 В первой части я утверждал, что пришло время подумать, как заменить современную веб-платформу для приложений. Причины — её низкая производительность и в принципе нерешаемые проблемы безопасности.
В первой части я утверждал, что пришло время подумать, как заменить современную веб-платформу для приложений. Причины — её низкая производительность и в принципе нерешаемые проблемы безопасности.Кое-кто решил, что я пишу слишком в негативном ключе и не обращаю внимания на положительные стороны веба. Так и есть: первая часть была в стиле «Обсудим факт, что мы попали в глубокую яму», а вторая часть — «Как разработать кое-что получше?» Это огромная тема, так что она на самом деле двумя частями не ограничится.
Назовём нашего конкурента вебу NewWeb (э, брендингом можно заняться потом). Для начала нужно понять, почему веб изначально стал успешным. Веб обошёл другие технологии создания приложений с лучшими инструментами для разработки GUI, так что у него явно есть какие-то качества, которые перевешивают недостатки. Если мы не будем соответствовать этим качествам, мы обречены.
Создание GUI в Matisse, редакторе UI с автоматическим выравниванием и ограничителями. Да здравствует (новый стильный) король?
Нужно также сконцентрироваться на дешевизне. У веба многочисленные группы разработчиков. Бóльшая часть их работы дублируется или выбрасывается, кое-что можно использовать повторно. Возможна и новая разработка в небольшом объёме… но по большому счёту любую технологию NewWeb придётся собирать из кусочков существующего программного обеспечения. Беднякам не приходится выбирать.
Вот мой личный список пяти главных свойств веба:
- Развёртывание и изоляция в песочнице
- Простота в освоении пользователями и разработчиками
- Устранение дихотомии документ/приложение
- Продвинутое оформление и брендинг
- Открытый код и бесплатное использование
Это не совсем то, что принято считать главными принципами архитектуры: если опросить разработчиков, то большинство из них, вероятно, назовут сутью архитектуры веба URL, просмотр исходников, кроссплатформенность, HTTP и так далее. Но это всё просто детали реализации. Веб взял верх над Delphi и Visual Basic не потому что JavaScript настолько крут. Есть более глубокие причины.
Перечисленные выше вещи, в принципе, довольно понятны. Я более подробно проанализирую их по ходу статьи. Для победы над вебом недостаточно просто повторить его сильные стороны, мы должны идти дальше и предложить уникальные улучшения, которые веб не способен легко интегрировать. Иначе нет смысла: вместо своего проекта мы будем просто работать над улучшением веба.
В этой статье я предлагаю две вещи: определённые принципы архитектуры, которым, по-моему, должен следовать любой серьёзный конкурент веба, и конкретный пример, собранный из различных open source проектов. Многим читателям не понравится конкретный пример, потому что им по душе другие проекты или языки программирования, в этом нет ничего страшного. Мне не важно. Это просто иллюстрация — по-настоящему важны принципы. Я называю конкретные кодовые базы только для иллюстрации, что эти мечты не совсем нереалистичны.
Принципы архитектуры
У веба отсутствует вразумительная философия архитектуры, по крайней мере, в отношении приложений. Вот каких необходимых вещей ему не хватает, на мой взгляд:
- Ясное понятие идентификаторов приложений.
- Единое представление данных от бэкенда к фронтенду.
- Бинарные протоколы и API.
- Аутентификация пользователей на уровне платформы.
- Ориентированная на IDE разработка.
- Компоненты, модули и отличная система вёрстки UI — точно как в обычной разработке для настольных компьютеров или мобильных устройств.
- Также понадобятся вещи, с которыми хорошо справляется веб: мгновенный запуск стриминговых приложений без инсталляции или необходимости ручного обновления, изоляция этих приложений в песочнице, сложная стилизация UI, сочетание и и приведение в соответствие «документального» и «программного» материала (вроде возможности связать определённые виды приложений), возможность постепенного обучения и архитектура, которая не затрудняет разработчикам создание слишком сложных UI.
Первые четыре пункта, выделенные жирным, связаны с безопасностью, поскольку именно проблемы с безопасностью вынудили меня занять столь радикальную позицию. Возможно, низкую производительность веба можно исправить новым фреймворком JavaScript — может быть. Но я не думаю, что можно устранить проблемы с безопасностью. В последующих статьях я рассмотрю пункты, которые не выделены жирным.
Идентификаторы приложений и ссылки
Чтобы получить преимущества веба по развёртыванию и изоляции в песочнице, требуется некий браузер для приложений. Неплохо было бы получить возможность ссылаться на отдельные части приложения как на части гипертекстового документа. Это ключевой элемент успеха веба: страница с поисковыми результатами Amazon похожа на некое приложение, но мы можем ссылаться на него, так что это одновременно и документ.
Но наш браузер приложений не должен физически напоминать веб-браузер. Посмотрите свежим взглядом: UI веб-браузера не идеален.
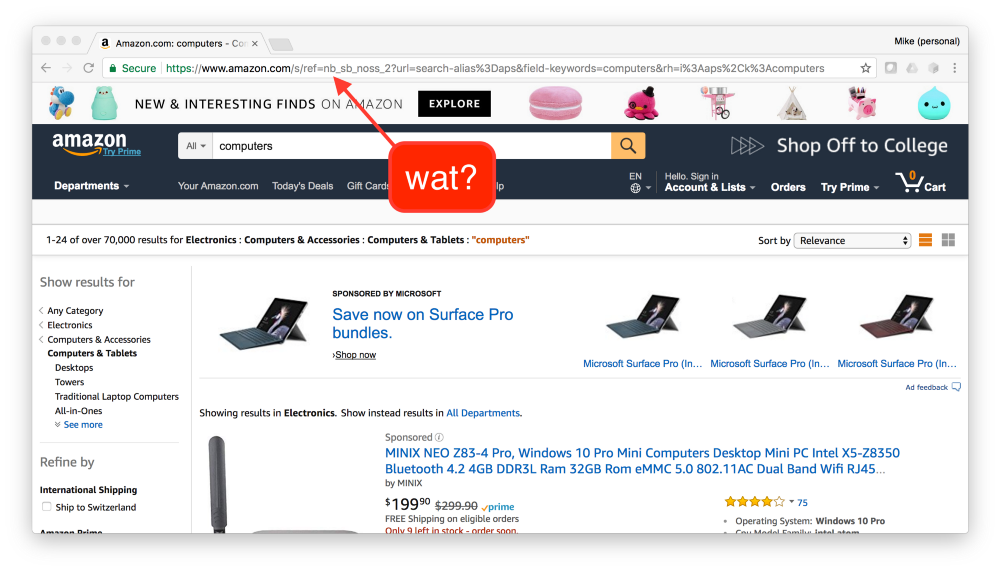
URL — основная часть дизайна любого браузера, но иногда он вносит путаницу!
Первая проблема в том, что URL'ы проникают повсюду в UI. Адресная строка постоянно содержит случайные биты из памяти браузера, закодированные в таком виде, который сложно понять и людям, и машинам, что ведёт к параду эксплоитов. Если бы десктопное приложение выгружало случайные внутренние переменные в строку заголовка, мы бы посчитали это серьёзным багом, угрожающим репутации фирмы, так почему здесь мы должны это терпеть?
Вторая проблема в том, что машинам тоже сложно воспринимать URL'ы (здесь возможно создание сумасшедших эксплоитов). Даже не учитывая хитрых трюков кодирования вроде этого, в вебе есть различные способы установить идентичность приложения. Браузеру требуется некое понятие идентичности приложения для отделения друг от друга хранилищ кукисов и для отслеживания выданных разрешений. Это «источник» (origin). Со временем концепция источника в вебе эволюционировала, и теперь её в сущности невозможно сформулировать. RFC 6454 пытается сделать это, но в самом документе написано:
Со временем многие технологии сошлись на концепции источника как на удобной единице изоляции. Однако многие из ныне используемых технологий, такие как куки [RFC6265], созданы раньше, чем современная концепция источника в вебе. У этих технологий часто другие единицы изоляции, что ведёт к уязвимостям.
Например, подумайте, что мешает вашему серверу установить куки для домена .com. А что насчёт kamagaya.chiba.jp? (это не веб-сайт, а просто раздел иерархии, как и .com!)
Возможность неожиданно поставить ссылку на часть приложения, которая не получает от этого никакой выгоды и не ожидает этого — один из источников проблемы «опасных ссылок». Сильно URL-ориентированный дизайн подвергает всё ваше приложение опасности инъекции данных со стороны посторонних злоумышленников. Это ограничение дизайна, которое известно тем, что с ним практически невозможно бороться, но оно беспечно поощряется самой архитектурой веба.
Тем не менее, возможность поставить ссылку на середину приложения из документов и наоборот была бы очень приятной, если всё работает как задумано разработчиками. Итак, сформулируем пару требований:
Требование: идентичность приложения (изоляция) должна быть простой и предсказуемой.
Требование: мы должны иметь возможность поставить глубокую ссылку на приложение, но не всегда.
К их чести, архитекторы Android понимали эти требования и предложили решения. Отсюда мы можем начать:
- Идентичность приложения определяет публичный ключ. Все документы, подписанные одним ключом, изолированы в одном домене. Для определения изоляции не используется разбор строк.
- Приложения могут подписаться на получение строго типизированных пакетов данных, которые просят их открыться в какое-то состояние. Android называет эту концепцию «намерениями» (intents). Намерения на самом деле не очень строго типизированы в Android, но могли быть такими. Их можно использовать также для внутренней навигации, но чтобы разрешить ссылки из какого-то другого приложения, намерение должно быть опубликовано в манифесте приложения. По умолчанию приложения не реагируют на ссылки.
- Где найти приложение для скачивания? Доменное имя — достаточно хорошая позиция для начала. Хотя мы можем поддерживать и скачивания по HTTP[S], но мы находим сервер NewWeb по хорошо известному порту и забираем код оттуда. Так что доменное имя становится начальной точкой для получения приложения, но в остальных отношениях не такой важной.
Чтобы различать URL'ы и чужие намерения от наших собственных, назовём чужие линк-пакетами.
Отключение приёма внешних ссылок по умолчанию понизит ссылочную связность NewWeb, но улучшит безопасность. Может быть, это плохой компромисс и он станет фатальным. Но многие ссылки, которые люди могут теоретически создавать в современном вебе, по сути бесполезны или из-за требований аутентификации, или потому что не содержат никакого осмысленного начального состояния (многие SPA). Поэтому приложения минимизируют область атаки. Вредоносная ссылка, которая является стартовой точкой такого большого количества эксплоитов, немедленно становится менее опасной. Это кажется ценным достижением.
Но есть и другие преимущества — важность доменного имени для веб-приложений делает соблазнительным для провайдеров конфисковать домены, которые не нравятся их руководству. Хотя простые сайты можно перенести на другой домен без особых проблем, более сложные сайты могут дорожить сложившейся репутацией почтовых адресов, токенов OAuth и так далее, для них это более болезненная процедура. Секретные ключи могут быть потеряны или украдены, но то же самое с доменными именами. Если вы потеряли секретный ключ — по крайней мере, это только ваша вина.
Что касается остальных частей браузерного UI, от них, вероятно, можно избавиться. Вкладки могут пригодиться, но кнопка перезагрузки страницы никогда не должна использоваться, а кнопку возврата в предыдущее состояние можно встроить в само приложение, если в ней есть смысл, а-ля iOS.
Как создать браузер приложений? Хотя NewWeb довольно сильно отличается от веба, базовый UI полноэкраннных приложений вполне стандартен, а пользователи захотят переключаться туда и назад. Так почему бы не форкнуть Chromium и не добавить вкладку в новом режиме?
(Правка: некоторые поняли вышесказанное как «использовать Chrome для всего, что здесь перечислено» — это не то, что я имел в виду. Я имел в виду использование его реализации UI со вкладками, чтобы у вас были открыты рядом приложения NewWeb и OldWeb. Но UI с вкладками несложно сделать, и необязательно использовать Chromium, браузер приложений тоже может быть созданным с нуля приложением).
Единое представление данных
Может быть концепция линк-пакетов звучит немного туманно. Что это такое? Для более чёткого определения нам нужны структуры данных.
В вебе существует масса способов сделать это, но все они на основе текста. Напомню тезис из моей прошлой статьи: у текстовых протоколов (не только у JSON) есть фундаментальная уязвимость: это «внутриполосная» сигнализация буфера, то есть чтобы выяснить, где заканчиваются данные, нужно прочитать их все в поиске конкретной последовательности символов. Эти последовательности могут быть законной частью данных, то есть вам нужен механизм экранирования. А потом, поскольку эти протоколы предполагаются как человекочитаемые или хотя бы нердочитаемые, часто возникают странные пограничные случаи с обработкой пробелов или канонизированным Юникодом, что приводит к эксплоитам, вроде атак с разделением заголовка HTTP.
В прежние времена текстовые протоколы помогали веб-разработчикам. Просмотр исходника определённо помог мне столько раз, что я не могу сосчитать. Но теперь средний размер веб-страницы превышает 2 мегабайта, не говоря уже о веб-приложениях. Даже скучные веб-странички со статичным текстом часто содержат массу минифицированных скриптов, в которых без машинной помощи вы не сможете даже начать разбираться. Преимущества текстовых протоколов кажутся меньше, чем в прошлые времена.

Примитивный декомпилятор
Если честно, в последние годы веб медленно отказывается от текстовых протоколов. HTTP/2 бинарный. И разрекламированный “WebAssembly” — это бинарный способ выражения кода, хотя он на самом деле не решает проблем, о которых мы говорили. Но тем не менее.
Требование: сериализация данных должна быть автоматической типизированной, бинарной и неизменной от хранилища данных до фронтеда.
Код для сериализации не только утомительно писать, но это ещё и серьёзный вектор атаки. Хорошая платформа должна взять задачу на себя. Давайте определим в самом примитивном виде синтаксис для выражения структур данных:
enum SortBy { Featured, Relevance, PriceLowToHigh, PriceHighToLow, Reviews } @PermazenType class AmazonSearch( val query: String, val sortBy: SortBy? ) : LinkPacket
В вебе эквивалентом этого будет URL на сайте amazon.com. Он определяет структуру данных неизменного типа для обозначения запроса на открытие приложения в некоем состоянии.
Эта структура данных помечена как
@PermazenType. Что это значит?Если мы серьёзно относимся к коду с префиксированной длиной, строгой типизацией защитой от инъекций по всему стеку, то придётся что-то сделать с SQL. Язык структурированных запросов — приятный и хорошо понятный способ выразить сложные запросы к разнообразным исключительно мощным движкам БД, поэтому его жалко. Но SQL — это текстовый API. Хотя SQL-инъекции — один из самых простых типов эксплоитов, которые легко понять и исправить, но это также один из самых распространённых багов на веб-сайтах. Ничего удивительного: если использовать SQL на веб-сервере самым очевидным образом, то он будет нормально работать, но незаметно сделает сервер уязвимым для взлома. Параметризованные запросы помогают, но это сбоку привинченное решение, которое не в каждой ситуации можно использовать. Технологический стек создаёт для всех нас хорошо замаскированный медвежий капкан, и наша цель — минимизировать соотношение рисков и функциональности.
У SQL имеются и некоторые другие проблемы. Вы быстро столкнётесь с проблемой объектно-реляционного отображения. Результаты выполнения SQL-запроса нельзя нативно отправить по соединению HTTP или встроить в веб-страницу, так что всегда потребуется некая трансформация в другой формат. SQL скрывает от вас производительность нижележащих запросов. Бэкенд сложно масштабировать. Изменения схемы зачастую требуют заморозки таблицы, так что их невозможно развернуть без неприемлемого даунтайма.
Движки NoSQL ненамного лучше: они обычно исправляют одну или две из этих проблем, но за счёт отбрасывания решений SQL для всего остального. В итоге вы часто застреваете с решением, которое иное, но не обязательно лучшее. В результате крупнейшие компании вроде Google и Bloomberg тратят много времени, пытаясь найти способ масштабировать базы данных SQL (F1, ComDB2).
Permazen — это новый подход к хранению данных, который восхищает меня в данный момент. Цитата с их сайта:
Permazen — совершенно новый подход к стойкому программированию. Вместо того, чтобы начинать разработку со стороны технологии хранения, он начинает со стороны языка программирования, задавая простой вопрос: «Какие проблемы присущи стойкому программированию, независимо от языка программирования или технологии СУБД, и как их можно решить на уровне языка наиболее простым, самым корректным и самым естественным с точки зрения языка способом?»
Permazen — это библиотека Java. Однако её архитектуру и техники можно использовать на любой платформе или языке. Ей нужно сортированное хранилище «ключ-значение» такого типа, какой могут предоставить многие облачные провайдеры (она также может использовать RDBMS в качестве хранилища K/V), но всё остальное делается внутри библиотеки. У неё нет таблиц или SQL. Вместо этого она:
- Использует операторы хостового языка для осуществления объединений и пересечений (соединений).
- Схемы напрямую определяются классами, не требуется устанавливать объектно-реляционное отображение.
- Может производить пошаговую эволюцию схемы «точно в срок», устраняя необходимость в заморозке таблицы для изменения представления данных в хранилище.
- Транзакции установлены однозначно, а копирование данных из транзакции и назад чётко контролируется разработчиком.
- Отслеживание изменений, так что вы можете получать обратные вызовы, когда изменяются лежащие в основе данные, в том числе между процессами (если хранилище K/V это поддерживает, а часто так и есть).
- Есть интерфейс командной строки, позволяющий осуществлять запросы и работать с хранилищем данных (например, инициировать миграцию данных, если вас не устраивает миграция по расписанию), и GUI.
В самом деле, вам просто нужно почитать великолепный доклад или посмотреть слайды (в слайдах используется старое название библиотеки, но это тот же самый софт). Permazen не слишком хорошо известна, но это самый умный и ловкий подход к тесному интегрированию хранилища данных с объектно-ориентированным языком, какой я когда-либо видел.
Одна из интересных особенностей Permazen — то, что вы можете использовать «снимки транзакций» для сериализации и десериализации графа объекта. Этот снимок включает в себя даже индексы, то есть вы можете транслировать данные в локальное хранилище, если памяти мало, и уже над ним выполнять запросы по индексу. Теперь должно стать понятным, как эта библиотека унифицирует хранение данных с поддержкой офлайновой синхронизации. Разрешение конфликтов можно осуществлять транзакционно, поскольку все операции Permazen способны выполняться внутри сериализуемых транзакций (если хотите бесконфликтную работу в стиле Google Docs, которая требует библиотеки операционного преобразования).
Необязательно в NewWeb использовать именно такой подход. Вы можете выбрать что-то немного более традиционное вроде protobuf, но тогда придётся использовать специальный IDL, что одинаково неудобно во всех языках, а также помечать тегами поля. Вы могли бы использовать CBOR или ASN1. В моём текущем проекте Corda мы создали собственный движок для сериализации объектов, построенный на AMQP/1.0. В нём по умолчанию сообщения описывают сами себя, так что для каждого конкретного бинарного пакета вы всегда получаете схему — и поэтому там доступна функция просмотра исходников, как в XML или JSON. AMQP предпочтителен, потому что это открытый стандарт, а базовая система типов довольно хороша (например, он узнаёт даты и аннотации).
Смысл в том, что рискованно принимать данные из потенциально вредоносных источников, так что в рамках формата желательно получить столько степеней свободы, сколько возможно, и максимальное количество проверок целостности. Все буферы должны быть с префиксами длины, так что пользователи не могут попытаться инъецировать вредоносные данные в поле — такие попытки будут прекращаться на ранней стадии. Данные должны быть тщательно проверены при загрузке, а лучшее место для такой проверки — система типов и конструкторы самих структур данных, тот способ, о которым вы могли уже забыть. Схемы помогают понять, какой должна быть структура, мешая злоумышленникам использовать смешение типов.
Несмотря на абсолютно бинарную природу предложенной схемы, можно произвести одностороннее преобразование в текст для отладки и в образовательных целях. На самом деле Permazen и это умеет.
Простота и поэтапное обучение
У систем типов есть одна проблема — они привносят дополнительную сложность. Разработчикам, которые не сталкивались с типами, они кажутся некоей бессмысленной бюрократией. А без соответствующих инструментов бинарные протоколы могут быть сложнее для изучения и отладки.
Требование: простота в освоении
Уверен, что значительная часть успеха веба объясняется тем, что он по сути не типизирован. Всё здесь — просто строки. Плохо для безопасности, производительности и удобства обслуживания, но очень хорошо для обучения.
Один из способов обращения с такой структурой в мире веба — постепенная типизация в версиях JavaScript. Это хорошая и ценная исследовательская работа, но такие диалекты не нашли широкого применения, и большинство новых языков хотя бы отчасти строго типизированы (Rust, Swift, Go, Kotlin, Ceylon, Idris…).
Ещё одним способом выполнения этого требования может стать умная IDE: если позволить разработчикам сначала работать с нетипизированными структурами (всё что определяется как
Any), среда выполнения может попробовать определить, какими должны быть исходные типы, и транслировать эту информацию обратно в IDE. Затем она может предложить замену на лучшие аннотации типов. Если разработчик сталкивается с ошибками приведения типа во время работы программы, то IDE может предложить снова ослабить ограничение.Конечно, такой подход обеспечивает меньшую безопасность и удобство обслуживания, чем если заставить разработчика самого заранее продумывать типы, но даже относительно слабые эвристически выставленные типы, которые часто приводят к ошибкам во время выполнения, всё равно защищают против большого количества эксплоитов. Среды выполнения вроде JVM и V8 уже собирают информацию о типах такого рода. В Java 9 есть новый API, позволяющий контролировать виртуальную машину на низком уровне (JVMCI), он занимается таким профилированием — сейчас было бы гораздо проще экспериментировать с такого рода инструментами.
Языки и виртуальные машины
Какой язык должна использовать NewWeb? Конечно, это непростой вопрос: платформа не должна стать вычурной.
За прошедшие годы предпринималось много попыток ввести в веб другие языки, кроме JavaScript, но все они оказались неудачными, не получив консенсуса со стороны разработчиков браузеров (в основном, со стороны Mozilla). На самом деле, в этом отношении веб возвращается в прошлое — вы могли запускать Java, ActionScript, VBScript и другие языки, но производители браузеров систематически удаляли с платформы все не-JavaScript плагины. Это какой-то позор. Безусловно, можно же было сохранить конкуренцию. Грустный приговор веб-платформе, что WebAssembly — единственная попытка добавить новый язык, и этим языком является C… на котором, я надеюсь, вы не захотите писать веб-приложения! Достаточно нам XSS, чтобы добавлять сверху ещё уязвимости типа двойного освобождения одной и той же памяти.
Всегда проще согласиться с проблемой, чем с решением, но ничего страшного — пришло время выдвинуть (более) противоречивый тезис. Ядром моего личного дизайна NewWeb стала бы JVM. Это не удивит тех, кто меня знает. Почему JVM?
- HotSpot поддерживает больше различных языков программирования, чем любая другая виртуальная машина, а принцип дешевизны диктует максимально возможное использование кода open source.
Да, это значит, что я хочу оставить возможность использовать JavaScript (на высокой скорости), помимо Ruby, Python, Haskell, и да — C, C++ и Rust тоже останутся в игре. Всё это возможно благодаря двум действительно классным проектам, которые называются Graal и Truffle, о которых я подробно рассказывал. Эти проекты позволяют JVM запускать даже код на неожиданных языках (таких как Rust) в виртуализированной среде, быстро и и интероперабельно. Мне неизвестна никакая другая виртуальная машина, которая органично смешивает вместе так много языков и делает это с такой высокой производительностью. - Песочница OpenJDK годами подвергалась упорным атакам, и разработчики браузеров усвоили ряд болезненных уроков. Последний 0-day эксплоит датируется 2015-м годом, а предыдущий был в 2013-м. Всего два 0-day эксплоита в песочнице за пять лет — неплохо, на мой взгляд, особенно с учётом того, что после каждого из них были усвоены уроки и со временем сделаны фундаментальные улучшения в безопасности. Ни у какой песочницы нет идеальной репутации, так что в реальности всё сводится к личным предпочтениям — какой уровень безопасности считать достаточным?
- Существует огромное количество высококачественных библиотек, которые складывают ключевые фрагменты головоломки, такие как Permazen и JavaFX.
- Так получилось, что я достаточно хорошо знаю JVM и мне нравится Kotlin, который подходит для бэкенда JVM.
Я понимаю, что многие не согласятся с моим выбором. Без проблем — те же самые идеи архитектуры можно реализовать на базе Python или V8, или Go, или Haskell, или чего угодно другого, в чём вы плаваете. Лучше выбрать что-нибудь с открытыми спецификациями и наличием конкурирующих реализаций (как у JVM).
Политика Oracle меня не беспокоит, потому что у Java открытые исходники. Среди высококачественных и высокопроизводительных open source рантаймов небольшой выбор. Существующие проекты созданы крупными корпорациями, которые замарали себя спорными решениями в прошлом. На различных этапах своего развития веб находился под влиянием или прямым контролем Microsoft, Google, Mozilla и Apple. Все они совершали поступки, которые я считаю предосудительными: это свойственно крупным компаниям. Вам не захочется вечно соглашаться с их поступками. Oracle вряд ли выиграет конкурс популярности, но преимущество открытого кода в том, что ей и не придётся в нём участвовать.
Конкретно из Google Chrome я бы кое-что позаимствовал. Мой браузер приложений должен поддерживать эквивалент WebGL (т.е. eGL), и проект Chromium ANGLE подходит для этой цели. Браузер приложений должен незаметно автоматически обновляться, как это делает Chrome, а движки автоматических обновлений Google тоже распространяются под свободной лицензией. В конце концов, хотя формат Pack200 сильно сжимает код, не повредило бы использование качественных кодеков вроде Zopfli.
RPC
Бинарных структур данных недостаточно. Нужны ещё и бинарные протоколы. Стандартный способ связать клиента с сервером является RPC.
В настоящее время один из самых крутых британских стартапов — Improbable. Недавно разработчики опубликовали отличный пост в блоге о том, как они перешли с REST+JSON на gRPC+protobuf от браузера к серверу. Improbable описывает результат как «нирвану безопасной типизации». Браузеры справляются с этим не так легко, как с HTTP+XML или JSON, но с использованием нужных библиотек JavaScript вы можете прикрутить сверху нужный стек. Это хорошая мысль. Если вернуться в реальный мир, где мы все пишем веб-приложения, однозначно следует рассмотреть такой вариант.
В разработке протоколов RPC следует использовать имеющийся опыт. Мой идеальный RPC поддерживает:
- Возвращение фьючерсов (обещаний) и ReactiveX Observables, так что вы можете транслировать пуш-события естественным путём.
- Возвращение потоков байтов большого или бесконечного размера (например, для прямых видеотрансляций).
- Контроль потока при передаче трафика с низким/высоким приоритетом.
- Версионирование, эволюция интерфейса, проверка типов.
Опять же, в проекте Corda мы проектируем стек RPC именно с такими свойствами. Мы ещё не выпустили его в виде отдельной библиотеки, но надеемся в будущем сделать это.
HTTP/2 — одна из самых последних и наиболее проработанных частей веба, это достаточно приличный фреймовый транспортный протокол. Но он унаследовал слешком много хлама от HTTP. Только представьте, какие хаки становятся возможными, если отказаться от методов HTTP, которые всё равно никогда не используются. Странный подход HTTP к описанию состояния не нужен. HTTP сам по себе не меняет состояние в процессе исполнения, а вот приложениям нужны сессии с хранением состояния, так что разработчикам приложений приходится добавлять поверх протокола собственную реализацию, используя мешанину легко воруемых кукисов, токенов и так далее. Это ведёт к проблемам вроде атак фиксации сессии.
Лучше более чётко разделить всё по слоям:
- Шифрование, аутентификация и управление сессиями. TLS неплохо справляется. Можно просто использовать его.
- Транспорт и контроль потока. Этим занимается HTTP/2, но протоколы обмена сообщениями вроде AMQP тоже справляются с задачей, и без груза наследия прошлого.
- RPC
Очевидно, стек RPC интегрирован с фреймворком структуры данных, так что все передачи данных типизированы. Разработчикам никогда не понадобится выполнять парсинг вручную. Именование в RPC — это простое сравнение строк. Следовательно, отсутствуют уязвимости с выходом за пределы текущего каталога (path traversal).
Аутентификация пользователей и сессии
NewWeb не будет использовать куки. Для идентификации сессий лучше подходят пары открытого и закрытого ключей. Веб идёт в этом направлении, но чтобы сохранить совместимость с существующими веб-приложениями требуется сложный этап «привязки», на котором токены владельца вроде кукисов соединяются с несущей криптографической сессией, а это привносит дополнительную сложность в важный компонент безопасности — от этого этапа можно отказаться при полном редизайне. Сессии идентифицируются на стороне сервера только по открытому ключу.
Аутентификация пользователя — одна из самых сложных вещей, которые трудно правильно реализовать в веб-приложении. Я ранее высказал несколько мыслей по этому поводу, так что не буду повторяться. Достаточно сказать, что привязку сессии к почтовому адресу лучше выполнять на стороне базовой платформы, а не постоянно изобретать велосипед на уровне приложений. Сертификата TLS на клиентской стороне вполне достаточно, чтобы реализовать базовую систему единого входа, где поток операций вроде «отправить письмо и подписать сертификат в случае получения» настолько дёшев, что провайдеры бесплатных сертификатов в стиле Let's Encrypt станут вполне реальными.
Этот подход основан на уже существующих технологиях, но при этом серьёзно сократит количество фишинга, взлома баз с паролями, брутфорса и многих других проблем, связанных с безопасностью.
Заключение
Платформа, которая хочет конкурировать с вебом, должна серьёзно озаботиться вопросами безопасности, поскольку это важнейшее обоснование для её создания и конкурентное преимущество. Это главная вещь, которую невозможно легко исправить в вебе. То есть нам нужны: бинарные структуры данных с безопасной типизацией и бинарные API, RPC, криптографические сессии и идентификация пользователей.
В новом вебе также есть изоляция кода в песочнице и стриминг контента, UI с хорошим макетированием, но в то же время хорошо реагирующий и с поддержкой стилей, некий способ смешивать вместе документы и приложения, как это делает веб, и очень продуктивная среда разработки. Ещё нам следует рассмотреть политику нового веба.
Обсудим эти вопросы в следующей статье.
