Всем привет,
В предыдущей статье я писал о том, что мы сделали новую in-memory БД — быструю и с богатыми функциональными возможностями — Reindexer.
В этой статье хочу рассказать как при помощи Reindexer можно реализовать полнотекстовый поиск по сайту, написав минимум application кода.

Вообще, полнотекстовый поиск по сайту — эта важная фича, в наше время, обязательная, для любого интернет сайта. От качества и скорости работы поиска зависит
как быстро пользователи найдут интересующую их информацию или товары, которые они планируют приобрести.
Лет 15-20 назад поиск был абсолютно не интерактивным и простоватым — на сайтах была поисковая строчка и кнопка "Искать". От пользователя требовалось корректно,
без опечаток, и в точной форме ввести, что он хочет найти и нажать кнопку "Искать". Дальше — секунды ожидания, перезагрузка страницы — и вот они результаты.
Зачастую, не те, которые ожидал увидеть пользователь. И все повторялось по новой: ввести новый запрос, кнопка "Искать" и секунды ожидания. По современным меркам — вопиющие издевательство над базовыми принципами UX и пользователями.
За последние десятилетия уровень поисковых движков в среднем заметно подрос — они уже готовы прощать пользователю опечатки, слова в разных словоформах, а самые продвинутые могут преобразовывать поисковые запросы, введённые транслитом или на неверной раскладке клавиатуры, например, так "zyltrc" — "яндекс", по ошибке, введенный на английской раскладке.
Так же, подросла и интерактивность поисковых движков — они научились выдавать "саггесты" — предложения пользователю, что дальше стоит ввести в поисковой строчке, например, пользователь начинает вводит "прези", а ему по мере ввода автоматически предлагается подставить слово "президент".
Еще более продвинутый вариант интерактивного поиска — "search as you type": выдача поиска автоматически отображается по мере того, как пользователь вводит запрос.
Возможностей появилось много, однако, они не бесплатные — чем больше ошибок поиск может исправить, тем медленнее он работает. А если поиск работает медленно, то о саггестах и instant поиске придётся забыть.
Поэтому, зачастую разработчикам приходится идти на компромисс — либо отключать часть функционала, либо отключать интерактивность, либо заливать железом и тратить много денег на серверную инфраструктуру.
Итак, это было немного лирики. Давайте перейдем к практике — реализуем при помощи Reindexer поиск по сайту, без компромиссов.
А начнем мы сразу с результатов — что получилось: распарсили весь Хабр, включая комментарии и метаданные, загрузили его их реиндексер, и сделали бэкенд и фронтенд поиска по всему Хабру.
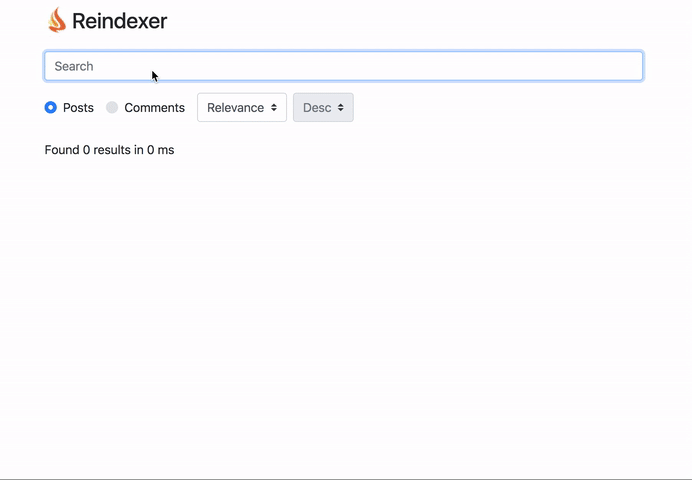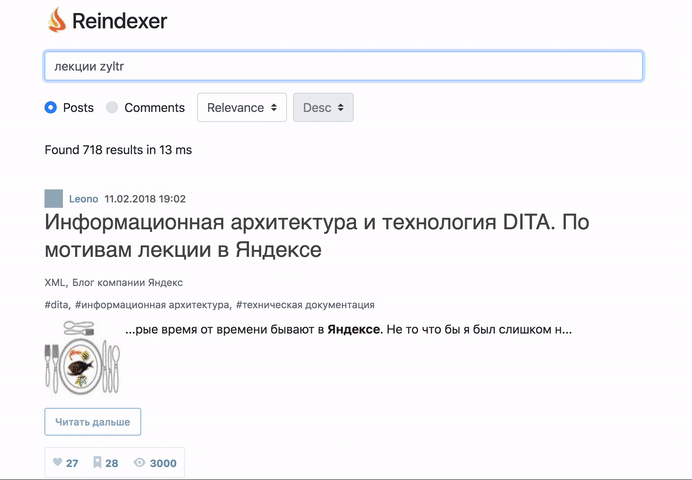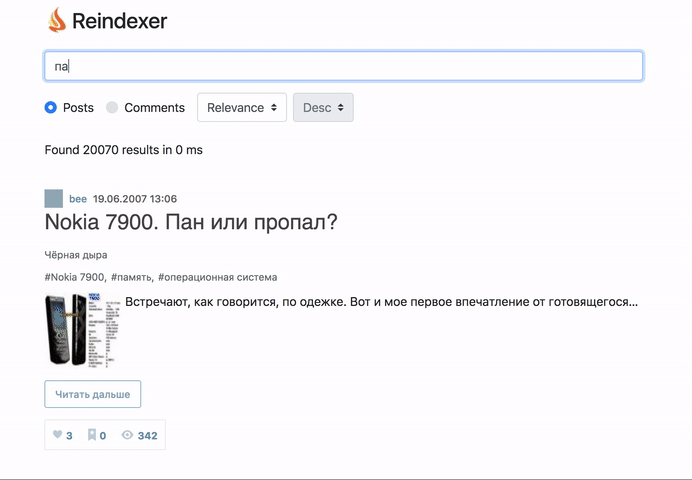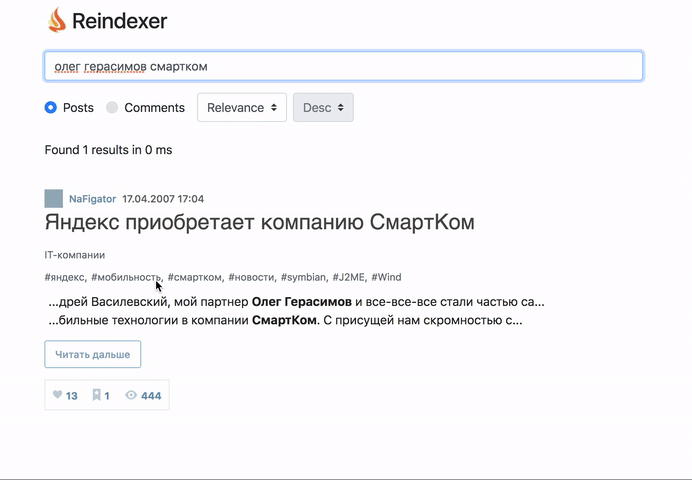
Пощупать вживую, то, что получилось можно тут: http://habr-demo.reindexer.org/
Если говорить про объем данных, то это — около 5гб текста, 170 тысяч статей, 6 миллионов комментариев.
Поиск работает со всеми фичами — транслит, неверная раскладка клавиатуры, опечатки и словоформы.
Однако, дисклеймер — все же собранный "на коленке" проект, за неделю, свободными от прочих дел вечерами. Поэтому прошу не судить строго.
Работает на 1-м VPS 4x CORE, 12 GB RAM. Минимально, можно было бы ужать до 1x CORE, и 10GB RAM, но оставили немного резерва — вдруг хабро-эффект, сами понимаете.
Реализация всего проекта < 1000 строчек, из которых заметная часть — парсер страничек habra, раскладывающий html по структурам с данными.
Дальше в статье расскажу, как это реализовано.
Бэкенд
Структура и используемые компоненты
Бэкенд — это golang приложение. В качестве http сервера и роутера используются fasthttp и fasthttprouter. В данном конкретном случае, можно было бы
использовать любой другой набор сервера и роутера, но решил остановиться на них.
В качестве БД используется reindexer, а для парсинга html страниц — замечательная библиотечка goquery
Структура приложения очень простая и состоит всего из 4-ех модулей:
- Репозиторий — отвечает за работу с хранилищем данных, так же в нем описание моделей данных
- HTTP — отвечает за обработку запросов
- Парсер — отвечает за парсинг страничек Хабра
- main — обработка интерфейса командной строки и запуск/инициализации компонентов
Методы API
- /api/search – полнотекстовый поиск постов и комментариев
- /api/posts/:id — получение поста по ID
- /api/posts — получение листинга постов с фильтрацией
Модели данных
Модели данных — это golang структуры. При работе с Reindexer в тэгах полей структуры описываются индексы, которые будут построены по полям.
Остановлюсь на выборе индексов подробнее — от выбора индексов зависит как и скорость выполнения запросов, так и потребляемая память.
Поэтому очень важно назначить правильные индексы полям, по которым предполагается поиск или фильтрация.
Структура с постом:
type HabrPost struct { // Уникальный ID записи. Заводим для него индекс имя `id` и флаг 'pk' - Primary Key // Это означает, что будет быстрый поиск по полю `id`, и то что Reindexer не разрешит вставить несколько записей с одинаковым id ID int `reindex:"id,,pk" json:"id"` // Время поста. В методах API, могут быть сортировки по этому полю, поэтому лучше использовать тип индекса `tree` Time int64 `reindex:"time,tree,dense" json:"time"` // Текст поста. Самостоятельных выборок с фильтрацией по полю text нет, поэтому тип индекса `-` - только хранение данных Text string `reindex:"text,-" json:"text"` // Заголовок поста. Самостоятельных выборок с фильтрацией по полю title нет, поэтому тип индекса `-` - только хранение данных Title string `reindex:"title,-" json:"title"` // Ник пользователя. Методы API предусматривают выборку по имени пользователя, поэтому тип индекса по умолчанию `HASH` User string `reindex:"user" json:"user"` // Массив хабов. Обычный HASH индекс, по полю массиву Hubs []string `reindex:"hubs" json:"hubs"` // Массив тэгов. Обычный HASH индекс, по полю массиву Tags []string `reindex:"tags" json:"tags"` // Количество лайков. Для поля не строится отдельный индекс. Запросов API с фильтрацией по этому полю нет. // Сортировка по полю `likes` используется только в полнотекстовых запросах, а для сортировки результатов полнотекстового // поиска по другому полю индекс не используется Likes int `reindex:"likes,-,dense" json:"likes,omitempty"` // Количество добавлений в закладки. Тип индекса выбран по аналогии с `likes` Favorites int `reindex:"favorites,-,dense" json:"favorites,omitempty"` // Количество просмотров. Тип индекса выбран по аналогии с `likes` Views int `reindex:"views,-,dense" json:"views"` // Флаг, если картинка. В запросах не участвует HasImage bool `json:"has_image,omitempty"` // Комментарии к статье - массив Comments []*HabrComment `reindex:"comments,,joined" json:"comments,omitempty"` // Определение полнотекстового индекса. Поиск по полям title, text, user // Название полнотекстового индекса - `search` // Флаг `dense` - уменьшает потребление памяти при построении индекса, но построение индекса будет медленнее _ struct{} `reindex:"title+text+user=search,text,composite;dense"` }
Структура с комментария заметно проще, поэтому не будем на ней останавливаться.
Реализация метода поиска
Хендлер
На уровне REST API обработчик — это обычный хэндлер fasthttp. Его основная задача — получить параметры запроса, вызвать метод поиска в репозитории и отдать ответ клиенту.
func SearchPosts(ctx *fasthttp.RequestCtx) { // Получить параметры запроса text := string(ctx.QueryArgs().Peek("query")) limit, _ := ctx.QueryArgs().GetUint("limit") offset, _ := ctx.QueryArgs().GetUint("offset") sortBy := string(ctx.QueryArgs().Peek("sort_by")) sortDesc, _ := ctx.QueryArgs().GetUint("sort_desc") // Сходить в репозиторий items, total, err := repo.SearchPosts(text, offset, limit, sortBy, sortDesc > 0) // Сформировать ответ клиенту resp := PostsResponce{ Items: convertPosts(items), TotalCount: total, } respJSON(ctx, resp) }
Основную задачу обращения к поиску выполняет метод репозитория SearchPosts — он формирует запрос (Query) в Reindexer, получает ответ и преобразует ответ из
[]interface{} в массив указателей на модели HabrPost.
func (r *Repo) SearchPosts(text string, offset, limit int, sortBy string, sortDesc bool) ([]*HabrPost, int, error) { // Создаем новый запрос к Reindexer query := repo.db.Query("posts"). // Обращаемся к полнотекстовому индексу `search`, предварительно превратив введенную строку в DSL Match("search", textToReindexFullTextDSL(r.cfg.PostsFt.Fields, text)). ReqTotal() // Заказываем получение результатов в виде сниппетов: // Эта запись означает, что в сниппет будет содержать 30 символов до и 30 символов после найденного слова // найденное слово будет заключено в тэги <b> и </b> и каждая строчка с найденным словом будет начинаться // на "...", а заканчиваться на "...<br/>" query.Functions("text = snippet(<b>,</b>,30,30, ...,... <br/>)") // Полнотекстовый поиск по умолчанию сортирует по релевантности и игнорирует направление сортировки // наиболее релевантные записи - выше // Если требуется сортировка по другому полю, то ее нужно заказать явно вызовом метода `query.Sort` if len(sortBy) != 0 { query.Sort(sortBy, sortDesc) } // Наложим пэйджинг applyOffsetAndLimit(query, offset, limit) // Исполнение запроса. Поиск и формирование результатов будет происходить во время вызова query.Exec () it := query.Exec() // Обработаем ошибку, если она была if err := it.Error(); err != nil { return nil, 0, err } // По завершении выборки итератор нужно закрыть. Он держит внутренние ресурсы defer it.Close () // Фетчим полученные результаты выборки items := make([]*HabrPost, 0, it.Count()) for it.Next() { item := it.Object() items = append(items, item.(*HabrPost)) } return items, it.TotalCount(), nil }
Формирование DSL и правил поиска
Обычно, поисковая строка сайта предполагает ввод запроса обычным человеческим языком, например, "Большие данные в науке" или "Rust vs C++", однако, поисковые движки требуют передачи запроса в формате специального DSL, в котором указывается дополнительные параметры поиска.
В DSL указывается по каким полям будет происходить поиск, подстраиваются релевантности — например, в DSL можно задать, что результаты, найденные по полю "заголовок"- более релевантные, чем результаты в поле "текст поста". Так же, в DSL настраиваются опции поиска, например, искать ли только точные вхождения слова или заодно, искать слово с опечатками.
Reindexer — не исключение, он так же предоставляет для Application DSL интерфейс. Документация по DSL доступна на github
За преобразование текста в DSL отвечает функция textToReindexFullTextDSL. Функция преобразовывает текст так:
| Введеный текст | DSL | Комментарии |
|---|---|---|
| Большие данные | @*^0.4,user^1.0,title^1.6 *большие*~ +*данные*~ |
Релевантность нахождения в поле tilte — 1.6, в поле user — 1.0 |
в остальных — 0.4. Искать слово большие во всех словоформах |
||
| как префикс или суффикс, а так же искать с опечатками и искать | ||
все словоформы, данные, как суффикс или префикс |
Получение и загрузка данных
Для удобства отладки, мы разделили процесс получения/парсинга данных с Хабра и загрузку их в реиндексер на два отдельных этапа:
Парсим Хабр
За загрузку и парсинг страничек Хабра отвечает функция DownloadPost — ее задача скачать с Хабра статью с указанным ID, распарсить полученную html страничку, а так же загрузить первую картинку из статьи и сделать из нее thumbinail.
Результат работы функции DownloadPost — заполненная структура HabrPost со всеми полями, включая комментарии к статье и массив []byte с картинкой.
Как устроен парсер, можно посмотреть на github
В режиме импорта данных приложение вызывает DownloadPost в цикле с ID от 1 до 360000 в несколько потоков, а результаты сохраняет в набор json и jpg файлов.
При скачивании в 5 потоков — весь Хабр скачивается примерно за ~8 часов. Из возможных 360000 статей — корректные статьи есть только по 170000 ID-шникам, по остальным ID
возвращается та или иная ошибка.
Суммарный объем распарсенных данных — около 5gb.
Загружаем данные в Reindexer
После завершения импорта Хабра у нас есть 170к json файлов. За загрузку сета файлов в Reindexer отвечает функция RestoreAllFromFiles
Эта функция преобразует каждый сохранённый JSON в структуру HabrPost и загружает ее таблички posts и comments. Обратите внимание, комментарии выделены в отдельную табличку, чтобы была возможность поиска по отдельным комментариям.
Можно бы поступить по другому и хранить все в одной таблице (это, кстати, уменьшило бы размер индекса в памяти), но тогда бы не было возможность поиска отдельных комментариев.
Эта операция не очень долгая — на загрузку всех данных в Reindexer уходит примерно 5-10 минут, в один поток.
Настройка полнотекстового индекса
У полнотекстового индекса есть целый набор настроек. Эти настройки вместе с настройками из DSL напрямую определяют качество поиска.
В настройки входит:
- список "стоп слов": это слова, которые часто употребляются в документах и не несут никакой смысловой нагрузки.
- опции построения индекса: поддержка транслита/опечатки/неверная раскладка клавиатуры
- коэффициенты формулы вычисления релевантности. В нее входят: функция bm25, дистанция между найденными словами, длина слова из запроса, признаки точного/не точного совпадения.
В нашем приложении за установку параметров поиска отвечает функция репозитория Init
Про фронтенд и баг Chrome с "бесконечным" скролом
Фронтенд реализован на vue.js — https://github.com/igtulm/reindex-search-ui
Когда делали "бесконечный" скрол с подгрузкой результатов столкнулись с очень неприятным багом Google Chrome — по мнению последнего, загрузка ответа от сервера при скроле иногда занимает 3-4 секунды.
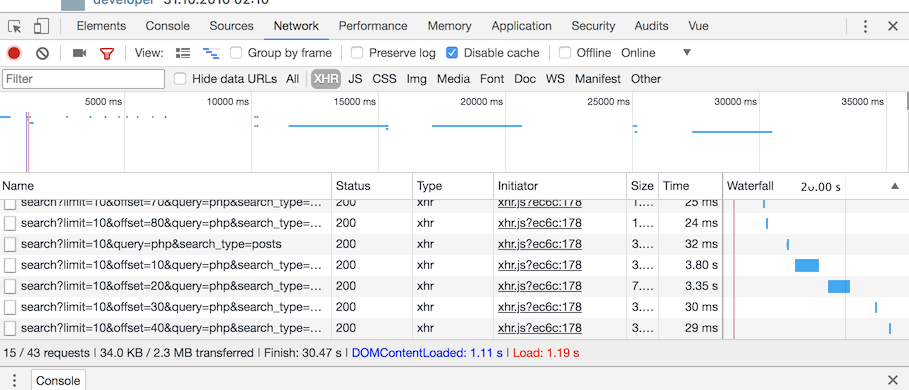
Как так! У нас же быстрый бэкенд с реиндексером, отвечающий за миллисекунды -а тут, целых 4 секунды. Стали разбираться:
По логам сервера все хорошо — ответы отдаются за считанные миллисекунды.
2018/04/22 16:27:27 GET /api/search?limit=10&query=php&search_type=posts 200 8374 2.410571ms 2018/04/22 16:27:28 GET /api/search?limit=10&offset=10&query=php&search_type=posts 200 9799 2.903561ms 2018/04/22 16:27:34 GET /api/search?limit=10&offset=20&query=php&search_type=posts 200 21390 1.889076ms 2018/04/22 16:27:42 GET /api/search?limit=10&offset=30&query=php&search_type=posts 200 8964 3.640659ms 2018/04/22 16:27:44 GET /api/search?limit=10&offset=40&query=php&search_type=posts 200 9781 2.051581ms
Логи сервера, конечно, не истина в последней инстанции. Поэтому, посмотрел на трафик tcpdump-ом. И tcpdump тоже подтвердил, что сервер отвечает за миллисекунды.
Попробовали в Safari и Firefox — в них такой проблемы нет. Следовательно, проблема явно не во времени ответа бэкенда, а где то еще.
Кажется, проблема все же в Chrome.
Несколько часов гугления принесли плоды — на stackoverflow есть статья с workaround
И добавление магического "workaround" из статьи отчасти исправило проблему в Chrome:
mousewheelHandler(event) { if (event.deltaY === 1) { event.preventDefault(); } }
Однако, все равно, если очень-очень активно скролить тачпадом, изредка, возникает задержка.
Что еще — небольшой бонус трек, вместо заключения
С момента публикации предыдущей статьи в Reindexer-е появилось много новых возможностей. Самая главная из них — полноценный серверный (standalone) режим работы.
golang API в серверном режиме, полностью совместимо с API в embeded режиме. Любые существующее приложения можно перевести с embeded на standalone заменой одной строчки.
Вот так приложение будет работать в embeded режиме, сохраняя данные на локальной файловой системе в папке /tmp/reindex/testdb
db := reindexer.NewReindex("builtin:///tmp/reindex/testdb")
Вот так приложение будет работать с standalone сервером, по сети:
db := reindexer.NewReindex("cproto://127.0.0.1:6534/testdb")
Standalone сервер можно либо установить с dockerhub, либо собрать из исходников
И еще, мы открыли телеграмм официальный канал поддержки Reindexer. Если есть вопросы или предложения — добро пожаловать!
