эту заметку можно небольшой шуткой на JavaScript в честь виновника торжества.
const nothingness = /[^]{0}/; const nothing = ''; console.log(nothing.search(nothingness)); // 0 console.log(nothing.match(nothingness)); // [ '', index: 0, input: '' ] console.log(nothing.split(nothingness)); // [] console.log(nothing.replace(nothingness, nothing)); // '' console.log(nothingness.test(nothing)); // true
P.S. Попробовал сравнить по скорости оба метода:
1. Node.js
/******************************************************************************/ 'use strict'; /******************************************************************************/ const str = '\ud83d\udc0e'.repeat(1000); const re = /[^]{0}/u; let symbols; let hrStart; let hrEnd; let i; /******************************************************************************/ hrStart = process.hrtime(); i = 100000; while (i-- > 0) symbols = [...str]; hrEnd = process.hrtime(hrStart); console.log( `${symbols.length} symbols via spread: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s` ); /******************************************************************************/ hrStart = process.hrtime(); i = 100000; while (i-- > 0) symbols = str.split(re); hrEnd = process.hrtime(hrStart); console.log( `${symbols.length} symbols via regexp: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s` ); /******************************************************************************/
2. Браузеры
/******************************************************************************/ 'use strict'; /******************************************************************************/ const str = '\ud83d\udc0e'.repeat(1000); const re = /[^]{0}/u; let symbols; let pStart; let i; /******************************************************************************/ pStart = performance.now(); i = 100000; while (i-- > 0) symbols = [...str]; console.log( `${symbols.length} symbols via spread: ${(performance.now() - pStart) / 1e3} s` ); /******************************************************************************/ pStart = performance.now(); i = 100000; while (i-- > 0) symbols = str.split(re); console.log( `${symbols.length} symbols via regexp: ${(performance.now() - pStart) / 1e3} s` ); /******************************************************************************/
Node.js 6.3.0
1000 symbols via spread: 28.284130503 s
1000 symbols via regexp: 14.887705856 sGoogle Chrome Canary 54.0.2790.0
1000 symbols via spread: 36.575210000000006 s
1000 symbols via regexp: 15.550919999999998 sFirefox Nightly 50.0a1
1000 symbols via spread: 20.392635000000002 s
1000 symbols via regexp: 26.935885000000003 sВ V8 выигрывает регулярное выражение (быстрее в два раза и более), в SpiderMonkey выигрывает оператор spread (ненамного).
P.P.S. Вместо
/[^]{0}/u можно использовать new RegExp('', 'u')